1.7 Apprentissage
Quelque soit le modèle considere, il doit
obligatoirement debuter par une phase d'apprentissage. L'apprentissage
automatique (Machine Learning) est un procede qui permet au système de
generaliser les connaissances qui a pu apprendre, grâce à des
donnees dejà traitees manuellement, à des donnees inconnues.
C'est une technique d'intelligence artificielle qui est appliquee dans une
large gamme de domaines, en premier lieu en classification.
Dans les systèmes de parole, l'apprentissage constitue
une phase cruciale. Pour chaque unite phonetique (mot ou phonème), le
système calcule une estimation à partir d'un echantillon de
donnees de reference. Le choix de cet echantillon est très important: il
faut à la fois minimiser la taille et generaliser la presentation. Ces
deux objectifs sont plus ou mois contradictoires. Si l'on choisi un ensemble
d'echantillons très petit, on risque d'avoir une mauvaise representation
comme reference. Ce qui entrainerait de mauvaises consequences lors de la
reconnaissance. De même, avec un ensemble très
grand, le problème peut devenir complètement
irrésolvable. Il convient donc de trouver un compromis.
Dans les modèles markoviens, le système apprend,
à partir d'un ensemble de mots donné, à prévenir
l'apparition d'un mot à partir des mots déjà apparus. Dans
les modèles de classification, l'apprentissage consiste à adapter
le système à classifier des phonèmes dont l'image
acoustique est légèrement différente de celle du prototype
source correspondant. Quant aux modèles à base de DTW,
l'apprentissage se préoccupe plutôt de surpasser les
décalages temporels dus aux variations de vitesses de locution.
1.8 Traitements linguistiques de haut niveau
Les traitements linguistiques ne sont pas tous disponibles
dans tous les systèmes de reconnaissance. Par exemple, dans les
systèmes de commande à mots isolés, aucun traitement
linguistique n'est nécessaire, voire n'est utile. Dans les
systèmes de dictée, une analyse lexicale et syntaxique est
incontournable; par contre, aucun intérêt ne serait apporté
par une analyse sémantique. Mais dans les applications de dialogue oral
par téléphone, toutes les analyses doivent être mises en
coopération pour qu'elle soit plutôt efficace.
Dans la plupart des systèmes, ces différents
niveaux d'analyse linguistique sont séquentiels et donc
indépendant de point de vue temporel. Cependant, une combinaison entre
eux peut s'avérer bénéfique. Par exemple, l'introduction
d'une analyse sémantique dans la phase de reconnaissance peut
améliorer la précision et lever l'ambigüité. Cette
technique est en quelque sorte implicitement introduite dans les modèles
markoviens dans lesquels, la probabilité de correspondance d'un mot ne
dépend pas seulement de son image acoustique, mais aussi de suite de
mots qui le précèdent.
Les applications de dialogue oral téléphonique
se répondent de plus en plus et couvre une grande variété
de domaines. Dans ce type d'applications, un module de compréhension
(d'analyse sémantique) est indispensable pour la traduction des phrases,
issues du module de reconnaissance et dont la nature est très
spontanée, à des commandes effectives.
Dans certaines applications, la compréhension
s'effectue suivant deux phases d'analyses séquentielles. La
première phase établie un découpage des phrases en groupes
syntaxiques (groupe nominal, groupe verbal, ...), et de leurs associer les
étiquettes sémantiques correspondantes. La phase suivante
effectue un rattachement sémantico-
pragmatique qui a pour but de relier les constituants minimaux
résultants de la première phase, et de définir les
dépendances entre eux.
D'autres modèles tels que les arbres de décision
sémantiques, le boosting ou les SVM, combinent les opérations de
reconnaissance et de compréhension en une seule phase. Les arbres de
décision sémantiques sont généralement les plus
utilisées. C'est une technique qui repose sur les grammaires
régulières. Les règles de la grammaire sont
constituées automatiquement à partir d'un corpus
d'entraînement.
Un des défis des applications de compréhension
orale, qui doivent souvent confronter, est l'aspect spontané de la
parole. Le problème se présente principalement dans les
hésitations, les fragments inutiles, les répétitions et
les déformations syntaxiques et sémantiques. Ces applications
doivent donc filtrer les phrases reconnues pour extraire ce qui est utile de ce
qui ne l'est pas.
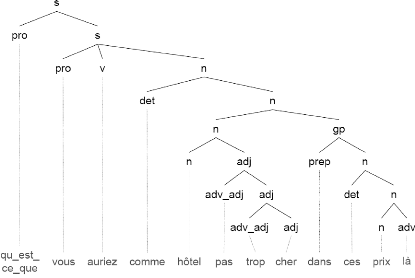
FIGURE 1.7 - Exemple de découpage syntaxique
| 

