|
ECOLE SCIENCES-U - LYON
Master II - Expert en Ingénierie Informatique
|
|
Demain, tous développeurs?
|
|
Mémoire de fin d'études 2011-2012
|
|
GODARD Romain


ECOLE SCIENCES-U - LYON
Master II - Expert en Ingénierie Informatique
|
Demain, tous développeurs?
|
|
Mémoire de fin d'études 2011-2012
|
|
GODARD Romain

Remerciements
En préambule à ce mémoire, je souhaitais
adresser mes remerciements les plus sincères aux personnes qui m'ont
apporté leur aide et qui ont contribué à
l'élaboration de ce mémoire ainsi qu'à la réussite
de cette formidable année scolaire.
Je tiens à remercier sincèrement Monsieur
Gevrin, Madame Huin et Monsieur Bouiche (professeurs et directeur de ma
formation) qui m'ont permis de cadrer mon sujet, de m'apporter de l'aide sur
les axes de développement et qui m'ont orienté sur des pistes de
recherches.
Mes remerciements s'adressent également à
Monsieur Villard, mon tuteur en entreprise, qui m'a permis de m'épanouir
énormément dans mon milieu professionnel durant cette
année chargée au niveau scolaire.
Une reconnaissance spéciale à monsieur Bendraou,
mon professeur de génie logiciel lors de ma licence, qui a eu des
conseils avisés à mon égard.
Je n'oublie pas mes parents pour leur contribution, leur
soutien et leur patience malgré la distance.
J'adresse mes plus sincères remerciements à tous
mes proches et amis, qui m'ont toujours soutenu et encouragé au cours de
la réalisation de ce mémoire et qui m'ont toujours
supporté même dans les moments les plus difficiles.
Et un énorme merci à la classe de master EII
avec qui nous avons passé deux très bonnes années de joie,
de rires, de soutiens, de conseils et d'aides.
Merci à tous et à toutes.
Résumé
Actuellement plusieurs outils permettent la création de
logiciels, de sites web, de bases de données et d'interfaces graphiques
sans avoir aucune connaissance en programmation. Avec les logiciels il existe
des outils de modélisation de systèmes qui vont permettre de
générer le code de l'application. La création d'interfaces
graphiques peut se faire via le système WYSIWYG ("What You See Is What
You Get" "ce que tu vois c'est ce que tu obtiens") basé sur du
glisser-déposer : on choisit quel type d'élément on veut
mettre en place et il suffit de le sélectionner et de le positionner
dans la fenêtre de conception. Pour ce qui est de la conception de sites
Internet, il y a ce qu'on appelle des CMS (Content Management System ou
Système de Gestion de Contenu) et des éditeurs de sites qui vont
nous permettre de concevoir et mettre à jour des sites web ou des
applications multimédia en utilisant également le WYSIWYG. Les
bases de données peuvent, quant à elles, se gérer
facilement via des SGBD (Système de Gestion de Base de Données),
qui sont eux très explicites quand à la création,
modification et suppression d'éléments de la base : de simples
clics de souris et un clavier sont suffisants pour gérer une base de
données.
Cependant ces systèmes ne permettent pas encore de
développer quelque chose de robuste, entièrement fonctionnel et
sécurisé. Ils vont permettre de créer des applications
basiques avec quelques petites fonctionnalités dans le meilleur des cas,
mais dans le pire des cas ce ne sera qu'une simple interface inexploitable.
Néanmoins, l'évolution des technologies, les
manières de développement et la démocratisation des moyens
énumérés plus haut peuvent laisser imaginer de bons
présages pour l'avenir. Ces outils seraient accessibles par tous,
faciles d'usage et ils permettraient surtout d'avoir un résultat final
des plus aboutis. Avec les possibilités du web 2.0, il est possible
d'imaginer, non pas un développement individuel où chacun fait sa
propre application (un peu comme les macros Excel dans les entreprises), mais
plutôt un développement collaboratif et participatif où
chacun pourrait apporter sa pierre et son savoir à l'édifice.
L'apparition des SaaS (Software as a Service) et du Cloud Computing, vont
peut-être permettre le développement de logiciels à l'image
du développement des sites web, où l'on aurait un
développement participatif et collaboratif au travers du web.
Mots clefs : WYSIWYG, CMS,
modélisation, interfaces graphiques, glisser-déposer,
fenêtre de conception, éditeurs de sites, bases de données,
web 2.0, applicatif, logiciel, SGBD, participatif, collaboratif, SaaS, Cloud
computing, développement.
Abstract
Currently several tools allow the creation of softwares,
websites, databases and graphical interfaces without any programming knowledge.
Concerning softwares there are systems modeling tools that allow to generate
the application code. Creating graphical user interfaces can be done via a
WYSIWYG system ("What You See Is What You Get") based on the drag and drop : we
choose what type of elements we want to be set up, simply by selecting it and
positioning it in the design window. Regarding websites conceptions, there are
CMS (Content Management System) and websites editors that will allow us to
design and update websites or multimedia applications using the WYSIWYG too.
Databases can be managed easily via DBMS (DataBase Management System), which
are themselves very explicit about creation, modification and removal of
elements of the database, simple mouse clicks and keyboard are good enough to
manage a database.
However these systems don't allow to develop something robust,
fully functional and secure yet. They allow to create applications with few
basic features in the best case, in the worst case it will be a simple
interface unusable.
However, technological evolutions, ways of development and
democratization of means listed above can be good omens for the future, when
these tools will be accessible by all of us, easy to use and will allow to have
a final result the most accomplished as possible. Without going up to this
tools that everyone will not use, we can imagine, with what the Web 2.0 showed,
not a development where everyone make their own application each of its side
(like the Excel macros in companies) but rather a collaborative and
participatory development where everyone can bring its own contribution and
knowledge to the conception. The emergence of SaaS (Software as a Service) and
Cloud Computing, maybe will allow the development of software like the
development of websites, where we would have a collaborative and participatory
development through the web.
Key words : WYSIWYG, CMS, modeling,
graphical interfaces, drag and drop, design windows, websites editors,
databases, Web 2.0, application, software, DBMS, participatory, collaborative,
SaaS, Cloud Computing, development.
Table des matières
REMERCIEMENTS
IV
RÉSUMÉ
V
ABSTRACT
VI
TABLE DES MATIÈRES
VII
TABLE DES MATIÈRES DES
ILLUSTRATIONS
IX
I. INTRODUCTION
1
1. HISTOIRE DU GUI (GRAPHICAL USER
INTERFACE, INTERFACE UTILISATEUR GRAPHIQUE)
1
A. Les premiers pas
1
B. Les stations de travail
adoptent le GUI
2
C. La micro s'empare à
son tour des interfaces à fenêtres
2
2. LE LOGICIEL
2
A. Le déploiement
2
B. L'évolution des
langages de programmation
3
C. Les interfaces
utilisateurs
3
D. Les principales tendances
dans la fabrication du logiciel
4
E. Le Génie Logiciel
(GL)
5
3. PROBLÉMATIQUE
5
II. ETAT DE
L'ART
7
1. LE LOGICIEL
7
A. Ingénierie
Dirigée par les Modèles (IDM ou MDE) MDE : Model-Driven
Engineering
8
B. Les IHM (Interface
Homme-Machine)
25
2. WEB
26
3. LES SYSTÈMES DE GESTION DE BASES
DE DONNÉES (SGBD)
27
III. NOUS POUVONS
ÊTRE TOUS DÉVELOPPEURS
31
1. LE LOGICIEL
31
A. La génération
de code
31
B. La génération
d'interfaces graphiques
37
2. LES SITES WEB
39
A. Le CMS (Content Management
System, Système de Gestion de Contenu)
40
B. Les éditeurs de
sites
42
3. LA SIMPLICITÉ D'UTILISATION D'UNE
BASE DE DONNÉES
44
IV. NOUS NE POUVONS
PAS TOUS ÊTRE DÉVELOPPEURS
49
1. LE LOGICIEL
49
A. Le MDA présente ses
faiblesses
49
B. Le DSML et ses limites
50
C. L'UML
51
D. Les éditeurs
graphiques WYSIWYG et leurs limites
53
2. LES SITES WEB
54
A. Les limites des CMS
54
B. Les faiblesses des
éditeurs de site web
55
3. LA CONSTRUCTION D'UNE BASE DE
DONNÉES NÉCESSITE UN APPRENTISSAGE
55
A. Un processus de conception
à assimiler
55
B. La
sécurité
56
C. Un vocabulaire à
connaitre et un apprentissage à faire
58
V. ET DEMAIN?
59
1. DES DÉVELOPPEURS BASIQUES?
59
2. TOUS DÉVELOPPEURS WEB?
59
A. Des nouveaux
développeurs Web
59
B. Développer c'est
partager l'information
63
C. Du contenu et du flux
64
D. Le Web participatif
65
E. On parle déjà
de web 3.0
66
3. TOUS DÉVELOPPEURS DE
LOGICIELS?
67
4. L'HYPER CONNECTIVITÉ
68
5. L'HISTOIRE NOUS DIS QUE OUI?
68
6. EST-CE QUE ÇA APPORTERAIT QUELQUE
CHOSE?
69
7. ET LES BASES DE DONNÉES QU'EN
FAIT-ON?
69
8. LE DÉVELOPPEUR DE "BASE" SERA
TOUJOURS LÀ.
70
9. ET SI C'ÉTAIT TOUT AUTRE
CHOSE?
70
A. Programmation par langage
naturel écrit
70
B. Programmation par langage
naturel parlé
71
VI. CONCLUSION
73
VII. TRAVAUX
CITÉS
75
VIII.
BIBLIOGRAPHIE
76
IX. ANNEXES
78
1. ANNEXE 1 : DIAGRAMMES UML
78
2. ANNEXE 2 : LE CODE SOURCE
GÉNÉRÉ PAR VISUAL EDITOR
82
3. ANNEXE 3 : EXEMPLE D'UNE
GÉNÉRATION DE CODE
83
Table des matières
des illustrations
FIGURE
1 : LE MACINTOSH
1
FIGURE 2 : EVOLUTION DE LA PRODUCTIVITÉ
DEPUIS 50 ANS
4
FIGURE
3 : CONSTAT DES PROJETS EN GÉNIE LOGICIEL
7
FIGURE
4 : EVOLUTION DE CES CHIFFRES
7
FIGURE 5 : EVOLUTION DU NOMBRE DE LIGNES DE
CODE
8
FIGURE 6 : UN EXEMPLE DE MODÈLE, LA PIPE
SELON MAGRITTE
10
FIGURE 7 : UN EXEMPLE DE
MÉTA-MODÈLE
11
FIGURE 8 : UNE ARCHITECTURE À 4 NIVEAUX
12
FIGURE 9 : NIVEAUX DE MODÉLISATION, EXEMPLE
DU JEU D'ÉCHEC
13
FIGURE 10 : PLUSIEURS VUES SUR UN MÊME
MODÈLE
14
FIGURE
11 : ABSTRACTION ET SÉPARATION DES PRÉOCCUPATIONS, L'EXEMPLE DE
GOOGLE MAPS
15
FIGURE 12 : LES TROIS TYPES DE MODÈLES DE
MDA
17
FIGURE 13 : EXEMPLE D'UTILISATION DES
MODÈLES DU MDA POUR RÉALISER UNE APPLICATION
17
FIGURE 14 : DSML
19
FIGURE 15 : HISTORIQUE DE L'UML
20
FIGURE 16 : L'ENSEMBLE DES DIAGRAMMES UML
22
FIGURE 17 : QUELQUES MODÈLES
D'ÉLÉMENT UML
23
FIGURE
18 : MÉTHODE DE DÉVELOPPEMENT UML
24
FIGURE 19 : APERÇU DE LA PARTIE GRAPHIQUE DE
VISUAL EDITOR SOUS JAVA
26
FIGURE 20 : APERÇU DE LA PARTIE SOURCE DE
VISUAL EDITOR SOUS JAVA
26
FIGURE 21 : L'APPROCHE BASE DE DONNÉES
28
FIGURE 22 : ARCHITECTURE D'UN SGBD
28
FIGURE 23 : ETAPE 1, LE POINT DE VUE FONCTIONNEL
(USE CASE)
32
FIGURE 24 : ETAPE 2, DIAGRAMME DE CLASSE
33
FIGURE 25 : ETAPE 3, DIAGRAMME DE
SÉQUENCE
33
FIGURE 26 : ETAPE 4, GÉNÉRER DU CODE
VIA LA MODÉLISATION
34
FIGURE 27 : UN EXEMPLE DE NOTES.
35
FIGURE 28 : EXEMPLE D'UN PROJET AVEC UN DSML
36
FIGURE 29 : RETOMBÉES ÉCONOMIQUE,
SOURCE METACASE 2009
37
FIGURE 30 : LA PALETTE
38
FIGURE 31 : UN EXEMPLE DE CONCEPTION EN DRAG AND
DROP
39
FIGURE 32 : RÉSULTAT LORSQUE L'ON
EXÉCUTE LE PROGRAMME
39
FIGURE 33 : UN EXEMPLE D'UTILISATION DU CMS
40
FIGURE 34 : LA PARTIE ADMINISTRATION DU CMS
41
FIGURE 35 : UN EXEMPLE DE CE QUI EST STOCKÉ
DANS LA BASE DE DONNÉES
41
FIGURE 36 : SAISIE DIRECTEMENT DANS L'INTERFACE
42
FIGURE 37 : UN EXEMPLE D'ÉDITEUR DE SITE
AVEC DES BOUTONS D'ÉDITION
43
FIGURE 38 : UN EXEMPLE DE PLATEFORME ONLINE AVEC DU
DRAG AND DROP
44
FIGURE 39 : UNE DES NOMBREUSE INTERFACE DES
SGBD
44
FIGURE 40 : LE CODE SQL LORSQUE LA TABLE A
ÉTÉ CRÉÉE
45
FIGURE 41 : CRÉATION D'UNE TABLE
45
FIGURE 42 : SPÉCIFICATION DES COLONNES
46
FIGURE 43 : REMPLISSAGE DES CHAMPS DE LA TABLE.
46
FIGURE 45 : EVOLUTION DU NOMBRE DE SITE CONSULTABLE
DEPUIS 1995
60
FIGURE 46 : EVOLUTION DU NOMBRE D'ARTICLE DE
WIKIPÉDIA EN FRANCE
63
FIGURE 48 : EVOLUTION DU NOMBRE DE COMPTE FACEBOOK
DANS LE MONDE
64
FIGURE 47 : AUGMENTATION DU NOMBRE DE BLOG DANS LE
MONDE, SOURCE TECHNORAITI
65
FIGURE 49 : LES INTERNAUTES DU WEB DEVIENNENT
ACTEURS
66
FIGURE 50 : DIAGRAMME DE CAS D'UTILISATION
78
FIGURE 51 : DIAGRAMME D'ACTIVITÉ
78
FIGURE 52 : DIAGRAMME DE CLASSE
79
FIGURE 53 : DIAGRAMME DE COLLABORATION
79
FIGURE 54 : DIAGRAMME
D'ÉTATS/TRANSITIONS
79
FIGURE 55 : DIAGRAMME D'OBJETS
80
FIGURE 56 : DIAGRAMME DE SÉQUENCES
80
FIGURE 57 : DIAGRAMME DE COMPOSANTS
81
FIGURE 58 : EXEMPLE DE GÉNÉRATION DE
CODE
83
I. Introduction
"Moi aussi je peux jouer ?". Petite phrase très commune
chez les enfants dans la cour de récréation désirant
participer à un simple jeu avec leurs camarades, afin de pouvoir
s'épanouir et éventuellement apprendre une nouvelle discipline.
La similitude peut être de mise avec le monde informatique et plus
particulièrement tous ces logiciels qui existent à profusion.
Beaucoup de personnes, hors du monde informatique, m'ont déjà
demandé "mais comment on créé un logiciel ?". Cette
question, qui peut paraitre anodine, montre bien que le monde informatique est
omniprésent dans la vie de tous les jours, et que chacun se montre
très curieux sur ces logiciels qu'on utilise quasiment quotidiennement
(pour ne pas dire tous les jours). Et bien sûr qui dit logiciel dit
interface graphique...
1. Histoire du GUI
(Graphical User Interface, Interface Utilisateur Graphique)
A. Les premiers pas
C'est du côté de Palo Alto (Etat-Unis), dans le
laboratoire de recherche de Xerox Parc, qu'une révolution informatique
va intervenir. En 1973, Xerox conçoit l'Alto, c'est une
révolution dans le domaine informatique car c'est la première
station à combiner une interface graphique avec des fenêtres, et
l'utilisation de la souris. Malheureusement Xerox ne prend pas le risque de
commercialiser sa machine qui est en totale rupture avec le marché.
Xerox la diffusera seulement sur ses sites pour pouvoir tester le concept, et
commercialisera le Xerox Star (qui reprend les grandes lignes de l'Alto)
seulement en 1981.
Figure 1 : Le Macintosh

Aujourd'hui tout le monde est au courant, c'est Apple qui fait
triompher cette nouvelle interface révolutionnaire avec son projet Lisa
(le nouveau micro-ordinateur de la marque), ceci c'est grâce à
Steve Jobs (suite à sa visite au Xerox Parc) qui va pousser Apple
à développer une interface similaire à l'Alto. Lisa est
commercialisé en 1983 mais c'est un échec car les performances
sont décevantes et la machine coûte 9995 dollars. L'arrivée
du Macintosh en 1984 rencontrera quant à lui le succès avec la
même interface (totalement intégrée à l'OS) que sur
Lisa. Apple se différencie ainsi de la concurrence des constructeurs
d'ordinateurs de bureau qui sont tous alignés sur le standard IBM PC et
MS/DOS.
B. Les stations de travail
adoptent le GUI
Ainsi tous les constructeurs vont équiper leur machine
du système à fenêtre. Apollo Computer lance son Display
Manager dès 1981, Sun Microsystems avec son interface SunTools, qui
s'exécute sur son système d'exploitation SunOS, James
Gosling and David Rosenthal développent NeWS, une interface
révolutionnaire car elle est basée sur une évolution
orientée objet de Postscript (langage d'impression exploité
notamment sur les imprimantes lasers), il n'y aura pas de suite à cette
expérience.
Mais les initiatives des industries convergent vers un
même standard : le X Window. Le X Window a été
développé en 1984 par le MIT (Massachusets Institute of
Technology) et est également connu sous le nom de X11. Il est
composé d'un logiciel serveur, d'un module client et d'un protocole de
communication pour permettre l'échange de l'un vers l'autre. X11 va
conduire à une génération de terminaux graphiques haute
résolution qui sont capables d'exécuter ce client X. Les machines
Unix par exemple disposeront d'une interface graphique et d'une ergonomie
semblable.
C. La micro s'empare à
son tour des interfaces à fenêtres
Par la suite les fournisseurs de micro-ordinateurs grand
public se sont mis à développer ces interfaces graphiques
grâce à la génération des processeurs 16/32 bits. On
peut citer l'AmigaOS créé par Commodore, le TOS de Atari ST, BeOS
créé par Jean-Louis Gassée ou encore le NextSTEP
créé par Steve Jobs.
Ces interfaces graphiques ont permis le développement
du logiciel.
2. Le logiciel
A. Le déploiement
La miniaturisation guide le rythme d'évolution de la
technologie du matériel mais c'est le déploiement logiciel qui
détermine la pénétration des ordinateurs dans les
activités qu'elles soient industrielles ou intellectuelles. Le logiciel
a complètement transformé l'ordinateur. Il est passé de
l'étape d'un outil pouvant dans la théorie solutionner un
problème à un outil qui le résout dans la pratique. Le
matériel est au logiciel ce que les instruments sont à la
musique. Léonard De Vinci avait défini la musique comme
"modelage de l'invisible", sa définition est d'autant plus
adaptée pour décrire un logiciel.
Les progrès du matériel ont été
énormes et ils le sont tout autant pour le logiciel. La grande
majorité des logiciels avait été inventée 15 ans
seulement après que Von Neuman ait définit l'architecture des
machines. Les programmeurs attendaient même des machines bien plus
puissantes pour pouvoir progresser. Pour s'en convaincre il suffit de regarder
les dates d'apparition des langages : Fortran en 1957, Lisp en 1959, Cobol en
1960, Basic en 1964,... Il en a été de même pour les OS
où les fonctions qu'un programme pouvaient exécuter en 1966 sous
l'OS des IBM 360 étaient quasiment les mêmes que celles de
l'OS/390 en 1995.
Les tous premiers programmes des ordinateurs ont
été conçus par des mathématiciens et des
scientifiques car ils croyaient que c'était du travail logique et
simple. Mais le logiciel s'est révélé bien plus
délicat à développer qu'ils ne l'avaient pensés. A
l'époque les ordinateurs étaient têtus, ils faisaient ce
qui été écrit plutôt que ce qui était voulu.
Les programmeurs sont donc apparus, ils n'étaient ni
mathématiciens, ni scientifiques mais étaient engagés dans
une nouvelle histoire avec les ordinateurs.
B. L'évolution des
langages de programmation
Les prémices des langages de programmation sont aussi
vieilles que le calculateur digital. Il a donc fallu inventer des notations
symboliques (un langage), ces notations sont ensuite traduites en code binaire
par des autres programmes (un compilateur). Le langage qui a été
le plus influent est le Fortran (développé en 1954 et 1957 par
John Backus & co. chez IBM). A l'époque, il n'était pas
certain que le compilateur puisse suivre la machine afin de produire du code
efficace. Pourtant l'objectif a été atteint et Fortran est encore
utilisé de nos jours. Mais Fortran avait des contraintes inutiles, des
limitations dans les structures de données et des carences dans le
contrôle logique du programme. Dans une moindre mesure on peut
considérer que les nouveaux langages ont vu le jour pour solutionner les
défauts de Fortran.
Malgré toutes les tentatives pour sortir un langage
universel par un comité (Cobol), une organisation commerciale (PL/I),
une personne (Pascal), ou par le ministère de la Défense
américaine (ADA) celles-ci ont échoué et ont ouvert la
voie à d'innombrables langages dont seulement une toute petite dizaine
est aujourd'hui utilisée.
A l'inverse du matériel, les forts progrès du
logiciel ne viennent pas d'une seule et même technologie mais d'un
ensemble de paramètres (structures de contrôle des programmes,
environnement de programmation, outils de programmation, etc). Malgré
cela, certains continuent de coder dans des langages qui datent de plus de 30
ans (Fortran).
"Je parle en espagnol à Dieu, en italien aux
femmes, en français aux hommes et en allemand à mon cheval"
disait Charles Quint, il n'y a pas de langage idéal en informatique
chacun fait selon ses sensations.
C. Les interfaces
utilisateurs
Un programme permet à l'ordinateur de se transformer en
un outil adapté à un usage particulier (fabrication d'un avion,
traitement de texte, etc). L'interface va servir d'intermédiaire entre
l'utilisateur et le logiciel, on parle d'IHM (Interface Homme Machine). Avant
on concevait l'interface utilisateur en dernier, désormais cela se fait
en premier ainsi chacun peut s'approprier "son" ordinateur. Bien sûr cela
reste une illusion, mais cette illusion est la métaphore
simplifiée que chacun se construit pour expliquer les actions du
système ou pour provoquer de nouvelles actions.
La majorité des principes et des
périphériques sont développés pour perfectionner
cette métaphore, c'est quelque chose qui est devenue commun dans la
programmation. Le principe le plus important est sans conteste le WYSIWYG
("What You See Is What You Get") c'est à dire ce que l'ont voit sur
l'écran est une représentation fidèle de la
métaphore de l'utilisateur. Un utilisateur veut un carré ? Il
obtient un carré. Chaque utilisation du carré entraîne une
modification prévisible du système, en tout cas du point de vue
de l'utilisateur. Les éléments de cette métaphore qui sont
les plus employés sont les fenêtres, les icônes, les menus,
etc.
Grâce à cela une nouvelle
génération de logiciel a émergé afin de
facilité la tâche de l'utilisateur.
D. Les principales tendances
dans la fabrication du logiciel
Sans le logiciel, les ordinateurs et les matériels de
communication ne pourraient pas fonctionner. Au tout début, les
coûts et les temps de développement des programmes ainsi que la
productivité des programmeurs n'étaient pas des données
critiques : Si une machine coûtait 2 millions de dollars, est-ce que
c'était important que le logiciel en coûte 200 000 dollars ?
L'arrivée des PC a bouleversé cette donne. En effet, la baisse
des prix du matériel a mit en lumière le coût des
logiciels.
La mesure de la productivité du logiciel est une
question très discutée. En utilisant la méthode des points
de fonction inventée par Allan Albrecht, chercheur chez IBM, vers la fin
années 70, on obtient la courbe suivante sur les 50 dernières
années :
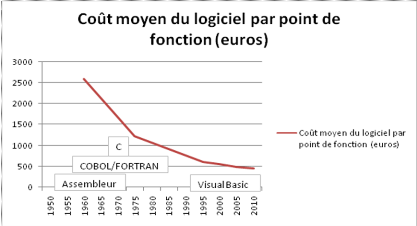
Figure 2 : Evolution de la productivité depuis
50 ans
Comme on peut le voir la courbe est en constante baisse depuis
la création des premiers logiciels, il y a donc peu de chance de voir la
productivité progresser considérablement dans les années
à venir. Les besoins en logiciel sont tels qu'on a vu apparaitre de
nouvelles idées et de nouvelles approches pour la programmation de
logiciel : le génie logiciel.
E. Le Génie Logiciel
(GL)
Le terme de software engineering (Génie
logiciel en français) a vu le jour à la sortie de deux
conférences du comité scientifique de l'OTAN (à Garmisch,
en Allemagne, du 7 au 11 octobre 1968, et à Rome, en Italie, du 27
au 31 octobre 1969).
Le génie logiciel est "une science de
génie
industriel qui étudie les méthodes de travail et les
bonnes pratiques des ingénieurs qui
développent
des logiciels. Le génie logiciel s'intéresse en
particulier aux procédures systématiques qui permettent d'arriver
à ce que des logiciels de grande taille correspondent aux attentes du
client, soient fiables, aient un coût d'entretien réduit et de
bonnes performances tout en respectant les délais et les coûts de
construction", selon Wikipédia. Son but est de maximiser les
durées de vie et les qualités des logiciels en minimisant les
coûts et les délais.
On retrouve la productivité au coeur du
développement des technologies de l'information et par conséquent
au coeur de l'activité des ingénieurs informaticiens. Ainsi se
dégagent deux aspects complémentaires :
· Perfectionner la productivité des codeurs et des
équipes qui réalisent le programme. Tout ceci grâce
à plusieurs méthodes, outils, facilités d'emploi et un
savoir-faire qui forment un tout homogène.
· Accroître le nombre d'ingénieurs pouvant
réaliser des programmes, où même éventuellement
permettre à un usager traditionnel de faire son propre programme dont il
a besoin (comme par exemple les tableurs qui ont vu le jour dans les
années 80 grâce à la micro informatique).
C'est ce dernier point qui va être le fil conducteur de
ce mémoire.
3. Problématique
L'idée de savoir si de simples usagers étaient
capables de réaliser eux-mêmes des programmes m'est venue l'an
dernier lors d'un projet où je devais développer une application
de production et de gestion de stocks en Java. Pour ce faire, j'ai dû
développer une IHM mais j'ai été confronté à
un problème : je n'avais pas toutes les compétences pour en
réaliser une qui soit, entre autres, ergonomique et visuellement
attractive.
En faisant des recherches sur Internet, j'ai trouvé un
plug-in pour Eclipse (environnement de développement libre) nommé
WindowsBuilderPro qui permet de créer des GUI sans écrire la
moindre ligne de code.
Ainsi je me suis demandé, est-ce que de tels outils ne
pourraient pas se généraliser dans l'avenir afin que chacun
puisse créer son propre logiciel? En condenser, demain, serons-nous tous
développeurs de programmes (et/ou sites web)?
Après avoir fait un état des lieux de
l'existant, je vous expliquerai de quel manière nous pouvons
déjà tous êtres développeurs, puis pourquoi
finalement nous ne pouvons pas l'être tous avant de savoir dans quelle
mesure cette problématique peut être légitime.
Il ne faut pas perdre des yeux que dans ce sujet je parle de
personnes qui n'ont aucune connaissance en programmation et qui dans le futur
pourraient être amenées à créer un logiciel, un site
web ou une base de données. Tout au long de ce mémoire
j'essaierai de répondre à la problématique en distinguant
bien ces trois notions que sont le logiciel, le site web et la base de
données dont la conception fait partie du métier de
développeur.
II. Etat de l'art
Dans cette partie, nous allons passer en revue tout ce qui va
nous permettre de développer un programme (ou un site web) sans
écrire une seule ligne de code. Comme expliquer dans la
problématique je distinguerai bien le logiciel, le site web et la base
de données.
1. Le logiciel
Le logiciel contrôle le monde, il est présent
absolument partout : processus métiers (administrative etc.),
gouvernement, l'industrie (Usines, chaines de fabrication), transports,
défense, finance, santé, édition, médias, nouvelles
technologies du web, commerce électronique, et bien plus encore.
Le logiciel a des enjeux aussi bien politiques
qu'économiques, d'autant plus que si un problème survient
à cause d'un logiciel les conséquences peuvent être
très lourdes :
· Therac 25, de 1985 à 1987 : 6 patients
irradiés, 2 morts
· Ariane 5 vol 88/501, en 1996 : le vol est
détruit au bout de 37 secondes et a coûté 850 millions de
dollars
· Mars Climate Orbiter & Mars Polar Lander sont
détruits en 1999
· Le projet d'informatisation de la bourse de Londres a
été abandonné au bout de 4 ans et a coûté 100
millions de livres
Figure 3 : Constat des projets en Génie
Logiciel
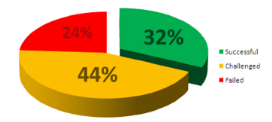
Figure 4 : Evolution de ces chiffres
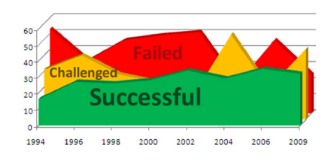
The Standish Group montre qu'en 2009 seulement 32% des projets
en génie logiciel respectent toutes les spécifications
prévues au départ et que 24% ne voient pas la fin. Bien que le
taux de succès reste en constante hausse, le taux d'échec est
quant à lui aléatoire :
Aujourd'hui les logiciels sont de plus en plus complexes car
ils ont plusieurs préoccupations, points de vue et aspects. Ces points
de vues sont noyés dans le code, il est donc impossible de les isoler.
Les applications sont également de plus en plus larges et le nombre de
lignes de code ne cesse d'augmenter, selon Wikipédia et Source Line Of
Code (SLOC) Windows XP c'est 40 millions de lignes de codes, ceci complique
grandement la communication ente les différents intervenants.
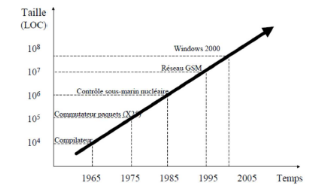
Figure 5 : Evolution du nombre de lignes de
code
Le logiciel c'est également des besoins qui
évoluent en cours de route, on a donc des besoins de variabilité.
Pour répondre à ces problématiques et à
l'évolution permanente des technologies, il est apparu, entre autres,
l'ingénierie dirigée par les modèles.
A. Ingénierie
Dirigée par les Modèles (IDM ou MDE) MDE : Model-Driven
Engineering
L'Ingénierie Dirigée par les Modèles
(IDM) est une méthodologie/vision de développement de logiciels
qui met l'accent sur la création de modèles (ou l'abstraction)
plus proche du concept du domaine concerné plutôt
qu'orienté informatique ou algorithmique.
Un paradigme de modélisation pour IDM est
considéré comme efficace si ses modèles ont un sens par
rapport au point de vue de l'utilisateur et peut servir de base pour
l'implémentation de systèmes.
Les principes de l'IDM :
· P1 : «Models as first class entities»
· P2 : Montée en abstraction
· P3 : Séparation des préoccupations
· P4 : Modèles productifs (Vs.
Contemplatifs)
P1 : Les modèles comme des entités de
première classe
Avec l'IDM on veut passer du "tout objet" au "tout
modèle", c'est-à-dire modéliser au lieu de coder. Il y a
un changement d'état d'esprit : on était dans le "coder une fois,
lancer partout" désormais on veut "modéliser une fois,
générer partout".
Le modèle objet a atteint ses limites, les concepts
objets sont plus proches de l'implémentation que du domaine
métier (Gabriel, 2002) et (Nierstrasz, 2010).
Avec le concept de l'objet il est difficile de raisonner et de
communiquer (code) car les aspects qu'ils soient fonctionnels ou pas sont
noyés dans des lignes de codes. Le défi est donc de s'orienter
vers une expertise métier et avoir un bon langage de
modélisation.
La définition d'un modèle : "A Model
represents reality for the given purpose ; the model is an abstraction
of
reality in the sense that it cannot represent all aspects
of reality. This allows us to deal with the world in a simplified manner,
avoiding the complexity,danger and irreversibility of reality" (Rothenber,
1989)
Traduction : un modèle représente une
réalité pour un sujet donné. Le modèle est une
abstraction de la réalité dans le sens où il ne peut pas
représenter tous les aspects de la réalité. Cela nous
permet de traiter le problème de manière simplifiée en
évitant la complexité, les dangers et
l'irréversibilité de la réalité.
La définition de la modélisation : "in the
broadest sense, is the cost-effective use of something in place of something
else for some cognitive purpose. It allows us to use something that is simpler,
safer or cheaper than reality instead of reality for some purpose" -
(Rothenber, 1989)
Traduction : au sens large, c'est l'utilisation rentable de
quelque chose à la place d'une autre dans un but cognitif. Elle nous
permet d'utiliser quelque chose qui est plus simple, plus sûre ou moins
chère que de la réalité.
Il faut cependant faire attention au débat qui dit que
l'abstraction est la même chose que la simplification car ce n'est pas le
cas. En effet, la modélisation simplifie la compréhension et la
communication autour du problème mais elle ne simplifie pas le
problème lui-même.
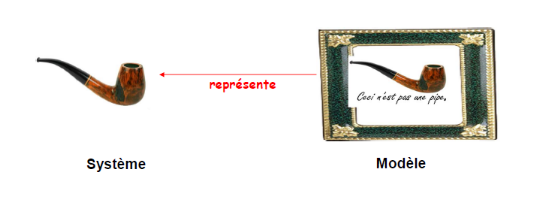
Figure 6 : Un exemple de modèle, la pipe selon
Magritte
Pour être productifs, les modèles doivent
être utilisés par des machines, on a donc besoin d'un langage
précis pour les définir, on appelle ceci
Méta-Modèle.
D'après l'OMG (Object Management Group. : Association
de professionnels de l'informatique
orientée objet
ayant défini la norme
Corba, ainsi que l'
OMA 1(*)et les
ORB2(*)) a "metamodel is a model that defines the language
for expressing a model". Traduction : un Méta-Modèle est un
modèle qui définit un langage pour définir un
modèle.
Pour Seidewitz, a «metamodel makes statements about
what can be expressed in the valid models of a certain modeling
language». Traduction : un méta-modèle fait des
déclarations sur ce qui peut être exprimé en modèles
valides de certains langages de modélisation.
La relation entre un modèle et son
méta-modèle est une relation "conforme à". Un
modèle est conforme à son méta-modèle si les
éléments et les relations entre ces éléments sont
définis dans le méta modèle
Conforme à
Représente
Méta-modèle
Modèle
Système
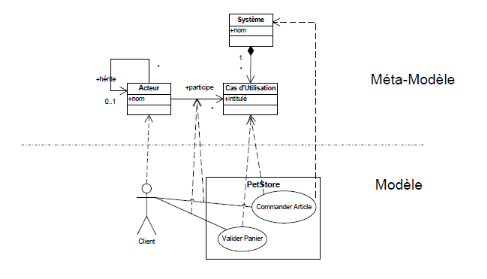
Figure 7 : Un exemple de
méta-modèle
Les langages utilisés pour exprimer les
méta-modèles ont eux-mêmes un modèle qu'on appelle
méta-méta-modèle et qui se trouve être
traditionnellement auto-descriptif. C'est en particulier le cas pour MDA (voir
plus loin). Un méta-modèle réflexif est exprimé
dans le même langage de modélisation qu'il décrit. Les
principaux langages de méta-modélisation existants sont MOF (pour
Meta-Objet Facilities), EMOF (pour Essential MOF), CMOF (pour Complete MOF) et
ECore défini par IBM et utilisé dans le framework de
modélisation d'Eclipse EMF (Eclipse Modeling Framework).
La spécification de MOF adopte une architecture de
méta-modélisations à quatre couches :
M0 : Ce niveau représente le
système réel à modéliser.
Exemple : Jeu d'échecs dans la figure ci
après.
M1 : Ce niveau est composé du
modèle représentant le système réel à
modéliser.
Exemple : modèle de jeu d'échecs via un DSL
(Domain Specific Langage)
M2 : Dans ce niveau on trouve le
méta-modèle décrivant le langage de
modélisation.
Exemple : méta-modèle du DSL de jeu
d'échecs.
M3 : Un niveau qui comporte le
méta-méta-modèle décrivant le langage de
méta-modélisation.
Exemple : Ecore, MOF.
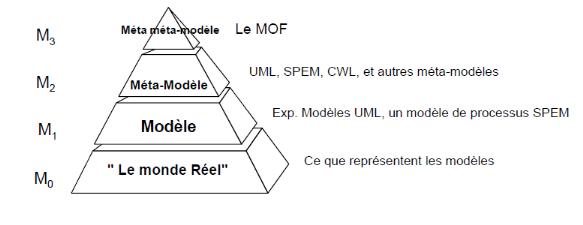
Figure 8 : Une architecture à 4
niveaux
On retrouve ces couches dans la figure 9, qui illustre un
système de jeu d'échec. L'échiquier est situé au
niveau M0, chaque élément de ce système est
modélisé au niveau M1. Dans ce niveau on retrouve le
modèle qui représente l'échiquier, les pièces sont
modélisées par une classe nommée pièce et qui a
certains attributs décrivant la pièce, même chose pour le
plateau et les cases. Ensuite on retrouve le méta-modèle au
niveau M2, ce dernier représente le langage de modélisation et il
est conforme à un méta-méta-modèle. Ce
méta-méta-modèle est situé dans le niveau M3, il
est conforme à lui-même et représente le langage de
méta-modélisation.
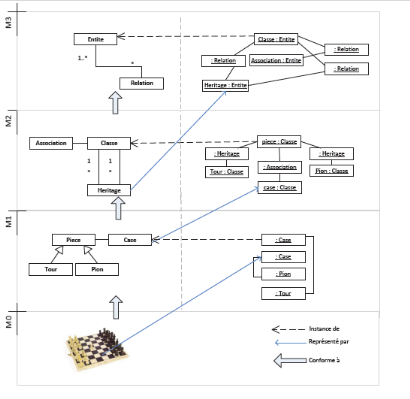
Figure 9 : Niveaux de modélisation, exemple du
jeu d'échec
P2 : Abstraction
L'abstraction c'est ignorer les détails insignifiants
et ressortir des détails les plus importants. Pour rappel l'importance
c'est décider de ce qui est signifiant et de ce qui ne l'est pas, cela
dépend directement de l'utilisation visée du modèle. Pour
le Larousse l'abstraction c'est l' "Opération intellectuelle qui
consiste à isoler par la pensée l'un des caractères de
quelque chose et à le considérer indépendamment des autres
caractères de l'objet."
Les modèles permettent de s'abstraire de certains
détails qui ne sont pas indispensables pour comprendre le système
selon un point de vue donné. Pour rappel le but du génie logiciel
c'est l'amélioration de la productivité via l'augmentation du
niveau d'abstraction.
Les langages de 3ème génération (
Fortran,
COBOL,
Simula,
APL, etc.) ont
amélioré la productivité du développeur par 450%
(Jones, 2006), alors que l'introduction des langages orientés objets
n'ont pas fait autant. Par exemple Java est 20% plus productif que le BASIC.
Les langages de programmation arrivent aujourd'hui à leur limite en
terme d'abstraction. Ainsi le défi c'est d'assurer la
transformation/transition vers le niveau le plus bas et de choisir le bon
niveau d'abstraction.
P3 : Séparation des
préoccupations
La séparation des préoccupations est
indispensable dans le cas d'applications complexes. Plusieurs aspects et/ou
points de vue signifient que nous avons plusieurs métiers
(sécurité, communication, GUI, QoS,..), mais un point de vue
concerne un modèle.
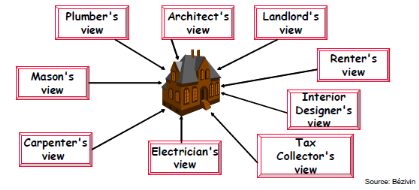
Figure 10 : Plusieurs vues sur un même
modèle
Chaque vue peut être exprimée en utilisant un
langage de modélisation différent. Il y a du coup plusieurs
intervenants dans la boucle. Le défis de l'IDM est d'intégrer des
vues et d'assurer une cohérence entre ces vues.
Vue plan

Vue satellite
Vue trafic

Un autre niveau d'abstraction
Street view
Figure 11 : Abstraction et séparation des
préoccupations, l'exemple de Google Maps
· P4 : Modèle productifs
La modélisation reste un investissement qu'il faudra
rentabiliser. On se dirige vers de plus en plus de code
généré automatiquement à partir des modèles.
Les défis des modèles productifs consistent en
des langages de modélisation proche du métier et précis,
des générateurs de code fiable, intégration du code
généré à partir de plusieurs vues vers un seul
système, génération du comportement, définition de
la chaine de transformation (raffinement) modèle vers code.
Les promesses de l'IDM sont donc :
· Gérer la complexité : les applications
sont de plus en plus énormes (Windows 2000 c'est 40 millions de lignes
de code) et ne peuvent pas être gérées par un seul
développeur.
· Meilleure communication : le code n'est pas toujours
compréhensible pour les développeurs qui ne l'ont pas produits,
on peut difficilement communiquer avec du code. Comme il y a souvent plusieurs
dizaines de personnes sur un projet cela permet d'avoir un langage commun et
universel (monde). Avec l'apparition de nouvelles façons de travailler
(outsourcing, sous-traitance,...) la communication y apparait comme
très importante.
· Pérenniser un savoir-faire : de part la
durée de certains projets. Les projets peuvent durer plusieurs
années donc ce ne sont pas toujours les mêmes personnes qui
travaillent dessus. Du coup il y a un besoin de capitaliser un savoir-faire
indépendant du code et des technologies. On veut capturer le
métier sans se soucier des détails techniques.
· Augmenter la productivité : On
génère du code à partir de modèles et on
maîtrise la variabilité c'est-à-dire que nous avons une
vision ligne de produits où l'on veut un modèle
générique pour un produit avec plusieurs variantes.
Exemple de NOKIA qui a vendu 1,1 milliard de
téléphones portables avec des milliers de versions logiciels
alors que le délai de mise sur le marché n'est que de 3 mois.
Ainsi se pose la question suivante : Quel langage utiliser
pour modéliser, méta modéliser (créer de nouveaux
langages) ? Pour cela nous allons voir deux approches :
· L'approche MDA : utilisation d'un ensemble de standards
fournis par l'OMG3(*) i.e.
MOF4(*), UML.
· L'approche DSML (Domain-Specific Modeling Languages)
L'approche MDA (Model-Driven Architecture)
L'approche MDA est une vision promue par l'OMG depuis 2001
(Soley, 2001), qui se base sur les modèles. La principale idée
est qu'un modèle indépendant de la plate-forme (Platform
Independent Model, PIM) définit l'ensemble des fonctionnalités du
système à développer. Le PIM va quand à lui
être traduit en modèle PSM (Platform Specific Model)
c'est-à-dire en modèle qui est spécifique à la
plate-forme. Le PSM va être utilisé par la suite pour
générer le code de la plate-forme cible. On entend aussi parler
de CIM (Computational Independent Model), il est encore plus abstrait que le
PIM et il est indépendant de tout système informatique selon
l'OMG. Il est là pour expliquer ce que le système devra
réellement faire.
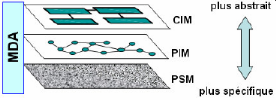
Figure 12 : Les trois types de modèles de
MDA
En résumé, les modèles CIM
décrivent les exigences sur le logiciel (services rendus, environnement
d'exécution, procédés métiers exploitants). Les
modèles PIM décrivent la conception abstraite du logiciel
(abstraction par la définition d'une machine conceptuelle), les
modèles PSM décrivent l'exploitation d'une plate-forme (choix
d'une machine d'exécution).
Attention, le CIM n'est pas une abstraction du PIM,
c'est-à-dire que les exigences ne sont pas une abstraction de la
conception abstraite, sauf si on suit le principe de raffinement. Le PIM est
une abstraction du PSM, c'est-à-dire que la conception abstraite est une
abstraction de la conception concrète. Le CIM et le PIM se recouvrent,
c'est à dire que les exigences du CIM doivent être
supportées par la conception, de même que le PIM et le PSM se
recouvrent, c'est-à-dire que la conception concrète doit
être conforme à la conception abstraite.
*
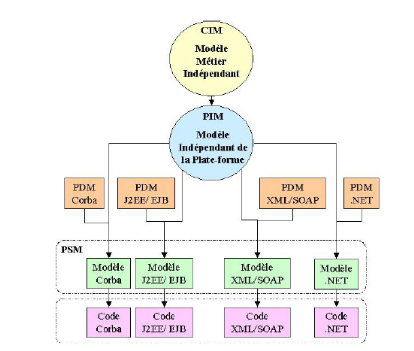
Figure 13 : Exemple d'utilisation des modèles
du MDA pour réaliser une application
* PDM pour Plateform Description Model. Il correspond
à un modèle de transformation du PIM vers un PSM
d'implémentation. L'architecte doit choisir une ou plusieurs plateformes
pour l'implémentation du système avec les qualités
architecturales désirées. Ce modèle propre à la
plate-forme est utile pour la transformation du PIM en PSM. La démarche
MDA est ainsi basée sur le détail des modèles
dépendants de la plate-forme. Il représente les
particularités de chaque plate-forme. Il devrait être fourni par
le créateur de la plate-forme.
Le MDA s'appuie sur plusieurs standards :
· Grâce au MOF, tous les méta-modèles
sont homogènes (diagramme de classe)
· Grâce à UML, il existe un langage de
modélisation très généraliste et ciblant plusieurs
niveaux d'abstraction (voir la partie dédiée à l'UML).
· Grâce à OCL, il est possible de
préciser des contraintes d'exploitation des modèles
· Grâce à AS, il est possible de
modéliser finement des comportements
· Grâce à XMI, il existe un format unique de
sauvegarde des modèles vers XML
· Grâce à SPEM, les procédés
de développement sont modélisables
· Grâce à QVT, les transformations sont
modélisables.
L'approche DSML (Domain-Specific Modeling Languages)
Dans le monde du génie logiciel, un DSML est un langage
de modélisation dédié à un domaine
précis.
A l'inverse du MDA qui utilise des méthodologies de
modélisation généraliste, la modélisation
spécifique à un domaine (DSM) lui utilise une méthodologie
qui est centrée sur un domaine spécifique et qui a pour but de
perfectionner la productivité. L'idée c'est de baisser l'espace
de conception afin d'avoir dans la plupart des cas une seule gamme de produit
par organisation. Ainsi le niveau d'abstraction des modèles est
élevé et la génération totale de
l'implémentation sera sur mesure pour l'organisation, d'où le
gain de productivité.
Le principe de la modélisation DSM est simple, et
réside dans la notion de langage de modélisation
spécifique à un domaine (Domain-Specific Modeling Language ou
DSML). On rassemble l'ensemble des connaissances du domaine d'application dans
un langage de modélisation qui lui est dédié, on en fait
des modèles et à partir de ces modèles on
génère du code.
L'approche DSML fait partie d'un environnement complet avec un
générateur de code et un environnement d'exécution
(framework) pour former les DSM.
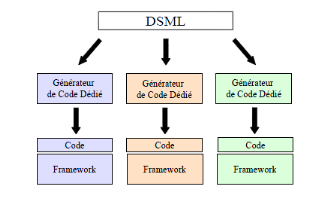
Figure 14 : DSML
L'UML (Unified Modeling Language)
Entre 1989 et 1994 : le nombre de méthodes
orientées objet est passé de 10 à plus de 50, où
chacune proposait son propre langage de modélisation. Toutes ces
méthodes avaient pourtant d'énormes points communs (objets,
méthodes, paramètres, ...). Au milieu des années 90, UML
est l'accomplissement de la fusion de précédents langages de
modélisation objet :
Booch,
OMT,
OOSE principalement issus des
travaux de
Grady Booch,
James Rumbaugh et
Ivar Jacobson. Les
principales influences de l'UML sont :
· Booch : Catégories et sous-systèmes
· Embley : Classes singletons et objets composites
· Fusion : Description des opérations,
numérotation des messages
· Gamma, et al. : Frameworks, patterns,
et notes
· Harel : Automates (Statecharts)
· Jacobson : Cas d'utilisation (use cases)
· Meyer : Pré- et post-conditions
· Odell : Classification dynamique, éclairage sur
les événements
· OMT : Associations
· Shlaer-Mellor : Cycle de vie des objets
· Wirfs-Brock : Responsabilités (CRC)
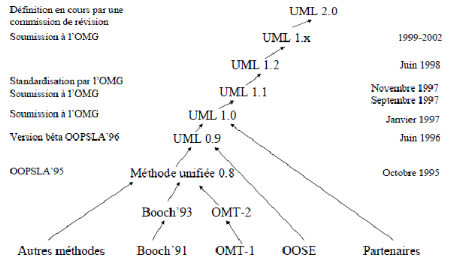
Figure 15 : Historique de l'UML
Aujourd'hui, UML est le langage de modélisation
orienté objet (OO) le plus connu et le plus utilisé et s'applique
à plusieurs domaines tels que : OO, RT, Déploiement,
Requirement,... Peu d'utilisateurs connaissent le standard, ils ont une vision
outillée d'UML (Vision Utilisateur) où 5% ont une forte
compréhension, 45% une faible compréhension, 50% aucune
compréhension.
Il y a trois utilisations possibles d'UML :
· Comme un langage pour faire des croquis, esquisses,
ébauches... (explorer)
Probablement la manière dont UML est le plus
utilisé aujourd'hui : pouvoir échanger, communiquer
rapidement autour d'une idée où les modèles ne sont pas
forcément à 100% complets. Ses objectifs sont d'analyser,
réfléchir et décider (brainstorming)
· Comme un langage de spécification de
modèles, patrons... (spécifier). On spécifie ici, des
modèles complets, prêts à être codés,
utilisés pour prendre des décisions poussées de design,
des modèles issus du Reverse Engineering (afin de
réfléchir dessus, d'améliorer la conception, de casser des
dépendances, etc.). Il y a également une possibilité de
faire du round-trip engineering (Génération de code et Reverse
engineering)
· Comme langage de programmation (produire). Ici, on veut
tout mettre dans le modèle, le modèle UML devient alors la source
du code afin de pouvoir générer et compiler du code à
partir du modèle.
C'est ce dernier point qui va nous intéresser.
La génération de code conduit à plus de
productivité (la structure d'une centaine de classes,
d'opérations, ... sont générés en un seul clic). Il
y a également moins d'erreurs car le savoir faire est codé dans
les générateurs de code.
Les principes d'un générateur de code consistent
en :
· un ensemble de règles décrivant la
correspondance entre concepts du modèle et concepts du langage (Java par
exemple, voir ci-après).
· paramétrages d'option (dans certains
cas/outils)
o Choix des constructions dans le langage cible (Vector ou
ArrayList en JAVA)
o Générer les accesseurs et les constructeurs
o Implanter les méthodes abstraites
· Un moteur de génération de code avec en
input le modèle et en output le code.
Voici à titre d'exemple quelques règles sur la
génération de code UML 2 vers JAVA :
· Une classe UML correspond à une classe JAVA
ayant le même nom.
· Une interface UML correspond à une interface
JAVA ayant le même nom
· Si une classe UML est associée à une
autre et que l'association est navigable, il y a alors un attribut dans la
classe JAVA qui va correspondre à la classe UML. Le nom de cet attribut
correspond au nom du rôle de l'association. Si l'association
spécifie une cardinalité supérieure à 1, alors
l'attribut de JAVA est une ArrayList.
· Une opération d'une classe UML correspond une
opération d'une classe JAVA ayant le même nom, ainsi que les noms
des éventuels paramètres.
Cette liste est non exhaustive, il existe encore beaucoup de
principes mais qui ne seraient pas pertinents ici.
UML se décompose en trois sous ensemble :
· En vue
· En diagramme
· En modèles d'élément
Les vues :
· des cas d'utilisation : montrent les besoins de chaque
acteur du système
· logique : montrent comment les besoins des acteurs
peuvent être satisfaits
· d'implémentation : montrent les
dépendances entre les modules
· des processus : montrent la vue temporelle et
technique
· de déploiement : montrent la position
géographique et l'architecture des éléments
Les diagrammes :
Ils sont au nombre de treize, représentant
différents aspects du système.
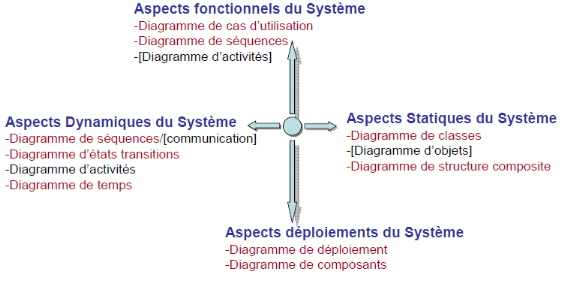
Figure 16 : L'ensemble des diagrammes UML
Je vais vous présenter succinctement les principaux
diagrammes UML
Point de vue fonctionnel :
Cas d'utilisation : OMG définit le cas d'utilisation
par une "représentation d'un ensemble de séquences d'actions
qui sont réalisées par le système et qui produit un
résultat observable intéressant pour un acteur
particulier".
Point de vue statique :
Diagramme de classes : va représenter les classes qui
interviennent dans le système.
Diagramme d'objets : représente la vue statique d'un
ensemble d'instance de classe
Point de vue dynamique :
Diagramme de séquences : représente les
interactions entre les objets dans la réalisation du processus de
l'application
Diagramme de collaboration/communication : il possède
les mêmes constituants que le diagramme de séquences mais il met
davantage l'accent sur les objets impliqués dans l'interaction que sur
l'aspect temporel des échanges.
Diagramme d'état/transition : description d'un objet
aux changements de son environnement.
Diagramme d'activité : modélise les traitements
effectués par une opération.
Point de vue déploiement :
Diagramme de composants : sert à montrer le lien entre
les différents composants d'une application
Les modèles d'élément
:
Ce sont les briques des diagrammes. Ce sont tous les
éléments qui vont permettre de concevoir les diagrammes.
Figure 17 : Quelques modèles
d'élément UML
La méthode de développement UML respecte un
processus strict. Après avoir lu le cahier des charges, il y a
établissement en parallèle le diagramme de cas d'utilisation (UC)
et de classes (seulement avec les attributs). A partir du diagramme de UC on
établit les diagrammes de séquences d'analyses et
d'activités. On peut ainsi peaufiner le diagramme de classes avec les
opérations et finir par les diagrammes de séquences de
conception.
Figure 18 : Méthode
de développement UML
Classes d'analyse
Classes de conception
Activités
Séquence de conception
Séquences d'analyses
Cas d'utilisation
En parallèle
Cahier des charges
B. Les IHM (Interface
Homme-Machine)
L'exemple de Visual Editor pour Java
Tout ce que l'on a vu jusqu'à maintenant concernait la
conception pure de logiciel, mais sans un brin d'IHM, les logiciels ne seraient
utilisables que par une petite partie de personnes. Ainsi, toujours dans
l'idée de s'abstenir de programmer, de nombreux éditeurs d'IHM
existent. J'ai choisi de vous expliquer le fonctionnement de l'un d'entre eux :
Visuel Editor qui est un plug-in pour Eclipse (environnement de
développement).
L'éditeur graphique Visual Editor (VE) permet de
développer rapidement des interfaces graphiques basées sur
SWING/SWT (bibliothèque graphique pour JAVA). L'éditeur graphique
génère un code Java standard de bonne qualité qui peut
être modifié par la suite. Les évènements des objets
graphiques peuvent également être générés
avec VE. Il est aussi possible de gérer les modèles abstraits
pour les objets complexes tels que les Jtable ou encore les Jlist. La prise en
main de VE est intuitive, par exemple la gestion des layouts (mise en page)
permet de définir des structures graphiques complexes d'objets
imbriqués avec les containers (conteneurs). Le code
généré n'a pas un format spécifique à
Eclipse VE, un simple éditeur comme notepad++, peut suffire pour
continuer un développement.
VE est divisé en deux fenêtres, l'une montrant
les composants de Java dans une fenêtre de conception, et l'autre
montrant la source associée. Dans la fenêtre de conception ce sont
des représentations graphiques (boutons, label, layout,...). Lorsque
vous modifiez les composants dans la fenêtre de conception, la source est
mise à jour. Inversement, lorsque vous modifiez les fichiers source, la
fenêtre de conception est mise à jour afin de refléter les
modifications que vous apportez. Ce cycle de déclenchement des
fenêtres de conception et de la source est conçu de telle sorte
que l'éditeur visuel pour Java peut être utilisé non
seulement comme un outil pour générer du code, mais comme un
éditeur pour montrer l'effet de modifications du code source au cours du
développement. Une fois que vous apportez des modifications à
votre fichier dans un autre éditeur, vos changements seront
reflétés dans la fenêtre de conception de VE.
VE montre par défaut la fenêtre de conception
dans un onglet "Design" et la source dans un onglet "source". La fenêtre
de conception est une surface WYSIWYG qui vous permet de composer l'interface
graphique que vous construisez, tandis que le volet source affiche le contenu
du fichier Java. La fenêtre de conception dispose d'une palette sur la
gauche qui vous permet de contrôler la sélection des composants. A
tout moment vous pouvez utiliser l'option Annuler dans le menu d'édition
ou de l'action afin d'annuler une modification.
Bien sûr VE n'est pas le seul éditeur graphique
pour JAVA, on peut également citer WindowsbuilderPro ou encore
Jbuilder.
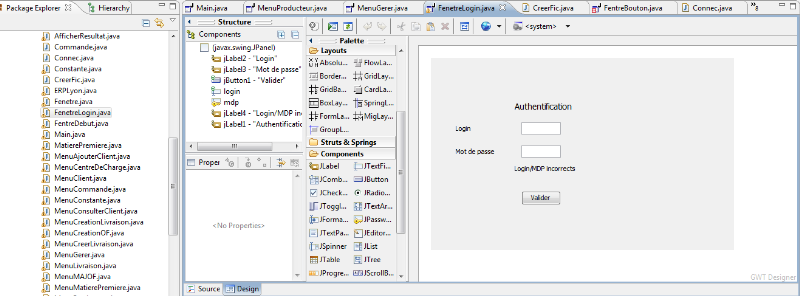
Figure 19 : Aperçu de la partie graphique de
Visual Editor sous JAVA
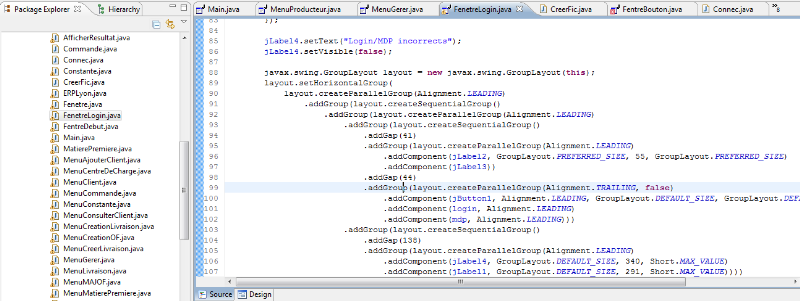
Figure 20 : Aperçu de la partie source de
Visual Editor sous JAVA
Pour la source, voir l'Annexe 2.
3. Web
Concernant la partie Web, beaucoup de sites proposent de
créer son site web en cinq minutes sans la moindre connaissance en
programmation. Ces sites s'adaptent aux besoins des utilisateurs et permettent
de créer un site dynamique, un blog, un
site
e-commerce - ou les 3 à la fois - sans aucune connaissance
technique.
L'ambition de ces sites est d'assouvir les besoins des
utilisateurs. Ils travaillent pour leur faire profiter des dernières
avancées technologiques à des prix accessibles, voire gratuits.
Parallèlement, ils concentrent leur activités afin
d'élaborer des solutions Web complètes et faciles à
configurer sachant que la majorité de leurs clients ne sont pas des
informaticiens professionnels.
Beaucoup proposent des "extras" comme par exemple une
collection de logiciels ou l'utilisation d'un serveur
sécurisé.
Les espaces clients deviennent de plus en plus ergonomiques et
leur permettent de pouvoir configurer facilement un nom de domaine ou
gérer un compte email POP3 par exemple. Beaucoup d'utilisateurs ne sont
pas des professionnels de la création de sites, ainsi ces sites
conçoivent des applications de telle manière que n'importe qui
sachant surfer sur le net puisse instinctivement utiliser ces programmes en
ligne.
Ces sites proposent d'enregistrer des noms de domaine qui sont
de moins en moins cher (<10€/an) avec des solutions
d'hébergements consistants (vaste espace disque, trafic inclus
considérable, collection gratuite de logiciels...).
Ces sociétés se développent après
avoir acquis, pendant des années, de l'expérience et de la
maturité en tant que fournisseurs de produits et services à la
pointe de l'innovation. Ils ciblent les petites et moyennes entreprises ainsi
que les particuliers soucieux d'un service de qualité à bon prix.
Ces sites investissent énormément pour
construire les plus grands et plus modernes centres de calcul. Surpassant tous
les standards de sécurité, d'alimentation, de
connectivité, de hardware et de performance, les sites web se trouvent
entre de bonnes mains. Leurs équipes de maintenance surveillent en
permanence l'activité des serveurs, garantissant ainsi une
disponibilité réseau proche de 100%.
Parmi ces sites on peut citer Jimbo ou Prestashop pour faire
des sites de e-commerce, Joomla ou Drupal qui sont des CMS (on y reviendra plus
tard dans ce mémoire) afin de faire de la gestion de contenu, et des
plates-formes en ligne comme OneAndOne ou Wix pour élaborer n'importe
quel type de site et bien sûr sans oublier l'utilisation des blogs et des
wikis qui ont explosé au milieu des années 2000 et qui permettent
de poster régulièrement des billets, ou faire de la modification
de contenu. On a dénombré pas moins de 156 millions de blogs
début 2011.
4. Les systèmes de
gestion de bases de données (SGBD)
Sans les bases de données la programmation web et
applicatif ne servirait à rien. En effet, nous aurions seulement de
simples interfaces où l'on ne pourrait pas stocker (ou remonter) des
données. Par exemple, une identification sur un site ne serait pas
possible. Le métier de programmeur ne se limite donc pas simplement aux
développements de logiciels, mais il faut également qu'il sache
créer et gérer une base de données.
Une base de données (BDD) est une collection de
données structurées sur des entités (objets, individus) et
des relations dans un contexte (applicatif) particulier. Un système de
gestion de base de données (SGBD) est un (ensemble de) logiciel(s) qui
facilite la création et l'utilisation de bases de données. Les
données sont définies, administrées et
gérées en utilisant des langages fondés sur des
modèles de données.
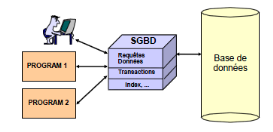
Figure 21 : L'approche base de
données
L'objectif du SGBD est de faciliter le partage de grands
volumes de données entre différents utilisateurs/applications. Il
doit garantir la cohérence et l'intégrité des
données en cas d'erreurs de programmation, d'accès concurrents,
de pannes, d'accès non autorisés, etc. Il doit également
garantir des performances d'accès sur des grands volumes de
données pour un grand nombre de clients.
Un SGBD a trois fonctions principales. Il doit, tout d'abord,
représenter et structurer l'information. Ceci par le biais d'une
description de la structure de données (ex : employés, âge,
noms,...), d'une description de contraintes logiques sur les données (ex
: 0 < Age < 150, ...) et d'une vue, c'est-à-dire une
réorganisation (virtuelle) de données pour des besoins
spécifiques. Un SGBD doit ensuite gérer l'intégrité
des données. Pour cela il y a une vérification des contraintes,
une exécution transactionnelle des requêtes (mise à jour)
et une gestion de la concurrence multiutilisateurs et des pannes. La
dernière fonction principale d'un SGBD est le traitement et
l'optimisation de requêtes.
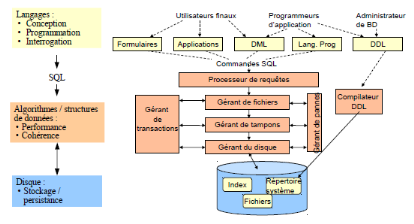
Figure 22 : Architecture d'un SGBD
Nous avons également trois types d'utilisateurs pour un
SGBD. Tout d'abord il y a l'utilisateur final (end user) qui accède
à la base de données par des formes d'écran, des formes
applicatives ou, pour les plus experts, des requêtes SQL5(*). Ensuite il y a le
développeur d'application qui va construire le schéma conceptuel,
définir/gérer le schéma logique et les vues et
concevoir/implémenter des applications qui accèdent à la
base de données. Le dernier type d'utilisateur d'un SGBD est
l'administrateur de base de données que l'on appelle DBA (DataBase
Administrator). Le DBA gère le schéma physique et règle
les performances, charge/organise la base de données (BDD) et
gère la sécurité et la fiabilité.
De nombreux SGBD existent sur le marché dans lesquels
on peut citer : Ingres, Oracle, Access, MySQL, PostgreSQL ou encore Progress.
III. Nous pouvons
être tous développeurs
1. Le logiciel
A. La génération
de code
Nous allons voir deux exemples de projet qui vont permettre de
générer du code via l'ingénierie dirigée par les
modèles. Pour rappel l'idée est de générer du code
à partir de modèles que nous allons au préalable
créer. Comme vu dans l'état de l'art, il y a deux langages de
modélisation: le MDA via l'UML et le DSML. Nous allons traiter un
exemple pour chacun, et voir que créer un programme peut être
à la portée de tous, et ce même dès aujourd'hui.
Exemple d'un projet avec UML
Nous allons traiter le cas d'une application que nous
appellerons "QCM".
QCM est une application de passages d'examens de type
"questions à choix multiples" en ligne et possède deux aspects
:
· Système côté enseignants
· Système côté étudiants
Ainsi, les professeurs peuvent, à partir de fichiers
XML ou en revisitant les anciens QCM, créer des QCMs pour évaluer
le niveau de leurs étudiants.
Les étudiants de leur côté, sont
prévenus par l'administration qu'un compte leur est affecté sur
le programme et leur fournis leur identifiant afin de procéder à
la validation de celui-ci.
Ces jeunes diplômants peuvent ainsi, lorsqu'ils entrent
dans la période de passage d'un QCM d'un des modules suivis, se
connecter au site et passer leur examen en ligne pendant un temps défini
par le créateur du QCM.
Une fois la date de passage du QCM arrivée à
échéance, les notes peuvent être récoltées
par le professeur et s'il le désire, envoyées aux
étudiants. Les étudiants peuvent, quant à eux, visualiser
les réponses aux QCMs qu'ils ont passé et savoir où ils
ont commis des erreurs.
Pour traiter ce sujet, nous avons les étapes classiques
d'un projet : recueil des besoins, modélisation, etc. Les modèles
vont nous permettre de générer du code. A la fin du projet nous
avons une synchro entre le code et les modèles, sous prétexte que
le code n'ait pas été modifié par un
développeur.
Dans un premier temps, dans un souci de communication nous
commençons par un diagramme de Use Case (ou cas d'utilisation), qui est
très parlant pour tout le monde.
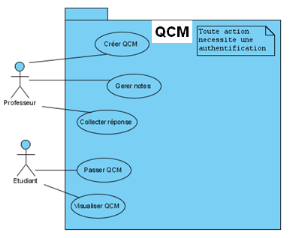
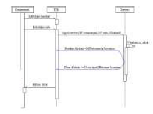
Figure 23 : Etape 1, le point de vue fonctionnel (Use
Case)
Dans notre cas, tout accès à QCM
nécessite une authentification. Il y a deux types d'authentification :
soit professeur, soit étudiant. Un professeur pourra créer un
QCM, gérer les notes et collecter des réponses. Un
étudiant pourra quant à lui passer un QCM et le consulter.
La deuxième étape consiste à passer au
point de vue structurel avec des diagrammes de classes. Cela va permettre de
présenter les classes et les interfaces du système ainsi que les
différentes relations entre celles-ci. Avec ceci nous avons des
"classes" et des "associations" au lieu de "widget", "menu", "champs". Il y
également une notation graphique sans aucun lien avec le domaine,
l'utilisateur manit ainsi des noms qui lui parlent, ce n'est pas du code
incompréhensible qu'il doit manipuler.
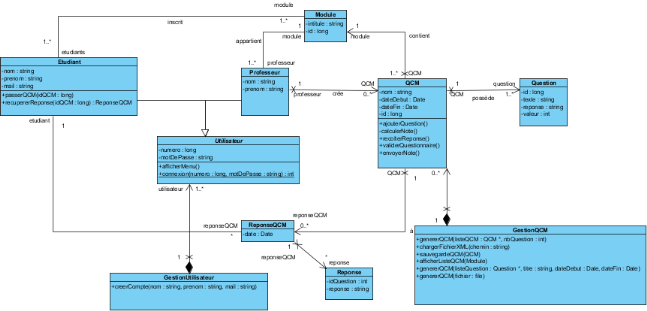
Figure 24 : Etape 2, diagramme de classe
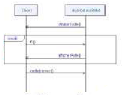
Ensuite vient le point de vue comportemental via le diagramme
de séquences, qui permet à l'utilisateur d'avoir une
représentation graphique des interactions entre les acteurs et le
système selon un ordre chronologique.
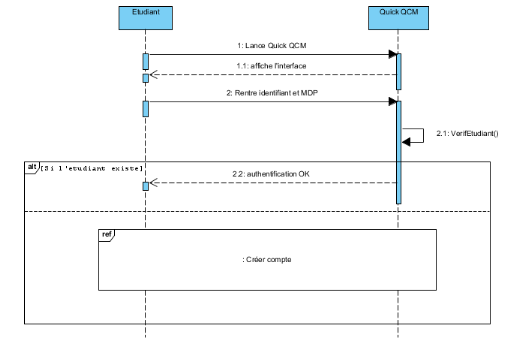
Figure 25 : Etape 3, diagramme de
séquence
Par le biais de ces trois étapes, nous avons fait le
strict minimum niveau modélisation pour pouvoir générer du
code. Cela se fait par un simple clic :
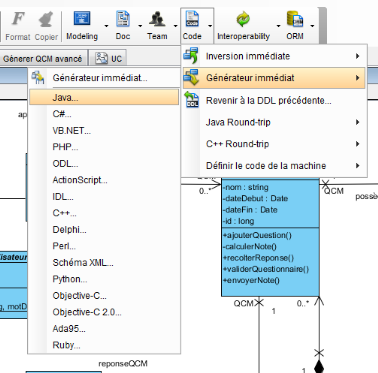
Figure 26 : Etape 4, générer du code via
la modélisation
Nous avons même plusieurs choix de langage concernant la
génération. Nous nous en tiendrons au Java. Vous pouvez voir un
exemple de génération de code en Annexe 3 concernant la partie
Utilisateurs de l'application. Seulement nous pouvons voir sur cette annexe,
qu'avec cette technique, le corps des méthodes reste vide. Pour cela, il
y a deux solutions : soit spécifier le corps des opérations avec
les activités et actions UML 2.0 soit associer des notes aux
opérations contenant le code des opérations.
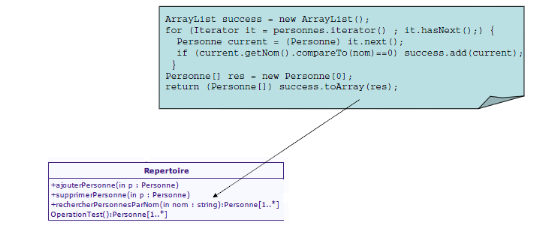
Figure 27 : Un exemple de notes.
L'association de notes nécessitent des connaissances en
programmation, nous ne l'expliquerons pas davantage.
L'idée, avec le diagramme d'activité c'est de
pouvoir en faire pour chaque opération du diagramme de séquence.
Ainsi chaque action du diagramme de séquence saura quand se
déclencher et quand s'arrêter. Le tout pourra être ainsi
interprété par le générateur de code et être
retranscrit.
Beaucoup d'outils UML permettent la génération
de code tels que :
· EclipseUML
· JDeveloper
· MagicDraw UML
· ModelSphere
· Objecteering
· PowerAMC
· QDesigner
· Visual Paradigm
· Visual UML
Ces outils permettent la création de langage de
modélisation et de suite outillée dans leur environnement
respectif (Eclipse par exemple). Ils permettent de créer des
modèles et des méta-modèles, générer des
bibliothèques permettant la manipulation de modèles. Tout ceci
grâce à des facilités dédiées
(transformation, éditeur graphique, vérificateur de contraintes,
...).
Exemple d'un projet avec DSML (Domain Specific Modeling
Language)
Dans le projet DSML nous allons ici traiter le cas d'une
application dans le domaine de la téléphonie mobile. Le projet
est de faire une application pour s'enregistrer à une conférence
depuis son téléphone portable.
Nous sommes ici dans un domaine
métier propre. Il est délimité, ce qui sous entend qu'on a
un grand besoin de productivité, d'où l'utilisation du DSML. Si
on doit faire une similitude avec UML, on peut dire que le DSML s'apparente
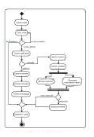
à un diagramme d'activité enrichi. Tout projet DSML commence par
un noeud initial, chaque étape est modélisée sous une
forme graphique compréhensible. Pour chacune d'elle il y a aussi la
possibilité de donner l'étape suivante en fonction du choix de
l'utilisateur. Pour mettre un terme à une suite d'instructions on met un
noeud final qui va marquer la fin de l'activité en cours.
Figure 28 : Exemple d'un projet avec un
DSML
Dans un projet avec DSML les modèles sont accessibles
et sont faits par des experts métier et pas forcément des
développeurs/analystes. En effet, c'est un langage avec peu de concepts,
tout est graphique et donc beaucoup plus compréhensible. Le niveau
d'abstraction est meilleur, donc il y a une utilisation de concepts propres au
domaine de modélisation.
Les générateurs de code intègrent
directement les librairies du Framework/plateforme d'exécution. Ainsi on
a 100% du code généré avec peu de maintenance à
faire car tout le savoir-faire est dans les générateurs.
L'utilisation de DSML a conduit à beaucoup de "success
stories" telles que :
· Nokia qui est de 300% à 1000% plus productif.
David Narraway, chef de projet chez Nokia "UML and other methods and
technologies say nothing about mobile phones. We are looking for more".
· US Air Force 300% plus productif
· Alcatel Lucent plus de 300% plus productif, et a
développé plusieurs DSMLs pour leurs clients.
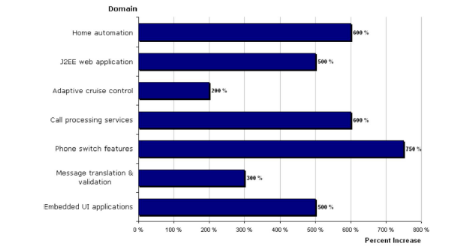
Figure 29 : Retombées économique, Source
MetaCase 2009
Nous avons avec les DSML un time-to-market plus court, un
feedback plus rapide avec les clients, une réduction des coûts (si
répétition + plusieurs variantes). Le nombre de participants au
projet devient potentiellement plus grand donc une réduction des
coûts de formation. David Narraway "Nokia case showed that the domain
knowledge contained in the modeling language produced faster learning curve for
new employees or transferred personnel. Before, a new developer becomes
productive after 6 months. 2 weeks with the DSML".
B. La génération
d'interfaces graphiques
Comme nous l'avons vu dans l'état de l'art il existe de
nombreux éditeurs graphiques se basant sur le drag and drop (glisser et
déposer). Le principe est très simple : nous avons à
disposition une palette qui liste l'ensemble des représentations
graphiques, on choisit l'élément que l'on veut mettre dans la
fenêtre de conception. Pour cela il suffit de sélectionner
l'élément, maintenir enfoncer la souris et le glisser dans la
partie conception. Ainsi nous avons un rendu visuel, et le code associé
généré automatiquement.
Figure 30 : La palette
Pour montrer la simplicité de la manipulation, nous
allons créer une fenêtre de Test. Cette fenêtre demandera
notre âge, proposera un champ pour entrer notre réponse et un
bouton pour la valider.
Nous avons donc trois champs à mettre en place : la
question, le champ de réponse et le bouton de validation. La question
est matérialisée par un Label, le champ de réponse par un
TextFiel et le bouton de validation par un Button. Il suffit simplement de
choisir ces trois éléments et de les glisser sur la fenêtre
de conception.
Il est donc très accessible et très simple de
pouvoir créer une IHM pour un logiciel, sans avoir aucune connaissance
en programmation.
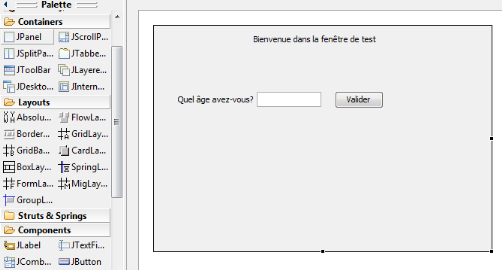
Figure 31 : Un exemple de conception en drag and
drop
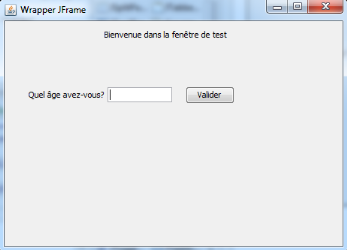
Figure 32 : Résultat lorsque l'on
exécute le programme
2. Les sites web
Comme nous l'avons vu dans l'état de l'art, nous avons
plusieurs moyens de créer des sites web en n'ayant aucune connaissance
en programmation. Nous avons deux grands types de conception : par CMS pour
faire de la gestion de contenu ou par des éditeurs de sites qui vont
nous permettre de créer n'importe quel type de site. Nous avons
parlé également de sites e-commerce, de blogs, de wikis, etc. Je
n'en parlerai volontairement pas dans cette partie car les processus de
conception se rapprochent grandement de ce qui se fait soit pour les CMS soit
pour les éditeurs de sites.
A. Le CMS (Content Management
System, Système de Gestion de Contenu)
Le but d'un CMS est de proposer à l'utilisateur de
pouvoir modifier le contenant et le contenu d'un site Internet sans avoir de
connaissances techniques complexes (HTML, FTP, PHP, etc.). Un CMS va apporter
à l'utilisateur une autonomie, même s'il n'est pas
familiarisé avec la technique. Il va pouvoir également faire de
la maintenance et faire vivre son site.
Un CMS est composé de deux parties : le front office et
le back office.
Concernant la partie front office, le but est d'utiliser
simplement des styles centralisés (couleurs, polices, attributs, etc)
afin de pouvoir modifier à un seul endroit l'aspect
général de toutes les pages de l'application.

Figure 33 : Un exemple d'utilisation du
CMS
Concernant la partie back office (partie étant
réservée à l'utilisateur de manière
sécurisée), elle permet la modification ou la création
d'une page en saisissant son contenu et en affectant les styles aux
différents blocs de textes (paragraphes, mots...) qui composent la page.
Cette action se fait via un outil similaire à un traitement de texte, il
suffit donc de savoir écrire avec un clavier. Il faut simplement
enregistrer la manipulation et le changement apparait en ligne.
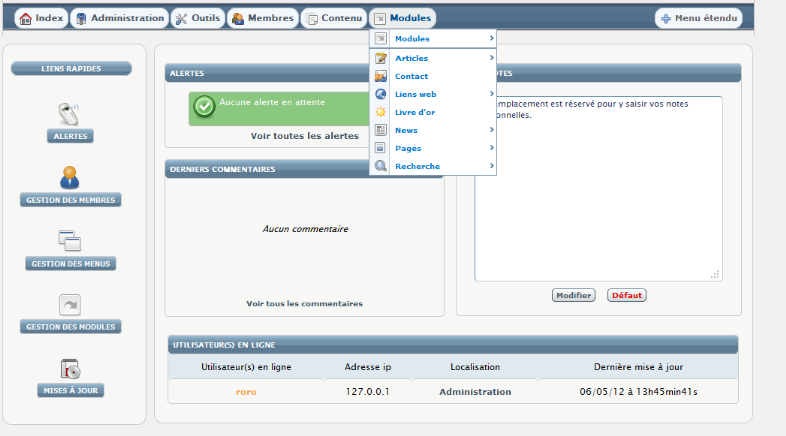
Figure 34 : La partie administration du
CMS
Le CMS est une solution qui permet de gérer de
manière autonome son site sans aucune connaissance en
développement web. Cependant certains CMS ne gèrent que des pages
statiques, il a donc fallu que les CMS intègrent des possibilités
de liberté, pour l'utilisateur, presque infinie tant sur le
côté contenu que contenant.
Pour avoir du contenu dynamique il faut donc une base de
données. Une base de données est le coeur de toute application
(internet ou pas).

Figure 35 : Un exemple de ce qui est stocké
dans la base de données
Les CMS mettent à disposition de l'utilisateur des
pages d'édition permettant de gérer le contenu des tables de la
base de données en modification/création et suppression. La
saisie se fait directement dans l'interface du site.
Le véritable backoffice d'une application internet
consiste à mettre à disposition de l'administrateur, des pages
d'édition permettant de gérer le contenu de leurs bases de
données (tables) en modification, création, suppression, etc. Ce
qui est généralement proposé permet la saisie directement
dans l'interface du site.
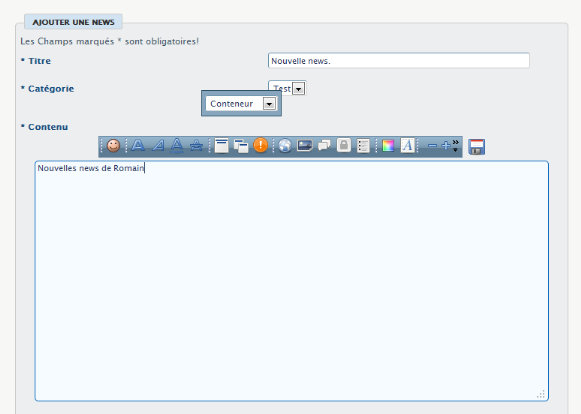
Figure 36 : Saisie directement dans
l'interface
Concernant le contenant (configuration libre de l'affichage,
avec un gabarit dynamique, des styles dynamiques, des menus dynamiques), la
personnalisation va nous permettre d'affecter de nombreux
éléments comme le gabarit général des pages, les
styles de l'application, ainsi que les contenus latéraux, ou encore la
barre supérieure de liens vers les pages principales.
"Avec Joomla, il y une grande possibilité de
création où les articles sont faciles à mettre en pages.
Le petit plus de l'aide en ligne est vraiment appréciable pour une
débutante". Noémie VIANA, lors de la création d'un
site internet dans le cadre de ses études.
B. Les éditeurs de
sites
Beaucoup de solutions online, ou pas, existent sur le
marché qui permettent de réaliser des sites sans coder une seule
ligne de code. Le principe est très proche des CMS mais en beaucoup plus
intuitif. Parmi les sites on peut citer Wix,
Weebly,
Synthasite,
Google Sites,
Sprout ou encore One And One. Ces
éditeurs de sites permettent de créer de manière
très simple des sites internet très sophistiqués.
L'intégration de contenu y est très bien pensée. De la
page web au widget en passant par l'en-tête d'un site, ils permettent,
entre autres de mettre du flash un peu partout.
Ces éditeurs peuvent être très utiles,
surtout pour les auto-entrepreneurs qui souhaitent montrer la vitrine de leurs
prestations mais qui n'ont pas forcément la connaissance pour faire du
développement web ou même les moyens de faire appel aux services
d'un développeur. Pour ces personnes, ce sont d'excellents outils pour
pallier à ce problème.
Suivant les éditeurs on trouve souvent deux
possibilités de conception de site : soit en choisissant un
modèle vierge, soit en choisissant un modèle préexistant
(qui en général sont faits en fonction d'un secteur
d'activité, d'un thème,..). Ils disposent le plus souvent d'un
éditeur drag and drop intuitif où ont lieu toutes les
créations, que ce soit pour le texte, les photos, les cartes ou
même encore les vidéos.
"Ce qui m'a plu avec ce genre de site c'est la
gratuité, la facilité de prise en main, lorsque l'on souhaite
cependant prendre le temps de s'y consacrer. Il y a la possibilité de
prendre un modèle si l'on ne veut pas y consacrer trop de temps ou
d'énergie, ou par manque de confiance en soi dans le domaine
informatique. Mais aussi le choix de créer un site du début
à la fin." Tommy ZIELINSKI, fondateur d' HAJIME FORMATION qui a
créé son site avec wix.fr : http
://www.hajimeformation.com.
Boutons d'édition
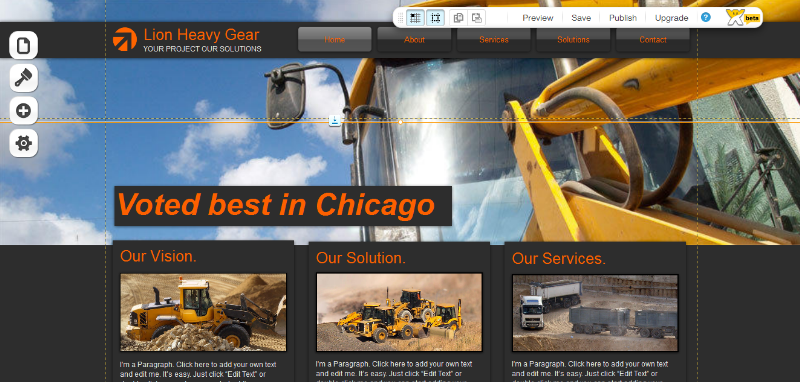
Figure 37 : Un exemple d'éditeur de site avec
des boutons d'édition
On peut glisser et déposer les différents item
sur la page du site
Figure 38 : Un exemple de plateforme online avec du
drag and drop
4. La simplicité
d'utilisation d'une base de données
Comme nous l'avons vu dans l'état de l'art le nombre de
logiciel proposant un SGBD est conséquent. Beaucoup d'entre eux
proposent de créer des bases de données de la plus simple des
manières avec des interfaces intuitives et très pratiques pour
les débutants.
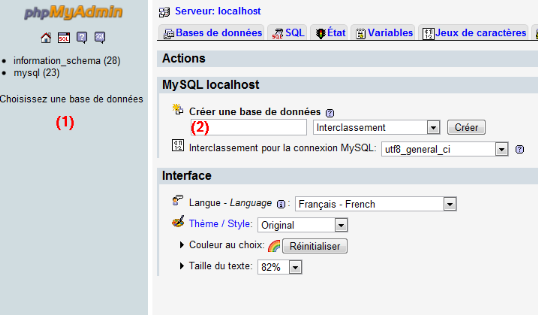
Figure 39 : Une des nombreuse interface des
SGBD
On peut ainsi créer une base très facilement en
lui donnant le nom que l'on veut.
Il y a 2 endroits importants, signalés par des
numéros sur la capture d'écran :
1. Liste des bases : c'est la liste des bases
de données. Le nombre entre parenthèses, c'est le nombre de
tables qu'il y a dans la base.
Sur la capture d'écran ci-dessus, il y a donc 2 bases :
information_schema, qui contient 28 tables, et mysql, qui contient 23
tables.
2. Créer une base : pour créer
une nouvelle base de données, il faut rentrer un nom dans le champ du
formulaire et cliquer sur "Créer".
Nous allons ainsi créer une base Test pour la suite de
la démonstration. Pour toutes
créations/modifications/suppressions le code SQL apparaît, cela
peut permettre aux débutants de commencer à apprendre le SQL, et
aux plus avertis de voir certaines erreurs de syntaxes lorsqu'ils
programment.

Figure 40 : Le code SQL lorsque la table a
été créée
Ainsi nous avons notre base, mais elle est dépourvue de
tables. C'est ce que nous allons faire. Les créations de tables sont
tout aussi simples que la création de bases. En général,
il suffit de cliquer sur le nom de la base afin de se placer à
l'intérieur, et la plupart du temps il est mentionné "Create
Table" ou " Créer une nouvelle table sur la base XXX" (ici Test).
Suivant les SGBD, la création de table peut se faire en plusieurs
étapes : nom de la table, et renseignement du nombre de colonnes et
ensuite spécification de chaque colonne, alors que d'autres peuvent tout
proposer en même temps.
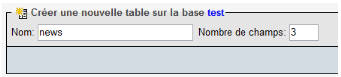
Figure 41 : Création d'une table
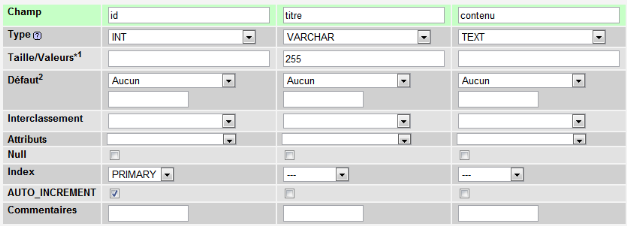
Figure 42 : Spécification des
colonnes
Nous avons ainsi créé une table aussi simplement
que possible sans écrire une seule ligne de code.
Désormais nous avons notre base et notre table, mais
sans donnée cela ne sert à rien. De manière analogue
à la création de table, il faut sélectionner la bonne
base, ainsi que la table dans laquelle nous souhaitons insérer les
données. En général, il est mentionné "create
data" ou "insérer". Ainsi le logiciel va proposer les différents
champs de la table à remplir.
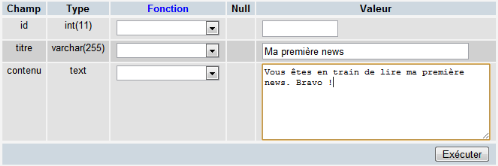
Figure 43 : Remplissage des champs de la
table.
On peut ainsi le faire plusieurs fois de suite, afin d'avoir
plusieurs données dans la table.

Dans cette table, le petit crayon et la croix, suivant les
SGBD, sont des items plus ou moins identiques : Le crayon va permettre de
modifier la ligne correspondante en identifiant les informations à
modifier. C'est la même interface qu'en Figure 43 et les changements
peuvent être faits très facilement ; La croix va quant
à elle permettre de supprimer un enregistrement d'un simple clic.
Une notation analogue est disponible pour les modifications et
suppressions de table.
Autant dire que la gestion d'une base de données est
à la portée de n'importe quel individu.
IV. Nous ne pouvons pas
tous être développeurs
1. Le logiciel
A. Le MDA présente ses
faiblesses
A. La question sur les outils
Pour rappel le but du MDA est de générer presque
automatiquement les modèles PSM depuis les PIM. Mais tout cela n'est
possible que pour quelques rares environnements techniques. En effet, le
problème est que la technologie sous-jacente change très
rapidement et le temps que les mappages automatiques se soient mis en place
pour une plate-forme donnée, la technologie aura changée. De
plus, pour que tout le monde y ait accès, la démarche MDA devrait
être adaptée à plusieurs plates-formes, or ce n'est pas le
cas. Ainsi, un utilisateur qui acquière un outil MDA se limite à
travailler sur certaines plates-formes, donc il n'y aurait pas de plates-formes
hétérogènes.
Chaque éditeur respecte le MDA à sa
manière à l'instar de CORBA 6(*). CORBA est une norme très complète pour
les architectures distribuées, cependant les outils supportant CORBA ne
l'étaient pas autant. Du coup les éditeurs implémentaient
leur propre vision de CORBA, et ainsi les différents ORB7(*) fonctionnaient mal ensemble.
Ainsi ce scénario pourrait se répéter avec le MDA. Les
outils seront différents et le passage d'un modèle d'un outil
à un autre pourrait être délicat malgré le XMI. Par
le passé, les stratégies d'intégration d'outils ont
énormément échoué, il est donc fort possible que
ça se reproduise avec le MDA.
B. Le MDA est trop compliqué
Une vision erronée du MDA est que les
développeurs ont des compétences en modélisation. En
effet, les développeurs créent rarement des diagrammes UML, ne
sachant pas forcément à quoi correspondent les treize diagrammes
UML.
Une approche par les modèles ne permet qu'à peu
de personnes d'avoir les compétences pour modéliser
complètement les systèmes. Le MDA nécessite
forcément l'implication de professionnels de la modélisation,
mais ces personnes sont rares dans les petites structures et chez les
industriels. Du coup on peut vite faire le raccourci : MDA est seulement une
approche destinée aux grands projets. Cette remarque peut nous faire
penser aux similitudes qu'il y a eu avec CORBA, cette norme qui était
très compliquée à mettre en place, la répartition
des implémentations CORBA a diminué au profit de
procédés plus aisés tels que .net ou J2EE.
C. La distinction des modèles
Le MDA différencie les objets de la plate-forme
à laquelle ils sont rattachés de ceux qui en sont
indépendants. Cependant cette indépendance ne reste qu'un
objectif. Derrière ce concept se cache une vérité bien
plus complexe. On peut se demander où se trouve la limites entre les
modèles ? L'OMG n'a pas donné de définition du terme
plate-forme, ainsi la limite qui sépare les modèles PIM et PSM
n'est pas franche tant que la définition n'est pas
spécifiée. Pour le moment, comme nous l'avons vu dans
l'état de l'art, la seule définition c'est qu'un PIM n'est pas un
PSM, même si l'idée de PDM aide à affiner cette
définition. Cependant, bien que CIM soit apparue, l'objectif reste quand
même, au travers de mise en oeuvre (en cas de logique métier
conservée), d'identifier ce qui est stable. Les progrès du MDA ne
permettent pas à tout le monde de l'utiliser car son utilisation est
très souvent destinée à la recherche et aux
sociétés impliquées dans la définition de cette
norme
B. Le DSML et ses limites
Bien que les DSML offrent des gains en terme de
sûreté et d'expressivité, leur développement n'est
pas si aisé. Leur implémentation exige une forte connaissance du
domaine auquel ils appartiennent mais également une expertise dans le
développement de langage. Avoir cette double compétence est
très rare. Développer un DMSL est donc souvent mis de
côté dans les entreprises et les projets de développement
de DSML restent souvent à l'étape d'une librairie. De
manières analogues, il existe d'autres entraves à l'utilisation
de DSML comme le coût de développement, la définition du
domaine et les propriétés du langage.
A. Coût de développement
Prouver la rentabilité d'un développement DSML
est difficile, car il faudrait pouvoir comparer le travail
réalisé avec un langage généraliste et cela peut
vite être très onéreux. (Herndon & Berzins, 1988),
(Batory, Thomas, & Sirkin, 1994), (Gray & Karsai., 2003) ont
montré que les DSML généraient quand même des
bénéfices mais que ceci restaient très difficile à
démontrer.
B. Problèmes liés au domaine
Comme nous l'avons vu, la définition d'un DSML n'est
pas simple. En faisant une analogie avec les DSL7(*) et plus particulièrement COBOL8(*) (dont certains pensent qu'il est
fait pour les applications commerciales alors que d'autres pensent qu'il rend
flou la notion de domaine d'application), il apparaît ainsi que la
particularité du domaine est simplement une question de degré.
(Van Deursen, Klint & Visser, 2000) montrent que l'ambiguïté
des DSML provient de l'imprécision de la définition des domaines.
Certains définissent les DSML comme un ensemble de systèmes, ce
qui sous entend qu'un domaine est réduit aux programmes qu'il contient.
Cette idée est très réductrice car les intervenants et
leurs besoins peuvent entrer dans la définition des domaines.
(Wile, 2004) a fait une étude sur l'introduction des
DSML sur une communauté d'utilisateurs. En se basant sur des
réalisations concrètes il démontre trois types de soucis
dans la conception, le développement et l'adoption du DSML :
technologique, organisationnel et social. Le rôle organisationnel des
personnes qui utiliseront ce langage apparait très important tout comme
leur expérience. En effet, ces deux points participent à la
définition du domaine et a donc une incidence sur la conception du
langage. Et pourtant les utilisateurs sont souvent délaissés
lorsque l'on parle de DSML. Le langage et les besoins de l'entreprise sont donc
en inadéquation, et il y a donc une difficulté de mise en place
de cette approche dans le processus de développement.
Parfois, il peut être avantageux d'avoir
différents DSML pour différents utilisateurs (un pour les novices
et un pour les experts par exemple) pour spécifier un aspect
isolé de l'application. Cette orientation pose la difficulté
centrale de la composition DMSL au sein d'un domaine, qui est aujourd'hui un
thème de recherche autour des DSML.
C. Propriétés du langage
Une autre source de problème est le langage
lui-même, surtout en cas de maintenance de d'évolutivité du
langage. (Van Deursen & Klint, Little Languages : Little Maintenance, 1998)
considèrent que l'évolutivité du langage et la maintenance
sont des points faibles de l'approche DSML. Concernant
l'évolutivité du langage, on peut avoir, par exemple, une
nouvelle fonction ou un nouveau type de donnée. Pour avoir cela il
faudrait donc adapter le compilateur et c'est une compétence qui peut ne
pas être présente au sein d'une entreprise ou d'un particulier.
Mais le point le plus important contre l'utilisation des DSML
est l'effet "Tour de Babel". Quand les développeurs programment leurs
propres langages, la confusion est très vite totale. La solution
pourrait être de développer de nouveaux langages pour tous les
domaines, mais cette idée poserait vite des problèmes
d'interopérabilité et de réutilisation d'infrastructures
et/ou d'outils.
C. L'UML
A. Les limites
L'UML est devenu très complexe et trop large car on ne
veut pas tout utiliser dans UML (notamment les diagrammes) et parce que les
liens entre les vues ne sont pas toujours évidentes. En utilisant l'UML
on utilise un concept qui est proche de la technologie d'implémentation
(i.e. OO avec classes, interfaces, héritages, etc) alors qu'avec les
DMSL on est déjà plus proche du domaine métier (i.e.
Formulaire, Client, connecteur, communication, message, etc.). Par
définition, un non initié sera plus à l'aise sur un sujet
qu'il désire travailler ou qu'il "maitrise" plutôt que de
travailler sur un outil qui dépend d'une technologie
d'implémentation. De plus, avec l'UML il est vraiment très
difficile d'atteindre les 100% de code généré à
partir des modèles UML. Il y a un peu une relation de causes à
effets avec le fait qu'UML n'arrive pas à s'imposer.
B. L'UML peine à s'imposer
Aujourd'hui l'enthousiasme qu'a suscité UML à
son commencement s'est vite heurté aux réalités
industrielles. Due notamment aux rachats des principaux offreurs d'outils UML
par IBM. Cela a conduit à en réduire considérablement le
nombre, et a fait d'IBM le principal fournisseur d'outils UML. Malgré
cela on trouve quand même d'autres fournisseurs comme Atego (suite
d'outils Artisan) ou encore No Magic (outils simples et complets), mais qui
restent des "poids plumes" comparés au géant.
Un autre signe de faiblesse d'UML est qu'il existe très
peu de grands projets open source susceptibles de rassembler une très
grande communauté de développeurs autour d'UML comme avec GNU par
exemple. Bien sûr comme nous l'avons vu dans l'état de l'art, il
existe plusieurs outils UML open source, mais la majorité d'entre eux
sont de simples modeleurs graphiques qui ne proposent pas tous les diagrammes
UML du standard. Malgré tout on peut quand même citer le projet
Papyrus dont le but est de proposer un outil industriel complet de MBE (Model
Based Engineering), avec Eclipse, avec une notion de modèles qui est
centrale, respectant le standard UML.
C. Ce n'est pas innée
Navigabilité mono directionnelle
Héritage
Comme nous l'avons vu dans la Partie 1, pouvoir
générer du code grâce aux diagrammes UML, nécessite
un processus à suivre. La première action à faire,
après la lecture d'un cahier des charges, c'est d'élaborer les
cas d'utilisation et par la suite le diagramme de classe. Bien qu'il ne soit
pas facile d'élaborer un diagramme d'utilisation on peut quand
même concevoir que sa conception soit à la portée de tout
le monde. En revanche la conception d'un diagramme de classes est d'une tout
autre nature. En effet, un diagramme de classes est composé de plusieurs
items. Il est composé de classes, et une classe se définit par
son nom, ses attributs et ses méthodes. Demander à quelqu'un de
concevoir les attributs et les méthodes d'une classe, c'est comme si on
lui parlait une langue inconnue. De plus, pour faire un diagramme de classes,
il faut mettre des relations entre les classes Comment expliquer à un
non initié que les deux flèches suivantes ne veulent pas dire la
même chose, et que les différencier est ô combien important
?


Ces deux flèches ne sont qu'une petite partie de la
subtilité que pose la navigabilité dans les diagrammes de
classes.
Mais admettons qu'un utilisateur de base arrive à se
dépatouiller comment faire un diagramme de classes cohérent et
robuste Il n'aura dans ce cas que le corps des méthodes, et il lui faut
continuer avec un diagramme de séquences et d'activités. Dans ces
deux diagrammes, en plus des symboles qu'il faut connaitre et qui sont aussi
subtiles que les relations des diagrammes de classes, il faut avoir des
connaissances sur la boucle if-then-else pour pouvoir différencier et
pouvoir traiter les différents cas possibles Il faut donc des
connaissances sur les réactions du système, d'où des
connaissances en informatique solides. On ne peut pas faire de l'UML dans le
but de générer du code pour une application robuste sans
connaissance en informatique. Et même pour un développeur, une
formation en modélisation est primordiale pour pouvoir assimiler les
diagrammes, les symboles et toutes les subtilités que la
modélisation présente.
D. Les éditeurs
graphiques WYSIWYG et leurs limites
Bien que l'approche WYSIWYG soit séduisante, simple et
agréable pour l'utilisateur de base qui l'utilise, elle présente
quand même certaines faiblesses.
· Le WYSIWIG est destiné à un et un seul
support majeur (une seule mise en forme).
· Tout est "vu" avec le WYSIWYG, on a un seul contenu
monolithique : il n'est pas possible de faire un contenu dynamique en fonction
des options que l'on peut choisir sur l'interface. Comme la traduction du
WYSIWYG le désigne ("ce que tu vois c'est ce que tu obtiens"), on a un
contenu statique.
· Dans les interfaces graphiques, on doit souvent mettre
des informations non publiées telles que des commentaires, des
méta données, etc. Ceci est très difficile à faire
avec un éditeur graphique malgré certaines solutions mais qui
restent très limitées, peu ergonomiques et destinées
à des usages prédéfinis (fenêtres de
propriétés, bulle de commentaires, etc).
· Le WYSIWYG favorise le résultat final de la
partie graphique, on privilégie donc la forme plutôt que la
structuration du contenu.
· Avec les éditeurs graphiques, l'utilisateur va
s'occuper de la forme pour avoir un résultat final plaisant. Cependant,
on connait la surcharge cognitive et la perte de temps que cela entraine, il
faudrait donc un WYSIWYG pauvre mais du coup il n'aurait pas la même
finalité pour avoir un rendu ergonomique.
· Bien que parfois les éditeurs soient lents, ils
ne pénalisent pas pour autant le développement. Dans ces
éditeurs il manque souvent quelques objets graphiques, et quand bien
même ils sont présents toutes les caractéristiques d'un
objet ne s'affichent pas forcément. Il est donc nécessaire de
faire des modifications dans le code.
· Si on reprend notre exemple de la partie 1 (l'IHM qui
nous demande notre âge), on a une interface simple qui a mis en forme ce
qu'on lui demandait, mais il y a aucun traitement de l'information. Que se
passe-t-il lorsqu'on appuie sur le bouton valider ? Si on rentre une chaine de
caractères, que se passe-t'il? Ce sont des problèmes qu'un
éditeur graphique ne peut pas gérer. Pour régler ces
problématiques il faut avoir des connaissances en programmation et aller
coder les différents évènements nécessaires aux
endroits adéquats.
· Quand j'ai voulu reprendre un projet existant
utilisant des IHM, il m'est souvent arrivé, lorsque je lançais
l'éditeur graphique, que ce dernier ne reconnaisse pas les objets et
affiche une erreur. C'est aussi une limite avec les éditeurs
graphiques : dès que l'on passe d'un éditeur à
l'autre les formes ne sont pas forcements reconnues.
En conclusion, l'éditeur graphique WYSIWYG peut
permettre à n'importe qui de faire de jolies fenêtres,
ergonomiques, etc. Mais s'il faut le rendre fonctionnel, il est
impératif d'avoir des connaissances en programmation dans le langage
dédié, sinon la fenêtre ne restera qu'une fenêtre
inexploitable. L'éditeur graphique WYSIWYG est en revanche très
utile pour les développeurs désirant gagner du temps à
coder une IHM sans faire un travail rébarbatif.
2. Les sites web
A. Les limites des CMS
A. Les limites posées par l'hébergeur
Si on veut utiliser un CMS pour gérer un site web il
faut être vigilant sur l'hébergeur. En effet, beaucoup
d'hébergeurs ne tolèrent pas les scripts PHP qui sont utiles au
fonctionnement des CMS (SPIP chez Free).
B. Pas de catalogue de bibliothèque chez les
CMS
Les CMS ne savent pas gérer un catalogue de
bibliothèque en ligne. Même si certains modules permettent aux CMS
de gérer un annuaire de sites, les catalogues ne peuvent être
réalisés avec un CMS.
C. Connaissances et assistance technique
Si nous n'avons aucune connaissance en programmation et
graphisme, la modification des graphismes, templates, modèles ou encore
squelette ne peut être possible sur le CMS. Le site ainsi obtenu n'est
pas personnalisé et laissé à l'affichage par
défaut. Les CMS sont très proches les uns des autres (en se
présentant généralement sous trois colonnes) ce qui
paradoxalement rend la prise en main difficile.
D. Longévité d'un CMS et taille de la
communauté
C'est le succès et la taille des communautés
utilisatrices d'open source qui conditionnent la longévité d'un
CMS.
E. Compétence
La majorité des critiques que l'on peut faire envers
les CMS sont généralement dues à une absence de
compétences dans le domaine technique au sein d'une entreprise qui
choisit d'administrer son site par un CMS. Par exemple, les termes workflow ou
templates ne sont pas des mots du quotidien mais ils doivent être
maîtrisés avec le CMS. De plus, avec un CMS, il faut
définir quels sont les objectifs de communication que l'on veut mettre
en place sur le site, et déterminer les rôles des responsables des
sites.
B. Les faiblesses des
éditeurs de site web
Avec ces éditeurs, ces sites sont vite limités
malgré leur simplicité d'utilisation. De plus, certains rendus ne
sont pas très plaisants. Les mises à jour ne sont pas toujours
dynamiques et il faut très souvent modifier chaque page manuellement
pour modifier le site. La conception de nos sites web reste très
limitée et décevante, et comparée à des sites qui
sont codés à la main elle reste vraiment très banale.
"Difficulté à associer son nom de domaine.
Site web flash, c'est le terme je crois, donc pas facile pour le
référencement, et pas facile aussi pour lire sur les tablettes ou
smartphones.
Mise en page approximative, ou qui change (décalage de
la page vers la droite dans mon cas)." Tommy ZIELINSKI, fondateur d'
HAJIME FORMATION qui a créé son site avec wix.fr.
www.hajimeformation.com.
3. La construction d'une
base de données nécessite un apprentissage
Bien que nous ayons vu dans la première partie du
développement que la création d'une base de données reste
assez simple via seulement quelques clics, ce n'est pas le cas s'il faut une
base de données robuste, optimisée et sécurisée.
A. Un processus de conception
à assimiler
Les bases de données sont organisées en tables
composées de colonnes et de lignes. Très souvent, voire quasiment
tout le temps, nous avons besoin de plusieurs tables. Par exemple une table
pour les produits, une pour les commandes et une autre pour les clients.
A la construction des tables dans le SGBD on peut rencontrer
deux types de problèmes :
· Où placer certaines informations? (par exemple
une adresse de livraison faut-il la mettre dans la table commande ou dans la
table client ?)
· Prévoir des tables de jonctions
intermédiaires (une table des interprétations est
nécessaire entre la table film et la table acteur).
Il faut donc passer par une étape préalable de
conception. Ce processus se décompose ainsi :
· Définir les objectifs de la base de
données : cette étape aide à préparer les
étapes suivantes.
· Recherche et organisation des informations
nécessaires : on réunit tous les types de données que l'on
souhaite stocker.
· Répartition des informations dans les tables :
on répartit les informations en entités ou sujets. Les sujets
seront des tables
· Conversion des éléments en colonnes :
choix des informations à stocker dans la table.
· Définition des clés primaires : afin
d'identifier de manière unique chaque enregistrement de la table.
· Définition des relations entre les tables :
permet de montrer de quelle manière les données d'une table sont
reliées à celles d'une autre.
· Affinassions de la structure : pour analyser la
conception et faire de la recherche d'erreur
· Application des règles de normalisation : pour
vérifier si les tables sont bien structurées, et
éventuellement apporter des modifications.
L'étape de conception est donc importante et n'est pas
à la portée de tout le monde, cela nécessite donc un
apprentissage. Sans connaissance on ne peut pas passer par cette étape
qui est vraiment très importante.
B. La
sécurité
Après avoir créé sa base de
données, on oublie souvent une partie fondamentale qui est la
sécurité. Les bases de données sont situées sur des
serveurs ce qui implique de faire un requêtage en passant par un
réseau. Qui dit réseau dit forcément risque.
"Le risque majeur pour les entreprises en termes d'attaque
est l'injection de code SQL", rappelle ainsi Jean-Paul Ballerini, expert
technique pour IBM ISS.
"Ce peut aussi être un moyen, en maitrisant le SGBD,
de prendre la main sur le système d'exploitation et de créer des
comptes avec des droits administrateur afin de se connecter ensuite
directement. Les vulnérabilités ne sont pas seulement au niveau
de l'applicatif, mais aussi de l'OS", poursuit-il. Il faut donc qu'une
base de données soit sécurisée, et pour cela il faut :
A. Connaitre son besoin
La sécurité d'une BDD passe par une
réflexion sur comment et qui va l'utiliser et par quel moyen de
connexion (directement ou pas un applicatif). Il est très important de
faire un état des lieux afin de mettre en place la politique de
sécurité la plus adaptée.
"La connexion d'un SGBD avec un progiciel, qui
nécessite une méthode d'interconnexion spécifique, peut
avoir pour effet d'abaisser le niveau de sécurité. Les
équipes sécurité et intégration, dont les missions
ne sont pas forcément en accord, doivent souvent trouver un
accord", Alexis Caurette, consultant pour Devoteam.
La sécurité ce n'est pas simplement de se
prémunir contre d'éventuelles attaques, c'est aussi pouvoir
préserver la confidentialité, la sauvegarde,
l'auditabilité, la traçabilité et
l'intégrité des données. Une politique dépend de ce
que l'on veut garantir et dépend de ce que l'on a identifié.
B . Une sécurité en amont
Une BDD est très souvent une partie d'un projet
beaucoup plus global. Il faut donc penser que la sécurité doit
être faite pour l'ensemble des éléments et surtout s'il y a
utilisation d'un applicatif pour accéder à la base. La BDD peut
être protégée, mais si l'applicatif est vulnérable,
il peut ouvrir des portes et un SGBD ne pourra pas faire de différence
entre une connexion qui est légitime et une qui ne l'est pas (un
attaque par le biais d'un frontal web par exemple).
C. Supervision
Il faut qu'il y ait un suivi des indicateurs de la BDD pour
déceler des anomalies, anticiper une interruption et pouvoir agir
rapidement en cas d'anomalie. La plupart des SGBD ont un système de
supervision, c'est ensuite à l'utilisateur de mettre les filtres
nécessaires.
D. Sensibiliser les DBA (DataBase Administrator,
administrateur de la base de données)
La performance ne doit pas être le seul souci du DBA, il
faut aussi qu'il soit sensible à la sécurité, aux risques
et à la criticité des contenus. En effet, un DBA peut être
amené à surveiller plusieurs bases en même temps et
pourrait ne pas avoir les bons réflexes.
E. Durcir le socle système
Une BDD repose sur une couche système. Il faut donc
durcir fortement la politique de sécurité de la couche
système. En effet, une BDD ne pourra pas se défendre contre un
individu qui aurait des droits administrateur sur un OS. Le durcissement
consiste en une limitation des services(qu'il soit réseau ou
système), la segmentation des droits de chacun, l'application d'une
politique de privilèges et faire une authentification avec des mots de
passe.
F. Renforcer la couche BDD
De manière analogue au système, les correctifs
qui servent pour la sécurité doivent être mis en place pour
les BDD.
"Les éditeurs ont fait des progrès
très significatifs dans ce domaine. Il y a encore 4 ans, avec une
configuration par défaut, le niveau de sécurité
était faible avec l'ouverture de nombreux services et une
authentification minimale. Entre Oracle 8 et 9, puis entre les versions 9 et
10, il y a un véritable fossé en termes de
sécurité", commente Alexis Caurette.
G. Gestion des comptes
Avec les comptes, la politique du privilège doit
être appliquée : si un utilisateur a uniquement besoin de
consulter des données, il ne doit pas avoir des droits en
écriture sur la base.
H. Méthodes d'accès
Une entrée sur la BDD doit être autorisée
selon certaines méthodes. C'est ici que le filtrage se fait. Par
exemple, si une connexion se produit depuis un site web, alors seulement le DBA
et l'application pourront accéder à la base. Par contre, ce
filtrage se complexifie si on intègre la base avec un PGI (Progiciel de
Gestion Intégré) ou un client lourd présent sur plusieurs
postes. Après le filtrage il y a l'intervention des gestions de profils,
des gestions des utilisateurs et de la gestion d'évolution des droits.
On dresse ainsi une cartographie des données et des habilitations afin
de pouvoir définir les populations accédant à la BDD et de
pouvoir définir aussi quelles parties sont autorisées à
accéder.
I. Chiffrer les flux de données
Les réponses aux requêtes doivent être
cryptées lorsqu'elles circulent sur le réseau. Pour cela il faut
écouter le trafic réseau, les flux seront cryptés entre la
base et les composants.
La sécurité des bases de données est
très importante et consistante. Une connaissance accrue en
sécurité et réseau est donc importante, ce qui n'est pas
accessible à tous et nécessite donc un apprentissage. Sans
connaissance, on ne peut pas passer par cette étape qui est vraiment
très importante.
C. Un vocabulaire à
connaitre et un apprentissage à faire
La conception d'une BDD va nécessiter au
préalable la conception d'un MCD9(*). Pour faire une analogie avec l'UML, c'est comme un
diagramme de classes mais qui représente les tables de la base. Donc
d'une manière analogue à l'UML, cette modélisation n'est
pas innée, il faut tout un apprentissage car la conception d'un MCD
n'est pas du tout intuitive. Un MCD fait intervenir énormément de
vocabulaire technique qui est très important dans la conception d'une
base de données. Un exemple : il est indispensable d'avoir dans une
base de données la clef primaire10(*), et très peu de personnes non initiées
à la conception des BDD, pourraient en donner la définition. On
pourrait également citer les clefs étrangères11(*) quasiment toutes aussi
importantes pour la structure de la base et dont un non initié
ignorerait l'existence en cas de conception. Mais aussi, un peu comme avec UML,
les relations entre les tables, les cardinalités, les identifiants,
etc.
Bien qu'il existe des SGBD intuitifs et faciles d'utilisation,
ils permettront seulement de créer de simples tables à priori qui
n'auraient pas de relations entre elles alors qu'elles le devraient. Si on
désire concevoir une base de données robuste et
sécurisée, il est indispensable d'avoir des connaissances
techniques dans la gestion des BDD.
V. Et Demain?
1. Des développeurs
basiques?
Nous avons vu que pour créer une application robuste,
viable, pérenne et sécurisée il faut une bonne
connaissance métier et un apprentissage sur certaines bases (voire plus)
de la programmation. Il faut également que le programme soit de
qualité avec une complémentarité des
fonctionnalités, une précision des résultats, fiable,
minimisant les pannes, facilité et flexibilité de son utilisation
(cette liste est bien sur non exhaustive). Cependant, pour faire des
créations d'applications, de sites web, de bases de données,
d'interfaces graphiques simplistes c'est à ce jour, à la
portée de n'importe quel individu. Il peut à sa guise faire son
programme par l'intermédiaire de diagrammes, faire son site par
l'intermédiaire de différentes applications, sa base de
données en seulement quelques clics et son interface à coup de
glisser-déposer. Si on entend alors développeur dans son sens le
plus simpliste du terme alors oui demain nous serons tous développeurs,
et nous pouvons même dire que c'est déjà le cas.
Mais le ferons-nous vraiment tous ? C'est pour cela que j'ai
décidé d'aller un peu plus loin dans l'analyse.
2. Tous développeurs
Web?
Aujourd'hui chacun de nous peut être développeur
web dans le sens où, en passant par des CMS et des plate-formes online,
les sites peuvent se faire via de simples glisser-déposer sur une
fenêtre d'édition ou de simples clics de souris. La
possibilité de créer un site web sans aucune connaissance en
programmation est déjà aujourd'hui d'une très grande
facilité, malgré l'existence de certaines limites que nous avons
pu voir dans la deuxième partie de ce mémoire. Mais vu le
développement du web depuis le début des années 2000, on
peut se demander si le sens de développeur aura un autre sens demain.
A. Des nouveaux
développeurs Web
Un tournant dans l'histoire du web a été
marqué en 2001 avec l'explosion de la bulle internet. Les gens pensaient
à ce moment là que le web était une technologie
surévaluée alors qu'en fait non. De plus, l'histoire a
montré que lorsqu'une bulle se forme et éclate par la suite cela
annonce une révolution industrielle. Cela se caractérise
même au moment où une technologie en pleine expansion est
prête à entrer dans une nouvelle phase. C'est aussi à ce
moment, que les prétendants arrivent à bout de souffle alors que
les points forts de la technologie en question pointent le bout de leur nez, et
c'est à partir de ce moment que l'on commence à voir ce qui
distingue l'un de l'autre. C'est ce qui s'est passé pour le web.
Le concept de "web 2.0" a vu le jour lors d'un brainstorming
entre O'Reilly et Medialive International. C'est Dale Dougherty (membre
d'O'Reilly et pionner du web) qui a noté que le web n'avait jamais eu
aussi d'importance car il apparaissait de nouveaux sites et de nouvelles
applications avec des innovations sans précédentes de
manière très régulière.
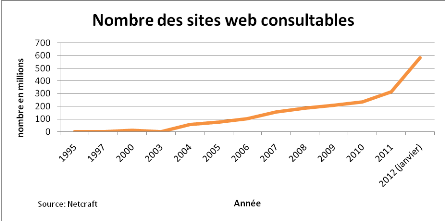
Figure 44 : Evolution du nombre de site consultable
depuis 1995
A la fin de ce brainstorming on a différencié
les sites et services dits "web 1.0" de ceux du "web 2.0". Par exemple, les
sites personnels sont devenus les blogs et un équivalent de mp3.com est
Napster. La différence ne s'est pas non plus arrêtée aux
simples sites mais aussi aux grandes familles de services liées au web.
Par exemple la spéculation des noms de domaines a laissé place au
référencement, les systèmes de gestion de contenu au wiki
(popularisé par Wikipédia), etc.
Le concept de web 2.0 concerne deux aspects : l'un technique
et l'autre orienté vers la communication et le partage :
· Au niveau technique cela correspond aux interfaces
enrichies avec notamment AJAX, Flash, etc, afin d'avoir une interface simple
à utiliser et ergonomique.
· Au niveau communication cela correspond aux partages et
à la diffusion d'information via les portails communautaires, les blogs,
RSS, etc. Avec le Web 2.0 on a une volonté de mettre l'utilisateur au
coeur du processus pour qu'ils devienne acteur.
Le web 2.0 utilise des technologies existantes et sûres,
ce n'est donc pas une révolution en soi mais plutôt une succession
d'évolutions :
· Structure de l'information des données
à valeur ajoutée : Désormais nous pouvons relier
les informations, partager ou agréger des services et du contenu,
refondre les interfaces,... Tout ceci grâce à un ensemble de
technologies comme le web sémantique qui permet à la machine
d'assimiler le contenu des pages. Ainsi, de part les espaces collaboratifs, il
est possible de personnaliser sa pratique de l'internet et participer, à
sa manière, au développement du web.
· Une interactivité toujours plus
grande : Avec les nouvelles interfaces des sites, les utilisateurs
peuvent avoir accès à de nouvelles fonctionnalités, AJAX
notamment va permettre la fluidité des pages (car lors d'une
modification il ne va pas recharger la page). Il y a également
l'introduction de l'audio et de la vidéo. Le drag and drop devient
possible, c'est un peu comme une navigation à la Windows. En somme, le
nouveau web devient de plus en plus interactif.
· Interopérabilité : Avec
le web 2.0 il y a l'apparition d'architectures plus flexibles. Mais
également des protocoles de communication beaucoup plus ouverts (Web
Services) avec REST et SOAP. L'interopérabilité est
également plus poussée, de même que les interfaces
utilisateurs qui sont nettement améliorées (niveau ergonomique et
sémantique) et permettent une plus grande souplesse d'utilisation.
· Modularité : Les applications
et services que l'on peut trouver sur les différents sites peuvent
être recombinés comme l'on désire avec d'autres
fonctionnalités pour aboutir à de nouvelles applications ou de
nouveaux services : on parle de mashups. Tout ceci est rendu possible
grâce aux web services. Les mashups vont ajouter des couches beaucoup
plus pratiques et fonctionnelles, ainsi l'utilisateur peut consulter
différents services via un portail unique.
· Montée en puissance des applications
bureautique en ligne : L'avenir des applications ne sont plus sur les
postes utilisateurs mais en ligne. En effet, on se dirige de plus en plus vers
des applications online qui pour beaucoup existent déjà
aujourd'hui : comme les outils de gestion de projet, suite bureautique, client
email, etc. On peut également citer dans ce domaine les deux
géants du moment que sont Google Docs de Google et Office Live de
Microsoft. On peut même imaginer d'ici quelques années, la fin des
applications de bureau au profit des applications accessibles de partout et sur
tous les supports, pour avoir plus de mobilité.
· Une mutation perpétuelle de
service : Parlons un peu des versions beta. Les versions beta ne sont
plus une étape vers une version figée. C'est désormais une
version stable d'un service. La mettre en ligne va générer du
"buzz" et, il y aura ainsi des beta testeurs, qui vont permettre de faire
évoluer le service. Ceci est rendu possible grâce aux
comportements des internautes sur cette version beta. C'est ainsi que le
service va évoluer petit à petit pour arriver à une
version robuste et dans l'attente des internautes.
· Une démarche open source à
travers le développement participatif : L'infrastructure du web
repose beaucoup sur des méthodes de production individuelle de l'open
source. Ces méthodes émanent de l'intelligence collective. On
peut dire que les utilisateurs sont, dans ce nouveau web, des
co-développeurs.
D'après Wikipédia, nous sommes rentrés
dans l'ère du WEB 2.0 en octobre 2004 après la première
conférence Web 2.0. Ceci grâce à O'Reilly, Batelle et
Dougherty. Ils définissent le web 2.0 de la manière suivante :
"The Web as platform data as the driving force network
effects created by an "
architecture
of participation" innovation in assembly of systems and sites
composed by pulling together features from distributed independent developers
(a kind of "open source" development) lightweight business models enabled by
content and service syndication the end of the software adoption cycle ("the
perpetual beta") software above the level of a
single device, leveraging the power
of "
The Long
Tail"
Il est de plus très intéressant de noter que
(toujours dans le même article Wikipedia) : "An earlier usage of the
phrase Web 2.0 was as a synonym for "
Semantic
Web", and indeed, the two concepts complement each other. The
combination of
social
networking [...] with the development of tag-based
folksonomies
and delivered through
blogs and
wikis creates a
natural basis for a semantic environment."
Par ailleurs, Scot Mc Nealy, l'ex PDG de SUN,
déclare le
24 février 2006, à l'occasion des vingt-quatre ans de la
société :
"The biggest industry trend in the IT sector is the move
from the Internet world to the participation age [...] With
regard to the move away from the "Internet age" to the participation
age, in which instant messaging, blogging, e-mail and podcasting are
the norm, McNealy said this move was a good and positive thing and would
enhance all forms of media.".
Nous pouvons faire quelques commentaires de ces
définitions.
La première conférence Web 2.0 a fait
apparaître le terme de "architecture of participation". Elle
décrit particulièrement le processus de développement open
source. Ce terme s'applique également à la création de
contenu (licence "creative commons") et pas seulement aux
programmes.
Lors de cette conférence est également apparu le
terme de « Data-driven». Bien que le terme semble trop
technique, ce n'est pas dans le sens où l'utilisateur manipule la data
mais dans le sens où il manipule un contenu. Si l'utilisateur devait
manipuler la data il ne pourrait rien en faire et ne "participerait pas". Par
exemple, il ne participe pas autour d'une BDD relationnelle de chiffres
statistiques, mais il participe autour du contenu décrivant ces
données.
Concernant le terme "Semantic Web", il est un peu
"surdimensionné". En effet, sémantique signifie sens et qui dit
sens dit interprétation. Or, le web est incapable d'interpréter
le sens du contenu, c'est bien l'utilisateur qui l'interprète. On peut
donc rapprocher sémantic de structuration de données,
comme les billets de blog, les flux RSS ou encore les wikis. On pourrait donc
parler de Structure Web.
Il y est mentionné également le terme de
"participation age" comme les blogs, l'e-mail, les réseaux sociaux, etc.
Le nouveau web c'est donc l'âge de la participation et les
conséquences atteignent nos activités quotidiennes, nos
entreprises et même nos démocraties grâce à l'esprit
participatif de chacun.
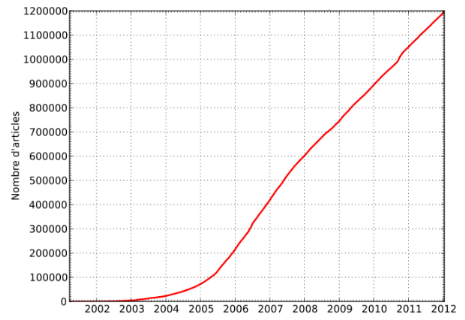
Figure 45 : Evolution du nombre d'article de
Wikipédia en France
B. Développer c'est
partager l'information
Le web 2.0 permet le partage de l'information fondé sur
l'ouverture des BDD permettant d'être utilisées par tout le monde.
Pour le Web 2.0, on parle de "glocalisation12(*)", on peut partager, créer, trouver et
organiser l'information de manière personnelle, et cette information est
globalement accessible.
Ce sont ces utilisateurs de base qui créent les
contenus (flux RSS, échanges de fichier, portails communautaires, blogs,
etc). Le nouvel internaute devient acteur et rédacteur du
développement du web.
Avec ces nouvelles formes de partage qui ont vu le jour, il y
a l'apparition de création de communautés et de réseaux
sociaux. Le web devient partie prenante de la vie d'un citoyen, et plus
seulement comme outil de recherche. Les bouleversements sont déjà
tous là que ce soit au niveau artistique, économique,
communication ou même encore politique.
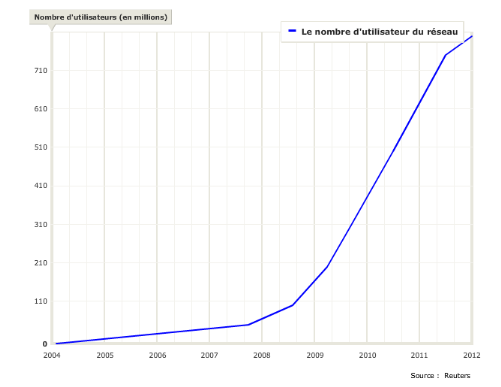
Figure 46 : Evolution du nombre de compte facebook
dans le monde
En 2003, on parlait de web 2.0 pour l'évolution
technologique. Il devait faire évoluer Internet, en mettant
l'utilisateur final au coeur du processus, afin de lui proposer de nouvelles
applications qui lui permettent de personnaliser sa pratique d'Internet. Comme
vu plus haut ce sont les flux RSS (afficher sur une même page des
informations de sources différentes) et les espaces collaboratifs
(Wikipédia, réseaux sociaux) qui sont très en vogue. Avec
l'explosion des blogs au milieu des années 2000, ont
émergé des internautes qui sont devenus acteurs, spectateurs et
commentateurs. Ce n'est pas une démarche commerciale mais bien une
démarche de partage d'idées, de documents, etc. Abraham Lincoln
disait "Gouvernement du peuple par le peuple et pour le peuple", avec
ce nouveau web ça serait "le Web par le peuple, pour le
peuple". Mais tout ceci a été possible grâce à
l'informatique libre et gratuite. Ainsi la triple casquette des nouveaux
utilisateurs web, les rendent capable de créer leur site personnel de
manière autonome
C. Du contenu et du flux
On a l'impression d'être revenu aux années
1993-1995 où l'on chattait en IRC, faisait des rencontres,
échanges de bons procédés, etc. On avait l'impression que
tout cela avait disparu avec le boom commercial d'Internet. Mais les blogs son
apparus et ont permis l'émergence d'une nouvelle communauté
humaine complètement interactive. Par exemple, on pourrait appeler les
réseaux sociaux, des groupes d'intérêts c'est-à-dire
des personnes qui ne se seraient jamais rencontrées dans la vraie vie et
qui partagent, grâce aux accès faciles à l'information,
des intérêts communs.
Nous sommes vraiment donc dans l'ère du contenu,
où l'on subit un flux continuel d'informations. Nous structurons
même notre vie par rapport à lui, ceci à cause de nos
actions tant individuelles que collectives (ces flux provenant d'autres
personnes autour de nous), grâce à nos commentaires, un blog, etc.
On pourrait parler de collaboration. Mais la collaboration se veut
structurée et "travailleuse" (travailler avec d'autres - à
une oeuvre commune, Larousse), or avec ces flux d'informations, qui sont
énormes, il n'est pas possible d'avoir une collaboration
structurée. On est plus dans la participation que la collaboration.
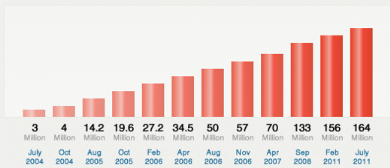
Figure 47 : Augmentation du nombre de blog dans le
monde, source Technoraiti
D. Le Web participatif
Comme nous l'avons dit, les nouvelles communautés du
Web 2.0 sont apparues avec les blogs, réseaux sociaux et wiki.
Désormais, on peut simplement modifier du contenu, commenter,
créer des articles, etc. Cette nouvelle démarche fait
énormément évoluer les relations entre les individus,
où chacun est à la fois acteur, auteur et lecteur. On n'est plus
dans un système collaboratif mais bien participatif.
Pour en arriver là beaucoup d'étapes ont
été franchies. Les outils, les sites Web, les intranets et
même les extranets ont suivi ces évolutions progressivement. On
dénombre cinq étapes :
· Publication
· Interaction
· Echange
· Collaboration
· Participation
Ces étapes sont comme des poupées russes, la
publication étant la plus petite.
Comme nous l'avons dit plus haut le participatif est non
structuré, il est de plus transversal, d'égal à
égal et hétérarchique13(*). Ce qui est paradoxal, c'est que les outils
collaboratifs et structurés ont eu du mal à s'imposer dans les
organisations qui pourtant elles le sont. Peut-être que l'être
humain n'aime pas travailler de manière structurée. Cette non
structuration entraine un petit "chaos" dans les organisations (le trop plein
de fichiers Excel présents sur les réseaux d'entreprises par
exemple). On pourrait alors se demander si c'est une situation immuable. Le
retour d'expérience du web 2.0 et son adoption en grand nombre par les
utilisateurs nous indiquent que non : c'est une évolution
inéluctable.
Nous sommes rentrés dans l'ère du web
participatif. De part son usage il modifie les relations de groupes et, qui
sait peut-être plus tard, il finira par bousculer les relations
hiérarchiques dans notre société. On pourra
peut-être voir l'émergence des forces vives et créatrices
de chacun.
Nous en sommes peut-être à l'étape ultime
du web participatif au niveau organisation et création de valeur. Il
créera peut-être ses propres règles et ses propres usages.
Nous n'en sommes qu'au début, il faut tout construire et peut-être
tout modifier (on parle déjà d'Entreprise 2.0 et de
Démocratie 2.0).
E. On parle déjà
de web 3.0
Internet sera présent partout, c'est le principe de
"cloud computing" (de Rosnay, 2009) c'est-à-dire on ne veut plus de
stockage sur une machine en local mais bien sur un serveur distant. Et des
sociétés commencent à proposer des solutions disponibles
sur le cloud (CBS, 2009). On parlera aussi de web 3.0 pour tous ces objets
qu'on utilise tous les jours et qui risquent fortement d'avoir demain un
accès à internet (réfrigirateur, radio-réveil,etc).
Ce serait un monde où tout se passerai sur le cloud, nos terminaux ne
seront justes que des consommateurs de service.
On peut donc considérer que le développeur Web
de demain peut avoir une tout autre signification que celui qu'il a
actuellement. Vu que désormais chaque utilisateur peut modifier à
sa convenance son site, participer aux partages de l'information, la
création de communauté, c'est peut-être ça le Web du
futur où chacun y sera à sa manière développeur.
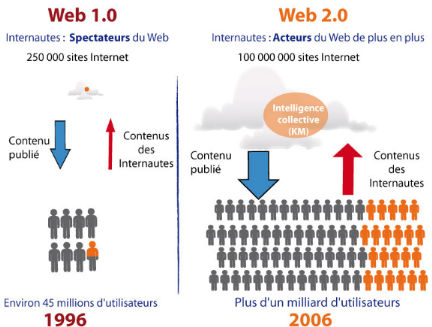
Figure 48 : Les internautes du web deviennent
acteurs
3. Tous développeurs
de logiciels?
Nous avons pu voir que si nous voulons être tous
développeurs d'applications, il faut passer par de la
génération de code et de la modélisation. Qui dit
modélisation dit ingénierie dirigée par les modèles
(IDM). Nous avons quasiment notre réponse dans le nom de ce concept. Il
fait intervenir le mot ingénierie, qui est, on le rappelle, l'art de
l'ingénieur. Etre ingénieur ce n'est pas innée, cela
s'apprend, donc de part ce premier point nous ne serons pas tous
développeurs de logiciels.
Si l'on souhaite quand même s'approprier l'IDM, nous
avons deux approches (comme déjà vu) : le MDA et le DSML.
Concernant le MDA il présente plusieurs
problèmes, notamment le changement de plates-formes, comment fera un non
initié s'il doit changer de plate-forme ? De plus, nous avons vu que le
MDA utilisait l'UML pour le langage de modélisation. Or, UML
nécessite un processus très strict si l'on veut
générer du code utile et fonctionnel. L'UML est un langage
à part entière et comme tout langage (que ce soit écrit ou
parlé) il faut un apprentissage pour l'utiliser et le comprendre. Une
approche par les modèles ne permet qu'à peu de personnes d'avoir
les compétences pour modéliser complètement les
systèmes. Il nécessite forcément l'implication de
professionnels.
Le DSML quant à lui implique une forte connaissance du
domaine auquel il appartient mais surtout une expertise dans le
développement de langage. Comme pour l'IDM, qui dit expert dit une
petite partie des gens concernés.
Pour faire un logiciel, il y a aussi toute la partie interface
utilisateur à créer. Comme nous l'avons vu, il est bien sûr
très simple de les créer, cela peut donner un rendu satisfaisant
au premier regard. En revanche, sans connaissance en programmation, il est
impossible de le rendre fonctionnel. Malgré certains outils, comme
Windev, qui vont proposer des options selon les modèles graphiques que
nous mettons en place, mais il est impossible d'avoir toutes les
possibilités.
Bien que l'on tende justement vers des outils de ce calibre
à l'avenir, il est encore prématuré de dire si un outil
pourra exister de façon simple, et qui proposera en plus de
l'éditeur graphique, de pouvoir faire un logiciel pouvant
répondre à différentes attentes (de l'utilisateur final).
En revanche, avec l'apparition SaaS (Software as a Service) et du
Cloud-Computing qui voient désormais le logiciel comme un service en
ligne et non plus comme une application de bureau, on peut très bien
imaginer un développement collaboratif et participatif, comme ce que
l'on a vu pour les sites web. Chacun pourrait apporter sa pierre à
l'édifice et participer ainsi au développement de ces nouveaux
logiciels qui risquent très fortement de se développer d'ici
quelques années. Il ne faudrait surtout pas non plus oublié que
l'on soit dans un monde hyper connecté si l'on veut être tous
développeurs. Avoir les outils qu'il faut pour l'être c'est bien
mais il faut également avoir les moyens.
4. L'hyper
connectivité
Nous avons montré ce qu'il faudrait pour être
développeur. Mais maintenant interrogeons-nous sur comment on peut
l'être TOUS. Bien sûr, exit tous les programmes techniques qui vont
nous permettre de développer. Il faut quelque chose de simple et
inéluctable, et je pense que le monde hyper connecté vers lequel
on se dirige va nous permettre cela. Selon une étude du cabinet Gartner
14(*)(publiée le 11
août 2011) il a été vendu 429 millions de
téléphones portables dans le monde lors du deuxième
trimestre de cette même année. Les ventes mobiles enregistrent une
hausse de 16.5% alors que la vente de smartphones connaît une croissance
de 74%. Duncan Stewart, Directeur de Deloitte Research, Centre de
recherches mondial du cabinet Deloitte15(*) nous explique que "l'augmentation du nombre de
ménages possédant plusieurs tablettes a été
phénoménal. Il a fallu plusieurs
décennies avant que plus de 5% des ménages possèdent plus
d'un téléphone, d'une voiture, d'une radio ou d'un
téléviseur. Dans le cas des ordinateurs personnels et des
téléphones cellulaires, il a fallu attendre plus de 10 ans.
Pour les tablettes, on attendra moins de trois ans." D'après le
cabinet DisplaySearch il y a eu 72,7 millions de tablettes vendus dans le monde
en 2011 (+256% par rapport à 2010), soit 3 fois plus que les netbooks et
talonnant les PC portables (187 millions). Ceci nous montre bien que ces objets
portatifs vont gagner en nombre et en personnes les possédants. Ainsi
à terme, il est fort probable que chacun de nous en possède et
puisse participer, de manière quasiment inconsciente (car ces objets
vont rentrés dans les moeurs), au développement participatif
auquel on faisait référence plus haut.
5. L'histoire nous dis que
oui?
Pour rappel, la programmation informatique a commencé
dans les années 1950, où les programmes informatiques
étaient des inscriptions sur des cartes en carton perforé. La
programmation consistait à percer des trous dans le carton. En 1970,
c'est l'apparition de la programmation structurée qui a simplifié
le travail des programmeurs et qui a permis la création de programmes
traitant un plus grand nombre de tâches tout en étant beaucoup
plus complexe. L'apparition des IHM, entre 1980 et 1990, a complètement
démocratisé le développement d'applications qui n'est
désormais plus réservé aux professionnels mais
également aux personnes n'ayant que peu de formation.
Comme nous l'avons vu le développeur de nos jours est
beaucoup plus multi tâches qu'avant. Il ne va pas seulement se
spécifier que dans la création de code, il peut faire partie d'un
aspect beaucoup plus fonctionnel. Il n'a pas qu'un seul domaine de
compétence et pas non plus qu'un seul domaine technique. Le
développeur est aujourd'hui un homme avec plusieurs cordes à son
arc aussi variées que possible.
Avec le recul nous voyons bien que sur des cycles de 20 ans,
le métier de développeur change du tout au tout. Il faut
s'attendre à ce qu'à l'horizon de 2030, le métier de
développeur évolue encore énormément. On commence
déjà à ressentir les prémices de ce
changement : les projets sont de taille de plus en plus importante, et
nécessitent donc d'avoir des personnes qui collaborent en fonction de
leur spécialisation. De plus en plus, le développeur doit
comprendre les besoins, le business et le contexte du client. Il n'est plus
uniquement un "faiseur de code", le métier qui consiste à
simplement écrire que du code est destiné à disparaitre,
et d'autant plus que, comme nous l'avons vu, des outils et interfaces
d'automatisation peuvent fortement l'aider dans l'aspect technique.
Le développeur du futur devra donc avoir des
compétences en communication, des capacités d'écoute et de
synthèse et se préoccuper de la facilité de l'utilisation
du programme. De plus, l'univers sera de plus en plus mondialisé, et
la programmation y sera proche du langage naturel, les outils de
développement conviviaux et simples à utiliser.
6. Est-ce que ça
apporterait quelque chose?
C'est une question assez importante que l'on pose ici. En
effet, se demander si demain nous serons tous développeurs peut paraitre
justifier, on peut également se demander si ça pourrait servir
à quelque chose. Si on admet que chacun sera développeur demain,
une chose est sure c'est qu'il ne le sera pas à 100% de son temps.
Effectivement, quelqu'un qui développe pendant 100% de son temps
ça sous-entend qu'il délaisse son domaine dans la
société à laquelle il appartient. Chaque entreprise serait
alors une unique DSI, ce qui n'est vraiment pas envisageable. Par contre,
quelle entreprise n'a pas connu une personne de la comptabilité, des
ressources humaines, de QHSE,... n'arrivant pas à remonter des
données et demandant au service informatique un coup de main pour
l'aider ? Cela arrive quotidiennement dans chaque société. Dans
le futur on pourrait imaginer que, par le biais de nos outils, ses demandes
n'existeraient plus car chacun serait capable de résoudre ces
problèmes. On pourrait même imaginer qu'en fin de projet,
où les délais sont très court, un transfert de ressources
(vers la DSI) au sein de l'entreprise, soit fait afin de clôturer le
projet dans les délais prévus.
Mais en essayant de rester dans un cadre assez
réaliste, il est possible que le terme "développeur" ait un
nouveau sens d'ici quelques années puisque désormais chaque
utilisateur peut modifier à sa convenance son site, participer aux
partages de l'information, créer des communautés, etc. Et pour
pouvoir continuer ce partage et cette évolution chaque internaute sera
utile et chacun apportera à sa manière son savoir. Ce serait une
espèce d'intelligence collective où chacun apporte à sa
manière sa plus value.
En revanche, il est vrai que si on entend développeur
dans le même sens qu'aujourd'hui, il est difficile de penser que le fait
d'être tous développeurs soit possible et apporte vraiment quelque
chose à l'avenir. Notre environnement et nos technologies
évoluent, il faut que notre vocabulaire évolue avec lui.
7. Et les bases de
données qu'en fait-on?
Nous avons vu que concernant le développement web c'est
l'ère du contenu et du flux continuel d'informations. La
définition que je donne et qui je pense sera celle de demain, est que
les développeurs web seront des développeurs collaboratifs et
participatifs. Ainsi, la base de données est complètement
invisible pour lui, il n'aura pas besoin de la gérer car elle le sera en
back office.
Comme nous avons fait une analogie avec le
développement applicatif et le développement web, nous pouvons
ici faire de même. Dans le sens où, si on se dirige
également vers du développement logiciel participatif et
collaboratif la vision de la base de données sera complètement
invisible pour le développeur.
Le problème c'est que, comme vu dans la partie 2 du
développement, une gestion de base de données nécessite
une connaissance accrue en conception et de solides connaissances en
sécurité et réseau. Autrement dit, pour réaliser
une base de données sécurisée, bien conçue et
fiable il faut des connaissances techniques et si demain nous sommes
amenés à être tous développeurs, ce n'est pas avec
de la technique mais bien avec des choses simples et accessibles de tous.
La gestion en back office de ces bases de données se
fera par des personnes dédiées et formées pour. De
même que les outils mis à la disposition de ces "nouveaux"
développeurs doivent être eux-mêmes
développés, et ceci nécessite des personnes ayant eu des
formations en programmation (que ce soit pour la partie applicative, la partie
web où la partie base de données).
8. Le développeur de
"base" sera toujours là.
Il est fort probable que nous soyons tous développeurs
plus tard, ceci grâce à des outils simples d'utilisation,
ergonomiques, sécurisés, viables, etc. Mais doit-on rappeler que
pour que ces outils existent il faut qu'il y ait quelqu'un derrière qui
puisse les créer ? Le métier de développeur, qu'on peut
appeler "de base", sera a priori, toujours là. Quoiqu'il arrive nous
aurons besoin de ces personnes pour que les développeurs, qu'on peut
appeler "dépendants", puissent utiliser les outils qui sont mis à
leur disposition. Pour aller vers le développement participatif et
collaboratif de chacun d'entre nous, il faudra qu'il y ait ces deux types de
développeurs.
A moins que l'on fasse totalement fausse route ?
9. Et si c'était
tout autre chose?
A. Programmation par langage
naturel écrit
Il existe plusieurs langages de programmation qui permettent
de mettre en avant leur capacité à traduire du langage naturel.
On peut citer Hypertalk, Perl ou encore Supernova.
Le langage humain est vaste et contient beaucoup de mots donc
il va falloir utiliser seulement une petite partie afin de "réduire la
complexité" du problème et de sorte d'avoir des performances
acceptables. Contrairement à d'autres langages de programmation qui sont
basés sur les états, ces langages sont basés sur les
paragraphes qui contiennent de nombreuses déclarations imbriquées
et en ignorant certains mots (le, et,...). Par exemple: 1- Je veux une
fenêtre. 2- Le titre de la fenêtre est bonjour. Ces langages
utilisent différentes règles notamment la PVC (Pronom Verbe
Classe). P pour "je", V pour "veux" et C pour "fenêtre". Ainsi il y a une
distinction des différentes données.
Ainsi ces langages peuvent faciliter le développement,
et être compris par un très grand nombre de personnes. Une
personne qui n'a pas de base en programmation sera moins rebutée si elle
parle comme avec une personne à la machine. C'est ce qui a fait le
succès de Hypercard à la fin des années 1980 et
début 1990 car il proposait de créer de manière simple des
interfaces graphiques à la souris.
B. Programmation par langage
naturel parlé
Et si Apple n'avait pas ouvert de nouvelles
opportunités avec son système de reconnaissance vocale, Siri ? On
peut imaginer un système qui va permettre à des utilisateurs de
trouver des données ou même des informations sur un sujet par
commandes vocales. Ceci permettrait d'avoir une toute nouvelle interaction
entre l'homme et la machine qui serait basée sur la voix. Son
évolution, on peut l'imaginer un peu comme on a pu le voir avec le web,
c'est-à-dire qu'au début, le système de reconnaissance
vocale pourra interpréter de simples requêtes (comme le fait SIRI
déjà). Et plus tard, pourquoi pas, avoir quelque chose de
beaucoup plus complet où l'interaction serait quasi instantanée,
où l'on pourrait tout demander au système, comme par exemple
ouvrir une application, aller sur tel site, etc. Tout en imaginant qu'à
terme on pourrait lui demander : "Je veux le logiciel "X" avec telle,
telle et telle option", sans même toucher un ordinateur. Mais là,
on entre un peu dans un autre débat qui pourrait tout à fait
être le sujet d'un autre mémoire.
Conclusion
Il est vraiment très difficile de répondre
dès aujourd'hui à notre problématique. En effet, pour
répondre nous nous sommes basés sur ce que l'informatique nous a
apporté depuis le début, sur l'évolution des logiciels et
des manières de développement.
Concernant la partie logiciel, nous avons montré qu'il
est possible, pour un non initié, de faire des outils simples
grâce à des logiciels de glisser-déposer qui sont faciles
et intuitifs, ou via des outils de modélisation qui vont
générer du code (si encore il a certaines bases en
modélisation). Mais ces outils ne vont pas permettre de réaliser
des logiciels robustes ayant énormément de
fonctionnalités.
Concernant la partie web, nous avons pu voir que via les CMS
et les éditeurs de sites web il est actuellement très simple de
faire un site.
La différence se fait surtout au niveau de
l'évolution de chacun. Même si ces deux domaines ont
évolué de manière exponentielle, le web a mis
l'utilisateur final au coeur du processus de génération de
contenus et de services. Et si on ne respecte pas encore à la lettre la
définition du développeur web, on est tous développeurs
dans une certaine mesure. Mais au vu : de l'évolution des
procédés et des technologies, de la démocratisation du
web, du monde hyper connecté vers lequel nous nous dirigeons et ce que
l'évolution nous a montré, on peut d'ores et déjà
dire, que demain nous serons tous développeurs web. Et je pense
fortement que la définition de développeur va être
amenée à changer. En effet, on entendra désormais par
développeur web tout le côté collaboratif et participatif
que nous avons vu dans ce mémoire. Il est plus qu'envisageable que
chacun de nous (seul impératif : avoir un accès à
internet) soit considéré comme des développeurs à
part entière en participant et en collaborant au futur monde hyper
connecté d'Internet.
En revanche le scepticisme est de mise concernant le
côté applicatif. En effet, être développeur de
logiciel est, comme nous l'avons vu, très compliqué. Il faut
avoir de bonnes notions, un savoir-faire énorme qui touche à
plusieurs domaines et encore plus aujourd'hui qu'hier. Malgré
l'existence d'outils de générateurs de code et d'éditeurs
graphiques, nous avons pu voir que pour pouvoir développer une
application digne de ce nom il fallait quand même avoir un certain bagage
de connaissances en programmation et en modélisation. Cependant, avec
l'apparition du Cloud Computing et du SaaS, nous pourrions très bien
imaginer une évolution "à la web". Celle-ci ouvrirait les portes
à une sorte de développement collaboratif où, au
début, chaque "vrai" développeur pourrait apporter sa pierre
à l'édifice et, à l'image du web, avoir, à terme,
un utilisateur de base qui devient acteur du développement
d'application. Cela pourrait être possible, peut être, en essayant
de ne pas réimplanter les IDE dans les navigateurs, mais en repensant
la façon de développer, en s'appuyant sur ce qui a fait la force
du web.
Concrètement, pour que l'on soit tous
développeurs il faut un monde hyper connecté, où chacun
apporte quelque chose sur un sujet commun (on peut imaginer que pour un SaaS,
un utilisateur de base explique ce qu'il faudrait améliorer ou pas) afin
que ce soit collaboratif et par la suite participatif. Et surtout, qu'il n'y
ait en aucune façon, une part technique, car cela réduirait le
nombre de personnes capables de l'interpréter. C'est une condition sine
qua non. Bien qu'il y aura toujours les développeurs de base pour la
partie technique, il y aura également de nouveaux types de
développeurs pour une partie peut être plus collaborative et
participative. Un peu à l'image d'une relation client-fournisseur,
où le client intervient directement dans le développement.
Les langages ont permis une abstraction plus
élevée, ainsi un développeur peut se focaliser sur une
fonctionnalité en se détachant des détails techniques de
son implémentation (en tous cas, ils tendent vers cela). Tant qu'il n'y
a pas de contraintes techniques particulières et que d'autres "vrais"
développeurs sont là pour mettre à disposition ces outils,
une nouvelle catégorie de développeurs peut se permettre une
meilleure connaissance de leur domaine.
Mais on peut aussi également
penser que comme l'histoire des langages de programmation est liée
à celle de l'informatique, de la technologie et même à
celle de la téléphonie, on verra peut-être des changements
encore utopique pour nous. Par exemple, au niveau de l'interface, il sera
peut-être possible de commander des ordinateurs "à la voix" en
utilisant le "langage naturel".
Et dire que Minority Report est déjà
obsolète...
Travaux cités
Batory, D., Thomas, J., & Sirkin, M. (1994).
Reengineering a Complex Application.
Gabriel, R. P. (2002). Objects have failed. Openning
OOPSLA.
Gray, J., & Karsai., G. (2003). Proceedings of the
36th.
Herndon, R., & Berzins, V. (1988). The Realizable
Benefits of a Language.
Jones, C. (2006). Software Productivity Research
(SPR).
Nierstrasz, O. (2010). Ten Things I hate about Object Oriented
Programming. ECOOP.
Rothenber, J. (1989). The nature of modeling.
Soley, R. (2001). MDA Guide.
Récupéré sur OMG : www.omg.org
Van Deursen, A., & Klint, P. (1998). Little Languages
: Little Maintenance.
Van Deursen, A., Klint, P., & Visser, J. (2000).
Domain-specific languages : An annotated bibliography.
Wile, D. (2004). Lessons learned from real DSL
experiments. Science of Computer.
Bibliographie
Application du modèle MDA (Model-Driven
Architecture) dans le développement du logiciel - VO Duc An -
2007
Approche langage au développement logiciel :
Application au domaine des services de Téléphonie sur IP
- Fabien Latry - 2007
Bases de données - Bernd Amann -
2012
Conception d'une base de données -
Cyril Gruau - 2005
De la réutilisabilité des applications
à celle des modèles métiers: apport pour
l'ingénierie des modèles - Pierre Crescenzo et Philippe
Lahire - 2010
Développement d'Applications à Grande
Echelle par Composition de Méta-Modèles - Germàn
Eduardo VEGA BAEZ - 2005
Développement logiciel orienté paradigme
de conception : la programmation dirigée par la
spécification - Damien Cassou - 2011
End-User Modeling Défis du Génie de la
Programmation et du Logiciel, journées nationales du GDR GPL -
Albert Patrick (IBM, Paris), Blay-Fornarino Mireille (I3S, Sophia-Antipolis),
Collet Philippe (I3S, Sophia-Antipolis), Combemale Benoit (IRISA, Rennes),
Dupuy-Chessa Sophie (LIG, Grenoble), Front Agnès (LIG,Grenoble), Grost
Anthony (ATOS, Lille), Lahire Philippe (I3S, Sophia-Antipolis), Le Pallec
Xavier (LIFL,Lille), Ledrich Lionel (ALTEN Nord, Lille), Nodenot Thierry
(LIUPPA, Pau) et Pinna-Dery Anne-Marie (I3S,Sophia-Antipolis) et Rusinek
Stéphane (Psitec, Lille) - 2010
Etat de l'art sur le développement logiciel
dirigé par les modèles - Samba Diaw, Rédouane
Lbath , Bernard Coulette - 2008
Génération de Code & Reverse
Engineering - Cours de Reda Bendraou
Génie Logiciel - Cours de Reda
Bendraou
Ingénierie Dirigée par les
Modèles (IDM) État de l'art - Benoît Combemale -
2008
Ingénierie dirigée par les
modèles Model Driven Architecture - Laurent Pérochon -
2008
Journée sur l'ingénierie dirigée
par les modèles - Lille 7-8 juin 2011
L'INGÉNIERIE DIRIGÉE PAR LES
MODÈLES : Un bilan critique Journées NEPTUNE - Telecom
ParisTech Paris, 17-18 mai 2011
L'approche Model-Driven Architecture, crédible
pour développer un progiciel de gestion intégré -
Xavier Moghrabi -2003
Le génie logiciel et l'IDM :une approche
unificatrice par les modèles -
Jean-Marc Jézéquel,
Sébastien Gérard,
Benoit Baudry
- 2006
Les classes et la génération de code
sous Bouml - Bruno Pagès - 2007
Les Design Patterns - Cours de Reda
Bendraou
Les Patterns pour l'Ingénierie des
Systèmes d'Information Produit - Lilia GZARA - 2000
Ligne de Produits Logiciel et variabilité des
modèles - cours de Philippe Lahire
Lignes de Produits Logiciels - cours de
Tewfik Ziadi
Manipulation de Lignes de Produits Logiciels : une
approche dirigée par les modèles - Tewfik Ziadi,
Jean-Marc Jézéquel - 2005
Manipulation de Lignes de Produits Logiciels : une
approche dirigée par les modèles - Tewfik Ziadi,
Jean-Marc Jézéquel - 2005
Model-Driven Engineering: Des Principes aux Concepts
Avancés - Cours de Reda Bendraou
Modélisation en Interaction Homme-Machine et en
Système d'Information : A la croisée des chemins -
Sophie DUPUY-CHESSA - 2011
Modélisation O-O avec UML - Cours de
Reda Bendraou
Service-Oriented Computing from the User
Perspective - Nassim LAGA - 2010
UML, le langage de modélisation objet
unifié - Laurent Piechocki - 2009
Une approche pour améliorer la
réutilisabilité des modèles métiers -
Pierre Crescenzo et Philippe Lahire - 2005
Utiliser Kemeta pour transformer les modèles -
Sébastien Mosser - 2009
Annexes
1. Annexe 1 : Diagrammes UML
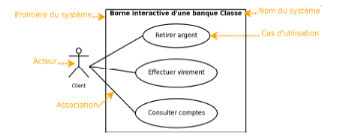
Figure 49 : Diagramme de cas d'utilisation
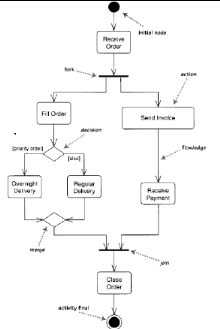
Figure 50 : Diagramme d'activité
Figure 51 : Diagramme de classe
Figure 52 : Diagramme de collaboration
Figure 53 : Diagramme
d'états/transitions
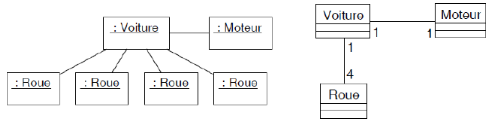
Figure 54 : Diagramme d'objets
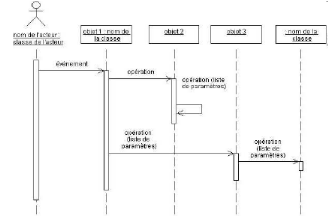
Figure 55 : Diagramme de séquences
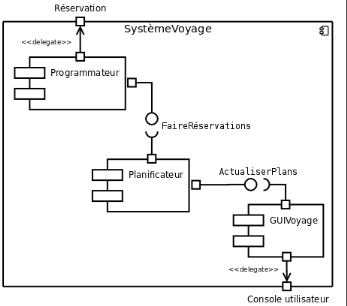
Figure 56 : Diagramme de composants
2. Annexe 2 : Le code source
généré par Visual Editor
javax.swing.GroupLayout layout = new
javax.swing.GroupLayout(this);
layout.setHorizontalGroup(
layout.createParallelGroup(Alignment.LEADING)
.addGroup(layout.createSequentialGroup()
.addGroup(layout.createParallelGroup(Alignment.LEADING)
.addGroup(layout.createSequentialGroup()
.addGap(41)
.addGroup(layout.createParallelGroup(Alignment.LEADING)
.addComponent(jLabel2,
GroupLayout.PREFERRED_SIZE, 55,
GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel3))
.addGap(44)
.addGroup(layout.createParallelGroup(Alignment.TRAILING,
false)
.addComponent(jButton1, Alignment.LEADING,
GroupLayout.DEFAULT_SIZE, GroupLayout.DEFAULT_SIZE,
Short.MAX_VALUE)
.addComponent(login, Alignment.LEADING)
.addComponent(mdp, Alignment.LEADING)))
.addGroup(layout.createSequentialGroup()
.addGap(138)
.addGroup(layout.createParallelGroup(Alignment.LEADING)
.addComponent(jLabel4,
GroupLayout.DEFAULT_SIZE, 340, Short.MAX_VALUE)
.addComponent(jLabel1,
GroupLayout.DEFAULT_SIZE, 291, Short.MAX_VALUE))))
.addContainerGap(21,
GroupLayout.PREFERRED_SIZE))
);
layout.setVerticalGroup(
layout.createParallelGroup(Alignment.LEADING)
.addGroup(layout.createSequentialGroup()
.addGap(71)
.addComponent(jLabel1)
.addGap(18)
.addGroup(layout.createParallelGroup(Alignment.BASELINE)
.addComponent(jLabel2)
.addComponent(login,
GroupLayout.PREFERRED_SIZE, GroupLayout.DEFAULT_SIZE,
GroupLayout.PREFERRED_SIZE))
.addGap(18)
.addGroup(layout.createParallelGroup(Alignment.BASELINE)
.addComponent(jLabel3)
.addComponent(mdp,
GroupLayout.PREFERRED_SIZE, GroupLayout.DEFAULT_SIZE,
GroupLayout.PREFERRED_SIZE))
.addPreferredGap(ComponentPlacement.UNRELATED)
.addComponent(jLabel4)
.addGap(30)
.addComponent(jButton1)
.addContainerGap(58, Short.MAX_VALUE))
);
3. Annexe 3 : Exemple d'une
génération de code
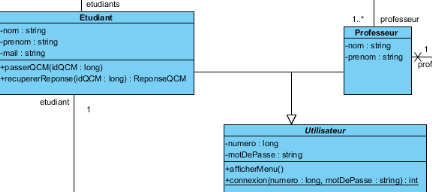
Figure 57 : Exemple de génération de
code
public abstract class Utilisateur {
private long _numero;
private String _motDePasse;
public void afficherMenu() {
throw new UnsupportedOperationException();
}
public static int connexion(long aNumero, String aMotDePasse)
{
throw new UnsupportedOperationException();
}
}
public class Etudiant extends Utilisateur {
private String _nom;
private String _prenom;
private String _mail;
public Module[] _module = new Module[0];
public ReponseQCM[] _reponseQCM = new ReponseQCM[0];
public void passerQCM(long aIdQCM) {
throw new UnsupportedOperationException();
}
public ReponseQCM recupererReponse(long aIdQCM) {
throw new UnsupportedOperationException();
}
}
public class Professeur extends Utilisateur {
private String _nom;
private String _prenom;
public Module _module;
public QCM[] _qCM = new QCM[0];
}
* 1 Object Management
Architecture: désigne une structure de management d'objets
* 2 Object Request
Broke: s'apparente à une tuyauterie permettant les échanges
de messages entre objet
* 3 Object Management Group :
est une association
américaine
à but non lucratif créée en
1989 dont
l'objectif est de standardiser et promouvoir le
modèle
objet sous toutes ses formes.
* 4 Meta-Object Facility :
est un standard de l'
Object
Management Group s'intéressant à la représentation des
méta
modèles et leur manipulation. Le langage MOF
s'auto-définit.
* 5 Structured Query Language
est un
langage
informatique normalisé servant à effectuer des
opérations sur des
bases de
données
* 6 Common Object Request
Broker Architecture, est une
architecture
logicielle, pour le développement de composants et d'
Object Request
Broker où ORB.Corba est un standard maintenu par l'
Object
Management Group.
* 7 Domain specific
language(langage dédié) est un
langage de
programmation dont les spécifications sont
dédiées à un
domaine
d'application précis.
* 8 COmmon Business
Oriented Language est un
langage de
programmation de troisième génération, c'est
langage commun pour la programmation d'applications de gestion.
* 9 Modèle
Conceptuel de Données: contrainte qui garantit l'
intégrité
référentielle entre deux tables.
* 10 Champs permettant
d'identifier un enregistrement de façon unique
* 11 Contrainte qui garantit
l'
intégrité
référentielle entre deux tables.
* 12 Combinaison de global
et de local. C'est un concept alliant les tendances globales aux
réalités locales.
* 13 Interdépendance
entre les membres plutôt qu'une structure ascendante
* 14 Entreprise
américaine de
conseil et
de recherche dans le domaine des
techniques
avancées
* 15 Cabinets d'audit et de
conseil
| 

