111.4 Simulation n°4
Les caractéristiques des individus actifs pour cette
dernière simulation sont les suivantes :

Et voici les données équivalentes pour ce qui en
est de la population mère :
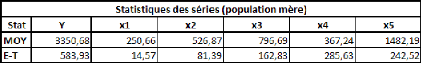

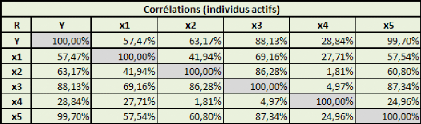
Comme pour les précédentes simulations de ce test,
les caractéristiques de la population mère sont assez mal
représentées par l'échantillon.
Passons à présent à l'étude des
différents modèles PLS possibles :
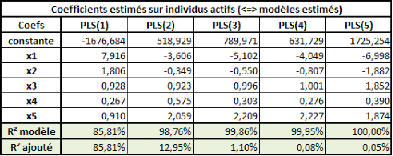
Ce critère nous incite à retenir 1 ou 2 axes.
Voyons ce que l'on peut dire des variances des axes :
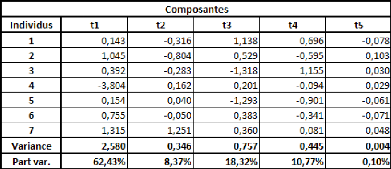
Ce critère nous incite à retenir, selon
différentes interprétations possibles, 1, 2, 3 ou 4 axes.
Nous sommes en présence d'un choix délicat.
Retenir 1 seul axe est probablement insuffisant. Retenir un deuxième axe
nous apporte moyennement peu en termes de variance, mais l'apport est
significatif en termes de R2 ajouté. Globalement, il faut
donc retenir le deuxième axe.
Mais dès lors que l'on retient deux axes, on est
forcément tenté de retenir le troisième qui comporte une
variance non négligeable. Sachant que le 4ème axe
détient lui aussi une certaine variance, se priver à la fois du
3ème et du 4ème axe peut paraitre
dangereux.
Nous choisirons donc, pour cette fois, de retenir 3
axes. Nous n'en retenons pas moins
dans l'espoir d'éviter le
danger qui consiste à avoir un modèle trop peu
représentatif de
l'ensemble X. Nous n'en retenons pas plus dans l'espoir
d'éviter le surparamétrage. C'est le seul choix qui ne nous
expose que modérément à chaque risque pris
individuellement.
Voyons dès lors quels sont les résultats de la mise
à l'épreuve des modèles sur les autres individus de la
population mère :
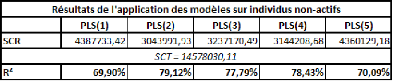
Les résultats semblent assez indifférents quant au
choix de retenir 2, 3 ou 4 composantes.
Parmi les trois modèles concernés, nous avons
choisi le moins bon, mais nous avons probablement évité certains
risques (qui ne se sont pas vraiment vérifiés ici).
De plus, l'écart par rapport aux deux autres
modèles est relativement infime. Voyons ce qu'il en est du meilleur
résultat possible :
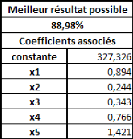
Apparemment, la population mère était, cette fois,
légèrement moins bien modélisable qu'elle ne
l'était lors des précédentes simulations.
Cela explique peut-être, en partie, les faibles
résultats obtenus par les modèles établis sur base de
l'échantillon.
Quoi qu'il en soit, les critères nous ont permis à
nouveau de retenir un modèle se situant dans la bonne « tranche
» de résultats.
Il est à présent temps de conclure sur le
troisième test.
| 

