111.5 Conclusions sur le test n°3
Le but de ce troisième test était de voir si la
régression PLS était bel et bien une méthode
intéressante sur un échantillon faible, et, plus
particulièrement, de voir si une réduction de la taille de
l'échantillon permet à l'approche PLS de « creuser
l'écart » par rapport aux autres modèles.
Voyons donc le tableau résumant les résultats
obtenus :
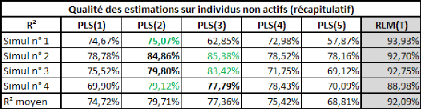
On s'aperçoit que dans 3 cas sur 4, notre choix s'est
porté sur le modèle à 2
composantes. Dans le dernier
cas, notre choix s'est porté sur le modèle à 3
composantes.
Même si nous n'avons choisi le meilleur qu'à une
seule reprise, notre choix s'est toujours porté sur les deux
modèles (PLS(2) et PLS(3)) qui cumulent à eux deux tous les
meilleurs résultats sur les 4 simulations. Parmi ces deux
modèles, le plus important était de ne pas choisir le
modèle 3 lors de la première simulation.
On observe aussi qu'en moyenne, le modèle PLS(2) est le
meilleur, suivi de près par le modèle PLS(3). Le modèle
PLS(5) est quant à lui nettement moins bon puisqu'il se situe à
plus de 10% (en moyenne) des meilleurs modèles.
La régression linéaire au sens des MCO est donc
clairement désavantagée par la faiblesse de l'échantillon,
puisque dans le test précédent, l'écart avec les meilleurs
modèles n'était en moyenne que de 4%.
Le test semble donc, dans une certaine mesure, doublement
concluant :
- Nous constatons, comme nous l'avons expliqué d'un point
de vue théorique, que la régression PLS est plus utile sur un
échantillon faible.
- Les modèles choisis au regard des critères sont
constamment parmi les meilleurs.
Notons qu'en moyenne, les modèles retenus sur base des
critères sont 10 à 11% meilleurs que le modèle de
régression linéaire des MCO.
Il est également positif de constater que les
résultats du modèle retenu sont assez stables. Ils oscillent
entre 75.07% et 84.86% (9.79% d'amplitude), alors que le modèle PLS(5)
oscille entre 57.87% et 78.16% (20.29% d'amplitude).
Néanmoins, cette conclusion serait clairement ternie si
par malchance nous avions retenu le modèle à 3 composantes pour
la première simulation. Mais quoi qu'il en soit, même dans ce cas
de figure, les résultats auraient été meilleurs que ceux
obtenus par la régression PLS(5) pour chaque simulation.
Voyons à présent les différents
écarts-types des coefficients enregistrés sur les 4 simulations
pour chaque modèle :
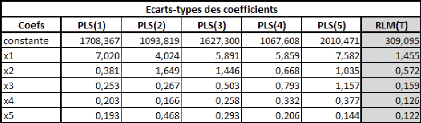
La première chose que l'on remarque, c'est qu'il semble
extrêmement pénalisant de passer d'un échantillon de 10
individus à un échantillon de 7 individus, toutes choses
égales par ailleurs. Tous les modèles présentent, dans
l'ensemble, des coefficients très peu stables, en comparaison avec ce
que l'on a pu voir précédemment.
On s'aperçoit que le meilleur modèle possible
sur les 43 individus non actifs (dont les écarts-types se trouvent dans
la colonne de droite du tableau ci-dessus) est nettement plus stable que ne le
sont les différents modèles estimés sur base des 7
individus actifs, ce qui est parfaitement normal.
On s'aperçoit également que le modèle
PLS(1), sur l'ensemble des coefficients, est probablement le plus stable (les
écarts-types sont les plus faibles excepté s'agissant des
coefficients affectés à la constante et aux variables x1 et x4,
bien que restant très faible pour la variable x4). Le modèle
PLS(2) est également l'un des plus stables.
On s'aperçoit également que le modèle
PLS(5) est hautement instable, exception faite de certains coefficients. Cela
tend à souligner, dans une certaine mesure, la faible robustesse de
l'approche des MCO sur un échantillon trop de taille faible. Ce qui
n'est, bien entendu, pas surprenant, étant donné les nombreuses
explications fournies à ce sujet tout au cours du mémoire,
notamment s'agissant de « l'opportunisme » de la méthode des
MCO.
On constate néanmoins qu'aucun modèle n'a le
« monopole » de la stabilité de l'ensemble des coefficients.
C'était déjà le cas dans nos précédents
tests. Le nombre de simulations est trop faible que pour que ce ne soit le
cas.
Quoi qu'il en soit, globalement, les coefficients sont plus
instables que dans le test n°2, ce qui est normal, puisqu'on travaille sur
des séries qui ont les mêmes caractéristiques, avec un
échantillon plus faible, donc moins représentatif des
caractéristiques intrinsèques des variables, et dont la
modélisation est donc fortement soumise au facteur aléatoire.
Voyons à présent ce qu'il en est des
différences constatées entre la moyenne des séries (au
niveau des individus actifs comme au niveau de la population mère) et
les espérances des variables :
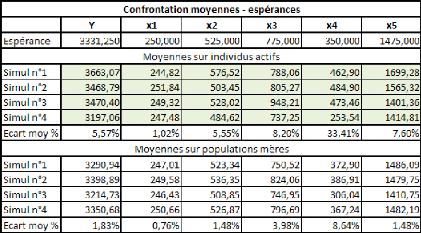
Par rapport au précédent test, il est logique de
constater que les écarts à l'espérance s'équivalent
dans une certaine mesure, étant donné que la population
mère est de même taille dans les deux tests, et étant
donné que les séries gardent les mêmes
propriétés.
On constate une relative hausse de l'instabilité des
caractéristiques des individus actifs. Il est étonnant de
constater que cette hausse reste modérée, après avoir
amputé l'échantillon de 30% des ses individus (10 dans le test
n°2, 7 dans le test n°3). On aurait pu s'attendre à ce que les
moyennes soient nettement plus instables. Ce n'est pas complètement le
cas. Nous aurions peut-être dû travailler avec seulement 6
individus afin de diminuer encore davantage la qualité de
l'échantillon (5 auraient été insuffisants car le
modèle linéaire établi sur le critère des MCO
aurait systématiquement trouvé la
présence d'une relation linéaire exacte,
excessivement instable d'un échantillon à l'autre).
De manière à conclure sur ce test, comparons
à présent les résultats moyens obtenus par les
différents modèles lors des tests n°2 et n°3.

On constate que l'effet de la diminution de l'échantillon
est réel, car les résultats sont en chute libre.
Mais il est fort intéressant de constater que les
modèles à faible nombre d'étapes sont ceux qui souffrent
le moins de ce changement. Si on s'en tient aux extrêmes, on
s'aperçoit que, sur 10 individus, le modèle PLS(5)
(équivalent au critère des MCO) est meilleur d'à peu
près 5% que le modèle PLS(1). Mais lors du passage à 7
individus, les résultats du modèle PLS(5) plongent de plus de
15%, alors que le modèle PLS(1) pers moins de 5%. Le modèle
PLS(1) surpasse alors le modèle PLS(5) de presque 6%.
S'agissant des autres modèles à 2, 3 et 4
étapes, les pertes semblent assez semblables. Le modèle PLS(2)
est le moins affecté des 3. Il était déjà le
meilleur (en moyenne) lors du 2ème test, et l'écart se
creuse davantage ici, excepté par rapport au modèle PLS(1) qui
est le seul à tendre à le rattraper.
Cela nous confirme donc que l'approche PLS,
représentée par les premières étapes de la
construction d'un modèle PLS, est particulièrement utile
lorsqu'il y a peu d'individus actifs, car ses résultats sont moins
sensibles au nombre d'individus actifs et au facteur aléa. Il semble
donc s'agir bel et bien d'une approche plus robuste que ne l'est l'approche des
MCO.
On pourrait se demander ce qu'il en serait si l'on augmentait
considérablement le nombre d'individus actifs. On peut penser que les
dernières étapes s'amélioreraient considérablement,
alors que les premières étapes auraient plutôt tendance
à stagner.
Quoi qu'il en soit, cela ne veut pas dire que l'approche des
MCO au sens stricte soit à privilégier. Tout dépendrait
bien entendu de l'efficacité des critères que nous avons
utilisés au cours de nos 12 simulations.
Il est à présent temps de conclure sur cette
troisième et dernière partie.
| 

