Techniques d'extraction de connaissances appliquées aux données du Web( Télécharger le fichier original )par Malika CHARRAD Ecole Nationale des Sciences de l'Informatique, Université de la Manouba, Tunis - Mastère en informatique, Option : Génies Documentiel et Logiciel 2005 |

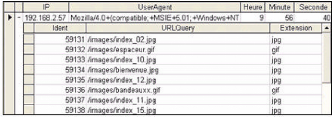
5.1.4 Retraitement des fichiers LogSeconde étape de nettoyage des images (N3b) La seconde méthode que nous proposons pour éliminer les images téléchargées sans intervention de l'internaute consiste à supposer qu'un utilisateur ne peut cliquer à la fois (au même instant) sur plusieurs images pour les visualiser; Tenant compte de cette hypothèse, nous déterminons pour chaque utilisateur l'ensemble des requêtes effectuées au même instant. Les requêtes correspondantes à des fichiers images sont éliminées. L'exemple suivant montre que plusieurs images peuvent apparaître en même temps (9 :56 :40) à l'écran d'un utilisateur unique. Une simple vérification sur le site a montré que plusieurs images sont contenues dans la page www.cck.rnu.tn/default.htm (fig 5.8) et dont les URLs sont présentées dans la figure 5.9.
FIG. 5.8 : Exemple de pages contenant plusieurs images
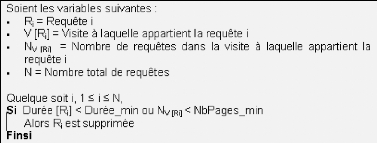
FIG. 5.9 : URLs des images contenues dans la page Seconde étape d'identification des robots (N2e) La seconde phase d'identification des robots repose sur la vitesse de navigation »Browsing Speed» obtenues en divisant la durée de la visite par le nombre de requêtes effectuées par visite. BS = durée Vis ite/NbReqPar Vis ite En adoptant les critères proposés par [Tan, 03], nous considérons que les visites vérifiant les conditions - BS[Vk] > 2 pages/seconde Et - N[Vk]>15 pages sont effectuées par des robots Web. Elles sont, par conséquent, supprimées. Filtrage des requêtes et des visites Cette phase vise à ne garder que les requêtes et visites supposées porteuses d'informations. En d'autre termes, elle consiste à supprimer »le bruit» dans les données. Pour ce faire, nous considérons les deux variables suivantes : - Durée _min : la durée minimale de consultation d'une page par l'utilisateur, - Nbpages_min: le nombre minimal de pages que peut contenir une visite.
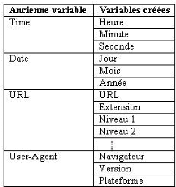
FIG. 5.10 : Algorithme de filtrage des visites et des requêtes Dans notre cas, en prenant Durée _min = 15 secondes et NbPages_min = 2 pages nous avons considéré que les requêtes dont la durée est nulle (ou presque nulle) et les visites constituées d'une seule page sont inintéressantes pour notre analyse. Généralement, les requêtes dont la durée est nulle correspondent à des processus automatiques (indexation par un robot ou enregistrement par un aspirateur) ou à des requêtes interrompues avant chargement complet de la page. Les codes d'état le montrent bien. En effet, environ 20.4% de ces requêtes ont été servies en code 3xx i.e. redirection sur un autre URL ou en 206 i.e. document chargé partiellement. L'examen des User-Agents des requêtes servies correctement (code 200) permet de penser que ce sont des consultations des robots, en particulier des aspirateurs des sites Web. En effet, environ 91% de ces requêtes sont effectuées par le User-Agent de windows-IE (MSIE) qui permet le téléchargement des pages Web pour consultation o- ine avec une durée nulle entre l'enregistrement des pages. Les visites composées d'une seule page sont considérées comme du »bruit» ne ramenant aucune information utile. Cependant, l'examen des URLs de provenance (Referrer) des requêtes composant ces visites montre que dans 30% des cas, l'internaute parvient au site à travers un moteur de recherche (Google, Yahoo, Altavista) ce qui explique pourquoi l'utilisateur ne visite qu'une seule page dans le site (i.e. le moteur lui envoie la page qui répond le mieux à sa requête). Création de nouvelles variables A partir des variables préexistantes, nous allons créer de nouvelles variables permettant de faciliter l'analyse envisagée. D'autres variables peuvent être créées suivant la nature de l'analyse envisagée.
TAB. 5.1 : Création de nouvelles variables
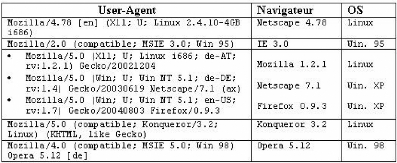
TAB. 5.2 : Transformation de la variable URL La création des variables »Navigateur», »Version» et »Plateforme» à partir de la variable »User-Agent» n'est pas aisée pour plusieurs raisons: - La difficulté de décryptage du User-Agent: D'une part, les navigateurs utilisent des formats différents pour s'identifier (absence de format standard). En effet, Netscape présente généralement un User- Agent de la forme: Produit [langue] (plateforme; niveau de sécurité3; description du système d'exploitation) Par exemple, Mozilla / 4.04 (X11; I; SunOS 5.4 sun4m) Par contre, Internet Explorer présente un format différent : Mozilla/4. 0 (compatible; MSIE 5. 23; Mac_ PowerPC). D'autre part, la version du navigateur n'est pas toujours explicite. Il faut dans certains cas la dégager à partir du »Build Number». Dans l'exemple Mozilla/5.0 (Macintosh; U; PPC Mac OS X; de-de) Apple WebKit/85. 7 (KHTML, like Gecko) Safari/85.7, le »Build Number» vaut 85.7 et le navigateur est Safari dont la version est 1.0 - La guerre entre les navigateurs: Cette histoire remonte à la grande époque de Netscape. En effet, plusieurs sites ne fournissent leurs versions riches qu'à Netscape. Comme ce dernier utilise depuis toujours le nom de code Mozilla dans la chaîne User-Agent pour s'identifier, Internet Explorer reprend cette même identification dans ses premières versions, en rajoutant la mention compatible. Par exemple, Mozilla/4. 0 (compatible; MSIE 5. 22; Mac_ PowerPC) ne correspond pas à Netscape 4.0 comme on peut le croire. Il s'agit plutôt d'Internet Explorer 5.22. Certains navigateurs peuvent être tentés de faire de même pour se faire passer pour IE, comme IE se faisait passer pour Netscape. C'est l'exemple du navigateur Opéra qui peut avoir un User-Agent de cette forme: Mozilla/4. 0 (compatible; MSIE 6.0; Windows NT 5.1) Opera 7.54 [fr] - La difficulté d'identification du système d'exploitation : En effet, souvent le système d'exploitation Windows s'identifie en utilisant des noms de versions différentes de celles réelles. Le tableau suivant présente les versions mentionnées dans le User-Agent et les versions réelles correspondantes. 3Prend les valeurs : » U » pour sécurité de haut niveau et » I» pour sécurité faible
TAB. 5.3: Identification du système d'exploitation - Le changement du User-Agent par l'internaute: Les utilisateurs de nombreux navigateurs (Opéra, Mozilla, et autres navigateurs alternatifs) peuvent changer eux-mêmes la chaîne User-Agent. Cette manipulation est souvent réalisée pour contourner des filtrages de sites incompatibles avec ces nouveaux navigateurs, pour effectuer des tests (par les développeurs) ou pour faire face au blocage des User-Agents des aspirateurs par des sites professionnels. »User-Agent Switcher»4 permet de faire passer un navigateur pour un autre, voire de s'inventer un nouveau User-Agent. Il est également possible de modifier le format de la ligne »User-Agent» envoyée au cours de la requête http pour cacher le type du navigateur utilisé. L'examen des User-Agents des différents navigateurs nous a permis de dégager les règles suivantes: - Netscape utilise toujours le nom de code Mozilla dans la chaîne User-Agent pour s'identifier. A partir de la version Mozilla 5.0, on ne parle plus de Netscape, on parle plutôt de navigateurs Gecko. - Internet Explorer, dans ses premières versions, s'identifie également par le nom de code Mozilla, en rajoutant la mention »compatible» suivie par la chaîne »MSIE». Aucun autre nom de navigateur n'est présent dans le User- Agent. - Mozilla, Netscape 6/7 et les autres navigateurs Gecko sont définis par la présence de la chaîne »Mozilla 5.0» et le mot-clé »Gecko». La version de Mozilla est précédée par l'abréviation »rv». Celle des autres navigateurs est présentée à la fin, précédée par le nom du navigateur. - Les navigateurs »KHTML-based» tels que Konqueror de Linux et Safari d'Apple se présentent par leurs noms, leurs versions et la mention »compatible» ou (KHTML, like Gecko) pour montrer leur compatibilité avec les navigateurs Gecko. - Le navigateur Opera, qui s'identifie par défaut comme Internet Explorer, est défini par la présence de la chaîne »Opera» suivie de la version. Le tableau 5.4 présente un exemple sur le décryptage du User-Agent. 4http : // www.chrispederick.com/work/firefox/useragentswitcher/
TAB. 5.4 : Décryptage du User-Agent La succession chronologique de ces étapes est illustrée par la figure 5.11.
FIG. 5.11 : Succession chronologique des étapes de prétraitement |
|