Chapitre 2. Les algorithmes de création de
communautés
Les deux éléments de validation de ces
communautés sont les suivants :
? La cohérence interne sur le critère de
regroupement doit être la plus élevée possible ;
? La cohérence externe sur le critère de
regroupement doit être la plus faible possible.
Autrement dit, les communautés doivent apparaître
comme les plus homogènes possibles et posséder une grande
distance entre elles.
2.2.1 Les algorithmes séparatistes
Le partitionnement de graphes
Le partitionnement de graphes est sans doute le moyen le plus
ancien d'effectuer un découpage dans un graphe. Le fait que l'on
prédétermine avant tout le nombre d'ensembles à
créer peut faire douter qu'il s'agisse vraiment de regroupement. En
effet, la première règle (nombre de communautés dans le
graphe) n'est pas une règle liée aux caractéristiques des
communautés à créer mais aux caractéristiques du
graphe lui-même. Le plus célèbre des algorithmes de
partitionnement est le « min cut » de Kernighan et Lin
[Kernigha&al-1970] (cf. figure 2.1).
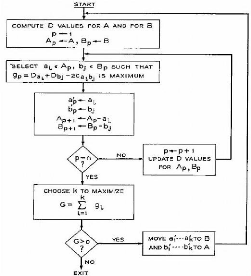
Figure 2.1 : Algorithme récursif tel que
présenté en 1970 par Kernighan et Lin pour le partitionnement de
graphe [Kernigha&al-1970].
Parfois aussi appelé algorithme de « migration de
groupe », il calcule itérativement, pour chaque noeud et chaque
déplacement entre communautés, le coût du
déplacement. Ce coût est généralement le rapport
entre le nombre de liaisons inter-communautés créées et le
nombre de liaisons intra-communautés créées. Puis, il
identifie le noeud qui produit la plus grande baisse ou la plus petite
augmentation dans ce coût. Ensuite, il fait l'échange et
répète
2.2. Les partitions ou communautés sans recouvrement 52
Chapitre 2. Les algorithmes de création de
communautés
le processus en utilisant la nouvelle partition comme
partition initiale jusqu'à ne plus trouver de partition de coût
inférieur.
La figure 2.1 décrit cet algorithme où
G(V,E) est un graphe constitué de l'ensemble V des
noeuds du graphe et de E l'ensemble des paires
d'éléments de V représentant les liaisons.
L'algorithme démarre à partir de X communautés de
taille équivalente qui scindent G en X partitions. Ces
communautés sont générées aléatoirement et
précédemment à la partie de l'algorithme
présenté.
L'algorithme va optimiser deux communautés A
et B parmi X entre elles. Dans une première
phase, l'algorithme copie les deux communautés A et B
dans deux communautés de travail Ap et
Bp.
Nous définirons un noeud « a »
présent dans la communauté Ap,
'a comme la somme des liens entre le noeud a et
les autres noeuds de communautés Ap,
Ea comme la somme des liens entre le noeud a et les
autres noeuds de communautés Bp.
Da = Ea -
'a ou Da est la différence pour
le noeud « a » entre les liens externes et internes
Supposons maintenant un noeud « b »
appartenant à la communauté Bp, en cas
de permutation p des noeuds a et b le gain G
de la permutation p sera de Gp=
Da- Db - 2Ca,b, où Ca,b
est le coût possible de la relation entre les noeuds a et
b.
Dans une première boucle l'algorithme va tester
l'ensemble des permutations possibles en recherchant la permutation donnant le
plus grand gain Gp. Cette permutation est effectuée
et ainsi de suite tant qu'il existe des permutations ayant un gain positif.
Enfin, dans une dernière phase, si le coût de
l'ensemble des liaisons dans les nouvelles communautés
Ap et Bp est supérieur à
celui des communautés A et B, celles-ci remplacent les
communautés de A et B. Il est ensuite possible de
relancer l'algorithme en comparant deux autres communautés de X,
jusqu'à ce qu'il n'y ait plus d'amélioration possible.
Le partitionnement de données
Contrairement au partitionnement de graphe, le partitionnement
de données est essentiellement utilisé sur des graphes
pondérés. La pondération étant alors
utilisée comme une valeur distanciatrice entre les sommets. Les
algorithmes de partitionnement de données ou « data clustering
» vont ensuite regrouper les noeuds en fonction de leur
proximité.
Une des méthodes consiste à utiliser ces «
distances » comme un système de localisation dans un espace
Euclidien de n dimensions relativement les unes par rapport aux autres
et de regrouper ensuite les sommets par zones pour créer des
communautés de « voisinage »
[Jain&al-1999].
Communautés créées à partir
d'une vision hiérarchique du graphe
Créer des communautés à partir de la
vision hiérarchique d'un graphe consiste à transformer le graphe
en un dendrogramme (arbre représenté par une succession de
fourches). Pour cela, on considère au départ chaque sommet de
l'arbre comme une communauté. On
2.2. Les partitions ou communautés sans recouvrement 53
Chapitre 2. Les algorithmes de création de
communautés
lance ensuite un algorithme qui va rechercher pour chaque
communauté, celle qui lui sera la plus proche. Ces deux
communautés seront alors intégrées pour en créer
une nouvelle. On traite ainsi toutes les communautés de même rang
puis on recommence jusqu'à n'avoir qu'une communauté.
On relie ensuite les communautés de départ entre
elles. La règle de rapprochement est variable. Elle peut être
basée sur la présence de liens communs entre les sommets, ou sur
le nombre de liens entre tous les sommets d'une communauté vers une
autre. On peut aussi utiliser la notion de centralité (centroïd) et
définir une valeur des liens en fonction de la distance au centre, comme
dans la méthode de Ward [Ward-1963]. Dans le cas d'un
graphe pondéré, on peut, bien sûr, faire intervenir les
valeurs de pondération pour choisir les communautés à
rapprocher.
Il suffira ensuite de choisir un niveau de séparation
pour obtenir plus ou moins de communautés. Ce nombre pouvant alors aller
de une (obtenue par l'agglomération de toutes les communautés de
départ), au nombre de sommets de l'arbre constituant les
communautés de départ.
Dans les communautés créées à
partir d'une vision hiérarchique du graphe, celles fondées sur la
marche aléatoire sont particulièrement pertinentes et vont
constituer la base de nombreuses autres méthodes. Ces méthodes
considèrent qu'un promeneur va potentiellement de noeuds en noeuds de
façon aléatoire. En fonction de sa position il a donc toujours la
possibilité d'emprunter une liaison pour se rendre sur un des noeuds
voisins, il peut bien sûr faire aussi marche arrière. La
méthode va donc permettre de définir des promenades plus ou moins
probables et donc des ensembles de noeuds plus probables que d'autres. De ces
ensembles vont naître les communautés [Pons&al-2005]
[Pons-2007]. Deux noeuds sont alors dans la même
communauté si, depuis leurs positions, un promeneur a une
probabilité maximale de faire une promenade identique ou des promenades
très proches. Le niveau de découpage sera ensuite choisi comme
étant celui procurant la plus grande qualité. Le coefficient de
qualité ou l'élément de vérification étant
souvent basé sur les valeurs de modularité.
La méthode est remarquable à plus d'un titre :
elle intègre une vision «agglomérative» nouvelle
à la vision séparatiste de départ. En effet, la position
de départ est locale et les « promenades » construisent la
communauté en ajoutant les noeuds explorés. La démarche
reste cependant séparatiste de par le fait que le nombre des
communautés et donc des partitions est préalablement
fixé.
| 

