II.II.2.2 SÉLECTION DE SEUIL
Deux méthodes statistiques de modélisation des
queues sont possibles:
· La méthode BM
· La méthode POT
En finance de marché, nous allons privilégier
la méthode POT, plus adaptée, notamment parce qu'elle va en
adéquation avec un phénomène couramment observé: Le
<<clustering48 >>. De plus, comparée à la
méthode BM, qui ne considère pas toutes les valeurs susceptibles
d'être extrêmes49, cette méthode est à la
fois plus flexible et plus réaliste.
P&L Distribution |P&L|
15.00%
10.00%
5.00%
0.00%
-5.00%
-10.00%
12.000%
10.000%
8.000%
6.000%
4.000%
2.000%
0.000%
47 La Théorie des Marchés Efficients
(Efficient Market Theory) soutient que les marchés fonctionnent
de manière à retranscrire intégralement et
instantanément l'ensemble des informations disponibles. Jegadeesh et
Titman, en 1993, mettent en évidence l'effet <<momentum
>>. Ils observent que la tendance des titres par rapport au
marché semble se poursuivre dans une mouvance irrationnelle. Il en va de
même pour la variance journalière dans ce contexte.
48 Le phénomène de cluster, vu
précédemment en section théorique, se défini comme
une grappe de volatilités caractéristiques des
rentabilités liées aux actifs financiers.
49 La méthode BM extrait le maximum de
chaque période définie préalablement. Elle ne prend donc
pas en compte certaines données extrêmes liées aux cycles
financiers et peut en revanche prendre des valeurs faibles lors des blocks
précédents.
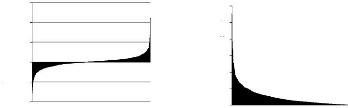
Cette modélisation de queue de distribution engage un
échantillon au-dessus du seuil u, lequel conduit à une
forme de loi GPD. Les méthodes utilisées reposent sur le
comportement graphique des valeurs considérées supérieures
à un seuil. Ces deux graphiques montrent d'une part la variation
décroissante du DJIA pendant la crise des subprimes. D'autre part, la
variation décroissante en valeur absolu e. Remarquons le
caractère asymptotique de la courbe. Le nombre de valeurs se
réduisant lorsque l'on approche la valeur nulle de l'abscisse. Il est
alors délicat de choisir un seuil u grand pour que l'estimation
de la distribution de Pareto généralisée soit valide.
Celui -ci ne peut également pas être trop élevé pour
garder une certaine cohérence avec le comportement réelle du
cours du DJIA. Le nombre de données supérieur à u
défini est en rapport direct avec l'espérance future
d'observer un tel évènement. Nous constatons au vu du tableau
présenté ci-dessous qu'il existe très peu de variation
supérieure à 5% (soit 4,86% des échanges). Environ la
même quantité est observée pour les valeurs
dépassant 4%. Les valeurs inférieures à 3% semblent
cohérentes en terme de volume d'observations, cependant, celles-ci
risquent de biaiser le modèle, se rapprochant trop de la tendance
centrale.
TAB 10: Nombre d'observation supérieure à
u
|
|
Variation> u
|
Nobs
|
2%
|
149
|
3%
|
58
|
4%
|
28
|
5%
|
15
|
6%
|
9
|
7%
|
5
|
8%
|
2
|
|
Nous présentons donc un seuil u = 0.03. Nous
obtenons 58 données. Le graphique ci-contre représente ce seuil,
qui semble correspondre aux valeurs extrêmes présentées par
la théorie.
| 

