Republique de Côte d'Ivoire

Union-Discipline-Travail
Ministère de l'Enseignement Supérieur et de
la Recherche Scientifique
Ministère de l'Economie Numérique et de la
Poste
|
International Data Science Institute
|
|
|
Année académique 2019-2020
pour l'obtention du
Master en Data Science - Big Data
THEME
Traduction automatisée des langues
Africaines
Cas du lingala
TANO Assandé Jacob
|
Encadreur pédagogique BROU Konan
Marcellin
|
Maitre de stage Fabrice ZAPFACK
|
Master Data Science - Big Data I

DEDICACES
À ma famille, amis et connaissances qui m'ont
apporté le soutien moral et financier
afin que je puisse réussir cette formation aux
métiers de la data science.
Master Data Science - Big Data II

REMERCIEMENTS
Nous remercions tout d'abord l'Eternel Dieu pour le souffle de
vie et la force nécessaire qu'il nous a accordé pour
l'effectivité de ce travail. Nos remerciements vont aussi à
l'endroit d' Orange Côte d'Ivoire, la fondation X Polytechnique,
l'école X Polytechnique, l'INP-HB de Yamoussoukro et l'ENSEA d'Abidjan
qui ont tout mis en oeuvre pour la réussite de cette formation.
Ensuite au Directeur Technique (CTO) de data354, M. Fabrice
ZAPFACK, pour l'accueil et l'assistance qu'il nous a apporté durant ces
six mois de stage. Également nous remercions les membres de
l'équipe de data354, pour leur sympathie, disponibilité, conseils
et bonne humeur, qui ont contribué à faciliter notre
intégration.
Nous témoignons aussi notre profonde gratitude à
l'administration de l'INP-HB, en particulier à Monsieur KOFFI
N'Guéssan, actuel Directeur de l'INP-HB, à Monsieur Tanoh Tanoh
Lambert, Directeur de l'IDSI, et à ses collaborateurs.
Nos remerciements les plus distingués vont
également à l'endroit du Professeur BROU Konan Marcellin pour
l'encadrement durant toute la période de stage.
Mes sincères remerciements à mon oncle GBOZO
Yao, à ma tante MEA Odette, à mon frère cadet TANO Kouakou
Aaron Junior, à mes amis TANOH Bredoux Fulgence, DJE Marie-Christelle,
KOUAKOU Fulbert et ADAYE Kissi Patrice qui m'ont accompagnés moralement
et financièrement tout au long de cette formation, sans oublier tout
ceux ou celles qui ont pris de leur temps pour lire et corriger ce
mémoire.
SOMMAIRE
DEDICACES I
REMERCIEMENTS II
SOMMAIRE III
LISTE DES TABLEAUX IV
LISTE DES FIGURES V
LISTE DES ABREVIATIONS VI
GLOSSAIRE VII
AVANT-PROPOS VIII
RESUME IX
INTRODUCTION GENERALE 1
PARTIE I : ENVIRONNEMENT DE LA MISSION 2
I- PRÉSENTATION DE LA STRUCTURE D'ACCUEIL 3
II- PRÉSENTATION DU CAHIER DES CHARGES 4
III- PLANNING PREVISIONNEL 6
IV- ANALYSE DE L'EXISTANT 6
PARTIE II: ETUDE DES APPROCHES EXISTANTES DE TRADUCTION
AUTOMATIQUE ET CHOIX
|
D'UNE APPROCHE
|
7
|
|
I- PRESENTATION DES METHODES DE TRADUCTION AUTOMATIQUE
|
8
|
|
II- CHOIX D'UNE APPROCHE
|
11
|
|
PARTIE III : DESCRIPTION DE LA TRADUCTION AUTOMATIQUE NEURONALE
|
12
|
|
I- LA TRADUCTION AUTOMATIQUE NEURONALE
|
13
|
II- LES RÉSEAUX DE NEURONES RÉCURRENTS
|
17
|
III- MODÈLES NEURONAUX DE TRADUCTION AUTOMATIQUE
|
24
|
IV- EVALUATION D'UN MODÈLE DE TRADUCTION AUTOMATIQUE
|
|
28
|
|
|
PARTIE IV : IMPLEMENTATION DU MODELE DE TRADUCTION AUTOMATIQUE
|
33
|
|
I- PRÉSENTATION DU PROCESSUS GLOBALE DE TRAITEMENT
|
34
|
|
II- COLLECTE ET PRÉPARATION DES DONNÉES
|
36
|
|
III- CONSTRUCTION DU MODÈLE DE TRADUCTION AUTOMATIQUE
|
40
|
|
IV- PRESENTATION DES RESULTATS
|
41
|
|
CONCLUSION GENERALE
|
44
|
|
BIBLIOGRAPHIE
|
.X
|
|
WEBGRAPHIE
|
.XI
|
|
ANNEXES
|
.XII
|
|
TABLE DES MATIÈRES
|
XV
|
Master Data Science - Big Data
III
Master Data Science - Big Data IV

LISTE DES TABLEAUX
Tableau 1 : Planning prévisionnel d'exécution du
projet 6
Tableau 2 : Calcul de la précision modifiée (P1)
des unigrams 30
Tableau 3 : Calcul de la précision modifiée (P2)
des bigrams 30
Tableau 4 : Calcul de la précision modifiée (P3)
des 3-grams 31
Tableau 5 : Calcul de la précision modifiée (P4)
des 4-grams 31
Tableau 6 : Caractéristiques du jeu de données
36
Tableau 7 : Exemple de mise en minuscule des mots du jeu de
données 37
Tableau 8 : Exemple de suppression de bruts du jeu de
données 37
Tableau 9 : Exemple d'harmonisation des écrits du jeu
de données 38
Tableau 10 : Modèles de traduction automatique 40
Tableau 11 : Quelques hyperparamètres des
modèles construits 40
Tableau 12 : Présentation des résultats des
différents modèles de traduction automatique 41
Tableau 13 : Extrait de traduction machine et humaine 43
Master Data Science - Big Data
V

LISTE DES FIGURES
Figure 1 : Statistiques des univers linguistiques 5
Figure 2 : Traduction automatique à base de
règles 8
Figure 3 : Traduction automatique statistique 9
Figure 4 : Traduction automatique neuronale 10
Figure 5 : Mise en correspondance neurone biologique / neurone
artificiel 14
Figure 6 : Structure d'un neurone artificiel j 14
Figure 7 : Génération de texte caractère
par caractère 19
Figure 8 : Traitement d'une séquence de taille T un
réseau de neurone récurrent 19
Figure 9 : Prédiction de la probabilité du
caractère suivant à partir d'une séquence initiale 20
Figure 10 : Une couche RNN, prenant en entrée des
séquences de 10 caractères 21
Figure 11 : Représentation simplifiée d'une
cellule LSTM 22
Figure 12 : Représentation simplifiée d'une
cellule GRU 23
Figure 13 : Représentation fermée d' un
modèle séquence-à-séquence 24
Figure 14 : Représentation ouverte d' un modèle
séquence-à-séquence 25
Figure 15 : Représentation détaillée d'un
seq2seq pour une traduction anglais vers lingala 25
Figure 16 : Représentation simplifiée d'un
`Transformer' 27
Figure 17 : Processus global de la mise en place de l'outil de
traduction 34
Figure 18 : Exemple de vectorisation d'une entrée 39
Figure 19 : Répartition des données 39
Figure 20 : Interface web de traduction 42
Figure 21 : Extrait du script de traduction XII
Figure 22 : Extrait du corpus parallèle XIII
Figure 23 : Extrait du script de l'encodeur et du
décodeur XIV
Master Data Science - Big Data VI

LISTE DES ABREVIATIONS
BLEU : BiLingual Evaluation Understudy
CTO : Chief Technical Officer
ENSEA : École Nationale
Supérieure de Statistique et d'Economie Appliquée
FFN : Feed Forward network
GRU : Gated recurrent unit
IA : Intelligence Artificielle
IDSI : International Data Science
Institute
INP-HB : Institut National Polytechnique
Félix Houphouët Boigny
LSTM : Long Short-Term Memory
NMT : Neural Machine Translation
NLP : Natural Language Processing
OOV : Out Of Vocabulary
RBMT : Rules Based Machine Translation
RPA : Robotics Process Automation
(Automatisation des Processus Robotiques)
RNN : Recurrent Neural Network
SMS : Short Message Service
SMT : Statistical Machine Translation
TA : Traduction Automatique
TAL : Traitement Automatique du Langage
TALN : Traitement Automatique du Langage
Naturel
TAN : Traduction Automatique Neuronale
TAS : Traduction Automatique Statistique
GLOSSAIRE
l Anglais: langue indo-européenne
germanique originaire d'Angleterre et parlée comme langue officielle
dans plusieurs pays du monde.
l Arabe : C'est la langue officielle de plus
de vingt pays et de plusieurs organismes internationaux, dont l'une des six
langues officielles de l' Organisation des Nations unies.
l Haoussa : Haoussa, hausa ou hawsa, est une
langue africaine de la famille des langues afro-asiatiques1
parlée en Afrique de l'Ouest, principalement au Niger et au Nigeria,
mais aussi au Bénin.
l Igbo : L'igbo, ou ibo est une langue
parlée au Nigéria par environ 20 à 35 millions de
personnes, les Igbos, en particulier dans le sud-est du Nigéria.
l Intelligence artificielle : elle
désigne l'ensemble des théories et des techniques mises en oeuvre
en vue de réaliser des machines capables de simuler l'intelligence
humaine.
l Langue Africaine : une langue est tout
d'abord un instrument permettant la communication entre individus. L'on doit
donc entendre par langue africaine, une langue parlée sur le continent
africain.
2
l Lingala : c'est une langue de la famille
des langues bantoues , parlée en République democratique
du Congo (communément appelé Congo-Kinshasa) et en
République du Congo (appelé communément
Congo-Brazzaville).
l Natural Language Processing (NLP) : encore
appelée en français traitement automatique du langage naturel
(abr. TALN), ou traitement automatique des langues (abr. TAL) c'est un domaine
qui vise à créer des outils de traitement de la langue naturelle
par des algorithmes d'Intelligence artificielle.
l Swahili : Le Swahili ou Kiswahili est une
langue d'origine africaine, parlé dans dix pays à savoir le
Malawi, le Rwanda, la Somalie, le Mozambique, la RDC, le Kenya, l'Ouganda, le
Burundi, la
Tanzanie puis aux Comores.
l Traduction automatique : consiste à
traduire un texte (ou d'une conversation audio, en direct ou en
différé) d'une langue source vers une langue cible en utilisant
un ou plusieurs programmes informatiques, sans qu'un traducteur humain n'ait
à intervenir.
3
l Wolof : langue sénégambienne
principalement parlée au Sénégal et en Mauritanie.
l Word Embedding : Le word embedding est une
technique de vectorisation de mots où les mots se rapprochant
sémantiquement sont représentés par des vecteurs plus
proches.
l Yoruba : est une langue d'Afrique de
l'ouest principalement parlée au Nigeria, Bénin et au Togo.
l Zulu : Le zulu est une langue de la
famille des langues bantoues, parlée en Afrique australe.
1 Afro-asiatiques : une famille de langues
parlées principalement en Afrique du Nord, dans la Corne de l'Afrique,
au Moyen-Orient, dans le Sahara et dans une partie du Sahel.
2 Langues bantoues : La famille des langues
bantoues est un ensemble de langues africaines qui regroupe environ 400 langues
parlées dans une vingtaine de pays de la moitié sud.
3 Langues sénégambiennes : Les
langues sénégambiennes sont des langues africaines
rattachées à la branche nord des langues atlantiques.
Master Data Science - Big Data VIII

AVANT-PROPOS
l'International Data Science Institute est
une chaire internationale de formation en Data Science et Big Data, issu d'un
partenariat entre l'opérateur de téléphonie Orange,
l'Institut National Polytechnique Félix Houphouët-Boigny (INP-HB),
l'École Nationale Supérieure de Statistique et d'Economie
Appliquée (ENSEA), l'École polytechnique (X) et la Fondation de
l'École polytechnique (FX).
Homologué par l'État de Côte d'Ivoire, la
chaire à ouvert ses portes à la toute première promotion
en 2017 et elle a pour objectif de former des experts dans le domaine de la
statistique, de l'intelligence artificielle et du Big Data.
D'une durée de deux ans, l'IDSI propose un master
d'excellence de niveau international à destination d'étudiants
qui s'approprient des connaissances en ingénierie informatique
basée sur les nouvelles évolutions en matière de stockage
et de traitement des données. Les cours sont dispensés au sein du
Data Science Institute de l'INP-HB par une équipe pédagogique
composée de professeurs de l'INP-HB, de l'ENSEA, de l'X, ainsi que des
professionnels experts dans leur domaine.
Pour parfaire la formation et se rapprocher du monde
professionnel, il est prévu un projet de fin d'études
sanctionné par la rédaction d'un mémoire puis une
soutenance devant un jury d'enseignants de l'INP-HB de l'ENSEA de l'X et de
responsables d'entreprises.
C'est dans ce cadre que l'IDSI initie en fin de cycle, des
stages pratiques en entreprise en vue d'amener ses élèves
à confronter leurs connaissances théoriques acquises durant leur
parcours académique aux réalités du monde professionnel.
C'est ainsi que nous avons été accueilli par l'entreprise data354
du 17 mars 2020 au 18 septembre 2020 pour un stage de 6 mois dans ses
locaux.
Master Data Science - Big Data IX

RESUME
Le traitement automatique de langues naturelles ou Natural
Language Processing (NLP) a connu une révolution majeure ces
dernières années. Plusieurs systèmes de traduction ont vu
le jour permettant de traduire certaines langues les plus parlées dans
le monde. Le constat général est que beaucoup de langues
africaines sont restées en marge de cette révolution outre
certaines langues telles que l'Arabe, le Yoruba, le Zulu, le Swahili, le Igbo,
le Wolof qui sont actuellement traduisibles par certaines plateformes tel
google translate. De ce fait, nous nous sommes intéressés
à ce domaine afin de concevoir un traducteur automatique basé sur
un modèle de réseaux de neurones pour la traduction l'anglais
vers le lingala.
Le travail exposé dans ce mémoire est un projet
interne à l'entreprise qui vise à mettre en place un
système de traduction de langues africaines par l'utilisation des
méthodes du NLP.
Nous exposons dans ce mémoire les méthodes et
outils utilisés pour atteindre nos objectifs, pour se faire, nous
procédons tout d'abord par la collecte des données
utilisées par la suite pour entraîner un modèle de
traduction automatique neuronale appelé sequence-to-sequence.
L'évaluation du sesquence-to-sequence produisant des résultats
peu satisfaisants, nous avons été amenés à mettre
en place un transformer (aussi un modèle de traduction automatique
neuronale) qui nous a donné des résultats encore meilleurs.
L'implémentation s'est entièrement faite avec le langage de
programmation python et l'entraînement des différents
modèles s'est fait sur google collaboratory.
Mots clés :
Traduction automatique neuronale; deep learning;
apprentissage profond; sequence-to-sequence; transformer; Natural Language
Processing; réseaux de neurones; traduction automatisée de
langues africaines.
Master Data Science - Big Data 1

INTRODUCTION GENERALE
La traduction automatique (TA) est le processus consistant
à traduire un texte d'une langue à une autre à l'aide d'un
logiciel en intégrant des connaissances informatiques et linguistiques.
Dans les débuts, les systèmes de traduction automatique se
faisaient en associant simplement le sens des mots de la langue source à
la langue cible à l'aide de règles linguistiques. Cependant, ces
systèmes n'ont pas donné de bons résultats en raison de
leur incapacité à saisir les différentes structures de
phrases dans une langue. De plus, ce processus de traduction prend beaucoup de
temps et nécessite également des personnes qui maîtrisent
les deux langues. Par la suite, des approches de traduction basées sur
des corpus, comme la traduction automatique statistique (TAS) et la traduction
automatique neuronale (TAN), ont été introduites dans le but de
corriger les inconvénients des méthodes basées sur des
règles.
Aujourd'hui grâce aux progrès du domaine de la
traduction automatique, l'on constate sur internet de nombreux sites de
traduction en ligne et en temps réel d'un grand nombre de documents.
Aussi nous constatons sur différents sites de traduction tels que Google
Traduction, DeepL, plusieurs langues traduisibles mais parmi ces langues
seulement une poignée de langues africaines sont traduisibles. Certaines
langues africaines telles que le Wolof, l'Igbo, le Haoussa, le Lingala ayant le
statut de langues nationales se valent d'être traduites à cause de
leurs portées qui se justifient par le fait qu'elles sont même
parlées sur certains plateaux télé et radio
internationales.
Dans cet élan de valorisation des langues africaines,
et de participation à l'éducation par l'apprentissage des langues
africaines, data354 souhaiterait mettre en place un système de
traduction de langues dites internationales vers les langues africaines, Dans
le cadre de cette tâche, la décision a été prise de
démarrer par la traduction de l'anglais vers le lingala. C'est donc dans
ce cadre que le thème suivant : Traduction automatisée de
langues Africaines: Cas du lingala , nous a été
confié lors de nos six mois de stage effectués au sein de ses
locaux.
De ce fait comment parvenir à traduire automatiquement
une langue source vers une autre langue cible en d'autres termes, quelles
approches et algorithmes utiliser pour effectuer la traduction automatique ?
Pour répondre à toutes ces questions, nous commencerons
après avoir présenté notre structure d'accueil, à
présenter les approches de traduction automatique existantes et nous en
choisirons une pour la résolution du problème posé. Dans
une seconde partie nous procéderons à la description
détaillée de l'approche choisie et enfin dans la dernière
partie nous présenterons l'implémentation du modèle de
traduction automatique.
Master Data Science - Big Data 2

PARTIE I : ENVIRONNEMENT DE LA MISSION
Nous présenterons dans cette partie, la structure
d'accueil, ensuite le cahier de charges et les objectifs I atteindre ainsi que
le planning I observer. Par la suite nous procéderons I une analyse de
l'existant qui nous permettra de mieux cerner nos objectifs afin de
développer un système de qualité.
I- PRÉSENTATION DE LA STRUCTURE D'ACCUEIL
1. Structure d'accueil
data354
www.data354.com est une
société de consulting technique sur les produits et services
d'ingénierie et d'analyse des données. La société
accompagne aujourd'hui les acteurs du secteur public et privé à
la maîtrise des données et au développement de solutions
d'analyse prédictive. Fondée par une équipe
expérimentée, pluridisciplinaire et complémentaire, tous
animés d'une vision commune: celle de mettre en place des outils
analytiques et prédictifs de pointe au service des organisations
évoluant en Afrique; elle accompagne aujourd'hui ses clients tout au
long de leur transformation data grâce à son expertise
Technologique et à sa capacité de conseil en
Stratégie et Management.
2. Les domaines de compétences de la structure
d'accueil
Partenaire privilégié des cabinets de conseils
en transformation digitale en Afrique et en Europe, data354 propose une large
gamme de prestations externalisées tels que :
l Cartographie de l'infrastructure technique et des
données existantes;
l Collecte, stockage, sécurisation, traitement,
visualisation et valorisation de données internes et externes;
l Mise en place d'outils d'aide à la
décision;
l Intelligence artificielle : machine learning / deep
learning (entraînement des modèles, prédictions et
visualisation).
Elle accompagne également les entreprises
technologiques internationales à l'adaptation de leurs solutions aux
marchés africains.
Les services proposés par l'entreprise sont
regroupés en trois grands groupes de services à savoir :
Data Strategy
l Évaluation maturité Data
l Stratégie & plan gouvernance Data & IA
l Acculturation Data
|
Data Management
l Infrastructure Big Data et temps-réel
l Qualité des données
l Data Catalog1
|
|
Data Intelligence
l Data Science
l Business Intelligence
l RPA2
1 Data catalog : un Data Catalog est un
catalogue de données. Plus précisément, il s'agit d'un
emplacement centralisé où sont regroupées les informations
sur les données contenues dans une base de données : les
métadonnées.
2 RPA : La RPA, ou Robotic Process
Automation, est une technologie permettant d'automatiser des processus
métier qui nécessitaient, jusque-là, l'intervention d'un
humain. c'est -à-dire traiter des tâches répétitives
et chronophages grâce à l'utilisation de logiciels d'intelligence
artificielle capables d'imiter un travailleur humain.
Master Data Science - Big Data 3
Master Data Science - Big Data 4

II- PRÉSENTATION DU CAHIER DES CHARGES
De nos jours, de nombreux africains vivent en Europe, en
Amérique ou même Afrique dans un milieu citadin où ils ont
peu de chance d'apprendre leurs valeurs traditionnelles. Fort est de constater
que de nombreuses personnes éprouvent assez de difficultés
à s'exprimer dans leurs langues maternelles parce qu'elles n'ont jamais
été ou n'ont pas passé un grand nombre de temps dans un
environnement favorisant un échange en langue maternelle.
Cette situation nous laisse souvent dans des situations
très inconfortables, surtout lors des échanges avec les parents
des milieux ruraux ou avec ceux des milieux urbains mais qui se sentent plus
à l'aise dans les échanges en langue maternelle.
La maîtrise de la langue est utile pour
s'intégrer dans un groupe social donné et favorise la
création et le renforcement des liens amicaux surtout lors des visites
dans des pays africains où une langue locale est reconnue et
parlée comme langue nationale.
De ce fait data354, dans l'optique de permettre un
apprentissage des langues africaines aux africains ayant perdus le lexique de
leurs langues maternelles ou à tout autre personne physique
désireuse d'apprendre une langue africaine ou à une personne
morale voulant traduire un certain nombre de documents en langue africaine de
pouvoir le faire aisément via une plateforme de traduction qu'elle
voudrait mettre en place.
Pour le début, ce projet de création de
système de traduction vise à traduire dans un premier temps des
phrases écrites en anglais vers le lingala et par la suite permettre la
traduction de d'autres langues africaines.
1- Motivation du choix des langues
Plusieurs raisons ont motivé le choix des deux langues
retenues :
ANGLAIS
l L'une des langues ayant plus de locuteurs natifs;
l La langue la plus utilisée sur internet;
l La langue la plus utilisée dans le monde du travail et
pour la communication internationale.
Master Data Science - Big Data 5

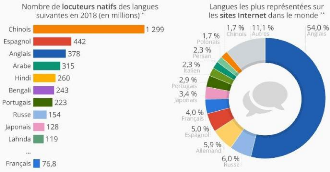
Sources : W3techs, Ethnologue
Figure 1 : Statistiques des univers linguistiques
LINGALA
l Se situe dans le top 10 des langues Africaines les plus
parlées;
l Expansion de la langue à travers la musique;
l Statut de langue Nationale en république
démocratique du Congo;
l L'une des langues africaines les plus parlées et pas
encore pris en compte dans les systèmes de traduction tels que google
translate, DeepL.
2. Objectif général
L'objectif lors ce stage c'est de mettre en place un outil
pour la traduction automatique de phrases écrites en Anglais vers le
Lingala à l'aide des algorithmes d'intelligence artificielle.
3. Objectifs spécifiques
Pour atteindre l'objectif général, nous
identifions trois objectifs spécifiques du projet à savoir :
l Collecter et préparer un ensemble de données
bilingue où l'on aura des phrases en anglais et leur équivalent
en Lingala ;
l Implémenter un modèle de traduction
automatique ;
l Produire une interface utilisateur conviviale offrant des
services de traduction.
Master Data Science - Big Data 6

III- PLANNING PREVISIONNEL
1- Planning d'exécution du projet
La clé principale de la réussite d'un projet
est un bon planning. En effet, le planning aide à bien subdiviser le
travail et séparer les tâches à réaliser, il offre
une meilleure estimation et gestion de temps nécessaire pour chaque
tâche. De plus, il donne assez de visibilité permettant d'estimer
approximativement la date d'achèvement de chaque tâche. Dans notre
projet, le planning prévisionnel se présente comme suit.
Durée
|
Tâches
|
Livrables
|
Outils
|
1 semaine
|
Setup environnement de travail
|
|
Linux, AWS, GCP, Azure
|
3 semaines
|
Préparation des datasets
|
Fichiers contenant 10000+ avis labellisés
|
Python, spark, pandas,
SQL
|
6 semaines
|
Revue de littérature
Benchmark de services
cloud
(AWS, GCP, Azure)
|
Création d'un MVP3
Evaluation sur un
dataset de
référence
|
Python, Rest API, AWS, GCP, Azure
|
6 semaines
|
Créer un de machine translation
|
Evaluation sur le dataset de
référence
|
NLP, tensorflow,
transformers
|
4 semaines
|
Déploiement et intégration du modèle
d'extraction d'entités
|
Micro service déployé sur une infrastructure
cloud
|
AWS lambda, AWS EKS
|
4 semaines
|
Finalisation du projet
|
Documentation détaillée
Rapport de stage
|
|
|
Tableau 1 : Planning prévisionnel
d'exécution du projet
IV- ANALYSE DE L'EXISTANT
1. Constat
Aujourd'hui, nous disposons sur internet de plusieurs
plateformes de traduction automatique de l'anglais/français vers
l'Arabe, le Wolof, l'Igbo, le Zulu, le Yoruba, le Haoussa, le Swahili mais peu
de plateformes sont proposées pour la traduction en temps réel de
l'anglais/français vers le lingala.
2. Commentaires
Nous trouvons sur internet plusieurs plateformes tels :
lexilogos (
www.lexilogos.com ),
glosbe (
https://fr.glosbe.com ),
etc... qui proposent des dictionnaires anglais - lingala et vise-versa. Hormis
les dictionnaires en ligne, il n'existe presque pas de systèmes de
traduction en ligne d'un ensemble de mots(phrase) de l'anglais vers du lingala
bien que le lingala soit une langue nationale. Par contre certaines langues
nationales africaines tels le wolof (Sénégal),
l'Igbo(Nigéria) ont bien trouvés leurs places dans la traduction
en ligne par certaines plateformes comme google traduction (
https://translate.google.com/ ), imtranslator (
https://imtranslator.net/translation/),
lingojam (
https://lingojam.com ), etc...
3 MVP : Minimum Viable Product, peut être
perçu comme une première version basique du produit à
livrer.
Master Data Science - Big Data 7

PARTIE II : ETUDE DES APPROCHES EXISTANTES
DE TRADUCTION AUTOMATIQUE ET CHOIX D'UNE
APPROCHE
Nous présenterons dans cette partie, les
différentes approches de traduction automatique existantes. Cette
présentation permettra de montrer le mode de fonctionnement de ces
différentes approches, leurs points forts et points faibles puis au vu
des points forts et faibles de chacune d'entre elles nous choisirons une
approche pour le traitement de notre sujet d'étude.
Master Data Science - Big Data 8

I - PRÉSENTATION DES APPROCHES DE TRADUCTION
AUTOMATIQUE
Le domaine de la traduction a connu un essor
considérable ces dernières années, les limites des
traductions humaines ont suscité le désir de mettre en place des
algorithmes dans le but de permettre à la machine d'effectuer ces
tâches de traduction. L'on distingue aujourd'hui plusieurs approches de
traduction automatique, nous nous évertuerons à présenter
les plus utilisées puis nous choisirons dans la suite une approche pour
le traitement de notre cas d'étude. [ 1 ]
1 - Traduction Automatique Basée sur des
Règles (TABR)
Le système de Traduction Automatique Basée sur
des Règles(TABR) ou Rules-Based Machine Translation (RBMT) prend en
entrée des phrases dans une langue dite source pour produire en sortie
des phrases dans une langue dite langue cible. Cette traduction se base sur une
analyse morphologique, syntaxique et sémantique de la langue source et
cible impliquée dans la tâche de traduction.
Dans un RBMT, Le programme de traduction automatique va
associer des dictionnaires de mots courants ainsi que des règles
linguistiques et grammaticales pour procéder à la traduction. Il
arrive de même que la traduction obtenue avec un RBMT n'est pas à
la hauteur de nos attentes, il est cependant possible d'enrichir les
dictionnaires de mots afin d'améliorer la qualité de la
traduction. [ 2]

Source : Enquête de Barbara Vignaux(
https://www.liglab.fr/files/qa_traduction_auto_bd.pdf)
Figure 2 : traduction automatique à base de
règles
Les systèmes basés sur des règles
présentent un certain nombre d'avantages et inconvénients :
Avantages
l Rapidité dans la restitution de traduction;
l Vu que les différents paramètres de traduction
sont établis par l'humain, il est donc possible de les personnaliser
pour un résultat de traduction optimal.
Inconvénients
l La construction de nouveaux dictionnaires est
coûteuse.
Master Data Science - Big Data 9

l Élaboration manuelle de règles linguistiques,
qui peuvent être coûteuses;
l Il est difficile de gérer les interactions de
règles dans les grands systèmes, l'ambiguïté dans
dans la traduction des expressions idiomatiques;
l Incapacité d'adapter automatiquement la traduction
à un nouveau domaine, il va falloir revoir les règles de
traduction;
l Bien que les systèmes RBMT fournissent
généralement un mécanisme pour créer de nouvelles
règles pour étendre et adapter le lexique, les changements sont
généralement très coûteux et les résultats,
souvent, ne sont pas rentables.
2 - Traduction Automatique Statistique (TAS)
Dans les années 90, la puissance de calcul et la
capacité de stockage des ordinateurs ont connu un boom. Cela a
donné lieu à l'essor de la traduction automatique statistique
(TAS) ou Statistical Machine Translation (SMT). Cette technologie
génère des traductions basées sur des modèles
statistiques dérivés de grands corpus de textes bilingues, qui
ont commencé à être disponibles dans les années
90.
L'hypothèse initiale est que toute phrase d'une langue
est une traduction possible d'une phrase dans une autre langue. Si on traduit
depuis une langue source s vers une langue cible ( t) , le but est de
trouver la phrase cible (t) la plus appropriée pour traduire la phrase
source s . Pour chaque paire de phrases possible (s, t) , on
attribue une probabilité P(t|s) qui peut être
interprétée comme la probabilité qu' « un
traducteur» produise ( t) dans la langue cible, lorsque la phrase (s) a
été énoncée dans une langue source, ou autrement
dit, la probabilité que la traduction de s soit t.
En traduction automatique statistique, les modèles
probabilistes sont utilisés pour trouver la meilleure traduction
possible ( t*) d'une phrase source donnée s , parmi
toutes les traductions t possibles dans la langue cible. Il s'agit
alors d'appliquer des méthodes d'apprentissage statistiques afin
d'entraîner le système avec un corpus bilingue(composé
d'une langue source et d'une langue cible).

Source : Enquête de Barbara Vignaux(
https://www.liglab.fr/files/qa_traduction_auto_bd.pdf)
Figure 3 : traduction automatique statistique
Master Data Science - Big Data 10

Avantages
l Nécessite un effort humain minimal;
l Contrairement au RBMT, la traduction est basée sur
le calcul de probabilités de succession de mots ce qui rend la
qualité de traduction meilleure.
Inconvénients
l L'une des faiblesses de la TAS est le défi de
traduire des documents qui ne sont pas similaires au contenu des corpus de
formation;
l La traduction automatique statistique TAS fonctionne
généralement moins bien pour les paires de langues dont l'ordre
des mots est sensiblement différent.
3 - Traduction Automatique Neuronale (TAN)
L'intelligence artificielle (IA) envahit progressivement tous
les aspects de la vie et des affaires. Dans le monde de la traduction, la
traduction automatique neuronale(TAN) ou Neural Machine Translation (NMT) est
le nouveau venu. La TAN s'appuie sur les réseaux de neurones pour
obtenir des traductions plus précises en fonction du contexte,
plutôt que des phrases fragmentées traduites mot par mot.
Destinés à imiter les neurones du cerveau
humain, les neurones d'un système TAN peuvent apprendre et recueillir
des informations, établir des connexions et évaluer les
données d'entrée comme une unité entière. La TAN
effectue son analyse en deux phases : l'encodage et le décodage. Pendant
la phase d'encodage, le texte de la langue source est entré dans la
machine et ensuite convertit en vecteurs. Les mots qui sont similaires dans
leur contexte seront placés dans des vecteurs de mots comparables.
Ensuite, la phase de décodage transcrit les vecteurs dans la langue
cible de manière efficace et transparente. Tout au long du processus de
traduction, la technologie ne se contente pas de traduire des mots et des
phrases, mais traduit le contexte et les informations.
Le schéma ci-après illustre de façon
simplifiée le processus de fonctionnement d'une TAN.
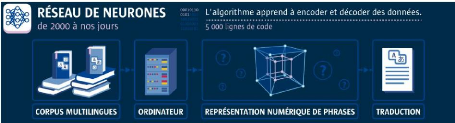
Source : Enquête de Barbara Vignaux(
https://www.liglab.fr/files/qa_traduction_auto_bd.pdf)
Figure 4 : Traduction automatique neuronale
Master Data Science - Big Data 11

Cette approche présente bien des avantages et
inconvénients. Avantages
l Traduit efficacement des langues grammaticalement
complexes, notamment le coréen, le japonais et l'arabe;
l Analyse complète d'une phrase avant traduction ce
qui permet de faire une traduction en employant des mots selon le contexte;
l Apprend les nuances des langues, telles que le genre et le
nombre;
l Aide à la rédaction multilingue, la
vérification des traductions et la vidéoconférence
multilingue.
Inconvénients
l Pour un apprentissage profond et pour une bonne
prédiction, l'on a besoin d'une grande quantité de données
au contenu diversifié pour permettre aux réseaux de neurones de
mieux se généraliser.
II - CHOIX D'UNE APPROCHE
1. Choix
Vu les caractéristiques, avantages et
inconvénients des approches sus présentées et vu notre
objectif qui est de mettre en place un système de traduction fiable par
l'utilisation des méthodes modernes de traduction, nous optons comme
choix la traduction automatique neuronale.
2. Motivations du choix
Nous avons porté notre choix sur la traduction
automatique neuronale car le système à mettre doit prendre en
compte certains aspects :
l Traduire des phrases tout en tenant compte du contexte dans
lequel les mots constituant la phrase sont employés ;
l Fournir des traductions fiables dans de brefs
délais;
l Permettre la traduction en temps réel;
Aux vues de ces aspects, la traduction automatique neuronale
s'avère la mieux adaptée à notre étude.
Master Data Science - Big Data 12

PARTIE III : DESCRIPTION DE LA
TRADUCTION
AUTOMATIQUE NEURONALE
Nous décrirons ici la traduction automatique
neuronale, qui est l'approche que nous avons retenue pour le traitement de
notre cas d'étude.
Master Data Science - Big Data 13

I- LA TRADUCTION AUTOMATIQUE NEURONALE
La traduction automatique neuronale ou Neural Machine
Translation (NMT) est une approche basée sur les réseaux de
neurones artificiels. Cette approche utilise une architecture appelée
sequence-to-sequence composée deux réseaux neurones
récurrents. [22]
1- Réseau de neurones artificiels
Ensemble de neurones formels (artificiels)
interconnectés permettant de construire un modèle d'apprentissage
automatique à partir d'exemples (données). Il est aussi
défini comme une modélisation mathématique du cerveau
humain.
a- Définition du neurone formel
Un neurone formel appelé aussi neurone artificiel est
une représentation artificielle d'un neurone biologique
De façon très réductrice, un neurone
biologique est une cellule qui se caractérise par
l Des synapses, les points de connexion avec les autres
neurones, fibres nerveuses ou musculaires ;
l Des dendrites ou entrées du neurone ;
l Les axones, ou sorties du neurone vers d'autres neurones ou
fibres musculaires ;
l Le noyau qui active les sorties en fonction des
stimulations en entrée.
Par analogie, Un neurone formel est une représentation
artificielle et schématique d'un neurone biologique :
l Les dendrites traduites par les entrées du neurone;
l Les synapses sont modélisées par des poids;
l Le soma ou corps cellulaire est modélisé par
la fonction de transfert, appelé aussi fonction d'activation;
l L'axone : l'équivalent de la sortie du neurone
artificiel.
Master Data Science - Big Data 14

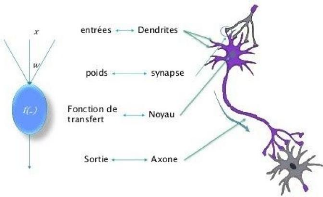
Figure 5 : Mise en correspondance neurone biologique /
neurone artificiel
b- Formulation mathématique du neurone
formel
Un neurone formel, au même titre qu'un neurone
biologique, reçoit plusieurs stimuli (xi) d'importances
différentes (les stimuli les plus importants sont munis de poids Wij
plus élevés), les analyse et fournit en sortie un
résultat.
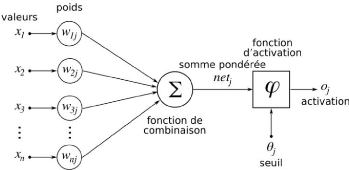
Figure 6 - Structure d'un neurone artificiel j
Description de la structure du neurone artificiel :
l Chaque poids possède une valeur notée . Cette
notation désigne le poids
allant d'un neurone formel i au
neurone formel j ;
l Chaque poids transmet une information/un stimulus provenant
du neurone source i noté ;
Master Data Science - Big Data 15

l Ce stimulus (sa valeur) correspondant à
l'information envoyé par le neurone source i est modulé
par le poids liant les neurones i etj. Mathématiquement cela se traduit
par :
l Ainsi le neurone j reçoit autant de stimuli
que de poids, dont il fait la somme
Si l'on note n le nombre de stimuli en entrée
du neurone j, une notation mathématique plus complète serait :
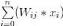
Cette expression se lit alors comme : la somme de toutes les
multiplications des valeurs des n entrées par les poids
associant ces entrées au neurone j considéré (
i prenant les valeurs : 0, 1, 2, ..., n)
C'est cette somme que le neurone formel j doit alors
traiter. Il utilise pour cela la fonction de transfert.
La fonction d'activation : Biologiquement, l'idée
d'une fonction d'activation vient de
l'idée de mimer le fonctionnement d'un potentiel
d'action d'un neurone biologique : si
l'ensemble des stimuli en entrée d'un neurone
atteignent le seuil d'excitabilité, alors ce neurone fournit une sortie
(il décharge).
Il existe un grand nombre de fonctions d'activation, telles que
:
l Sigmoïde : produit une courbe en forme de S. Bien que
de nature non linéaire, il ne tient toutefois pas compte des
légères variations des entrées, ce qui entraîne des
résultats similaires;
l Fonctions de tangente hyperbolique (tanh): Il s'agit d'une
fonction supérieure comparée à Sigmoïde. Cependant,
elle rend moins bien compte des relations et elle est plus lente à
converger;
l Unité linéaire rectifiée (ReLu): Cette
fonction converge plus rapidement, optimise et produit la valeur
souhaitée plus rapidement. C'est de loin la fonction d'activation la
plus populaire utilisée dans les couches cachées;
l Softmax: utilisé dans la couche de sortie car elle
réduit les dimensions et peut représenter une distribution
catégorique.
Master Data Science - Big Data 16

2- Type de Réseaux de neurones
Il existe différents types de réseaux de
neurones, nous nous évertuerons à présenter dans cette
partie les domaines d'applications des réseaux de neurones plus
populaires
:
a- Les réseaux de neurones à propagation
avant - Feed Forward Neural Networks (FFN)
Généralement utilisé pour des projets de
:
l Classification ;
l Reconnaissance faciale ;
l Vision par ordinateur ;
l Reconnaissance de la parole.
b- Les réseaux de neurones convolutionnels -
Convolutional Neural Network (CNN)
Ce type de réseaux de neurones est beaucoup
utilisé pour :
l Le traitement d'image ;
l La vision par ordinateur ;
l La Reconnaissance vocale.
c- Les réseaux de neurones récurrents -
Recurrent Neural Networks (RNN)
Ils sont utilisés pour :
l Le traitement de texte comme la suggestion automatique, les
vérifications de grammaire, etc.
l La mise en place de synthèse vocale ;
l Analyse des sentiments ;
l Traduction automatique.
Notre projet consistant à faire de la traduction
automatique de texte, nous allons dans la suite nous focaliser sur les
réseaux de neurones récurrents.
Master Data Science - Big Data 17

II- LES RÉSEAUX DE NEURONES
RÉCURRENTS
Les réseaux de neurones constituent aujourd'hui
l'état de l'art pour diverses tâches d'apprentissage automatique.
Ils sont très largement utilisés par exemple dans les domaines de
la vision par ordinateur, classification d'images, détection d'objets,
segmentation et du traitement automatique des langues (traduction automatique,
reconnaissance vocale, modèles de langage...). [ 10 ]
Le but ici c'est de décortiquer le réseau de
neurones récurrent - recurrent neural Network(RNN) afin d'en expliquer
leur fonctionnement.
1- Généralité
L'architecture globale des réseaux de neurones
récurrents tire son fondement de l'architecture du perceptron
multicouches (Multi-Layer Perceptron).
a- généralité sur Le perceptron
multicouches (MLP)
Les MLP sont des algorithmes de machine learning
supervisés. Ils prennent la description d'un objet en entrée, et
fournissent une prédiction en sortie. L'entrée est
représentée par un vecteur numérique, qui décrit
les caractéristiques ( features) de l'objet. Ce vecteur
traverse une succession de couches de neurones, où chaque neurone est
une unité de calcul élémentaire. La prédiction est
fournie en sortie sous la forme d'un vecteur numérique.
Dans le schéma suivant, une couche de MLP
reçoit en entrée un vecteur [a, b, c], et produit en sortie un
vecteur [h1, h2, h3, h4].
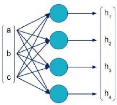
De façon simplifiée, nous pouvons
représenter une couche entière sous la forme d'une cellule. Le
schéma précédent devient alors :
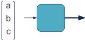
Master Data Science - Big Data 18

b- du perceptron multicouche au réseau de
neurone récurrent
Supposons maintenant que nous travaillions sur un objet
dynamique. Nous souhaitions prédire le futur à partir d'une
entrée. Les variables d'entrée [a, b, c] ne sont plus des valeurs
uniques mais des séquences. Par exemple, la variable a est une suite
chronologique de n valeurs (a1, a2, ..., an).
Comment un réseau de neurones peut-il traiter ce genre
d'entrées ?
Une façon naïve de procéder serait de
mettre à plat l'ensemble des valeurs dans un unique vecteur (a1, ...,
an, b1, ..., bn, c1, ..., cn), et de les fournir en entrée de la
première couche d'un MLP. Cependant les MLP ne font aucune distinction
dans l'ordre des valeurs d'une couche. Cette méthode équivaut
ainsi à mélanger toutes les valeurs : la dynamique temporelle
serait annihilée, la relation entre les valeurs successives prises par
a, b et c serait perdue. De plus, le nombre de paramètres à
apprendre sur la première couche augmenterait proportionnellement avec
la longueur des séquences. En bref, la performance ne serait pas au
rendez-vous.
C'est là que les réseaux récurrents
(RNN) entrent en jeu. Un réseau récurrent est un type particulier
de réseaux de neurones, particulièrement adapté aux
données séquentielles. Une couche récurrente est
représentée de cette façon :
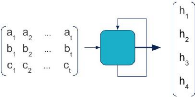
L'entrée est une séquence de vecteurs. Chacun
correspond à un incrément de temps. Une flèche en boucle
apparaît sur la cellule. En pratique, le RNN parcourt successivement les
entrées [a i, b i, c i ], et calcule des sorties intermédiaires
[h 1,i, h 2,i, h 3,i, h 4,i ]. Pour ce faire, il utilise non seulement
l'entrée courante, mais également la sortie calculée
précédemment [h 1,i-1 , h 2,i-1 , h 3,i-1 , h 4,i-1 ]. C'est la
signification de la boucle, qui symbolise le caractère récurrent
du RNN.

Master Data Science - Big Data 19

2- Architecture du réseau de neurones
récurrents - Recurrent Neural Network (RNN)
Pour une meilleure compréhension, nous utiliserons un
cas d'usage qui consiste à la génération de texte à
partir d'un texte initial en entrée.
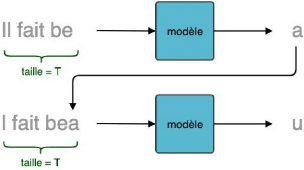
Figure 7: Génération de texte
caractère par caractère
Un RNN prend en entrée une séquence (donc une
matrice de taille (T x M)) et retourne en sortie un vecteur de taille R qui est
une représentation compressée de la totalité de la
séquence de caractères. [9 ]

Figure 8 : Traitement d'une séquence de taille T un
réseau de neurone récurrent
Où,
l taille_séquence (T) = nombre (fixe) de
caractères par séquence (dimension temporelle). Le choix de T est
empirique et il y a un compromis à trouver : si T est petit, le
modèle aura la « mémoire courte ». Si T est grand,
l'entraînement sera très long et pas toujours efficace;
l nb_variables (M) = taille de la représentation
vectorielle de chaque caractère. Chaque caractère est donc
représenté par un vecteur de taille M grâce à des
techniques ( one-hot-encoding, word embedding);
l La taille R est fonction du nombre de neurones dans une couche
dense qui est un hyperparamètre à choisir.
Générer le caractère suivant consiste
à choisir le caractère le plus pertinent parmi les M
caractères possibles. Il faut donc que notre modèle produise une
sortie de taille M. Ce vecteur de sortie associe alors à chaque
caractère une probabilité d'être le suivant dans la
séquence, étant donné les T caractères
précédents.
Pour obtenir cette distribution de probabilité, on
empile une couche de neurones classiques (Appelée également
couche dense) de taille M à la suite de la couche RNN et on utilise une
fonction d'activation softmax. Considérons l'exemple ci-dessous : la
séquence d'entrée étant « il fait be »,
la probabilité de sortie la plus élevée pourrait
correspondre à la lettre « a », dans l'optique de
générer la phrase « il fait beau ».

Figure 9 : Prédiction de la distribution de
probabilité du caractère suivant à partir d'une
séquence initiale
Détaillons maintenant ce qui se passe à
l'intérieur-même de la couche RNN. Une couche RNN est une
succession de T cellules. Chaque cellule a deux entrées :
l L'élément correspondant de la séquence :
la tème cellule est associée au tème caractère de
la séquence;
l Le vecteur en sortie de la cellule précédente.
La première cellule, qui n'a pas d'antécédent, prend alors
un vecteur initialisé aléatoirement
Master Data Science - Big Data 20
Master Data Science - Big Data 21

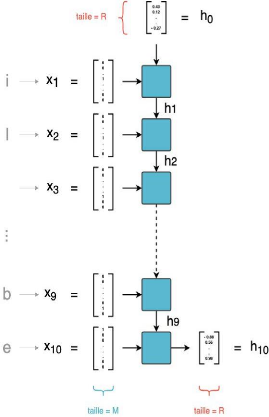
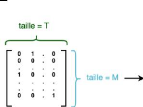
Figure 10 : Une couche RNN, prenant en entrée des
séquences de 10 caractères
Dans une couche RNN, on parcourt donc successivement les
entrées x 1 à xT . À l'instant t, la tème
cellule combine l'entrée courante xt avec la prédiction au pas
précédent ht-1 pour calculer une sortie h t de taille
R.
Le dernier vecteur calculé h T (qui est de taille R) est
la sortie finale de la couche RNN. Une couche RNN définit donc une
relation de récurrence de la forme :
ht = f(xt, ht-1)
Master Data Science - Big Data 22

3- Les Variantes du réseau de neurones
récurrents
Plusieurs variantes du RNN ont vu le jour pour remédier
aux problèmes rencontrés avec les réseaux de neurones
récurrents. Nous allons ici décrire le LSTM pour Long Short-Term
Memory et le GRU pour Gated recurrent unit.
a- Long Short-Term Memory - LSTM
L'idée derrière ce choix d'architecture de
réseaux de neurones est de diviser le signal entre ce qui est important
à court terme à travers le hidden state (analogue à la
sortie d'une cellule de RNN simple), et ce qui l'est à long terme,
à travers le cell state, qui sera explicité plus bas. Ainsi, le
fonctionnement global d'un LSTM peut se résumer en 3 étapes :
1. Détecter les informations pertinentes venant du
passé, piochées dans le cell state à travers la forget
gate ;
2. Choisir, à partir de l'entrée courante,
celles qui seront pertinentes à long terme, via l'input gate. Celles-ci
seront ajoutées au cell state qui fait office de mémoire longue
;
3. Piocher dans le nouveau cell state les informations
importantes à court terme pour générer le hidden state
suivant à travers l'output gate. Regardons cela de plus près. En
respectant la même convention que pour le schéma simplifié
de la cellule RNN, on peut représenter une cellule LSTM de la
façon suivante :
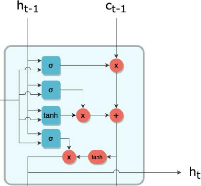
Figure 11 : Représentation simplifiée d'une
cellule LSTM
Master Data Science - Big Data 23

Comme le RNN, le LSTM définit donc une relation de
récurrence, mais utilise une variable supplémentaire qui est le
cell state c :
ht = f(xt, ht-1, ct-1)
L'information transite d'une cellule à la suivante par
deux canaux, h et c. À l'instant t, ces deux canaux se mettent à
jour par l'interaction entre leurs valeurs précédentes ht-1 et
ct-1 ainsi que l'élément courant de la séquence xt.
b- Gated Recurrent Unit - GRU
Variante du LSTM, le GRU :
l Combine les portes forget et input gate
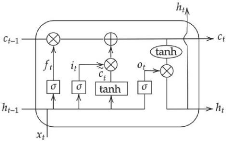
Figure 12 : Représentation simplifiée d'une
cellule GRU
Le GRU définit donc une relation de récurrence
établie comme suit : ht = (1 - zt) * ht-1 + zt * tanh(W · [rt *
ht-1, xt])
Où :
l zt : l'équation de la porte update gate
l W : le vecteur de poids.
Master Data Science - Big Data 24

III- MODÈLES NEURONAUX DE TRADUCTION
AUTOMATIQUE
Les modèles classiques de Deep Learning (ConvNet,
RNN...) ne pouvant alors être utilisés pour des tâches comme
la traduction automatique, le résumé de texte et le sous-titrage
d'images puisque leurs sorties sont de taille fixe, l'on assiste à
l'apparition de certains modèles beaucoup plus adaptés à
la résolu des problèmes sus cités.
1. Méthodologie
L'idée fondamentale d'un système NMT est de
prédire une séquence de mots Y=( y 1 ,...,
yt) dans la langue cible pour une phrase donnée de la langue
source
X=( x 1 ,..., x s ) . Cette
distribution de probabilité conditionnelle est modélisée
à l'aide de l'architecture encoder-decoder basée sur les RNN.
L'encodeur prend la phrase de langue source de longueur
variable et la convertit en un vecteur de longueur fixe. Ce vecteur de longueur
fixe contient la signification de la phrase d'entrée.
Le décodeur prend ensuite cet encastrement de phrase
(vecteur) comme entrée et commence à prédire les mots de
sortie en prenant en considération le contexte de chaque mot.
Mathématiquement, cette pensée peut être
représentée comme : log P ( y | x )=?
tk=1 log P ( yk | yk-1 , ... y 1 ,
x , c) (1)
où P ( y | x ) est la
probabilité d'obtenir un mot de la langue cible y pour un mot
donné de la langue source x , et c : le contexte de ce
mot particulier.
2. Le modèle sequence-to-sequence
Un modèle sequence-to-sequence(Seq2Seq) est un
modèle qui prend une séquence d'éléments (mots,
lettres, caractéristiques d'une image...etc) et qui produit une autre
séquence d'éléments en sortie. En traduction automatique
neurale, une séquence est une série de mots, traités les
uns après les autres. La sortie est, elle aussi, une série de
mots. [ 11 ]

Figure 13 : Représentation fermée d'un
modèle sequence-to-sequence
De quoi est composé le modèle sequence-to-sequence
?
Le modèle est composé d'un encodeur(encoder) et
d'un décodeur(decoder) tous deux réseaux de neurones
récurrents (RNN, LSTM ou GRU).
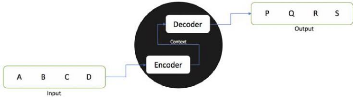
Figure 14 : Représentation ouverte d'un
modèle sequence-to-sequence
a- Description du fonctionnement
Pour une bonne compréhension du modèle
Sequence-to-sequence, nous prenons le cas d'usage consistant à traduire
par un modèle Sequence-to-sequence la phrase en anglais :
Excuse me vers le lingala : limbisa
ngaï
Nous résumons sur la figure ci-dessous les
différentes étapes de la traduction :
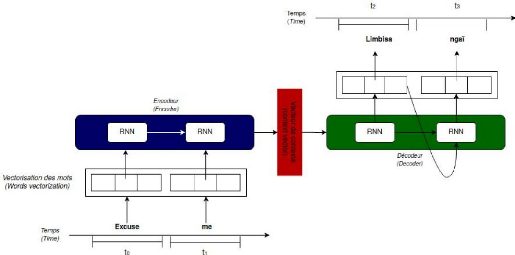
Figure 15 : Représentation détaillée
d'un seq2seq pour une traduction anglais vers lingala
Master Data Science - Big Data 25
Master Data Science - Big Data 26

Le principe général est le suivant :
4
a. Vectorisation des tokens de la séquence
entrée par l'utilisateur;
b. Lecture des vecteurs de mots :
- À t=0, la forme vectorielle de «Excuse» est
lu par le réseau de neurones; - À t=1, la forme vectorielle de
«me» est lu par le réseau de neurones;
c. Traitement des vecteurs de mots (word vector) par
l'encodeur qui va fournir en sortie un vecteur d'état appelé
vecteur de contexte(hidden state or context vector) de taille fixe (hidden_size
: 256, 512 ou 1024 à définir lors de la construction du
modèle);
e. Le vecteur de contexte contient donc toutes les
informations décrivant la séquence la séquence
initiale;
f. Il est alors mis en entrée d'un décodeur (un
autre RNN) qui va générer au fur et à mesure les
éléments constituant la séquence de sortie.
b- Procédés d'amélioration d'un
modèle Sequence-to-Sequence
Le modèle sequence-to-sequence présente un certain
nombre de limites notamment :
l Les informations de la source sont compressées dans
un vecteur de contexte de longueur fixe (le contexte);
l Vu la taille fixe du contexte, l'on constate
l'incapacité du modèle à gérer de longues phrases
ce qui conduit donc à de mauvais résultats.
Pour pallier ces problèmes, des procédés
applicables au modèle ont été mises en place afin
d'améliorer considérablement la qualité de traduction
fourni par le modèle sequence-to-sequence.
Il existe plusieurs procédés classiques
applicables à un modèle Sequence-to-sequence pour
améliorer sa performance. Le plus utilisé est le mécanisme
de l'attention.
3- le modèle `Transformer'
Le `Transformer' est un modèle d'apprentissage profond
introduit en 2017, utilisé principalement dans le domaine du traitement
du langage naturel.
Comme les réseaux neuronaux récurrents (RNN),
les `Transformers' sont conçus pour traiter des données
séquentielles, comme le langage naturel, pour des tâches telles
que la traduction et le résumé de textes. Toutefois,
contrairement aux RNN, les 'Transformers' n'exigent pas que les données
séquentielles soient traitées dans l'ordre. Par exemple, si les
données d'entrée sont une phrase en langage naturel, le
'Transformer' n'a pas besoin de traiter le début de cette phrase avant
la fin. Grâce à cette caractéristique, le `Transformer'
permet une parallélisation beaucoup plus importante que les RNN et donc
des temps de formation(entraînement) réduits.
Depuis leur introduction, les `Transformers' sont devenus le
modèle de choix pour résoudre de nombreux problèmes en
NLP, L'intérêt du `Transformer' réside dans le fait qu'il
fait largement appel à l'attention. Le mécanisme d'attention
permet à un réseau
4 Token : On appelle ici token les différents
mots constituant une phrase
Master Data Science - Big Data 27

de neurones d'apprendre à se focaliser sur certaines
caractéristiques d'une séquence en cours de traitement pour la
décision L'utilisation classique de l'attention vient du modèle
de traduction automatique, où la sortie est produite selon le contexte
des données en entrée. [ 12 ]
a. Architecture
Six encodeurs empilés, chaque encodeur prenant en
entrée la sortie de l'encodeur précédent (sauf le premier
qui prend en entrée les embeddings), suivi de six décodeurs
empilés, prenant en entrée la sortie du décodeur
précédent et la sortie du dernier encodeur (sauf pour le premier
décodeur qui ne prend en entrée que la sortie du dernier
encodeur). [ 15]
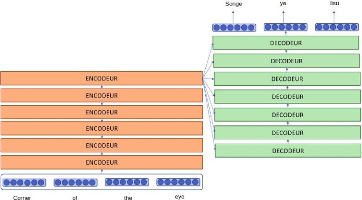
Figure 16 : Représentation simplifiée d'un
`Transformer'
b. Description
l Chaque encodeur se compose de deux sous-couches: une couche
d'auto-attention
5
suivie d'un FFNcomplètement connecté. Chaque
sous-couche possède en sortie une couche qui ajoute, additionne, les
sorties de la couche et du raccord à une connexion dite
résiduelle (qui connecte directement les valeurs d'entrée de la
couche à la sortie de la couche) et qui normalise l'ensemble;
l Chaque décodeur se compose de trois couches : une
couche d'auto-attention suivie d'une couche d'attention avec le dernier
encodeur, puis d'un FFN complètement connecté. Chaque sous-couche
possède en sortie une couche qui ajoute, additionne, les sorties de la
couche et du raccord à une connexion dite résiduelle (qui
connecte directement les valeurs d'entrée de la couche à la
sortie de la couche) et qui normalise l'ensemble.
5 FFN : Feed Forward Network
Master Data Science - Big Data 28

IV- EVALUATION D'UN MODÈLE DE TRADUCTION
AUTOMATIQUE
Nous présentons dans cette partie la métrique
utilisée pour l'évaluation de la qualité de la traduction
produite par les systèmes de traduction automatique.
1- La métrique BLEU
Le score BLEU «BiLingual Evaluation Understudy» est
la métrique utilisée pour l'évaluation d'un modèle
de traduction automatique. Il compare la traduction produite avec un ou
plusieurs fichiers de référence. Le calcul est basé sur
une comparaison de courtes séquences de mots(n-grammes), pour chaque
phrase du texte traduit et du texte de référence. En effet, le
BLEU score tient compte des correspondances entre les n-grammes et entre les
mots simples de la phrase traduite et de la phrase référence. Le
BLEU est une mesure de précision qui calcule le degré de
similitude entre une traduction et sa référence, en se basant sur
la précision n-grammes. Le score BLEU peut être exprimé en
pourcentage. [6]
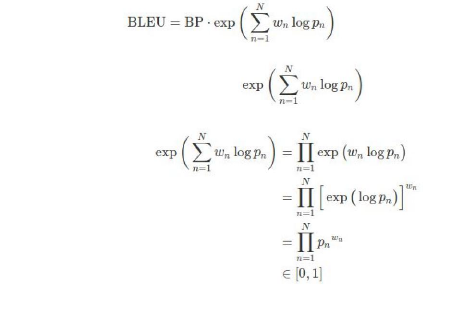
Réécrivons plus simplement l'expression :
On a :
Si la traduction produite par le traducteur est identique
à la traduction de référence, le score est égal
à 100. Dans le cas contraire, où aucune phrase traduite n'existe
dans la traduction référence, le score est égal à
0. Le BLEU est compris entre 0 et 1 et calculé suivant la formule
suivante :
Avec :
l BP : Brevity Penalty
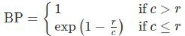
l c : Nombre de mot dans la traduction
proposée (phrase candidate)
l r : Nombre de mot dans la phrase servant
de référence (phrase de
référence)
l N : Nombre de n-grams pour le calcul du
BLEU : unigram, bigram, 3-gram, 4-gram
6
l Wn : Poids uniforme des différentes
précisions des n-grammes .
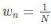
l Pn : Précision modifiée
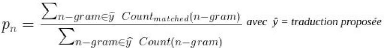
2- Exemple de calcul du BLEU Score
Source en anglais : Love each other like your
heavenly father loves you (x)
Référence en lingala : Bo lingana
boko basusu lokola tata na bino a lingui bino (y) Phrase
candidate : Bo lingana bo lingana boko basusu lokola tata na bino
lingui bino (j)
6 Un n-gramme : est une sous-séquence de
n éléments construite à partir d'une séquence
donnée.
Master Data Science - Big Data 29
Master Data Science - Big Data 30

a- calcul manuel
Nous nous proposons de faire un calcul manuel du score BLEU de
la traduction proposée par notre modèle
l Calculons la précision modifiée (P 1 ) des
unigrams :
Différents mots dans la
phrase
candidate
|
Nombre d'apparition dans la Candidate
|
Nombre d'apparition
dans la
Référence
|
P 1 = 10/12
|
Bo
|
2
|
1
|
|
2
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
2
|
2
|
|
1
|
1
|
|
12
|
10
|
|
Tableau 2 : Calcul de la précision modifiée
(P1) des unigrams
l Calculons la précision modifiée (P 2 ) des
bigrams :
Différents mots dans la
phrase
candidate
|
Nombre d'apparition dans la Candidate
|
Nombre d'apparition
dans la
Référence
|
P 2 = 8/11
|
Bo lingana
|
2
|
1
|
|
1
|
0
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
0
|
|
1
|
1
|
|
11
|
8
|
|
Tableau 3 : Calcul de la précision modifiée
(P2) des bigrams
Master Data Science - Big Data 31

l Calculons la précision modifiée (P 3 ) pour les
3-grams :
Différents mots dans la phrase
candidate
|
Nombre
d'apparition dans la
Candidate
|
Nombre d'apparition
dans la
Référence
|
P 3 = 6/10
|
Bo lingana bo
|
1
|
0
|
|
1
|
0
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
0
|
|
1
|
0
|
|
10
|
6
|
|
Tableau 4 : Calcul de la précision modifiée
(P3) des 3-grams
l Calculons la précision modifiée (P 4 ) pour les
4-grams :
Différents mots dans la phrase
candidate
|
Nombre d'apparition dans la Candidate
|
Nombre d'apparition
dans la
Référence
|
P4 = 5/9
|
Bo lingana bo lingana
|
1
|
0
|
|
1
|
0
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
1
|
|
1
|
0
|
|
1
|
0
|
|
9
|
5
|
|
Tableau 5 : Calcul de la précision modifiée
(P4) des 4-grams

Le résultat est donc le suivant :

b- Vérification du calcul manuel à
l'aide de la bibliothèque «nltk» de python
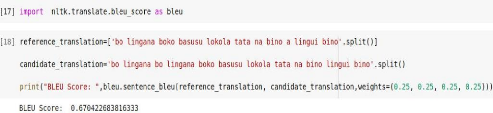
Nous remarquons à l'issu de la vérification que le
calcul manuel effectué correspond bien à celui effectué
via «nltk».
Master Data Science - Big Data 32
Master Data Science - Big Data 33

PARTIE IV : IMPLEMENTATION DU MODELE
DE TRADUCTION AUTOMATIQUE
Nous présenterons dans cette partie ci les
différentes étapes de l'implémentation de la plateforme de
traduction ainsi que les technologies utilisées.
Master Data Science - Big Data 34

I- PRÉSENTATION DU PROCESSUS GLOBALE DE
TRAITEMENT
1- Processus globale de traitement
La mise en place de notre système de traduction se
décline en plusieurs phases tel que présenté ci-dessous
:
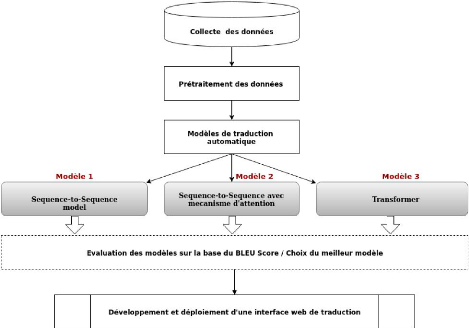
Figure 17 : Processus global de la mise en place de
l'outil de traduction
Master Data Science - Big Data 35

2- Prérequis
Nous décrivons dans cette partie les outils qui seront
utilisés pour l'implémentation de la plateforme de traduction.
l Le langage de programmation : Python
Le langage Python a été retenu pour
l'implémentation du système pour plusieurs raisons :
Dispose de plusieurs librairies de Machine Learning utilisables
dans le cadre de notre projet
Des Frameworks basés sur python tels que Django,
Flask facile à prendre en main et utilisables pour le
développement de l'interface web de traduction
Langage par excellence de notre structure d'accueil
l Bibliothèques Python : Keras et
Pytorch
Keras et Pytorch sont deux bibliothèques python
utilisables dans le cadre de la construction de modèles d'apprentissage
automatique basée sur les réseaux de neurones.
l Plateforme Cloud pour la formation du modèle
: Google Colaboratory Google Colab ou Colaboratory est un service
cloud, offert par Google (gratuit), basé sur Jupyter Notebook et
destiné à la formation et à la recherche dans
l'apprentissage automatique. Cette plateforme permet d'entraîner des
modèles de Machine Learning directement dans le cloud. Sans donc avoir
besoin d'installer quoi que ce soit sur votre ordinateur à l'exception
d'un navigateur.
l Plateforme pour le déploiement : Microsoft
Azure
Microsoft Azure est un ensemble de services cloud
destinés à aider les entreprises à relever les
défis auxquels elles sont confrontées. Il vous permet de
construire, de gérer et de déployer des applications sur un
énorme réseau mondial en optant pour des infrastructures et
outils favoris.
Master Data Science - Big Data 36

II- COLLECTE ET PRÉPARATION DES
DONNÉES
1- La collecte des données
Les données sont indispensables et primordiales pour la
formation(entrainement) d'un d'un modèle de machine learning.
Dans le cadre de notre projet nous avons eu recours au site web
intitulé OPUS dont le lien d'accès est
http://opus.nlpl.eu/ , pour la collecte de données.
a- OPUS
OPUS est une plateforme web proposant des corpus
parallèles en diverses langues et divers domaines.
Dans le cadre de notre projet nous y avons trouvé un
corpus parallèle (anglais - Lingala) des références
bibliques.
b- Caractéristiques du jeu de
données
l Les variables du jeu de données :
- Anglais (en) : les phrases en anglais;
- Lingala (ln) : la traduction en lingala des phrases en
anglais
l Quelques descriptions
|
:
|
|
|
|
|
|
|
|
|
en - ln
|
|
|
Nombre de phrases
(enregistrements)
|
|
|
|
537 792
|
|
|
Nombre Colonnes (variables)
|
|
|
|
2
|
|
|
Nombre de mots
|
8
|
623
|
680
|
|
23
|
715
|
120
|
Nombre de mots uniques
|
2
|
123
|
681
|
|
16
|
708
|
380
|
Taille sur disque du jeu
de
données
|
|
|
|
115 MO
|
|
|
|
Tableau 6 : Caractéristiques du jeu de
données
2- Préparation les données
La préparation des données est une étape
très importante dans la mise en place d' un modèle
d'apprentissage automatique. Elle consiste à nettoyer les données
afin de les
rendre idéales à la formation d'un modèle
d'apprentissage automatique. [ 17 ]
Dans notre étude la préparation des données
prend en compte les étapes suivantes :
a- Minuscules
La mise en minuscules de toutes les données textuelles
est applicable à la plupart des problèmes d'exploration de texte
et de NLP et contribue considérablement à la cohérence de
la sortie attendue. Les minuscules sont un excellent moyen de résoudre
les problèmes de parcimonie.
Voici un exemple de la façon dont les minuscules
résolvent le problème de parcimonie, où les mêmes
mots avec des cas différents correspondent à la même forme
minuscule :
CANADA Canada CanadA
|
Normalisé en minuscule
|
|
TOMCAT Tomcat toMcat
|
tomcat
|
|
Tableau 7 : Exemple de mise en minuscule des mots du
jeu de données b- Suppression du bruit
La suppression du bruit consiste à supprimer les
caractères, les chiffres et les morceaux de texte qui peuvent
interférer avec votre analyse de texte. La suppression du bruit est
l'une des étapes les plus essentielles du prétraitement de texte.
Il dépend également fortement du domaine.
Par exemple, dans les Tweets, le bruit peut être tous
les caractères spéciaux à l'exception des hashtags, car il
signifie des concepts qui peuvent caractériser un Tweet. Le
problème avec le bruit est qu'il peut produire des résultats
incohérents dans vos tâches en aval. Prenons l'exemple ci-dessous
:
Texte avec bruts
|
Texte sans bruits
|
|
..trouble..
|
trouble<
|
trouble
|
trouble
|
|
<a>trouble</a>
|
1.trouble
|
trouble
|
trouble
|
|
Master Data Science - Big Data 37
Tableau 8 : Exemple de suppression de bruts du jeu de
données
Master Data Science - Big Data 38

c. Harmonisation des écrits
L'harmonisation des écrits est une étape de
prétraitement très négligée. L'harmonisation des
écrits est le processus de transformation d'un texte en une forme
canonique (standard). Par exemple, le mot « gooood »
et « gud » peut être
transformé en «good», sa forme canonique. Un
autre exemple est la mise en correspondance de mots presque identiques tels que
« stopwords », « stop-words
» et « stop words » en simplement «
stopwords ».
L'harmonisation des écrits est importante pour les
textes bruyants tels que les commentaires sur les réseaux sociaux, les
SMS et les commentaires sur les articles de blog où les
abréviations, les fautes d'orthographe et l'utilisation des
Out-Of-vocabulary (oov) sont répandus. Voici un exemple de mots avant et
après la normalisation :
Texte initial
|
|
Texte harmonisé
|
|
|
|
2moro 2mrrw 2morrow 2mrw tomrw
|
|
tomorrow
|
b4
|
|
before
|
|
|
|
otw
|
|
On the way
|
|
|
|
|
smile
|
|
Tableau 9 : Exemple d'harmonisation des écrits du
jeu de données
d. Tokenisation
La tokenisation est l'une des tâches les plus courantes
lorsqu'il s'agit de travailler avec des données textuelles. Mais que
signifie réellement le terme "tokenisation" ? La tokenisation consiste
essentiellement à diviser une phrase, un paragraphe ou un document
textuel entier en unités plus petites, comme des mots ou des termes
individuels. Chacune de ces petites unités est appelée "token".
[ 13 ]
Exemple : Natural Language Processing --->
[`Natural','Language','Processing']
La tokenisation est l'étape la plus
élémentaire pour procéder au traitement de langue
naturelle. Cette étape est importante car le sens du texte pourrait
facilement être interprété en analysant les mots
présents dans le texte.
Il existe de nombreuses utilisations de cette méthode.
Nous pouvons utiliser cette forme tokenisée pour :
l Compter le nombre de mots dans le texte ;
l Comptez la fréquence du mot, c'est-à-dire le
nombre de fois qu'un mot particulier est présent et ainsi de suite.
Master Data Science - Big Data 39

e- Vectorisation
Le traitement de la langue naturelle nécessite la
conversion de la chaîne/du texte en un ensemble de nombres réels
(un vecteur) - Word Embeddings.
L'incorporation de mots (Word Embeddings) ou la vectorisation de
mots est une méthodologie de la NLP qui consiste à créer
une représentation vectorielle des mots d'une phrase en tenant compte
des similarités/sémantiques.
Le processus de conversion des mots en vecteur est appelé
vectorisation.
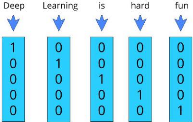
Figure 18 : Exemple de vectorisation d'une
entrée
3- Répartition des données
Dans l'optique d'évaluer notre modèle suite
à la phase d'apprentissage, nous allons faire une répartition des
données collectées afin qu'une partie de celles-ci serve à
l'apprentissage du modèle et une autre au test.
Dans notre cas nous avons fait la répartition comme suit
:
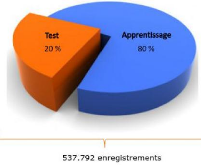
Figure 19 : répartition des données
l 80% de l'ensemble des données serviront à la
phase d'apprentissage;
l 20% seront utilisées pour la validation
III- CONSTRUCTION DU MODÈLE DE TRADUCTION
AUTOMATIQUE
1- présentation des différents
modèles construit
Nous résumons dans cette partie-ci les
différents modèles construit pour la résolution du
problème :
Dans l'optique d'avoir un modèle performant
c'est-à-dire un modèle avec lequel l'on pourra avoir une
traduction très proche d'une traduction humaine professionnelle, l'on a
construit plusieurs modèles de traduction automatique afin de comparer
leurs performances et d'y retenir le meilleur.
N°
|
Modèles
|
Modèle 1
|
Sequence-to-sequence
|
Modèle 2
|
Sequence-to-sequence avec mécanisme d'attention
|
Modèle 3
|
Transformer
|
|
Tableau 10 : Modèles de traduction
automatique
Nous présentons ci-après quelques
hyperparamètres des modèles construits et leurs valeurs :
Encoder Valeurs
RNN de type LSTM
Decoder
Classifier activation function RNN de type GRU
Source text embedding size
Target text embedding size 300
300
Encoder hidden size
Decoder hidden size 256
256
Learning rate 0.01
Master Data Science - Big Data 40
Tableau 11 : Quelques hyperparamètres des
modèles construits
IV- PRESENTATION DES RESULTATS
1- Evaluation
L'évaluation des modèles de traduction
automatique est extrêmement importante car elle est le facteur clé
qui détermine la qualité de la traduction. En
général, les résultats produits par un système de
traduction automatique sont évalués à la fois
automatiquement et manuellement. L'une des mesures d'évaluation
automatique les plus courantes est le BLEU score tel que décrit dans le
plus haut..
Nous résumons dans le tableau ci-après les
résultats obtenus des différentes architectures de modèle
de traduction automatique construites
|
N°
|
MODELES
|
BLEU Score
|
BLEU Score
|
|
|
(sur un ensemble de test au contexte biblique)
|
(sur un ensemble de test au contexte non biblique)
|
|

Modèle 1
Sequence-to-sequence
Modèle 2
Sequence-to-sequence avec mécanisme d'attention
0.4143
|
0.1111
|
0.598
|
0.232
|
0.787
|
|
|
|
|
Modèle 3
Transformer
Master Data Science - Big Data 41
Tableau 12 : Présentation des résultats des
différents modèles de traduction automatique
2- Commentaires
Suite à la comparaison des trois modèles
construits, nous constatons que le modèle 3 (Transformer) à des
performances meilleures que les deux autres modèles 1 et 2. Le score de
0.409 s'explique par plusieurs raisons :
l Quantité de données trop peu pour
entraîner un modèle de traduction automatique ;
l Modèle entraîné uniquement sur les
données bibliques et donc peu performant sur des jeux de données
ne se situant pas dans un contexte similaire au contexte biblique.
Pour une amélioration du modèle 3, nous
comptons collecter encore plus de données de contextes différents
et refaire l'entraînement du modèle.
Toutefois, pour des phrases bibliques, nous avons une
très bonne qualité de traduction.
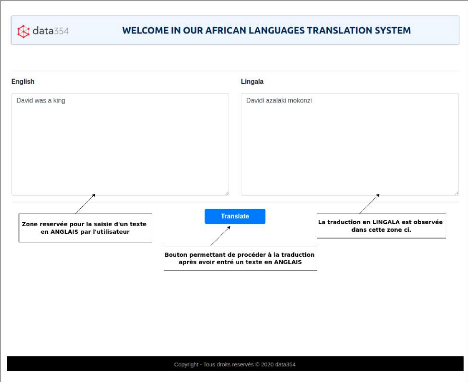
Master Data Science - Big Data 42

3- Interface et quelques traductions
a- Interface de traduction
L'interface de traduction présente comme suit :
Figure 20 : Interface web de traduction
l Une zone de texte à gauche:
Réservée à la saisie d'un texte en ANGLAIS par
l'utilisateur;
l Un bouton «Translate»: Permet au
système de procéder à la traduction après avoir
entrer le texte texte en ANGLAIS;
l Une zone de texte à droite : Dans
laquelle est observée la traduction en LINGALA du texte saisi.
Master Data Science - Big Data 43

b- Quelques traductions
Ci-après quelques traductions produites par le
modèle 3 (Transformer) :
|
Entrée
|
|
traduction produite par
le modèle
|
|
Traduction humaine
professionnelle
(texte de reference)
|
|
David was a king
|
|
Davidi azalaki mokonzi
|
|
Davidi azalaki mokonzi
|
|
|
|
|
|
|
Love each other like your
heavenly father loves
you
|
|
Bo lingana boko basusu lokola tata na bino a lingui bino
|
|
Bo lingana boko basusu lokola tata na bino a lingui bino
|
|
The king of Jerusalem was dead.
|
|
Mokonzi ya Yerusalémi akufaki
|
|
Mokonzi ya Yerusalémi akufaki
|
|
|
|
|
|
|
The feast took place that day in the royal
neck
|
|
Féti esalemaki mokolo yango na libanda ya ndako ya
mokonzi
|
|
Féti esalemaki mokolo yango na libanda ya ndako ya
mokonzi
|
|
The television newspaper takes place every evening at 8
p.m
|
|
Mayemi yango ezali na esika nyonso oyo ezali na kati ya
libándá 8
|
|
Basango na télé ezali ko pesama mokolo nionso na
m'pokua na ngonga ya muambe na sima ya zanga
|
|
|
|
|
|
|
My clinic appointment is
scheduled for
tomorrow
|
|
Nabongi mpo na kozwa esika ya liboso
|
|
Bo kutani na ngaï na kiliniki ezali nde lobi
|
Tableau 13 : Extrait de traduction machine et
humaine
Nous remarquons que les trois premiers textes bibliques ont
correctement été traduits, par contre les deux derniers textes
(dont le contexte n'est pas biblique) n'ont pas correctement été
traduits.
Master Data Science - Big Data 44

CONCLUSION GENERALE
De cette étude nous sortons très enrichi, car
elle nous a permis de mettre en pratique nos connaissances théoriques.
Par le thème qui nous a été confié, nous avons
exploré divers domaines : linguistique, informatique et
mathématique. La traduction automatique de langues est une innovation de
taille pour notre société actuelle car elle a permis de gagner du
temps dans la traduction de documents, de faire de la traduction en temps
réel à des conférences regroupant diverses
nationalités et aussi contribue efficacement à
l'éducation. Dans le cas de notre projet, les données
collectées nous ont permis de construire une première version
d'un modèle de traduction automatique de l'anglais vers le lingala qui
nous donne des résultats acceptables.
Afin de rendre le système actuel plus performant, nous
comptons collecter des données relatives à divers domaines
(médecine, éducation, informatique, etc...) dans l'optique
d'enrichir la base d'apprentissage du modèle et créer plutard des
services qui pourront apporter une rentabilité à l'entreprise.
Sous la responsabilité d'un directeur technique dynamique,
spécialiste des big data, le stage s'est déroulé dans de
très bonnes conditions. Le projet faisant l'objet de notre thème
s'est quasiment achevé, A présent il nous reste à le
parfaire et le déployer pour utilisation. Comme perspective nous
comptons généraliser le modèle à la traduction de
plusieurs autres langues africaines telle le dyula (dioula) qui est une langue
mandingue beaucoup utilisé pour le commerce dans certains pays tels la
Côte d'Ivoire, le Mali et le Burkina Faso.
Master Data Science - Big Data X

BIBLIOGRAPHIE
OUVRAGES
[1] Mahak Dureja ,
Sumanlata Gautam,Speech-to-Speech Translation : A Review,
International Journal of Computer Applications (0975 - 8887) Volume 129 -
No.13 , 2015.
[2] Barbara Vignaux ,
Traduction automatique, la révolution de
l'intelligence artificielle, 2017
[3] Daniel Jurafsky ,
James H. Martin,Speech and Language Processing, Third
Edition draft, 2017.
[4] FREDRIK BREDMAR ,
Speech-to-speech translation using deep learning,
Student essay, 2017.
[5] Mahak Dureja, Sumanlata Gautam,
Speech-to-Speech Translation :A Review, International
Journal of Computer Applications (0975 - 8887) Volume 129 - No.13, 2015.
[6] Kishore Papineni, Salim Roukos, Todd Ward, and
Wei-Jing Zhu,
BLEU: a Method for AutomaticEvaluation of Machine
Translation, Proceedings of the 40th Annual Meeting of the Association for
Computational Linguistics (ACL), Philadelphia, pp. 311-318., 2002.
[7] Maxime LORANT , Mathieu XHONNEUX
Développez votre site web avec le framework Django,
OpenClassrooms, 2015.
MEMOIRES
[8] TAPE Ange Fabien,
« Prévention du churn des clients
internetfixe : cas de la technologie TDD », mémoire de fin
d'étude pour l'obtention du Master en Data Science - Big Data, IDSI, 40
pages, 2018-2019.
[9] ZEGBOLOU Marc Dexter,
«Détection du multi-équipement des
abonnés mobile», mémoire de fin d'étude pour
l'obtention du Master en Data Science - Big Data, IDSI, 58 pages, 2018-2020
Master Data Science - Big Data XI

WEBOGRAPHIE
[10] Les réseaux de neurones récurrents :
des RNN simples aux LSTM,
https://blog.octo.com/les-reseaux-de-neurones-recurrents-des-rnn-simples-aux-lstm/,
consulté le 27 mai 2020 à 09:07
[11] Attention - Seq2Seq Model,
https://towardsdatascience.com/day-1-2-attention-seq2seq-models-65df3f49e263
, consulté le 10 juin 2020 à 22:40
[12] Neural Machine Translation with
Transformers,
https://medium.com/@galhever/neural-machine-translation-with-transformers-69d4bf918299
, consulté le 10 juin 2020 à 22:40
[13] How to Get Started with NLP - 6 Unique Methods to
Perform Tokenization,
https://www.analyticsvidhya.com/blog/2019/07/how-get-started-nlp-6-unique-ways-perform-tokenizatio
n/, consulté le 17 juin 2020 à 21:33
[14] All you need to know about text preprocessing for
NLP and Machine Learning,
https://www.kdnuggets.com/2019/04/text-preprocessing-nlp-machine-learning.html
, consulté le 17 juin 2020 à 22:15
[15] How Transformers Work,
https://towardsdatascience.com/transformers-141e32e69591
, consulté le 07 juillet 2020 à 10:10
[16] `Les Dieux du ${Code}` ,
https://lesdieuxducode.com/blog/2019/4/bert--le-transformer-model-qui-sentraine-et-qui-represente
, consulté le 07 août 2020 à 23:27
[17] Step 3: Prepare Your Data,
https://developers.google.com/machine-learning/guides/text-classification/step-3
, consulté le 10 août 2020 à 22:00
[18] Le plan d'un mémoire : quels
éléments intégrer ?
https://www.scribbr.fr/category/plan-memoire/,
consulté le 10 août 2020 à 22:33
[19] Google: L'intelligence artificielle s'applique
à améliorer la traduction automatique,
https://www.20minutes.fr/sciences/1934955-20161003-google-intelligence-artificielle-applique-ameliore
r-traduction-automatique, consulté le 20 août 2020 à
11:00
[20] Qu'est ce que la traduction automatique ?
Traduction à base de règles vs. traduction statistique,
http://www.systran.fr/systran/technologie/traduction-automatique/,
consulté le 25 août 2020 à 18:30
[21] L'intelligence artificielle au service de la
traduction automatique,
http://www.lefigaro.fr/secteur/high-tech/2016/12/07/32001-20161207ARTFIG00005-l-intelligence-artific
ielle-au-service-de-la-traduction-automatique.php , consulté le 27
août 2020 à 17:30
[22] La traduction neuronale, un nouveau standard ? -
Retour sur les premières rencontres de la communauté
internationale OpenNMT,
https://www.actuia.com/actualite/la-traduction-neuronale-un-nouveau-standard-retour-sur-les-premieres-rencontres-de-la-communaute-internationale-opennmt/,
consulté le 27 août 2020 à 20:00
Master Data Science - Big Data XII

ANNEXES
QUELQUES CAPTURES D'ÉCRANS
l
Figure 21 : Extrait du script de
traduction
Morceau du script de traduction
Master Data Science - Big Data XIII

l Extrait du corpus de textes parallèles
utilisé

Figure 22 : Extrait du corpus
parallèle
Master Data Science - Big Data XIV

l
Figure 23 : Extrait du script de l'encodeur et du
décodeur
Extrait du script de construction de l'encodeur et du
décodeur
Master Data Science - Big Data
XV

TABLE DES MATIERES
DEDICACES I
REMERCIEMENTS II
SOMMAIRE III
LISTE DES TABLEAUX IV
LISTE DES FIGURES V
LISTE DES ABREVIATIONS VI
GLOSSAIRE VII
AVANT-PROPOS VIII
RESUME IX
INTRODUCTION GENERALE 1
PARTIE I : ENVIRONNEMENT DE LA MISSION 2
I- PRÉSENTATION DE LA STRUCTURE D'ACCUEIL 3
1- Structure d'accueil 3
2- Les domaines de compétences de la structure d'accueil
3
II- PRÉSENTATION DU CAHIER DES CHARGES 4
1- Motivation du choix des langues 4
2- Objectif général 5
3- Objectifs spécifiques 5
III- PLANNING PREVISIONNEL 6
1- Planning du d'execution du projet 6
IV- ANALYSE DE L'EXISTANT 6
1- Constat 6
2- Commentaires 6
PARTIE II: ETUDE DES APPROCHES EXISTANTES DE TRADUCTION
AUTOMATIQUE ET CHOIX
D'UNE APPROCHE 7
I - PRESENTATION DES METHODES DE TRADUCTION AUTOMATIQUE 8
1 - La traduction automatique basée sur des règles
(RBMT) 8
2 - La traduction automatique statistique (TAS) 9
3 - La traduction automatique à neuronal (TAN) 10
II- CHOIX D'UNE APPROCHE 11
1- Choix 11
2- Motivations du choix 11
PARTIE III : DESCRIPTION DE LA TRADUCTION AUTOMATIQUE NEURONALE
12
I- LA TRADUCTION AUTOMATIQUE NEURONALE 13
1- Réseau de neurones artificiels 13
2- Type de Réseaux de neurones 16
II- LES RESEAUX DE NEURONES RECURRENTS 17
1- Généralité 17
2- Architecture du réseau de neurones récurrent -
Recurrent Neural Network (RNN) 19
3- Les Variantes du réseau de neurones récurrents
22
|
TANO Assandé Jacob
|
|
III- MODÈLES NEURONAUX DE TRADUCTION
AUTOMATIQUE
|
24
|
1- Méthodologie
|
24
|
2- Le modèle sequence-to-sequence
|
24
|
3- le modèle `Transformer'
|
|
26
|
|
|
IV- EVALUATION D'UN MODÈLE DE TRADUCTION AUTOMATIQUE
|
28
|
|
1- La métrique BLEU
|
28
|
|
PARTIE IV : IMPLEMENTATION DU MODELE DE TRADUCTION AUTOMATIQUE
|
33
|
|
I- PRÉSENTATION DU PROCESSUS GLOBALE DE TRAITEMENT
|
34
|
1- Processus globale de traitement
|
34
|
2- Prérequis
|
|
35
|
|
|
II- COLLECTE ET PRÉPARATION DES DONNÉES
|
36
|
1- La collecte des données
|
36
|
2- Préparation les données
|
|
37
|
|
|
3- Répartition les données
|
39
|
|
III- CONSTRUCTION DU MODÈLE DE TRADUCTION AUTOMATIQUE
|
40
|
|
1- présentation des différents modèles
utilisés
|
40
|
|
IV- PRESENTATION DES RESULTATS
|
41
|
|
1- Evaluation
|
41
|
2- Commentaires
|
41
|
3- Interface et quelques traductions
|
|
42
|
|
|
CONCLUSION GENERALE
|
44
|
|
BIBLIOGRAPHIE
|
.X
|
|
WEBGRAPHIE
|
.XI
|
|
ANNEXES
|
.XII
|
|
TABLE DES MATIERES
|
XV
|
Master Data Science - Big Data XVI


