I.4. Simulation n°4
Données des individus actifs :

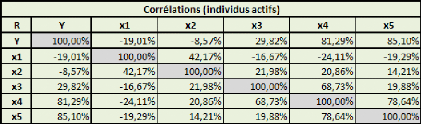
Données de la population mère :
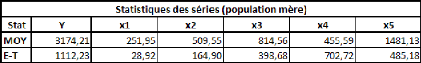
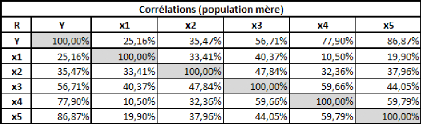
Il n'y a rien à ajouter sur ces données, quand on a
déjà vu (dans les précédentes simulations) à
quel point les séries étaient instables.
Partie 3: Simulations
Passons aux
caractéristiques des modèles et composantes afin de discuter des
critères :
Au regard de ce critère, il semble intéressant de
retenir deux composantes, les 3 dernières n'apportant rien
d'intéressant en terme d'explication de la variance de Y.
Voyons à présent l'inertie des composantes :

Ici, il semblerait qu'il soit préférable de retenir
4 composantes.
Dans une optique de compromis, nous retenons arbitrairement 3
composantes (2 ou 4 composantes auraient également pu se
justifier).

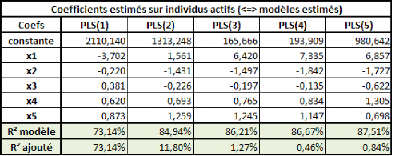
Voyons donc les résultats des différents
modèles :
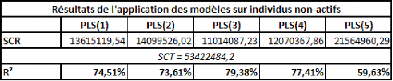
Dans l'ensemble, les modèles ont des résultats
plutôt moyens. Néanmoins, cette fois, les critères nous ont
conduits au choix du meilleur modèle.
La régression linéaire est celle qui obtient le
plus mauvais résultat. Les meilleurs résultats possibles
étaient les suivants :
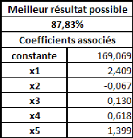
Le modèle choisi est bien entendu celui qui s'en approche
le plus.
De toutes les simulations effectuées, celle-ci est
celle qui présente la population mère la moins bien
modélisable. Il est donc normal que les résultats des
différents modèles testés soient moins bons dans
l'ensemble que ceux des simulations précédentes.

I.5. Conclusions sur le test n°1
Il est à présent temps de conclure sur l'ensemble
des simulations effectuées dans le cadre de ce premier test.
Le tableau suivant nous donne pas mal d'indications :
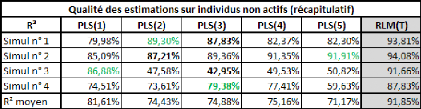
La colonne RLM(T) représente le R2
obtenu par régression linéaire multiple sur les individus non
actifs pour chaque simulation. Il s'agit du meilleur score possible à
obtenir, en termes de R2, par une régression de type
linéaire.
En vert est systématiquement indiqué, pour
chaque simulation, le meilleur modèle (parmi les 5 modèles
proposés par la régression PLS) obtenu àpartir de
l'échantillon.
En gras est systématiquement indiqué le
modèle PLS correspondant au nombre d'étapes retenues au regard
des critères.
On remarque plusieurs choses :
- Le meilleur modèle n'est jamais le même sur deux
simulations différentes.
- Le meilleur modèle n'a été choisi
qu'à une seule reprise à l'aide des critères.
- En général, le meilleur modèle se situe
environ à 5% du meilleur résultat possible. - Le modèle de
régression linéaire n'est le meilleur qu'à une seule
reprise.
- En moyenne, les résultats obtenus à l'aide du
modèle choisi (sur base des critères utilisés) est
meilleur que ne le sont les résultats de la régression
linéaire. C'est notamment le cas pour la simulation n°4, sans
laquelle cette remarque ne tiendrait plus. - En moyenne, c'est le modèle
PLS(1) qui obtient les meilleurs résultats.
- En moyenne, c'est le modèle PLS(5) qui obtient les plus
mauvais résultats.
- Les résultats varient peu, aussi bien au cas par cas
qu'en moyenne, s'agissant des modèles à 2, 3 et 4 composantes. On
pourrait facilement inclure la 5ème composante à ce
raisonnement si on ne tenait pas compte de la 4ème
simulation.
Les résultats sont donc très nuancés pour
cet exercice. L'utilité de la méthode semble pourtant
réelle, puisqu'en moyenne, la régression linéaire est
celle qui présente les moins bons résultats, et qu'en moyenne, le
modèle choisi est meilleur que le modèle de régression
linéaire. Mais ces résultats tiennent trop à la
présence de la 4ème simulation que pour être
jugés fiables.
On note néanmoins une certaine robustesse de l'approche
PLS vu les résultats obtenus à la première
étape.
Notons aussi que si on observe les coefficients trouvés
par les modèles, quels qu'ils soient, on se trouve devant un souci
évident d'interprétation, et il semble difficile de savoir si un
modèle est plus fiable ou non qu'un autre.
Voici un tableau retranscrivant les écarts-types
observés par les coefficients sur l'ensemble des simulations :
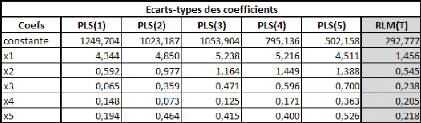
On note qu'excepté s'agissant de la constante, les
écarts-types sont nettement plus faibles pour la régression
PLS(1). Plusieurs d'entre eux sont même inférieurs aux
écarts - types observés pour les régressions faites sur
les individus non-actifs, ce qui est réellement impressionnant vu que la
taille de l'échantillon est 4 fois inférieure à la taille
de la population formée par les individus non-actifs.
Il est important de noter que la régression
linéaire (ou PLS(5)) est celle qui présente les coefficients les
plus instables, constante exceptée. Il s'agit là d'une relative
illustration de l' « opportunisme » de la méthode.
Pour en conclure sur ce test, nous retiendrons surtout que les
composantes aléatoires qui sont à l'origine de la création
des séries sont probablement nettement trop élevées que
pour obtenir des résultats suffisamment représentatifs de
l'efficacité des méthodes.
Ce tableau, confrontant les moyennes observées sur les
séries et les espérances de ces mêmes séries, le
confirme :
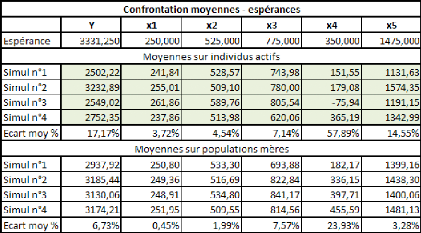
La colonne «Ecart moy 96 » calcule l'écart
relatif moyen (en valeur absolue) des moyennes considérées par
rapport à l'espérance de la série.
On note une forte instabilité générale
des séries. Les séries x1 et x2 sont les seules à
présenter une instabilité relativement faible. La série x5
présente quant à elle une instabilité acceptable. En
revanche, les séries x3, x4 et y sont considérablement instable,
particulièrement la série x4, ce qui est normal si l'on se
réfère à sa répartition en terme de degrés
d'aléa (le terme constant y est résiduel).
S'il est normal de constater des écarts significatifs sur
un échantillon de 10 individus, il l'est moins s'agissant d'une
population mère de 50 individus.
Le deuxième test que nous allons effectuer se fera en
conséquences avec des composantes aléatoires amoindries.
| 

