I.3.2 Présentation de l'architecture
client/serveur
De nombreuses applications fonctionnent selon un
environnement client/serveur, cela signifie que des machines clientes (des
machines faisant partie du réseau) contactent un serveur, une machine
généralement très puissante en terme de capacités
d'entrée-sortie, qui leur fournit des services. Ces services sont des
programmes fournissant des données telles que l'heure, des fichiers, une
connexion, etc.
Les services sont exploités par des programmes,
appelés programmes clients, s'exécutant sur les machines
clientes. On parle ainsi de client FTP, client de messagerie, ..., lorsque l'on
désigne un programme, tournant sur une machine cliente, capable de
traiter des informations qu'il récupère auprès du serveur
(dans le cas du client FTP il s'agit de fichiers, tandis que pour le client
messagerie il s'agit de courrier électronique).
[CCM05]
I.3.2.1 Fonctionnement d'un système
client/serveur
Un système client/serveur fonctionne selon le
schéma suivant:
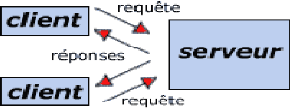
Figure 3 : Schéma de fonctionnement d'un système
client/serveur
· Le client émet une requête vers le serveur
grâce à son adresse et le port, qui désigne un service
particulier du serveur
· Le serveur reçoit la demande et répond
à l'aide de l'adresse de la machine client et son port.

I.3.3 Types d'architectures réseaux I.3.3.1
Architecture à 1-tiers
Dans une approche d'application de type 1-tiers, les trois
couches sont fortement et intimement liées, et s'exécutent sur la
même machine. Dans ce cas, on ne peut pas parler d'architecture
client-serveur mais d'informatique centralisée.
Dans un contexte simple utilisateur, la question ne se pose
pas, mais dans un contexte multiutilisateurs, on peut voir apparaître
deux types d'architectures mettant en oeuvre des applications 1-tiers : des
applications sur site central ; des applications réparties sur des
machines indépendantes communiquant par partage de fichiers.
I.3.3.2 Architecture à 2-tiers
L'architecture à deux niveaux (aussi appelée
architecture 2-tiers, tiers signifiant tierce partie) caractérise les
systèmes clients/serveurs dans lesquels le client demande une ressource
et le serveur la lui fournit directement. Cela signifie que le serveur ne fait
pas appel à une autre application afin de fournir le service.
[CCM05]

Interroger BD
BD
Requêtes
Niveau 2
Réponses
Niveau 1
Résultats
Client Serveur Base de données
Figure 4: Architecture à 2-Tiers
I.3.3.3 Architecture à 3-Tiers
Dans l'architecture à trois niveaux (appelée
architecture 3-tiers), il existe un niveau intermédiaire,
c'est-à-dire que l'on a généralement une architecture
partagée entre :
> Un client, c'est-à-dire l'ordinateur demandeur de
ressources, équipée d'une
interface utilisateur (généralement un navigateur
web) chargée de la présentation; > Le serveur d'application
(appelé également middleware), chargé de fournir la
ressource mais faisant appel à un autre serveur
> Le serveur de données, fournissant au serveur
d'application les données dont il a besoin.

Requêtes Requêtes

Niveau1
Client
Niveau2
Serveur d'application
Niveau3
Serveur de BD
Résultats
Résultats
BD
Figure 5: Architecture 3-Tiers
. Les niveaux de l'architecture 3-tiers
1) Client
Dans un réseau informatique un client est l'ordinateur
et le logiciel qui envoient des demandes à un serveur. L'ordinateur
client est généralement un ordinateur personnel ordinaire,
équipés de logiciels relatifs aux différents types de
demandes qui vont être envoyées, comme par exemple un navigateur
web, un logiciel client pour le World Wide Web.
2) Serveur
Dans un réseau informatique, un serveur est à
la fois un ensemble de logiciels et l'ordinateur les hébergeant dont le
rôle est de répondre de manière automatique à des
demandes envoyées par des clients ordinateur et logiciel via le
réseau.
Les serveurs sont d'usage courant dans les centres de
traitement de données, les entreprises, les institutions, et le
réseau Internet, où ils sont souvent un point central et sont
utilisés simultanément par de nombreux utilisateurs pour stocker,
partager et échanger des informations. Les différents usagers
opèrent à partir d'un client: ordinateur personnel, poste de
travail, ou terminal.
Le World Wide Web, la messagerie électronique et le
partage de fichiers sont quelques applications informatiques qui font usage de
serveurs.
3) Serveur de base de données
Lorsque le nombre d'enregistrements par table n'excède
pas le million, et que le nombre d'utilisateurs varie de une à quelques
personnes, un micro-ordinateur actuel de bonnes performances, un logiciel
système pour poste de travail, et un SGBD "bureautique" suffisent.

Si ces chiffres sont dépassés, ou si le temps de
traitement des données devient prohibitif, il faut viser plus haut. Le
micro-ordinateur doit être remplacé par un serveur de BDD, dont
les accès aux disques durs sont nettement plus rapides. Le logiciel
système client doit être remplacé par un logiciel
système serveur (donc multiutilisateurs), et le SGBD bureautique par un
SGBD prévu pour les grosses BDD multi-clients.
Ceci dit, la structure d'une grosse base n'est pas
différente de celle d'une petite, et il n'est pas nécessaire de
disposer d'un "mainframe" (une grosse machine) gérant des milliers de
milliards d'octets pour apprendre à se servir des BDD. Ce n'est pas
parce qu'il gère un plus grand volume de données qu'un SGBD
possède plus de fonctionnalités.
. Limites de l'architecture 3-tiers
L'architecture trois-tiers a corrigé les excès
du client lourd en centralisant une grande partie de la logique applicative sur
un serveur HTTP. Le poste client, qui ne prend à sa charge que la
présentation et les contrôles de saisie, s'est trouvé
soulagé et plus simple à gérer.
En revanche, le serveur HTTP constitue la pierre angulaire de
l'architecture et se trouve souvent fortement sollicité : il est
difficile de répartir la charge entre client et serveur. On se retrouve
confronté aux épineux problèmes de dimensionnement serveur
et de gestion de la montée en charge rappelant l'époque des
mainframes. De plus, les solutions mises en oeuvre sont relativement complexes
à maintenir et la gestion des sessions est compliquée, mais reste
possible.
Les contraintes semblent inversées par rapport à
celles rencontrées avec les architectures deux-tiers : le client est
soulagé, mais le serveur est fortement sollicité.
Le juste équilibre de la charge entre client et serveur
semble atteint avec la génération suivante : les architectures
n-tiers.
| 

