1.2.3.2. Méthodologie de l'étude
Cette partie expose la méthodologie adoptée pour
notre étude qui porte sur les déterminants de l'accès des
populations aux mutuelles de santé : cas de la Commune
d'Abomey-Calavi et comprend cinq (05) parties telles que la
population cible, les variables de l'étude, les
techniques et outils de collecte des données, les outils d'analyse et
le traitement des données.
§ Population cible
La population cible de notre étude est celle
constituée par les ménages de la Commune d'Abomey-Calavi.
L'unité statistique est un ménage résidant dans la Commune
d'Abomey-Calavi. Un échantillonnage en grappes a été
utilisé.Les arrondissements constituent des grappes. Ce qui donne un
total de 09 grappes pour l'ensemble de la Commune. Pour ce faire nous avons
effectué un échantillonnage aléatoire.
Tableau 1.2 : Répartition
des ménages par arrondissement.
|
|
2002
|
2011
|
|
ARRONDISSEMENTS
|
POPULATION
|
NOMBRE DE MENAGES
|
Population
|
NOMBRE DE MENAGES PROJETES
|
|
AKASSATO
|
17197
|
3388
|
23032
|
4538
|
|
GODOMEY
|
153447
|
33130
|
205515
|
44372
|
|
GLO-DJIGBE
|
12827
|
2228
|
17179
|
2984
|
|
HEVIE
|
13450
|
2689
|
18014
|
3601
|
|
KPANROUN
|
7421
|
1631
|
9939
|
2184
|
|
OUEDO
|
10067
|
2011
|
13483
|
2693
|
|
TOGBA
|
18674
|
3471
|
25010
|
4649
|
|
ZINVIE
|
13212
|
2836
|
17695
|
3798
|
|
ABOMEY-CALAVI
|
61450
|
13217
|
82301
|
17702
|
|
TOTAL
|
307745
|
64601
|
412168
|
86521
|
Source : Données de l'enquête, juillet
2012
Ø Taille de l'échantillon :
Le calcul de la taille de l'échantillon
nécessaire pour faire une inférence sur la population
donne :
N= (z2.p.q)/ d2. (Formule de
Schwartz)
Ce qui donne un échantillon de :
[(1.96)2. (0.2). (0.8)] / (0.05)2 = 246
ménages.
P : proportion des ménages
concernés par le problème d'adhésion aux mutuelles de
santé : nombre total de ménages/ population totale = 0.2
Q : proportion des ménages qui ne sont pas
concernés par le problème d'utilisation des services de
santé est : 1-p = 0.5
Z : l'écart correspondant à un degré
de confiance de 95% (1.96)
D : le risque d'erreur (la précision absolue) =
5%
Pour ne pas tomber en dessous de la taille minimale qui
garantit la précision dans l'estimation des paramètres, cet
échantillon a été ramené à 300
ménages. Ces ménages ont été répartis de
manière proportionnelle à la taille de la population pour chacun
des arrondissements de la commune d'Abomey-calavi.
Le tableau 1.3 donne la répartition des ménages
enquêtés par arrondissement.
Tableau 1.3 : Répartition
des ménages enquêtés par arrondissement.
|
ARRONDISSEMENTS
|
NOMBRE DE MENAGES PROJETES
|
Pourcentage
%
|
Nombre de ménages enquêtés
|
|
AKASSATO
|
4538
|
5
|
16
|
|
GODOMEY
|
44372
|
51
|
154
|
|
GLO-DJIGBE
|
2984
|
3
|
10
|
|
HEVIE
|
3601
|
4
|
12
|
|
KPANROUN
|
2184
|
3
|
8
|
|
OUEDO
|
2693
|
3
|
9
|
|
TOGBA
|
4649
|
5
|
16
|
|
ZINVIE
|
3798
|
4
|
13
|
|
ABOMEY-CALAVI
|
17702
|
20
|
61
|
|
TOTAL
|
86521
|
100
|
300
|
Source : Données de l'enquête, juillet
2012
Les arrondissements les plus représentés dans
notre échantillon sont ceux de Godomey et d'Abomey-Calavi. Cette
représentativité s'explique par la forte densité de la
population de ces arrondissements dans celle de la Commune d'Abomey-Calavi.
§ Variables de l'étude
Nous exposerons la variable dépendante et des variables
indépendantes.
Variable dépendante
Il s'agit du choix d'adhésion des populations aux
mutuelles de santé. C'est une variable binaire. Le choix
d'adhésion peut être une acceptation ou un refus d'adhésion
à une mutuelle de santé.
Variables indépendantes
Les variables indépendantes retenues dans le cadre de
notre étude sont : l'âge du chef de ménage, sa
religion, son niveau d'instruction, son revenu, l'alternative de recours aux
soins, la qualité des soins de santé, l'appartenance à une
structure communautaire, l'état matrimonial du chef de ménage et
la taille du ménage. Ces variables peuvent être classées en
trois grandes catégories : les caractéristiques du
ménage, l'alternative de recours aux soins et l'accessibilité aux
soins de santé.
Ø Les caractéristiques du
ménage
Les caractéristiques du ménage concernent
l'âge, la religion, la taille du ménage, le niveau d'instruction
et le revenu du chef de ménage.
L'âge est considéré comme une
variable continue.
La religion est considérée comme un
facteur d'intégration sociale. Elle peut être en effet la source
d'un mouvement de solidarité. Elle est divisée en quatre
modalités : catholique, protestant, musulman, animiste et
autres.
La taille du ménage a été
retenue parce qu'elle peut influer sur la décision d'aller ou non se
faire soigner. En effet, lorsque la taille du ménage est grande et que
le revenu n'est pas suffisant, on réfléchit pour faire un choix
entre se faire soigner ou subvenir à d'autres besoins du ménage.
Ce qui peut ne pas être le cas lorsque la taille du ménage est
petite.
État matrimonial : il peut influer la
décision du CM à adhérer à une mutuelle de
santé. Elle a été divisée en quatre (4)
modalités à savoir : mariés, divorcés, veufs
(veuves) et célibataires.
Le niveau d'instruction quant à lui est
divisé en cinq modalités : primaire, collège,
supérieur, alphabétisé en langues locales, non
alphabétisé.
Le revenu du chef de ménage est un des
déterminants importants de la demande des soins dans un système
de santé dans la mesure où il peut accroître la
probabilité d'utiliser un service santé. Cependant, la mesure du
revenu est toujours une opération délicate. Il est difficile de
connaître avec précision le revenu d'une famille paysanne qui
produit elle-même ses moyens de subsistance et vend un surplus sur le
marché local; ou celui d'un ménage citadin dont les membres
tirent leurs ressources des petits métiers du secteur informel. Ainsi,
nous estimons le revenu grâce aux dépenses courantes des
populations. En effet, les dépenses courantes constituent une meilleure
mesure du revenu permanent car il est moins sensible aux fluctuations
temporelles. Pour pouvoir quantifier le revenu, nous l'avons
décomposé en plusieurs postes de dépenses tels que les
dépenses alimentaires, présence d'eau courante, moyens de
déplacements etc...
L'appartenance à une structure communautaire
peut motiver le choix d'adhésion d'un CM à une mutuelle de
santé.
Ø L'alternative de recours aux soins
Il s'agit ici de voir le mode choisi par le ménage pour
bénéficier des soins. Le ménage peut faire une
automédication (moderne ou traditionnelle) ou fréquenter un
centre de santé (moderne ou traditionnel). Le ménage qui
fréquente un centre de santé peut être prêt à
accepter une adhésion à une mutuelle, compte tenu des
difficultés qu'il a à s'octroyer des soins de santé.
Ø La qualité des soins
La qualité des soins reçus par un membre d'un
ménage est bonne ou mauvaise. Cette qualité est mesurée
par l'accueil accordé au patient lors des prestations et la
capacité des prestations à guérir la maladie dont il
souffre.
2.3. Techniques et outils de collecte de données
Après le choix de notre domaine d'étude, nous
avons fait une recherche documentaire et quelques entrevues avant de passer
à l'enquête proprement dite.
§ Recherche documentaire
La recherche documentaire a été permanente tout
au long de notre étude. Il faut signaler que très peu de
documents font le point sur les mutuelles de santé au Bénin.
Les centres de documentation visités pour collecter les
ouvrages qui nous ont permis d'approfondir le sujet sont ceux :
Ø du Ministère de la Santé Publique
(MSP).
Ø de la représentation du Fonds des Nations
Unies pour l'Enfance (UNICEF) au Bénin.
Ø de la représentation de l'Organisation
Mondiale de la Santé (OMS).
Il faut signaler enfin que quelques sites Internet ont
été consultés en vue d'une connaissance plus approfondie
du thème choisi.
§ Entrevues
Les entrevues avec des personnes ressources ont permis de
cerner certains aspects techniques sur les mutuelles de santé. Ces
entrevues nous ont ainsi permis de recueillir des données
nécessaires pour une bonne organisation et un meilleur
déroulement de notre travail de recherche.
§ Enquête
L'enquête sur questionnaire a été à
passage unique. Elle s'est déroulée dans le mois de juillet 2012.
Le questionnaire initial a été testé
avant d'obtenir la forme définitive présentée en annexes.
Les informations recueillies sont relatives à l'identification ;
à la description des ménages; au revenu du chef de ménage
(CM), aux comportements sanitaires et à l'appartenance à une
structure communautaire.
L'enquêteur, une fois arrivé dans un village,
essaye de choisir au hasard les ménages contactés dans la zone
ciblée, seuls ceux qui étaient présents et ont
accepté de répondre aux questions ont été pris en
compte.
§ Outils d'analyse
L'objectif de notre étude étant de
déterminer les variables significativement liées au choix
d'adhésion des populations à une structure mutualiste, trois
techniques d'analyse ont été utilisées pour tester les
résultats obtenus. Il s'agit de la description analytique, de l'analyse
bivariée et de l'analyse multivariée.
§ L'analyse descriptive
L'analyse descriptive a été utilisée pour
exposer les caractéristiques des ménages de l'échantillon.
Elle donne les répartitions des ménages selon les
différentes variables explicatives.
§ L'analyse bivariée
Les variables de notre étude étant nominales,
l'outil d'analyse utilisé ici est le Chi-carré de Pearson. Le
principe du test de Chi-2 est de prouver l'indépendance entre deux
variables qualitatives, à partir d'un tableau de contingence à L
lignes et C colonnes.
Pour vérifier cette liaison entre les deux variables,
on détermine pour chaque effectif calculé (Ec) dans
l'hypothèse d'indépendance, le produit total de sa ligne par le
total de sa colonne divisé par le total général.
Le Chi-2 calculé est donné par la
formule :
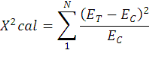
Pour l'ensemble des cases avec ET l'effectif
théorique. Le degré de liberté est déterminé
par la formule d.l = (L-1) x (C-1).
On choisit un seuil á et si la probabilité P
associée à la valeur du Chi-2 calculé est
inférieure à á, on rejette l'hypothèse
d'indépendance des variables concernées.
§ L'analyse multivariée
Les modèles économétriques à
variables dépendantes qualitatives peuvent se présenter sous
plusieurs formes (Amemiya, 1981 ; Griffiths et al, 1993) dont trois sont
les plus couramment utilisées : la fonction de
probabilité linéaire, la forme probit et la
forme logit (Amemiya, 1981, Maddala, 1983).
La fonction de probabilité linéaire est
inadéquate pour estimer les modèles de probabilité. Par
ailleurs le choix entre les deux modèles (Probit et Logit) est
difficile.
En effet Griffiths et al (1993), Amemiya (1981) Maddala
(1983), et Polson et Spencer (1991) sont arrivés à la conclusion
que les modèles probit et logit conduisent aux mêmes
résultats et la base de choix entre les deux modèles est
très limitée. La seule différence entre les deux
modèles réside dans la distribution du terme d'erreur qui suit
une loi normale pour le modèle probit et une loi logistique pour le
modèle logit.
Le modèle a été estimé par la
méthode de maximum de vraisemblance. La variable dépendante
étant une variable aléatoire, le modèle cherche à
déterminer la probabilité Pi que le chef de
ménage CMi accepte d'adhérer à une mutuelle de
santé, c'est-à-dire : Pi = Probabilité
(accepti = 1).
La décision d'adhérer à une mutuelle de
santé intervient seulement lorsque l'effet combiné des facteurs
atteint une valeur à partir de laquelle le CM accepte d'adhérer
ou non à une mutuelle de santé.
En supposant que l'effet est mesuré par un indice non
observable Ii pour le CMi et
I*i la valeur critique de l'indice à partir
de laquelle il accepte d'adhérer à une mutuelle de
santé :
(1)
Si
Icm >
I*cm, accept = 1
Icm =
I*cm, accept = 0
L'indice Icm pour le chef de
ménage (CM) est une combinaison linéaire de variables qui
déterminent le choix d'adhésion à une mutuelle de
santé et des coefficients inconnus (à estimer). Son expression
est :
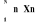
Icm = (2)
où Xcm représente la nième
variable indépendante qui explique le choix d'adhésion à
une mutuelle de santé par le CM et n le paramètre à
estimer correspondant à la variable Xcmi.
Si on désigne par B un vecteur des paramètres
à estimer et X un vecteur de variables indépendantes,
l'équation (2) devient : I = BX.
La probabilité Pi pour qu'un CM accepte d'adhérer
à une mutuelle de santé est alors
Pi = P (accept = 1).
L'indice I*i étant une
variable aléatoire, si on désigne par F(.) sa fonction de
probabilité cumulée, on a :
P (accept = 1) =P (I*i
Ii) = F (Ii)
P (accept = 0)= 1 - F (Ii)
(3)
La forme de F (.) est déterminée par celle de la
fonction de densité de probabilité de la variable
aléatoire Ii.
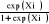
Pi s'obtient par : Pi = F (Xi) = .
Accepti
1 - accepti
La fonction de vraisemblance associée
s'écrit : [Maddala, 1983].
exp(xi)
1 + exp(xi)
1
1 + exp(xi)
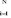
x
L (accepti, i ) =

L'estimation donne :
Accept(1) = CAM = 1 + 2 Agei
+3 Reli + 4 Niveinsi + 5
Etami +
6 ARSi + 7 Quali
+ 8 ASCi + 9 LogRevi +
10 Taillei
La fonction ainsi estimée permet de calculer la
probabilité
1
1 + e-accepi
Prob (accepi) =
Les différentes variables du modèle Logit et
leur niveau de mesure sont résumés dans le tableau 1.4
Tableau 1.4 : Liste des variables
indépendantes, leur niveau de mesure et leur signe attendu.
|
N°
|
Désignation
|
Mesure
|
Explication et niveau de mesure
|
Signe attendu
|
|
1
|
Age
|
Continue
|
Age du CM mesuré en années
|
+
|
0
Rel trad
Autre
Catholique
1
Musulman
Protestant
|
+
|
|
|
|
|
3
|
Niveins
|
Binaire
|
Alphabétisé : 1
Non alphabétisé: 0
|
+
|
0
Divorcé, veuf (ve)
Célibataire
|
+
|
|
|
|
|
|
5
|
ARS
|
Binaire
|
Centre de santé : 1
Auto médication; praticien de la médecine
traditionnelle : 0
|
+
|
|
6
|
Qual
|
Binaire
|
Qualité de soins reçus par les membres
du ménage
Bonne : 1 faible : 0
|
-
|
|
7
|
Taille
du ménage
|
continue
|
Nombre d'individus vivant
dans un ménage
|
+
|
|
8
|
RevCM
|
continue
|
Revenu mensuel moyen du CM en FCFA
|
+
|
|
9
|
ASC
|
Binaire
|
Membre
d'une structure communautaire
Oui : 1
Non : 0
|
+
|
Source : Nos enquêtes, juillet, 2012
§ Estimation du modèle logit et tests
statistiques
Le modèle Logit est estimé par la méthode
itérative du maximum de vraisemblance. Pour apprécier la
significativité des coefficients et la qualité de l'estimation,
trois tests ont été faits :
Ø Test sur les paramètres individuels
Le test classique T de Student reste valable dans le cas des
modèles Probit et Logit et permet de tester l'hypothèse nulle
selon laquelle le coefficient n est égal à zéro.
Ø Test sur les signes
Il s'agit de vérifier si les signes des
paramètres concordent avec ceux prédits par les hypothèses
de base. Ce test n'a de sens que pour les paramètres significativement
différents de zéro (Liao 1994).
Ø Test sur la qualité de l'estimation
Contrairement aux régressions classiques, où un
test unique F suffit pour tester la qualité de l'estimation, pour les
modèles Logit et Probit, il n'existe pas de test unique optimal (Amemiya
1981, p.1503).
Nous avons choisi le test de ratio du Maximum de vraisemblance
(LR) et le pourcentage de prédictions exactes comme mesures de la
validité du modèle.
v Test du ratio du Maximum de vraisemblance
Le test est basé sur l'hypothèse que chaque
coefficient estimé est nul, toutes choses étant égales par
ailleurs. Si l'hypothèse est retenue, on conclut
que la variable associée n'a aucun effet sur le
phénomène étudié. Dans ce cas la statistique LR
suit la loi de Chi-2 à k degré de liberté (où k est
le nombre de variables introduites dans le modèle).
LR = -2 [Log L(0) - Log L()].
Si LR > X²lu dans la table, alors on rejette
l'hypothèse que tous les coefficients n sont égaux à
zéro et on accepte qu'il existe au moins un coefficient
significativement différent de zéro.
Aussi, pour un seuil de significativité égal
à 5% donné, la statistique LR est significative si la
probabilité critique P est inférieure à .
v Test de pourcentage de prédictions exactes
Plus ce pourcentage est élevé, plus le
modèle est valide.
§ Traitement des données
Le traitement des données se décompose en
plusieurs phases à savoir :
Ø la codification des données collectées
à l'aide d'un guide code préétabli,
Ø la vérification des données
codifiées,
Ø la saisie informatique des données
codifiées,
Ø la vérification de la saisie par pointage et
correction des erreurs de saisie identifiées ;
Ø sortie des premières fréquences et
correction des erreurs ;
Ø réalisation des régressions.
La saisie a été faite dans le Logiciel Excel et
les analyses faites avec le logiciel de traitement économétrique
EVIEWS.
| 

