II. Test n°2
Comme il l'a été expliqué à la fin
du premier test, il est nécessaire de travailler avec des données
moins aléatoires, et notamment avec des relations moins
aléatoires entre les séries. Ce sera donc l'objet de ce second
test.
La seule différence avec le premier test va donc
résider dans les relations génériques entre les variables.
Le nombre de variables, d'individus actifs, d'individus au sein de la
population mère, et de simulations ne changeront donc pas.
Prenons donc, cette fois, les relations suivantes :
xi = 225 + 50*ALEA()
x2 = 125 + 50*ALEA() + ALEA()*xi + xi
x3 = 0.5*xi + ALEA()*xi + 0.5*x2 + ALEA()*x2
x4 = -50 -- 0.75*xi -- 1.5*ALEA()*xi + 0.5*x3 + ALEA()*x3
x5 = 125 + 50*ALEA() + 1.25*xi + 2.5*ALEA()*xi + x2 + 0.25*x4 +
0.5*ALEA()*x4
Y = 2.5*xi + ALEA()*xi + 0.25*x3 + 0.5*ALEA()*x3 + 0.75*x4 +
0.5*ALEA()*x4 + 1.125*x5 + 0.25*ALEA()*x5
Les relations semblent certes légèrement plus
complexes, mais en fait, la part d'aléa a été
divisée par deux dans chaque relation liant une variable à une
autre variable ou à une constante, et cette diminution a
été compensée par une hausse des relations directe entre
les variables entre-elles ou des relations entre les variables et les termes
constants. L'espérance des séries demeure ainsi inchangée
par rapport au premier test effectué.
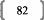
Voici le tableau synthétisant les relations entre les
variables :
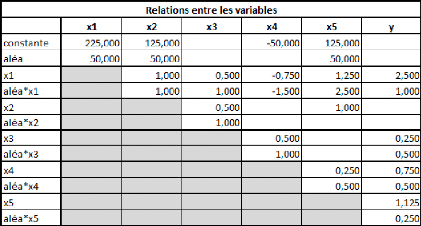
Et voici le tableau résumant les nouvelles
caractéristiques des séries :
Il est bon de noter qu'en divisant par deux la composante
aléatoire qui fondait toute relation directe entre les variables, et en
divisant par deux l'aléa des termes constants, on a fait bien plus que
diviser par deux l'influence de l'aléa dans l'ensemble des
séries. Mais cela n'empêche pas l'ensemble des séries de
conserver une forte composante aléatoire.
Si l'on observe le tableau, on s'aperçoit que les
espérances des séries restent inchangées. Seules les
proportions des différents degrés d'aléa sont
modifiées. Elles sont à présent plus raisonnables. Les
termes constants prennent une importance beaucoup plus conséquente. Les
aléas de degrés élevés prennent quant à eux
une importance nettement moindre.
On peut donc s'attendre à des séries plus
prévisibles, des relations entre les variables plus stables, et donc des
données moins aléatoires au sein des individus actifs et de la
population mère.
On a donc plus de chances d'avoir un échantillon de
qualité décente, et plus de chances d'avoir une population
mère représentant fidèlement les caractéristiques
des séries.
Passons donc à présent aux simulations, qui, comme
dans l'exemple précédent, seront au nombre de 4.
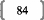
II.1. Simulation n°1
Voyons tout d'abord les caractéristiques des individus
actifs :

On observe que les écarts types des séries sont
nettement plus faibles que ceux que l'on a pu constater dans les simulations du
premier test. Les moyennes des séries sont raisonnablement proches de
leur espérance.
Caractéristiques de la population mère :
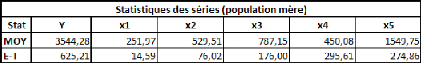
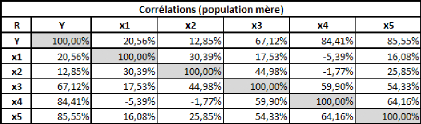
Naturellement, les moyennes enregistrées sur la
population mère sont encore plus proches des espérances
théoriques des séries. On observe néanmoins que la
série x4 est toujours fortement instable et que sa moyenne reste assez
éloignée de l'espérance.
Pour ce qui en est des corrélations, on peut dire que
l'échantillon représente assez moyennement la population
mère.
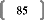
Attardons nous à présent sur les critères de
décision quant au choix du modèle, et observons pour cela les
caractéristiques des modèles et des composantes :
On s'aperçoit que les coefficients sont assez instables
d'un modèle à l'autre, et que même les variables
théoriquement les plus stables ne sont pas épargnées (bien
au contraire). Cela tient à la complexité du jeu des variables
entre-elles.
Notons également que les individus actifs sont nettement
mieux prédits (globalement) que dans les simulations du test
précédent.
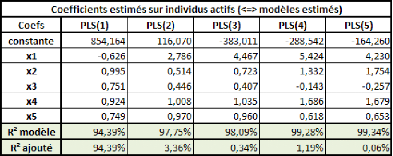
On remarque que les 3 dernières composantes apportent
très peu en termes de prédiction des individus actifs. Ce
critère nous incite à ne retenir que 2 composantes.
Le critère de la variance des axes nous incite
clairement à retenir 3 composantes. C'est ce que nous ferons, afin
d'éviter de perdre une partie importante de la représentation des
axes.
Notons que les deux derniers axes sont jugés
complètement inutiles par les deux critères. Nous retenons
donc 3 composantes.
Voyons à présent les résultats des
estimations des différents modèles sur les 40 autres individus
:
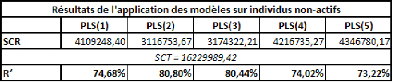
On remarque que les modèles à 2 et 3 composantes
sont considérablement meilleurs que les autres.
Les modèles recommandés par les deux
critères sont donc ici les meilleurs. Le modèle que nous avons
retenu (celui à 3 composantes) n'est pas le meilleur mais est
très proche de celui qui l'est.
Regardons à présent le meilleur résultat
possible :
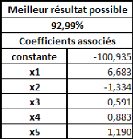
On s'aperçoit que les modèles en sont assez
loin, ce qui est paradoxal. En effet, dans les simulations du
précédent test, les meilleurs modèles s'approchaient en
moyenne à 5% du meilleur résultat possible. Cette fois-ci,
l'écart est de 12%, alors que nous avons réduit l'impact du
facteur aléatoire.
Cela relève probablement d'une mauvaise qualité
de l'échantillon, pas suffisamment représentatif de la population
mère. On peut raisonnablement qu'il s'agisse d'une exception et que les
prochains individus actifs seront plus représentatifs des prochaines
populations mères (dans les simulations suivantes).
Quoi qu'il en soit, cette simulation est plutôt positive
car les critères ont retenu les bons modèles.
| 

