2.2 Web Usage Mining
[Tan, 03] définit le WUM comme étant
l'application du processus d'Extraction des Connaissances à partir de
bases de Données (ECD) aux données issues des fichiers Logs HTTP
afin d'extraire des modèles comportementaux d'accès au Web en vue
de répondre aux besoins des visiteurs de manière
spécifique et adaptée (personnaliser les services) et faciliter
la navigation.
2.2.1 Motifs du Web Usage Mining
Selon [Mic, 02], il y a cinq motifs du WUM :
1. Évaluation et caractérisation
générale de l'activité sur un site Web : l'objectif est
l'observation et non pas la modélisation. Les techniques d'analyse
utilisées sont souvent simples. Elles relèvent, en effet, du
dénombrement et des statistiques simples (moyennes, histogramme,
indices, tris croisés).
2. Amélioration des modes d'accès aux
informations : le WUM permet de comprendre comment les utilisateurs se servent
d'un site, d'identifier les failles dans la sécurité et les
accès non autorisés.
3. Modification de la structure : le WUM peut
révéler le besoin de restructurer des pages et des liens afin
d'améliorer la structure du site Web. En effet,
les pages considérées comme similaires par des
techniques de classification peuvent être reliées de
manière hypertextuelle.
4. Personnalisation de la consultation : cet enjeu important
pour de nombreuses applications Internet ou sites de e-commerce consiste
à proposer des recommandations dynamiques à un utilisateur en se
basant sur son profil et une base de connaissances d'usages connus.
5. Mise en oeuvre de l'intelligence économique: cet
objectif concerne en particulier les sites marchands. Il s'agit de comprendre
quand, comment et pourquoi l'utilisateur est attiré par ce site, les
produits qu'il faut lui proposer à la vente...etc.
2.2.2 Données de l'usage
Les principales données exploitées dans le WUM
proviennent des fichiers Logs. Cependant, il existe d'autres sources
d'informations qui pourraient être exploitées à savoir les
connaissances sur la structure des sites Web et les connaissances sur les
utilisateurs des sites Web.
Fichiers Logs HTTP
Présentation des fichiers Log HTTP: Un Log file (en
français, journal de bord des connexions ou fichier journal) est un
fichier créé par un logiciel spécifique installé
sur le serveur Web permettant de garder une trace des requêtes
reçues et des opérations effectuées par le serveur. Il
existe plusieurs formats des fichiers Logs Web, mais le format le plus courant
est le CLF (Common Log file Format). Selon ce format six informations sont
enregistrées:
1. le nom du domaine ou l'adresse de Protocole Internet (IP) de
la machine appelante,
2. le nom et le login HTTP de l'utilisateur (en cas
d'accès par mot de passe),
3. la date et l'heure de la requête,
4. la méthode utilisée dans la requête (GET,
POST, etc.) et le nom de la ressource Web demandée (l'URL de la page
demandée),
5. le statut de la requête i.e. le résultat de la
requête (succès, échec, erreur, etc.),
6. la taille de la page demandée en octets.
Le format ECLF (Extended Common Log file Format),
supporté par certains serveurs Web, représente une version plus
complète du CLF. En effet, il indique en plus l'adresse de la page de
référence (où se trouvait l'internaute lorsqu'il a
lancé la requête (referrer)) et l'identification de l'agent client
(le nom du navigateur Web et le système d'exploitation).
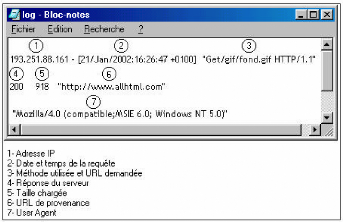
FIG. 2.1 : Schéma illustratif des champs d'une
requête
Problèmes spécifiques aux données des
fichiers Logs : Bien que les données fournies par les fichiers Logs
soient utiles, il importe de prendre en compte les limites inhérentes
à ces données lors de leur analyse et de leur
interprétation. Parmi les difficultés qui peuvent survenir:
- Les requêtes inutiles2 : Chaque fois qu'il
reçoit une requête, le serveur enregistre une ligne dans le
fichier Log. Ainsi, pour charger une page, il y'aura autant de lignes dans le
fichier que d'objets contenus sur cette page (les éléments
graphiques). Un prétraitement est donc indispensable pour supprimer les
requêtes inutiles.
- Les firewalls : Ces protections d'accès à un
réseau masquent l'adresse IP des utilisateurs. Toute requête de
connexion provenant d'un serveur doté d'une telle protection aura la
même adresse et ce, quel que soit l'utilisateur. Il est donc impossible,
dans ce cas, d'identifier et de distinguer les visiteurs provenant de ce
réseau.
- Le Web caching: Afin de faciliter le trafic sur le Web, une
copie de certaines pages est sauvegardée au niveau du navigateur local
de l'utilisateur ou au niveau du serveur proxy afin de ne pas les
télécharger chaque fois qu'un utilisateur les demande. Dans ce
cas, une page peut être consultée plusieurs fois sans qu'il y' ait
autant d'accès au serveur. Il en résulte que les requêtes
correspondantes ne sont pas enregistrées dans le fichier Log.
- L'utilisation des robots : Les annuaires du Web, connus sous
le nom de moteurs de recherche, utilisent des robots qui parcourent tous les
sites Web
afin de mettre à jour leur index de recherche. Ce
faisant, ils déclenchent des requêtes qui sont enregistrées
dans tous les fichiers Logs des différents sites, faussant ainsi leurs
statistiques.
- L'identification des utilisateurs : L'identification des
utilisateurs à partir du fichier Log n'est pas une tâche simple.
En effet, en employant le fichier Log, l'unique identifiant disponible est
l'adresse IP et »l'agent» de l'utilisateur. Cet identifiant
présente plusieurs limites [Sri, 00] :
- Adresse IP unique / Plusieurs sessions serveurs: La
même adresse IP peut être attribuée à plusieurs
utilisateurs accédant aux services du Web à travers un unique
serveur Proxy.
- Plusieurs adresses IP / Utilisateur unique: Un utilisateur
peut accéder au Web à partir de plusieurs machines.
- Plusieurs agents / Utilisateur unique : Un internaute qui
utilise plus d'un navigateur, même si la machine est unique, est
aperçu comme plusieurs utilisateurs.
- L'identification des sessions : Toutes les requêtes
provenant d'un utilisateur identifié constituent sa session. Le
début de la session est défini par le fait que l'URL de
provenance de l'utilisateur est extérieure au site [Lec, 03]. Par
contre, aucun signal n'indique la déconnexion du site et par suite la
fin de la session.
- Le manque d'information : Le fichier Log n'apporte rien sur
le comportement de l'utilisateur entre deux requêtes : Que fait ce
dernier? Est-il vraiment en train de lire la page affichée? De plus, le
nombre de visites d'une page ne reflète pas nécessairement
l'intérêt de celle-ci. En effet, un nombre élevé de
visites peut simplement être attribué à l'organisation d'un
site et au passage forcé d'un visiteur sur certaines.
Autres sources des données
Connaissances sur le site Web : Les pages d'un site sont
matérialisées par une adresse Internet spécifique,
appelée adresse d'allocation de la ressource (Uniform Resource Locator).
La structure d'un site Internet simple peut être
représentée par un arbre dont la racine correspond à la
page d'accueil du site.
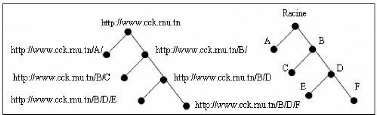
FIG. 2.2 : Exemple d'arbre d'un site
Chaque point (ou noeud) présente l'adresse d'une page
particulière, et les segments reliant ces points indiquent la
présence d'un lien hypertexte amenant aux sous-branches
immédiates de l'arbre. D'après le schéma ci-dessus, il est
possible de retracer le chemin de navigation de l'internaute sur le site.
Cependant, il n'est pas toujours aisé de représenter
l'architecture d'un site, en particulier les sites complexes.
Connaissances sur les utilisateurs du site : Les connaissances
sur les utilisateurs d'un site sont obtenues directement auprès des
utilisateurs eux-mêmes dans l'approche panéliste (âge, sexe,
ancienneté sur le Web). Dans le cas des sites à base
d'inscription, ces connaissances sont recueillies directement à partir
du login et du profil de l'utilisateur donnés par l'internaute au moment
de l'inscription. Ces données dites explicites, fournies directement par
les internautes sont très souvent erronées. Il est
également possible d'acquérir des connaissances sur les
utilisateurs du site en reconstituant leurs profils en fonction de leurs
activités passées sur le Web.
| 

