2. DIAGRAMME DE CLASSE
Ce diagramme va nous permettre de fournir une
représentation des objets du système qui vont interagir ensemble
pour réaliser les cas d'utilisation vu plus haut.
|
PROJET DE FIN DE CYCLE MASTER 2
|
30
|
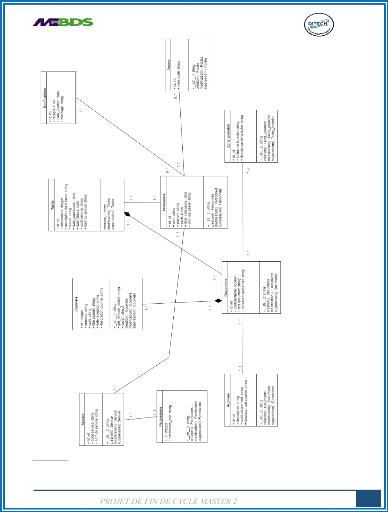
Figure 12: Diagramme de classe
PROJET DE FIN DE CYCLE MASTER 2
31

III. CONCEPTION DU MODÈLE DE CLASSIFICATION
Dans cette section, nous abordons les différentes
étapes de conception du modèle de
classification. Notre ensemble de données étant
étiqueté nous utiliserons l'apprentissage supervisé
pour la mise en oeuvre du projet. Nous avons passé en
revue les étapes suivantes :
- récupération de données;
- nettoyage des données ;
- sélection d'algorithmes de classification ;
- appliquer le modèle aux données pour
l'entraînement ;
- évaluation de modèles prédictifs.
1. LA RÉCUPÉRATION DES
DONNÉES
La récupération des données qui est
notre première étape cela consistera à la récolte
des données qui nous serviront à faire l'apprentissage de notre
modèle. En effet nous avons récupéré des
données sur kaggle pour l'essai de notre modèle [9].
2. LE NETTOYAGE DES DONNÉES
Le nettoyage des données consiste à redimensionner
toutes les images pour que les images aient les mêmes dimensions.


Figure 13: Nettoyage des données
3. LE CHOIX DE L'ALGORITHME DE
CLASSIFICATION
Le choix de l'algorithme dépend du problème
à résoudre, des caractéristiques des données et des
ressources de calcul et de stockage. Il est important de savoir que la
formation d'un modèle d'apprentissage automatique est un processus
itératif.
|
PROJET DE FIN DE CYCLE MASTER 2
|
32
|

Dans notre cas nous envisageons de faire la classification des
documents et de prédire la classe d'un document. Il existe plusieurs
types de classifications dans la famille de l'apprentissage supervisée
dont nous citerons quelques-unes :
- CNN ;
- arbre binaire.
3.1. RÉSEAU DE NEURONES CONVOLUTIFS (CNN)
Également appelés ConvNets, les CNN sont
constitués d'une multitude de couches chargées de traiter et
d'extraire les caractéristiques des données. De manière
spécifique, les réseaux neuronaux convolutifs sont
utilisés pour l'analyse et la détection d'objets. Ils peuvent
donc servir par exemple à reconnaître des images satellites,
traiter des images médicales, détecter des anomalies ou
prédire des séries chronologiques.

Figure 14: Epoch
Sur la figure ci-dessus nous avons l'application du
réseau de neurone convolutif. Il nous donne une précision de
0.9726 et l'estimation de l'erreur égal à 0.0827.
4. L'APPLICATION DU MODÈLE SUR LES
DONNÉES
Dans cette rubrique nous présenterons l'algorithme de
classification que nous avons appliqué sur nos données pour la
classification. Nous avons commencé par définir nos variables
d'entrainement. Nous avons découpé le jeu de données en
deux (02) groupes de données d'entraînement (train). Les
données du train font 2520 images et 372 images de test. Après le
découpage nous appliquons l'algorithme sur le modèle.
|
PROJET DE FIN DE CYCLE MASTER 2
|
33
|

Figure 15: Modèle
5. ARCHITECTURE D'APPLICATION DU
MODÈLE
La figure ci-dessous décrit le processus d'application
de l'algorithme sur les données. Il existe quatre types de couches pour
un réseau de neurones convolutif : la couche de
convolution, la couche de pooling,
la couche de correction ReLU et la couche
fully-connected (voir figure ci-dessous).
Figure 16: Réseau de neurone convolutif
[10]
PROJET DE FIN DE CYCLE MASTER 2
34

? La couche de convolution : C'est la
composante clé des réseaux neurones convolutifs et constitue la
première couche des CNN. Elle permet de transformer les images
d'entrées afin d'extraire des caractéristiques pour distinguer
correctement les documents.
? La couche de pooling : cette couche est
généralement placée entre deux couches de convolution.
L'opération de pooling consiste à réduire la taille des
images, tout en préservant les caractéristiques.
? La couche de correction ReLu : cette couche
a le rôle d'une fonction d'activation en remplaçant toutes les
valeurs négatives reçues en entrées par des zéros.
La fonction ReLu est : ReLu(x) = max(O, x)
? La couche fully-connected : la couche
fully-connected constitue toujours la dernière couche d'un
réseau de neurones, convolutif ou non - elle n'est donc pas
caractéristique d'un CNN. Elle détermine le lien entre la
position des features dans l'image et une classe.
|
PROJET DE FIN DE CYCLE MASTER 2
|
35
|

TROISIÈME PARTIE :
IMPLÉMENTATION

Dans cette section, nous définissons l'environnement de
travail et la réalisation des solutions.
| 

