c. Harmonisation des écrits
L'harmonisation des écrits est une étape de
prétraitement très négligée. L'harmonisation des
écrits est le processus de transformation d'un texte en une forme
canonique (standard). Par exemple, le mot « gooood »
et « gud » peut être
transformé en «good», sa forme canonique. Un
autre exemple est la mise en correspondance de mots presque identiques tels que
« stopwords », « stop-words
» et « stop words » en simplement «
stopwords ».
L'harmonisation des écrits est importante pour les
textes bruyants tels que les commentaires sur les réseaux sociaux, les
SMS et les commentaires sur les articles de blog où les
abréviations, les fautes d'orthographe et l'utilisation des
Out-Of-vocabulary (oov) sont répandus. Voici un exemple de mots avant et
après la normalisation :
Texte initial
|
|
Texte harmonisé
|
|
|
|
2moro 2mrrw 2morrow 2mrw tomrw
|
|
tomorrow
|
b4
|
|
before
|
|
|
|
otw
|
|
On the way
|
|
|
|
|
smile
|
|
Tableau 9 : Exemple d'harmonisation des écrits du
jeu de données
d. Tokenisation
La tokenisation est l'une des tâches les plus courantes
lorsqu'il s'agit de travailler avec des données textuelles. Mais que
signifie réellement le terme "tokenisation" ? La tokenisation consiste
essentiellement à diviser une phrase, un paragraphe ou un document
textuel entier en unités plus petites, comme des mots ou des termes
individuels. Chacune de ces petites unités est appelée "token".
[ 13 ]
Exemple : Natural Language Processing --->
[`Natural','Language','Processing']
La tokenisation est l'étape la plus
élémentaire pour procéder au traitement de langue
naturelle. Cette étape est importante car le sens du texte pourrait
facilement être interprété en analysant les mots
présents dans le texte.
Il existe de nombreuses utilisations de cette méthode.
Nous pouvons utiliser cette forme tokenisée pour :
l Compter le nombre de mots dans le texte ;
l Comptez la fréquence du mot, c'est-à-dire le
nombre de fois qu'un mot particulier est présent et ainsi de suite.
Master Data Science - Big Data 39

e- Vectorisation
Le traitement de la langue naturelle nécessite la
conversion de la chaîne/du texte en un ensemble de nombres réels
(un vecteur) - Word Embeddings.
L'incorporation de mots (Word Embeddings) ou la vectorisation de
mots est une méthodologie de la NLP qui consiste à créer
une représentation vectorielle des mots d'une phrase en tenant compte
des similarités/sémantiques.
Le processus de conversion des mots en vecteur est appelé
vectorisation.
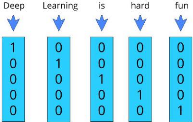
Figure 18 : Exemple de vectorisation d'une
entrée
| 

