Tables des Matières
Table des abréviations
AICC: Aviation Industry
CBT Committee
ADL: Advanced
Distributed Learning
IMS:
Intelligent Manufacturing System
IEEE:
Institute of Electrical and Electronics Engineers
ISO:
Organisation International de
Normalisation
AFNOR:
Association Française de
NORmalisation
LOM: Learning
Object Model
URL: Uniform Ressource
Locator
URI:
Uniform Ressource Identifier
HTML: Hyper Texte Markup Language
SCORM: Sharable
Content Object Reference
Model
DoD: Département de la
défense
OSTP: Office of Science and
Technology Policy
SCO: Sharable Content
Object
XML: eXtensible Markup Language
LO:
Learning
Object
API: Interface de Programmation
d'Application
LMS: Learning Management
Systems
CMS: Content Management
Systems
RLO: Reusable
Learning
Object
LCMS: Learning Content
Management Systems
IC: Ingénierie de
Connaissances
IO: Ingénierie
Ontologique
RDF: Resource Description
Framework
W3C: World Wide Web Consortium
FOAF: Friend of a
friend
RDFS: Resource Description
Framework Schéma
OWL: Web Ontology Langage
OWL DL: Web Ontology Langage
Description Logics
E-learning: Electronic learning
JDK: JAVA Development Kit
I. Introduction générale
L'apprentissage par machine a ouvert la voix aux enseignants et
aux apprenants en terme de facilité l'apprentissage et l'adapter selon
le niveau et le rythme des apprenants pour cela les ontologies sont
utilisées pour la recherche et l'indexation des différentes
ressources pédagogiques , qui peuvent être produites, acquises,
assemblées, modifiées et réutilisées, grâce
à un ensemble de spécifications communes, afin de construire des
unités d'apprentissage plus ou moins complexes comme un module, une
leçon, une évaluation, un cours (notion d'agrégation).
Ce projet a pour objectifs
de créer une base de ressources pédagogiques indexé
sémantiquement par une ontologie d'application appliquer
à l'enseignement de
l'algorithmique pour faciliter la scénarisation et autre
usage de cette base.
Dans le chapitre nous aborderons des normes et des standards.
Le chapitre sera consacré aux plates formes et leurs
fonctionnalités.
Le chapitre nous présenterons les ontologies et leurs
rôles et le langage de
spécification d'ontologie.
Le chapitre sera consacré à la conception de la
base de ressources, choix du
contenu du référentielle (les
métadonnées) de notre système.
Le chapitre sera consacré à
l'implémentation.
I. Introduction
Dans le monde de la formation, les normes et standards
produisent généralement un sentiment de rejet : la formation
est conçue comme une adaptation à des besoins spécifiques,
un ajustement aux demandes de l'apprenant. Il n'est donc pas question de se
plier à un quelconque format standardisé.
En contrepoint, le monde de la documentation a depuis
longtemps intégré la nécessité de normaliser les
langages documentaires, si bien que l'utilisation des normes et standards est
courante, voire perçue comme constitutive de l'identité
professionnelle.
II. Norme
II.1.a. Définition
Une norme est un ensemble de règles fonctionnelles ou
de prescriptions techniques relatives à des produits, à des
activités ou à leurs résultats, établies par
consensus de spécialistes et consignées dans un document produit
par un organisme de normalisation. Les normes permettent de fournir une
certaine garantie de fonctionnement, de sécurité, de performance,
de qualité, d'interchangeabilité, d'
interopérabilité.
Le principe de normalisation peut être
considéré comme un processus social qui a pour finalité le
partage d'un certain nombre de
connaissances
par une
communauté
qui peut s'y référer comme un bien commun.
II .1.b. Définition officielle
"Document établi par un consensus et approuvé
par un organisme reconnu, qui fournit, pour des usages communs et
repérés, des règles, des lignes directrices ou des
caractéristiques, pour des activités ou leurs résultats,
garantissant un niveau d'ordre optimal dans un contexte donné."
La norme propose des solutions à des questions
techniques et commerciales concernant les produits, les biens
d'équipement et les services. Elle établit un compromis entre
l'état de la technique et les contraintes économiques à un
moment donné.
La problématique de la normalisation de la
formation en
ligne est apparue sous l'effet conjugué et
complémentaire de deux nécessités : le besoin pour
une meilleure efficacité économique (économies de temps,
d'efforts et d'argent) des investissements en formation en ligne et celui d'une
amélioration de l'efficacité pédagogique de ses
produits.[http1]
L'enjeu central se résume à cinq défis
de base :
Accessibilité :
permettre la recherche, l'identification, l'accès et la livraison de
contenus et composantes de formation en ligne de façon
distribuée.
Interopérabilité :
permettre l'utilisation de contenus et composantes développés par
une organisation sur une plateforme donnée par d'autres organisations
sur d'autres plateformes.
Ré-utilisabilité :
permettre la réutilisation des contenus et composantes à
différentes fins, dans différentes applications, dans
différents produits, dans différents contextes et via
différents modes d'accès.
Durabilité : permettre aux
contenus et composantes d'affronter les changements technologiques sans la
nécessité d'une réingénierie ou d'un
re-développement.
Adaptabilité : permettre
la modulation sur mesure des contenus et des composantes. [http1]
III. Standard
III.1. Définition
Un standard est un ensemble de recommandations issues des
expériences de professionnels d'un secteur, de groupes
d'intérêts, d'organismes nationaux ou internationaux de
normalisation et préconisées par un groupe représentatif
d'utilisateurs.
Le standard se défini ainsi à la
lumière d'un ensemble d'usages constatés, récurrents et
pour un périmètre fini. Voilà pourquoi l'apparition d'un
standard engendre souvent la génération d'un ensemble de
standards collatéraux visant à le compléter ou à
l'adapter à des domaines adjacents ou périphériques.
Selon les organisations chargées de
standardiser :
"Les standards techniques sont construits à partir de
spécifications élaborées par des groupes de travail (AICC,
ADL,
IMS, Dublin
Core ...). Ces spécifications sont étudiées et
analysées et ont l'accréditation de standard après qu'un
consensus soit obtenu lors d'une réunion annuelle de l'
IEEE."
[http1]
IV. Norme / Standard
La différence norme / standard semble se situer
essentiellement au niveau des acteurs en jeu et des procédures de
consensus attachées :
Une norme est édictée par un organisme de
normalisation en collaboration avec des professionnels du domaine. La norme est
définie clairement dans des documents disponibles publiquement.
Les normes peuvent être lourdes et difficiles à
mettre en oeuvre car elles sont souvent le résultat de discussions et de
compromis entre de nombreuses instances aux intérêts
divergents.
La norme fait référence surtout à l'
ISO et
à ses instances nationales telles que l'
AFNOR en
France avec des processus de validation assez lourds.
Un standard ou format propriétaire est défini
par un industriel ou un groupe d'industriels. Un standard permet de
définir la nature des documents qui pourront être
échangés entre les différents services ou produits de
l'industriel. Il s'agit la plupart du temps de format de données non
ouverts, c'est-à-dire dont la définition n'est pas publique, afin
de garder une avance technologique par rapport à la concurrence.
L'industriel fait évoluer régulièrement son format de
données, ce qui occasionne parfois des incompatibilités
ascendantes entre les produits. Un standard peut parfois devenir une norme.
[http1]
V. Le cycle de la normalisation
Cinq phases y apparaissent clairement :
Phase initiale
Cette phase permet de recenser et d'identifier les
exigences auxquelles les normes devraient répondre.
C'est en quelque sorte l'étape de l'élaboration du cahier des
charges; [http2]
2e phase
La deuxième phase est celle de la définition ou
de l'élaboration de spécifications,
les intervenants (développeurs, consortiums, groupes de
travail...) élaborent des ensembles structurés et précis
de spécifications techniques visant à répondre, de
façon opérationnelle, aux exigences recensées dans la
phase précédente.
C'est à ce stade que le besoin se fait sentir pour le
« testing » et « l'évaluation » des produits et
services élaborés selon les spécifications connues.
[http2]
3e phase
La troisième phase est la phase de testabilité.
C'est à ce moment qu'apparaissent ou se consolident des groupes qui
développent des projets pilotes, des prototypes etc., susceptibles de
tester la validité des spécifications dans la
réalité concrète. Plus les tests sont concluants et plus
ils sont répétés et raffinés, plus les
spécifications sont jugées «stables ». C'est à
ce moment que des documents écrits sont préparés afin de
préciser les spécifications et leur donner corps. On les intitule
: « lignes directrices », « guide d'implantation », «
modèle de référence », « schéma ».
[http2]
4e phase
C'est la phase de la standardisation. À ce stade, le
raffinement et la consolidation des acquis de l'expérience se font
sentir. Les succès des modèles sont comptabilisés et se
confirment. Les échecs sont éliminés ou retournés
à la planche à dessin. À ce stade, se développent
ce que l'on appelle des « standards de fait », c'est-à dire
des modèles dominants qui prennent le pas sur l'industrie et s'imposent
d'eux-mêmes comme des exemples à suivre. [http2]
5e phase
La dernière phase est celle de la normalisation. C'est
la phase où les standards venus à maturité sont
discutés, validés et sanctionnés officiellement dans le
cadre d'un processus ouvert qui vise à assurer un haut de degré
de précision et de consensus. Ils deviennent des normes. Cela ne peut
être exercée que par un organe reconnu légalement à
cette fin sur un plan national (norme nationale), régional (norme
régionale) ou international (norme internationale de l'ISO). [http2]
VI. LOM
LOM est un modèle (ou standard) international
utilisé pour l'indexation des ressources pédagogiques. LOM est un
ensemble de métadonnées permettant de décrire la nature,
la syntaxe et la sémantique d'un objet pédagogique.
L'objectif de ce standard est de spécifier un
schéma de base, qui puisse être utilisé pour servir de
fondement au développement de pratiques, par exemple pour faciliter la
mise en oeuvre automatique, évolutive, des objets pédagogiques
par les outils informatiques. Il cherche aussi, par un schéma conceptuel
commun, à faciliter l'
interopérabilité,
donc l'échange des informations, des travaux, des supports
d'enseignement, mais aussi à faciliter les moyens de diffuser et
retrouver les ressources. [http3]
VI.1. Caractéristiques du modèle LOM
LOM résulte des efforts conjoints de plusieurs
organisations et consortiums intéressés par la normalisation. Le
modèle LOM a été adopté par la plupart des
organismes de standardisation (
IEEE LTSC,
IMS, ADL,
ARIADNE) et le plus souvent adaptées dans le cadre des
profils
d'application (
SCORM,
CanCore, UK LOM Core, Normetic, etc..). C'est un des standards de fait les plus
reconnus et utilisés.
Les LOM sont le schéma de métadonnées le
plus détaillé qui existe. Elles comprennent plus de 80
éléments hiérarchisés, regroupés en neuf
catégories. LOM intègre les 15 champs du
Dublin Core
qui est un modèle de métadonnées générique
défini pour être appliqué à tout type de document
numérique :
1. Général
Cette
catégorie regroupe les caractéristiques générales
indépendantes du contexte qui décrivent la ressource dans son
ensemble :
identifiant
de l'objet (identificateur global unique), son titre, sa description, la liste
des langues utilisées, une liste de mots clés, l'étendue
de la ressources (géographie, culture), le type de structure
(collection, linéaire, hiérarchique, etc.), son niveau de
granularité
(de 1 à 4, 1 désignant un cours entier).
2. Cycle De Vie
Caractéristiques relatives au cycle de vie :
historique de la ressource (version), état de la ressource (du point de
vue de son achèvement ou de sa disponibilité) et d'autre part les
personnes qui ont affecté cette ressource durant son évolution
(instance unique).
Toutes les sous catégories sont fondamentaux pour
pouvoir faire fonctionner un système d'information structurée
avec métadonnées. La plupart de ces catégories sont bien
connues des bibliothécaires, mais doivent être modifiées en
conséquence.
3. Méta Métadonnées
Caractéristiques de la description elle-même
(spécifiques à l'enregistrement des
métadonnées) : la date de contribution, les
différents contributeurs à l'établissement des
métadonnées, etc. Il est à souligner que la non confusion
entre création des métadonnées et création de
ressources doit être soulignée comme primordiale. Cette
catégorie est également fondamentale pour pouvoir faire
fonctionner un système d'information structurée avec
métadonnées. Les sous-ensembles que contient cette
catégorie étaient pour la plupart inconnus des
bibliothécaires qui y ont été confrontés lorsqu'ils
ont construit des bibliothèques numériques.
4. Technique
Cette catégorie
définit les exigences techniques en termes de navigateur, de
système d'exploitation, ou des caractéristiques comme le type des
données, le format, la taille de l'objet pédagogique (en octets),
sa localisation physique (URL Uniform Ressource Locator ou
URI Uniform
Ressource Identifier), sa durée, etc.
5. Pédagogie
Cette catégorie
se décline en treize sous-catégories pédagogiques. C'est
souvent par ces sous-catégories que l'on améliore l'exploitation
du contenu pédagogique. Il est par contre fondamental de bien comprendre
que les deux items densité sémantique et description ne sont pas
destinés à décrire la ressource pour la retrouver
ultérieurement ou la classer.
· Type
d'interactivité : le type d'interaction entre la
ressource et l'utilisateur typique (Active, Expositive, Undefined).
· Types de ressources
pédagogiques : le type pédagogique (exercice,
simulation) peut être présent plusieurs fois.
· Niveaux
d'interactivité : degré
d'interactivité.
· Densité
sémantique : de très basse
à très élevée.
· Rôle présumé de
l'utilisateur final : public ciblé
prioritairement destinataire de la ressource.
· Niveau : niveau du
public ciblé.
· Proposition
d'utilisation : description relative à l'utilisation
pédagogique de la ressource (contexte).
· Tranche
d'âge : âge de l'utilisateur.
·
Difficulté : difficulté de la
ressource.
· Durée d'apprentissage
moyen : durée approximative ou
typique d'apprentissage
pour le ou les niveaux indiqués.
·
Description : commentaires sur
l'utilisation de la ressource.
· Language : langue de
l'utilisateur.
6. Droits
Caractéristiques
exprimant les conditions d'utilisation : les droits (copyright)
liés à la ressource, les conditions légales d'utilisation,
éventuellement son coût.
7. Relation
Caractéristiques exprimant les liens avec d'autres
ressources pédagogiques en précisant la nature de la relation
(« ...est requis par... », « ...est une partie
de... »).
8. Annotation
Annotations ou commentaires
sur l'utilisation pédagogique de la ressource.
9. Classification
Caractéristiques
de la ressource décrite par des entrées dans des systèmes
de classification.
Ces descripteurs ne sont pas obligatoires mais certains
peuvent être répétés.
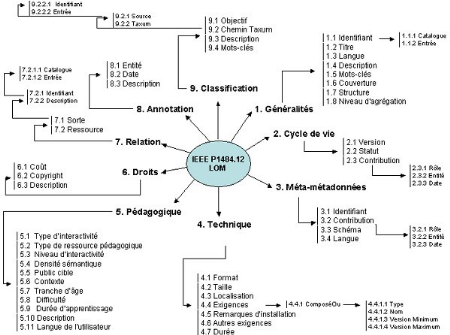
Fig1 : LOM
VI.2. Limitations du modèle LOM
§ Lourdeur du modèle
Arbitrage à réaliser entre le volume et la
pertinence des champs du modèle.
§ Complexité technique du
modèle
Difficulté de remplir les 79 champs du
modèle.
§ Insuffisance en termes d'aspects
pédagogiques
Les 9 catégories de LOM renferment implicitement des
modèles pédagogiques sous-jacents, approuvés de facto.
Dans l'état présent, ces normes ressortent davantage d'un
catalogue de ressources que d'une aide à la mise en place de dispositifs
efficients de transfert ou de construction de savoirs.
§ Manque de définition de ce qu'est
une ressource pédagogique
Les LOM s'appliquent indistinctement à des objets qui
ont des natures et des fonctionnalités très différentes
(ressources, activités et unité d'apprentissage) : cela
empêche leur description en tant que tels
§ Excès de
généricité
Les LOM offrent des champs de données à utiliser
comme fourre tout (Ex : la catégorie "classification" permet
à chaque institution de classer l'objet suivant son propre catalogue).
§ Rôle de descripteur n'est pas assez
poussé pour prendre en compte des
ressources plus interactives
Comme celles mises en oeuvre dans l'évaluation des
connaissances.
§ Manque de pertinence de certains champs en
termes d'indexation
Certains descripteurs (tels que la "densité
sémantique") apparaissent trop subjectifs, donc difficiles à
informer
§ Focalisation exclusive sur les contenus
sans prise en considération de la démarche pédagogique
à leur associer
§ Incompatibilité avec des
représentations structurées de l'information
Les
LOM ne permettent pas, dans leur forme actuelle, de représentations
enrichies de connaissances (liens, ontologies...)
§ Aspects déterministe de certaines
listes de valeurs
Par exemple, la valeur du champ "Niveau d'agrégation"
induit celle du champ "structure" :
Valeurs possibles pour le
"niveau d'agrégation" :
§ 1 (le plus petit niveau
d'agrégation : atomes) par exemple : des données brutes
ou des fragments
§ 2 (ensemble d'atomes) par
exemple : un document HTML comprenant des images, une conférence,
une leçon, ...
§ 3 (ensemble de ressources de niveau
2) : un site web avec un sommaire, un cours entier, ...
§ 4 (ensemble de ressources de niveau
") : un cursus, ...
Valeurs possibles pour la "Structure" :
§ Atome
§ Collection (ensemble d'objets sans relations
particulières entre eux)
§ Réseau (ensemble d'objets avec des
relations non spécifiées)
§ Hiérarchique (ensemble d'objets dont
les relations peuvent être représentées par une structure
en arbre)
§ Linéaire (ensemble d'objets
complètement ordonnés linéairement (par des relations de
précédence)
§ Ambiguïté dans l'utilisation de
la catégorie "Relation" [http3]
VII.
SCORM
(Sharable Content Object Reference
Model)
La
norme
SCORM est une spécification permettant :
· De créer des
objets
pédagogiques structurés
· D'agréger les ressources de "bas niveaux" (
grains)
en entité de "haut niveau" (Content Agregation Model)
· De suivre l'activité de l'apprenant.
SCORM permet aux systèmes d'apprentissage en ligne de
trouver, importer, partager, réutiliser, et exporter les contenus
d'apprentissage (cours), de manière normalisée. Elle vise le web
comme principal moyen pour offrir l'instruction, s'appuyant sur
l'hypothèse que le web constitue le meilleur support pour maximiser
l'accès au contenu d'apprentissage et la réutilisation de ce
contenu.
La "norme" SCORM d'
ADL
(Advanced Distributed Learning) s'impose aujourd'hui comme "le"
standard en matière de conception de cours et de
plates-formes
e-learning (LMS). L'ensemble d'un
parcours
pédagogique conçu sur une plateforme peut ainsi
être exporté depuis celle-ci sous la forme d'un fichier
compressé, conçu conformément au standard SCORM, puis
importé et reconnu sur une autre plateforme. [http7]
VII.1.Historique
L'origine
des standards SCORM provient du Département de la défense (DoD)
et du White House Office of Science and Technology Policy (OSTP) qui en
novembre 1997, ont lancé le projet ADL. Le but de ce projet était
de fournir l'accès à un enseignement de grande qualité,
qui en plus pourrait être personnalisé en fonction des besoins de
chacun mais qui par-dessous tout serait rentable. ADL développa le
modèle SCORM qui a pour objectif de favoriser la création de
contenus d'apprentissage réutilisables et cela en y appliquant un
ensemble de lignes directrices, de spécifications et de normes
fondées sur le travail de plusieurs organisations différentes
liées à l'apprentissage en ligne (
AICC,
ARIADNE,
LTSC de l'
IEEE et
IMS).
[http7]
VII.2. Le but de SCORM
Le SCORM aide à définir les bases techniques
d'un environnement d'apprentissage en ligne. Le SCORM décrit un «
modèle d'agrégation du contenu » et un « environnement
d'exécution » pour les objets d'apprentissage afin d'appuyer un
enseignement adaptatif fondé sur les objectifs, les
préférences, le rendement et d'autres facteurs liés
à l'apprenant (notamment les techniques d'instruction). Le SCORM
décrit également un modèle de « séquencement
et navigation » pour la présentation dynamique, et selon les
besoins de l'apprenant, des objets d'apprentissage. [http7]
VII.3. Version de SCORM
SCORM 1.0
La version originale de SCORM, la version 1.0, était
une validation de principe seulement. Elle a présenté la notion
des objets contents en commun (SCOs) et du modèle d'api dans lesquels le
fardeau de communication de gestion à travers l'Internet est
manipulé par l'environnement d'exécution, pas par les objets
contents.
SCORM 1.1
Le premier modèle de série de SCORM était
la version 1.1. Il a employé un dossier du format XML de structure de
cours basé sur les caractéristiques d'AICC pour décrire la
structure contente, mais a manqué d'un empaquetage robuste manifeste et
du soutien des métadonnées. La version 1.1 a été
rapidement remplacée par SCORM 1.2.
SCORM 1.2
SCORM 1.2 était la première version avec un vrai
essai de conformité sous forme de suite d'essai. Il emploie les
spécifications d'empaquetage contentes d'IMS avec le plein contenu
manifeste et l'appui pour des métadonnées décrivant le
cours. Permet également l'étiquetage détaillé
facultatif de métadonnées des objets et des capitaux contents
décrits dans le manifeste. La version 1.2 est plus maintenue ou pas
soutenue par ADL.
SCORM 2004(1.3)
La version en cours de SCORM est la version 1.3,
également connus sous le nom de SCORM 2004. Elle inclut la
capacité de spécifier l'ordonnancement adaptif des
activités cette utilisation les objets de contenu, nouvelles normes pour
la communication d'api, et résout beaucoup d'ambiguïtés.
SCORM 2004 inclut également la capacité de partager et employer
des informations sur le statut de succès pour le multiple apprenant des
objectifs ou des compétences à travers les objets contents et
à travers des cours pour le même étudiant dans le
même système de gestion de étude.
La version en cours/édition de SCORM est la version
1.3.3 (3ème édition de SCORM 2004).
Éditions de SCORM 2004
· 1êr édition (le janvier 2004) - version a
changé ainsi chaque livre pourrait être indépendamment
maintenu
· 2ème Édition (le juillet 2004) -
améliorations incluses concernant le modèle content
d'agrégation et l'environnement d'exécution
· 3ème Édition (l'octobre 2006) - diverses
conditions de conformité clarifiées et de l'interaction entre les
objets contents et l'environnement d'exécution pour l'ordonnancement ;
nouvelles conditions de conformité supplémentaires
d'améliorer l'interopérabilité [http4]
VII.4.
Caractéristiques de la norme SCORM
Un cours SCORM est composé d'objets "SCO" (Sharable
Content Object). Un SCO est une unité (ou
grain
pédagogique) de contenu qui possède un sens
pédagogique, qui peut être réutilisée dans un autre
cours, et qui sera reconnaissable par une plate-forme SCORM. Un SCO pourra
être composé de pages HTML, d'animations, de dessins, de
vidéos.... Plusieurs SCO pourront former un
Learning
Object ("LO", c'est à dire un objet pédagogique) et
un ou plusieurs LO pourront former un cours.
VII.5. Pourquoi SCORM ?
Voici les principales exigences auxquelles le modèle
SCORM devrait permettre, à terme, de satisfaire :
· Réutilisable : il peut
être facilement modifié et utilisé par différents
outils de développement.
· Accessible : il peut être
recherché et rendu disponible aussi bien par des apprenants que par des
développeurs.
· Adaptable : il peut être
personnalisé selon un contexte (personnes, organisations) particulier.
·
Interopérable ou compatible : il peut
fonctionner sur une grande palette de matériel, plates-formes,
systèmes d'exploitation, navigateurs Web, etc...
· Durable : il ne requiert pas
d'importantes modifications avec les nouvelles versions des logiciels.
· Abordable : le temps et les
coûts nécessaires pour dispenser des formations peuvent être
réduits et amener à une augmentation de l'efficience et de la
productivité. [http5]
VII.6. Découpé en plusieurs
parties
SCORM peut être découpé en plusieurs
parties distinctes :
· Modèle d'agrégat de
contenu
Le modèle d'agrégation du contenu SCORM
constitue un moyen, neutre sur le plan pédagogique, qui permet aux
responsables de la conception et de la mise en oeuvre de la formation de
regrouper les ressources appropriées dans le but d'offrir un parcours
individualisé de formation.
Une ressource d'apprentissage : consiste
en toute représentation de l'information utilisée dans le cadre
d'un parcours.
Les parcours de formation : sont
constitués d'activités supportées par des ressources
d'apprentissage électroniques et non électroniques.
Le Modèle de contenu SCORM décrit les composants
du modèle de référence SCORM utilisés pour
créer un parcours d'apprentissage à partir de ressources
d'apprentissage réutilisables. Le modèle de contenu
précise également comment ces ressources d'apprentissage de
niveau inférieur, partageables et réutilisables, sont
regroupées de afin de constituer des contenus d'apprentissage (Sharable
Content Object (SCO)). [Sémé2006]
Asset
Sous sa forme la plus élémentaire, le contenu
d'apprentissage se compose d'actifs (Assets), c'est-à-dire de
représentations électroniques de médias, de textes,
d'images, de séquences sonores, de pages web, d'objets
d'évaluation ou d'autres éléments d'information qui
peuvent être envoyés à un poste client.
Fig2: Asset
Sharable content Object (SCO)
Un objet de contenu partageable (Sharable Content Object, ou
SCO) est un ensemble comprenant un ou plusieurs actifs (Assets), y compris un
actif spécifique qui utilise l'environnement d'exécution du SCORM
pour communiquer avec des logiciels de gestion pédagogique (LMS2). Le
SCO peut être suivi par un LMS dans l'environnement d'exécution du
SCORM. La figure 3 ci-dessous contient un exemple de SCO
constitué de plusieurs actifs (Assets).
Pour pouvoir être réutilisé, le SCO
lui-même doit être indépendant du contexte d'apprentissage.
Les SCO sont conçus pour être des unités subjectivement
petites, de façon à pouvoir être réutilisées
dans un grand nombre d'objectifs d'apprentissage.
Un SCO peut être décrit au moyen de «
métadonnées de SCO » pour faciliter la recherche et le
repérage dans les dépôts de données en ligne, ce qui
a pour conséquence d'accroître les possibilités de
réutilisation.
Fig3 : Sharable Content Objet
La nécessité pour un SCO de participer à
l'environnement d'exécution du SCORM offre les avantages suivants :
- Tout LMS supportant l'environnement d'exécution du
SCORM peut lancer des SCO et en assurer le suivi, peu importe qui les a
générés,
- Tout LMS supportant l'environnement d'exécution du
SCORM peut assurer le suivi d'un SCO et en connaître les dates de
début et de fin,
- Tout LMS supportant l'environnement d'exécution du
SCORM peut lancer
n'importe quel SCO de la même façon.
[Sémé2006]
· L'environnement d'exécution
SCORM
L'environnement d'exécution doit permettre de lancer
les ressources d'apprentissage et consister en un mécanisme
standardisé permettant aux ressources d'apprentissage de communiquer
avec le LMS. Il s'appuie sur un langage commun (un vocabulaire
prédéfini) constituant la base de la communication. Comme on peut
le voir en examinant la figure suivante, ces trois aspects
caractéristiques de l'environnement d'exécution concernent
respectivement le lancement, l'interface de programmation d'applications (API)
et le modèle de données. [Sémé2006]
· Le modèle de
séquencement et de navigation
Permet une présentation dynamique du contenue. Il
décrit comment le système interprète les règles de
séquencement exprimées par un développeur de contenu,
ainsi que les événements de navigation lances par l'apprenant ou
par le système.
Ainsi, SCORM permet d'agréger automatiquement des
informations du style :
· Combien de temps telle personne a-t-elle passé
sur telle ou telle présentation (temps passé) ?
· Quelles diapositives a-t-elle regardées ?
· Quels résultats a-t-elle obtenus aux quiz ?
VII.7. Limites du SCORM
· Il n'est pas possible de placer des liens à
l'intérieur d'un SCO vers un autre SCO.
Les liens internes entre
les SCOs rendent l'extraction d'un SCO et sa ré-utilisation impossible
sans incorporer les autres SCOs.
· De même, un SCO ne peut pas directement
transmettre des données à un autre SCO.
· Créer du contenu SCORM est une tâche
lourde et peut donc présenter un coût de production
élevé.
Ecrire des métadonnées pour un SCORM implique
dans certains cas, remplir plus de 80 descriptions et prend donc un temps
considérable à faire. Cela en vaut la peine uniquement si le
contenu est par la suite réutilisé ou échangé.
[http6]
VIII. Conclusion
Le but de l'effort de normalisation que l'on observe
aujourd'hui dans les milieux de la formation à distance, c'est d'en
arriver à définir des objets d'apprentissage réutilisables
(Reusable Learning Objects).Ces entités, codées sous format
numérique ou non, peuvent être utilisées,
réutilisées ou référenciées lors d'une
formation supportée par les technologies.
En d'autres termes, il s'agit de rendre accessibles des cours
à partir d'environnements technologiques différents (des
plateformes d'apprentissage à distance, par exemple) de manière
à faciliter la mutualisation des ressources pédagogiques.
I. Introduction
Plusieurs plateformes ont été
développées et plusieurs sont disponibles sur le web en libre
accès. Ces plateformes sont des environnements qui permettent à
un enseignant de créer et de gérer très facilement un
cours, en lui laissant le libre choix de la méthode
pédagogique, et sans nécessiter de
compétences informatiques particulières.
Elles offrent aussi des outils de communication (forums,
chat), des instruments d'évaluation (exercices, sondages, travaux), et
la possibilité de déposer des ressources pédagogiques
(fichiers PDF, séquences vidéo, etc.).
II. LMS
L'objectif d'un LMS est de simplifier l'administration de
l'étude/des programmes de formation dans une organisation. Pour des
employés, il les aide à mesurer et prévoir leur
progrès d'étude, et à communiquer et collaborer avec leurs
pairs.
Pour des administrateurs, il les aide pour viser, livrer,
dépister, analyser, et rendre compte de leurs employés apprenant
la « condition » dans l'organisation. La plupart de LMSs
n'ont pas la capacité de créer le contenu d'instruction,
et c'est pourquoi la plupart des fournisseurs de LMS ou fournissent les outils
contents additionnels de création, ou collaborent avec les fournisseurs
de contenu pour fournir les solutions complètes. Des outils contents
autonomes de création comme
Dreamweaver
de Macromedia peuvent également être utilisés
pour créer le contenu adapté aux besoins du client.
De la figure 4, il est clair que le plus petit morceau d'un
seul bloc d'instruction dans le LMS soit le cours lui-même. Ainsi, s'il y
a une quelle conque réutilisabilité, elle devrait être au
niveau du cours (un cours --> beaucoup d'étudiants). [http8]
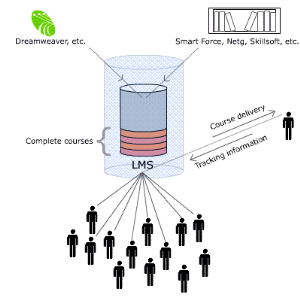
Fig4 : LMS
II.1. Fonctionnalités des LMS
· Gestion des apprenants (définition des
différents types de profils avec les droits associés)
· Outils simples de conception des cours
· Suivi du cursus de formation
· Suivi et bilan de la formation
· Classes virtuelles - interaction entre le tuteur et les
apprenants en mode synchrone ou asynchrone (audio/vidéo
conférence, dialogue, tableau blanc, etc.)[http9]
III. CMS
Les "Content Management Systems" forment une famille de
solutions intégrées et "multi plates-formes" de
complexités diverses, qui permettent de gérer facilement le
contenu dynamique et rédactionnel d'un site web. Ce sont des
systèmes de publication en ligne, c'est-à-dire de sites webs
constitués de deux espaces : un espace dit "public" ou "site
public", qui est accessible aux internautes et propose l'accès aux
contenus, et un "espace d'administration" ou "site privé" dont
l'accès est réservé, qui contient le système de
gestion et de publication des contenus.
Ils offrent la possibilité à des non-techniciens
de mettre en place des sites ou des applications Internet, en s'affranchissant
des contraintes techniques et de développement.
Cette gestion
automatisée englobe les multiples facettes de l'édition de tout
contenu web : tout d'abord, la création proprement dite, puis la
validation des contenus créés, puis enfin leurs conditions de
publication.
Les contenus disponibles sur Internet sont
généralement distingués en deux catégories :
soit il s'agit d'éléments dit "statiques", comme un fichier
texte, une image, un fichier vidéo ou un cours au format Flash, par
exemple, soit il s'agit d'éléments "dynamiques",
c'est-à-dire puisés au sein d'une ou plusieurs bases de
données, comme une liste de contacts, un catalogue de produits
commerciaux ou une série de modules de formation.
Le coeur d'un CMS est schématiquement constitué
de deux noyaux imbriqués : un système de classement des
contenus et un système de suivi de création et de publication de
ces contenus.
Le premier organise et classe les informations en les
associant à des "métadonnées" prédéfinies,
comme la date de rédaction, l'auteur, le titre, la thématique,
etc. Il facilite l'accès aux données par des modes de recherche
avancés. Le second offre un espace de "workflow" (chaîne de
travail) qui formalise et organise les étapes du cycle de vie d'un
document : création, validation, publication, archivage, mise
à jour, suppression, etc.
De la figure 5, il est clair que la plus petite information
d'un seul bloc soit le composant content. Ainsi, dans ce cas-ci la
réutilisabilité serait au niveau composant content (un composant
content --> beaucoup d'articles --> beaucoup de lecteurs).Ces composants
contents une fois utilisés dans le domaine de étude s'appellent
« étude objecte », ou l'étude
réutilisable objecte (RLOs). [http8]
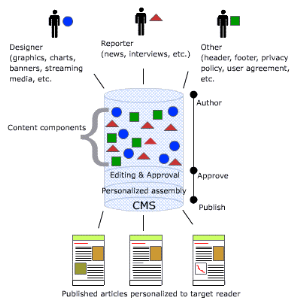
Fig5 : CMS
III.1. Les Fonctionnalités des CMS
Les CMS permettent :
· de séparer le fond (contenu) de la forme
(modèle de présentation), le gabarit permet de créer un
modèle de page utilisé pour travailler indépendamment le
contenu ou la forme. La feuille de style
CSS
facilite la présentation du contenu (police, taille ...). L'interface
utilisateur
WYSIWYG
simplifie la création de contenu ;
· d'éviter les saisies multiples, les
hyperliens
sont automatiquement mis à jour ;
· de réaliser un
travail
collaboratif (avec contrôle des versions) et donc
d'être un support du
Knowledge
Management ;
· de mettre en ligne des ressources en fournissant une
chaine de publication
workflow
· de gérer des droits : afin de répartir
les rôles des différents acteurs ;
· d'organiser le contenu : ressources (document, audio,
vidéo), outils de
groupware
(agenda partagé ...) ;
· d'intégrer des outils du
web2.0 :
blog,
forum,
chat,
wiki,
syndication,
Podcast
;
· d'intégrer les données externes contenues
dans le système d'information de l'entreprise :
bases de
données externes, annuaire
LDAP...
;
· d'adapter l'intégration de modules et composants
aux besoins de l'organisation : la structure des CMS n'est pas figée
dans le temps, il est possible d'ajouter ou de retirer les modules ou
composants.
Pour résumer, les CMS forment une famille de solutions
intégrées, ce sont des plates-formes de
publication en ligne, elles permettent de gérer facilement le contenu
dynamique et rédactionnel d'un site web en donnant des droits respectifs
à chacun. La plupart des CMS sont développés en PHP et
MYSQL mais il existe également des CMS développés sans
base de données. [http10]
IV. RLO
Il y a beaucoup de définitions de RLOs. Certains
égalisent un RLO à un graphique simple ou à un dossier
visuel. D'autres égalisent un RLO à un petit morceau
d'instruction qui vise un but d'exécution spécifique. Par
exemple, Netg
définit
leur RLO comme : la plus petite expérience d'instruction
indépendante qui contient un objectif, une étude et une
évaluation.
« L'objectif » est le but d'instruction,
ou le but d'exécution, que le RLO vise à atteindre.
« L'étude » est le corps du RLO c'est la
stratégie d'instruction que le RLO emploie pour satisfaire l'objectif
d'instruction. La pièce «d'évaluation » examine
la maîtrise au-dessus des thèmes.
Puisque RLOs sont les plus petits morceaux d'un seul bloc de
l'instruction, ils peuvent être mélangés et assortis pour
créer de plus grands ensembles d'instruction personnalisés
(cours, leçons, voies, etc.) plus ou moins la même manière
que les composants contents sont mélangés et assortis pour
créer les articles personnalisés. [http8]
V. LCMS
LCMS est un système (la plupart du temps basé
sur le WEB) qui est employé pour écrire, approuver,
éditer, et contrôler apprendre le contenu (plus
spécifiquement désigné sous le nom d'apprendre des
objets). Un LCMS combine les dimensions administratives et de gestion d'un LMS
traditionnel avec la création contente et des dimensions
personnalisées d'assemblée d'un CMS.
Dans un LCMS (voir Fig6), vous auriez des bibliothèques
de RLOs qui peuvent être employées indépendamment, ou comme
partie de plus grands ensembles d'instruction (un RLO --> beaucoup de cours
--> beaucoup d'étudiants).
Juste comme dans un CMS, il y aurait des processus de
déroulement des opérations autour d'un LCMS :
· Les concepteurs d'instruction créeraient un
nouveau RLOs visant des buts d'exécution spécifique, ou les
nouveaux cours en se réunissant déjà ont
créé RLOs
· Les rédacteurs (concepteurs d'instruction
aînés apprenant des dirigeants) iraient vue le RLO/course soumis,
et l'approuvent ou rejettent. Si approuvé, le RLO/course serait rendu
disponible à tous pour employer, autrement il serait renvoyé pour
la révision
· Les règles de personnalisation placeraient
dedans, visant le nouveaux RLOs/cours à ceux qui ont correspondu (ou,
ont souscrit) son profil
· RLOs et cours qui ont survécu à leur
utilité seraient soutenus et archivés, ou juste supprimés
du dépôt [http8]
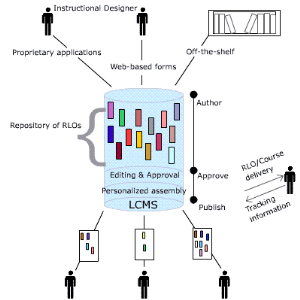
Fig6 : LCMS
V.1. Fonctionnalités des LCMS
· Création de contenu
· Stockage de contenu
· Diffusion dynamique
· La gestion de groupes (travail collaboratif)
· La comptabilité avec les normes (AICC, SCORM)
· Prise en compte du LOM (Learning Object Model,
métadonnées...) [http9]
VI. Utilité des plates-formes
d'eLearning
· Regrouper un ensemble de fonctionnalités sur
une même plate-forme afin de supporter les différents acteurs
de la formation (apprenants, enseignants, tuteurs, cours, etc.)
· Organiser et faciliter la création collaborative
de contenu
· Gérer les apprenants et leurs cursus
· Gérer de multiples contenus
· Gérer simultanément plusieurs formations
[http9]
VII.
Principales plates-formes existantes
Plus de 250 plates-formes d'eLearning dénombrées
à ce jour
1. Plates-formes propriétaires
· WebCT
· BlackBoard
· TopClass
· Apex Learning
· ANGEL Learning
· Etc.
2. Plates-formes libres (Open Source)
· ATutor
· Moodle
· Dorkeos
· Claroline
· Sakai Project
· Etc.
VIII. Points clés pour choisir une plate-forme
Choisir une plate-forme adaptée aux besoins de
l'ingénierie pédagogique est une étape importante pour
l'optimisation du dispositif et l'atteinte des objectifs.
Ce choix peut ainsi être conditionné
par :
· Respect des
normes d'eLearning
· Gestion multi sites
· Gestion de groupes d'apprenants
· Solutions de messagerie : forum, chat, liste de
diffusion, etc.
· Statistiques des activités de l'apprenant
(parcours, temps, etc.)
· Références existantes
· Support du système, notamment la présence
de clubs d'utilisateurs
· Compatibilité avec votre environnement
technologique
· Si possible :
· Intégration des apprenants par LDAP (OpenLDAP ou
AD)
· Gestion multi-langue
· Favorisez les systèmes basés sur des
logiciels libres, car plus compatibles avec le reste du monde (ATutor, Moodle,
Dokeos, etc.) [http9]
IX. Conclusion
En conclusion, les LMS et les LCMS sont deux outils
différents et complémentaires. La difficulté
d'appréhender cette différence provient notamment du fait que
bien souvent les LCMS intègrent toutes les fonctionnalités de
base d'un LMS. Les LCMS offrent donc les services
fusionnés du LMS et du CMS (ou pour une raison de simplification : LCMS
= LMS+ CMS).
I. Introduction
L'ingénierie de connaissances (IC) a longtemps
été considérée comme le domaine de
prédilection du développement d'expertise en conception de
système à base de connaissances. Afin d'améliorer la
conception des systèmes intelligents; historiquement,
l'ingénierie ontologique (IO) a émergé de
l'ingénierie des connaissances l'ingénierie ontologique permet de
spécifier la conceptualisation d'un système, c'est à dire,
de lui fournir une représentation formelle des connaissances qu'il doit
acquérir, sous la forme de connaissances déclaratives
exploitables par un agent.
Ainsi, l'exploitation par un mécanisme
d'inférence, d'une représentation de type déclarative
telle que l'ontologie, tout en suivant les règles d'inférence
définie dans cette ontologie, est la source de l'intelligence de
système.
L'ingénierie de connaissances a ainsi donné
naissance à l'ingénierie ontologique, où l'ontologie est
l'objet clé sur lequel il faut se pencher. La nécessité
d'une ontologie et d'une ingénierie ontologique des systèmes
à base de connaissances commence à être comprise et
accepté. [Chet&Rou]
II. Définition d'une ontologie
A l'origine, l'ontologie est une notion philosophique, dans
laquelle les philosophes ont tenté de rendre compte de l'existence de
façon formelle. L'intelligence artificielle et les chercheurs du Web
sémantique ont adapté ce terme dans leur propre jargon et
diverses définitions d'ontologie existent dans la littérature
informatique.
[Mizoguchi, 2004] insiste sur la nature conceptuelle d'une
ontologie, faite pour pouvoir partager des connaissances entre homme et
systèmes, et entre systèmes. Il considère
conceptualisation, partage et réutilisation comme les
concepts-clés d'une ontologie, ce qui représente les attentes de
la communauté d'intelligence artificielle sur les ontologies.
[Natalya et al, 2001] définit une ontologie comme une
description formelle explicite des concepts dans un domaine du discours
(classes appelées parfois concepts), des propriétés de
chaque concept décrivant des caractéristiques et attributs du
concept (attribut appelés parfois rôles ou
propriétés) et des restrictions sur les attributs (facettes
appelées parfois restrictions de rôles). Classe et concept
définissent le même terme dans ce qui suit. Une
méthodologie pour le développement d'une ontologie est aussi
développée dans [Natalya et al, 2001].
En résumé, en informatique, une ontologie est
comprise comme un système de concepts fondamentaux qui sont mis en
relation les uns avec les autres et représentés sous une forme
compréhensible par un ordinateur. [Mbao2007]
III. Rôle des ontologies
La communauté d'intelligence artificielle utilise les
ontologies pour deux raisons principales : le partage et la
réutilisation de connaissances, et l'amélioration de la
communication.
La réutilisation des données sur un domaine
précis est une des raisons majeures qui ont poussé la recherche
sur les ontologies.
D'après [Ranwez, 2000] il existe trois types de
communication dans un projet : communication homme-homme,
homme-système ou entre les différents modules du système.
Ces trois types de communication possèdent tous des
caractéristiques particulières qui engendrent certains
problèmes auxquels les ontologies peuvent apporter des solutions.
[Mbao2007]
IV. Composantes d'une ontologie
Les connaissances décrivant un domaine on utilisant la
notion d'ontologie sont représentées par les cinq
éléments suivants : Les concepts, les relations, les axiomes, les
fonctions et les instances. [Chet&Rou]
· Concept
Les concepts peuvent être une pensée, un
principe, une notion profonde. Ils sont appelés aussi termes ou classes
de l'ontologie, selon Gomez Pérez ces concepts peuvent être
classifiés selon plusieurs dimensions :
1) Niveau d'abstraction (concret ou abstrait).
2) Atomicité (élémentaire ou
composée).
3) Niveau de réalité (réel ou
irréel).
· Relation
Les relations d'une ontologie désignent les
différentes interactions et corrélations entre les concepts de
l'ontologie ces relations englobent les associations suivantes:
Sous classe de (spécification ou
généralisation), partis de (agrégation ou composition),
associé a, instance de, est un ... etc.
· Axiome
Les axiomes sont utilisés pour décrire les
assertions de l'ontologie qui seront considérés après
comme vrais, cette détermination a pour but de définir les
significations des composants d'ontologie, les contraintes sur les valeurs des
attributs, et les arguments de relations.
· Fonction
Elles constituent des cas particuliers de relation, dans
laquelle un élément de la relation, le nième est
défini en fonction des n-1 éléments
précédents.
· Instance
C'est une définition extensionnelle de l'ontologie, par
exemple les individus « Amina » et « Saloua » sont
des instances du concept «personne». [Chet&Rou]
V. Critères d'évaluation d'une ontologie
D'après Gruber, cinq critères permettent de
mettre en évidence des aspects importants d'une ontologie :
· La clarté
La définition d'un concept doit faire passer le sens
voulu du terme, de manière aussi objective que possible
(indépendante du contexte). Une définition doit de plus
être complète (c'est-à-dire définie par des
conditions à la fois nécessaires et suffisantes) et
documentée en
langage
naturel.
· La cohérence
Rien qui ne puisse être inféré de
l'ontologie ne doit entrer en
contradiction
avec les définitions des concepts (y compris celles qui sont
exprimées en langage naturel).
· L'extensibilité
Les extensions qui pourront être ajoutées
à l'ontologie doivent être anticipées. Il doit être
possible d'ajouter de nouveaux concepts sans avoir à toucher aux
fondations
de l'ontologie.
· Une déformation d'encodage
minimale
Une déformation d'encodage a lieu lorsque la
spécification influe la conceptualisation (un concept donné peut
être plus simple à définir d'une certaine façon pour
un langage d'ontologie donné, bien que cette définition ne
corresponde pas exactement au sens initial). Ces déformations doivent
être évitées autant que possible.
· Un engagement ontologique
minimal
Le but d'une ontologie est de définir un vocabulaire
pour décrire un domaine, si possible de manière
complète ; ni plus, ni moins. Contrairement aux bases de
connaissances par exemple, on n'attend pas d'une ontologie qu'elle soit en
mesure de fournir systématiquement une réponse à une
question arbitraire sur le domaine. Une ontologie est la théorie la
plus faible couvrant un domaine ; elle ne définit que les termes
nécessaires pour partager la connaissance liée à ce
domaine. [http11]
VI. Classification des ontologies
Les ontologies peuvent être classifiées selon
plusieurs dimensions. Parmi celles-ci, nous en examinerons quatre :
VI.1. Typologie selon l'objet de
conceptualisation
Par rapport quatre catégories au à l'objet de la
conceptualisation de l'ontologie, moins peuvent être
identifiées :
· Ontologie d'application
Contrairement à l'ontologie de domaine, l'ontologie
d'une application donnée ne peut pas être réutilisée
pour d'autre application, elle sert à décrire des
conceptualisations de domaine spécifique à l'application en
question.
· Ontologie de domaine
Ces ontologies peuvent être réutilisées
pour plusieurs applications qui touchent un domaine, elle concerne la
description et la définition des connaissances d'un domaine à la
qu'elle l'application désirée appartienne.
· Ontologie générique (ontologie de
haut niveau)
Cette ontologie a l'objectif d'exprimer les connaissances
acceptables par différents domaines, elle permet de catégoriser
les choses du monde, par exemple, les relations, les actions, l'espace, le
temps, etc. [Chet&Rou]
· Ontologie de représentation des
connaissances (méta ontologie)
Elle décrit les concepts utilisés par les
langages de représentation des ontologies. [Chet&Rou]
VI.2. Typologie selon le niveau de détail de
l'ontologie
Par rapport au niveau de détail utilisé lors de
la conceptualisation de l'ontologie en fonction de l'objectif
opérationnel envisagé pour l'ontologie, deux catégories au
moins peuvent être identifiées :
· Granularité fine
On parle sur ce niveau lorsque les ontologies sont très
détaillées, ou possèdent un vocabulaire plus riche capable
d'assurer une description détaillée des concepts pertinents d'un
domaine ou d'une tâche. Ce niveau de granularité peut
s'avérer utile lorsqu'il s'agit d'établir un consensus entre les
agents qui l'utiliseront. [Chet&Rou]
· Granularité large
Correspondant à un vocabulaire moins
détaillé comme par exemple dans les scénarios
d'utilisation spécifiques où les utilisateurs sont
déjà préalablement d'accord à propos d'une
conceptualisation sous -jacente. Les ontologies de haut niveau possèdent
une granularité large, compte tenu que les concepts qu'elles traduisent
sont normalement raffinés subséquemment dans d'autres ontologies
de domaine ou d'application. [Chet&Rou]
VI.3. Typologie selon le niveau de
complétude
Par rapport au niveau de complétude, trois
catégories au moins peuvent être identifiées :
· Niveau sémantique
Tous les concepts (caractérisés par un
terme/libellé) doivent respecter les quatre principes
différentiels :
- communauté avec l'ancêtre.
- différence (spécification) par rapport
à l'ancêtre.
- communauté avec les concepts frères
(situés au même niveau).
- différence par rapport aux concepts frères
(sinon il n'aurait pas lieu de le définir).
Ces principes correspondent à l'engagement
sémantique qui assure que chaque concept aura un sens univoque. Deux
concepts sémantiques sont identiques si l'interprétation du terme
à travers les quatre principes différentiels aboutit à un
sens équivalent. [Chet&Rou]
· Niveau référentiel
Outre les caractéristiques énoncées au
niveau précédent, les concepts référentiels (ou
formels) se caractérisent par un terme dont la sémantique est
définie par une extension d'objets. L'engagement ontologique
spécifie les objets du domaine qui peuvent être associés
aux concepts, conformément à sa signification formelle. Deux
concepts formels sont identiques s'ils possèdent la même
extension. [Chet&Rou]
· Niveau opérationnel
Outre les caractéristiques énoncées au
niveau précédent, les concepts du niveau opérationnel ou
computationnel sont caractérisés par les opérations qu'il
est possible de leur appliquer pour générer des inférences
(engagement computationnel).deux concepts opérationnels sont identiques
s'ils possèdent le même potentiel d'inférence.
[Chet&Rou]
VI.4. Typologie selon le niveau de
formalisme
Par rapport au niveau du formalisme de représentation
du langage utilisé pour représenter les ontologies, on distingue
des ontologies:
· Informelles : dans un langage naturel
(sémantique ouverte).
· Semi informelles :
dans un langage naturel structuré et limité.
· Semi formelles : dans
un langage artificiel défini formellement.
· Formelles : dans un langage artificiel
contenant une sémantique formelle. [Chet&Rou]
.11.VII. Langage de spécification d'ontologie
Plusieurs langages de spécification d'ontologies (ou
langage d'ontologies) ont été développés
pendant les dernières années.
VII.1. RDF
Resource Description Framework (RDF) est au centre de la
plupart des travaux du Web Sémantique, et pour cause : il s'agit de la
"glue" permettant de relier les ressources (pages, images...) entre elles.
C'est un vocabulaire XML pour décrire des ressources, ou des relations
entres ressources, en leur affectant des métadonnées. Les
machines peuvent dès lors classer ces ressources et modéliser
les liens entre elles (s'ils existent). RDF permet ainsi de définir les
règles qui relient les informations entre elles.
Parce qu'ils définissent une information sous forme de
triplet (sujet - prédicat - objet), les documents RDF doivent
être interprétés pour être "compris" par la
machine.
RDF n'est pas à proprement parler un langage XML. RDF
est simplement une structure de donnée constituée de noeuds. Sa
sérialisation XML n'est que l'une de ces représentations
possibles. Nous utiliserons ici "RDF/XML" pour parler de la vision du RDF
proposée par le W3C, et "RDF" pour parler simplement de la relation
entre données par triplets.
Pour résumer : RDF est un modèle de
données basé sur des triplets et indépendant de toute
syntaxe particulière, RDF/XML est la syntaxe créée par le
W3C pour utiliser RDF au sein du Web Sémantique.
VII.2. RDFS
RDF Schéma est un vocabulaire permettant de
décrire des vocabulaires. C'est un des piliers du Web
sémantique puisqu'il permet de bâtir des concepts, définis
par rapport à d'autres concepts, ayant la particularité
d'être partagés à travers le Web.
Par extension, un schéma RDF désigne un
vocabulaire définit avec la norme RDF Schéma, on parle aussi de
"vocabulaire RDF".
Par exemple, FOAF (http://websemantique.orf/FOAF)
possède un schéma RDF. RDF Schéma permet de décrire
des vocabulaires simples ; pour des vocabulaires plus expressifs, on se
tournera vers OWL qui enrichit le modèle RDF Schéma.
Comment RDF Schéma permet-il de définir un
vocabulaire ?
RDF Schéma est doté du nombre minimum de
constructeurs nécessaires à la définition d'un
vocabulaire.
· Il définit la notion de "classe" qui est un
ensemble de plusieurs objets.
· Il définit la propriété
particulière "est une sous-classe de" qui permet de définir
qu'une classe est un sous-ensemble d'une autre classe.
· Il définit la classe des "ressource" qui est
la classe mère de toutes choses : tout est une ressource dans le Web
sémantique, sauf la notion de "littéral"
· toute classe est une sous-classe de la classe des
ressources
· Il définit la notion de "littéral"
qui est une valeur comme une chaîne de caractère ou des chiffres :
ces choses ne sont pas des concepts et ne peuvent être manipulés
comme tels.
· Il définit la propriété
"s'applique à la classe" (range) permettant ainsi de spécifier le
champ d'application d'une propriété.
· Il définit la propriété "est
l'objet de la propriété" (domain) permettant ainsi de
spécifier quelles sont les classes auxquelles ont peut affecter telle ou
telle propriété.
VII.3. OWL
De nombreux langages informatiques sont apparus pour
construire et manipuler des ontologies. Dans le but de mettre au point un
langage standardisé, leW3C a crée le groupe Web Ont qui a mis en
place le langage OWL.
OWL Le Web Ontology Language (OWL) est un vocabulaire XML
basé sur
RDF, et permet de spécifier ce qui peut être
compris : il fournit un langage pour définir des ontologies Web
structurées. [Huy2003]
OWL définit donc une syntaxe RDF pour décrire et
construire des vocabulaires pour créer des ontologies. Cependant, le
langage OWL offre trois sous langages d'expression croissante conçus
pour des communautés de développeurs et d'utilisateurs
spécifiques qui sont :
· OWL Lite : Est le sous langage de
OWL le plus simple, il est destiné à représenter des
hiérarchies de concepts simples.
· OWL DL : Est plus complexe que le
précédent, il est fondé sur la logique descriptive d'ou
son nom (OWL Description Logics) .Il est adapté pour faire des
raisonnements, et il garantit la complétude des raisonnements et leurs
décidabilité.
· OWL Full : Est la version la plus
complexe du OWL, destiné aux situations ou il est important d'avoir un
haut niveau de capacité de description, quitte à ne pas pouvoir
garantir la complétude et la décidabilité des calculs
liés à l'ontologie. [Chet&Rou] [Mbao2007]
VIII. Structure d'une ontologie OWL
· Espace de nommage
L'espace de nom, parfois appelé espace de nommage
permet d'indiquer avec précision de quels vocabulaires les termes d'une
ontologie proviennent. C'est la raison pour laquelle, comme tout autre
document XML, une ontologie commence par une déclaration d'espace de
noms contenue dans une balise rdf:RDF.
Exemple : Voici la déclaration
d'espace de nom qui pourrait être employée pour écrire une
ontologie sur l'humanité:
<rdf:RDF
xmlns = "
http://domain.tld/path/humanite#"
xmlns:humanite= "
http://domain.tld/path/humanite#"
xmlns:base = "
http://domain.tld/path/humanite#"
xmlns:vivant = "
http://otherdomain.tld/otherpath/vivant#"
xmlns:owl = "
http://www.w3.org/2002/07/owl#"
xmlns:rdf = "
http://www.w3.org/1
999/02/22-rdf-syntax-ns#"
xmlns:rdfs = "
http://www.w3.org/2000/01/rdf-schema#"
xmlns:xsd = "
http://www.w3.org/2001/XMLSchema#">
Les deux premières déclarations identifient
l'espace de nommage propre à l'ontologie à élaborer. La
première déclaration d'espace de nom indique à quelle
ontologie se rapporter en cas d'utilisation de noms sans préfixe dans la
suite de l'ontologie. La troisième déclaration identifie l'URI de
base de l'ontologie courante.
La quatrième déclaration signifie simplement
que, au cours de la rédaction de l'ontologie humanité, on va
employer des concepts développés dans une ontologie vivant, qui
décrit ce qu'est un être vivant.
Les quatre dernières déclarations introduisent
le vocabulaire d'OWL et les objets définis dans l'espace de nommage de
RDF, du schéma RDF et des types de données du Schéma
XML.
· En-tête d'une ontologie
A la suite de la déclaration d'espaces de nom,
l'entête décrit le contenu de l'ontologie courante. La balise
owl:Ontology permet d'indiquer les informations contenues dans l'ontologie.
· Eléments de base
Il existe divers éléments de base pour le
langage OWL, cette partie ne va pas reprendre toutes les finesses d'OWL Lite,
OWL DL et OWL Full, mais uniquement les plus importantes.
Les classes : Une classe ou concept est définie
comme un groupe d'individus qui ont des caractéristiques similaires dans
un domaine.
Propriétés : Dans un langage OWL, une
propriété permet de définir des faits ou des relations
entre des classes. Il existe en OWL deux types de
propriétés : propriété d'objet
(owl :ObjectProperty) qui définissent une propriété
entre deux individus d'une classe ou de plusieurs classes et les
propriétés de type données (DataTypeProperty) qui relient
des instances à des valeurs de données.
Instance de classe : L'ensemble des individus d'une
classe est désigné par le terme extension de classe, chacun de
ces individus étant alors une instance de la classe. Les instances sont
utilisées pour représenter les éléments
spécifiques. [Mbao2007]
IX. Méthodologies de construction
IX.1. Méthode de Uschold et King «1995
»
Ils ont proposé la première méthode
d'ingénierie "générale", résultat de leurs travaux
de construction d'ontologies dans le domaine de la gestion des entreprises.
Initialement, cette méthode reposait sur quatre étapes :
- Identifier le but et la portée de l'ontologie.
- Construire l'ontologie : capturer les connaissances, coder,
réutiliser et intégrer des ontologies existantes.
- Évaluer l'ontologie.
- Documenter l'ontologie.
IX.2. Méthode de Uschold et King «1996
»
Distinguent trois possibilités pour identifier les
concepts qui seront présents dans l'ontologie :
- On part des concepts les plus génériques que
l'on déclinera en concepts de plus en plus spécifiques. Il s'agit
d'une approche de haut en bas (ou TOP DOWN).
- On part au contraire, de concepts spécifiques que
l'on organise avec des concepts plus génériques. C'est une
approche de bas en haut (ou BOTTOM UP).
- Identifier les concepts les plus importants (pas
forcément spécifiques ou génériques) et partir de
ceux-ci pour trouver les concepts plus génériques et plus
spécifiques dont on aura besoin. Cette approche part du milieu vers
les extrémités (ou MIDDLE
OUT).
Dans la pratique, il n'y a pas d'approche purement « TOP
DOWN » ou « BOTTOM UP » surtout lorsqu'une
ontologie déjà existante est réutilisée.
IX.3. Méthode de Bernaras et al «1996
»
Elle est conditionnée au développement d'une
application. Elle repose sur trois points :
- Spécifier l'application basée sur l'ontologie
en particulier les termes à collecter et les tâches à
effectuer en utilisant cette ontologie.
- Organiser les termes en utilisant les métas
catégories : concepts, relations, attributs, etc.
- Affiner l'ontologie et la structurer selon des principes de
modularisation et d'organisation hiérarchiques.
IX.4. Méthode SENSUS de Swartout et al «1997
»
Commence par la réutilisation d'une vaste ontologie
commune dans laquelle les concepts pertinents sont repérés afin
d'extraire le squelette initial de la future ontologie. L'ontologie initiale se
comporte comme une charnière entre les différentes ontologies
développées.
IX.5. Méthode de Assenac-Grilles et al «
2000 »
La méthodologie de construction d'une ontologie
à partir de texte proposée par Assenac-Gilles insiste sur
l'étape de conceptualisation.
IX.6. Méthode de Bachimont « 2000
»
Propose de déterminer le sens d'un concept (noeud) dans
l'arbre ontologique (taxonomie). Cette
méthode s'articule sur quatre principes :
- Le principe de communauté avec le père.
- Le principe de différence avec le père.
- Le principe de différence avec les frères.
- Le principe de communauté avec les frères.
IX.7. Méthode OntoSpec de Kassel « 2002
»
Développée par l'équipe IC de LARIA
d'Amiens repose sur la notion d'axe sémantique groupant les sous
concepts d'un concept selon les caractéristiques impliquées dans
la définition de leur différentiation.
Malgré le nombre important de méthodes et de
démarches proposées, à l'heure actuelle on en compte une
trentaine, aucune n'a pu s'imposer. Ces méthodologies peuvent porter sur
l'ensemble du processus et guider l'ontologiste sur toutes les étapes de
la construction d'ontologies. [Chet&Rou]
.11.X. Conclusion
Les ontologies visent à capturer la connaissance de
domaine d'une manière générique et fournissent une
compréhension généralement convenue à travers un
domaine. Elles peuvent être réutilisées et
partagées entre les applications et les groupes.
Les ontologies fournissent un vocabulaire commun d'un secteur
et définissent avec différents niveaux de formalité la
signification des termes et les relations entre eux.
I. Introduction
Ce chapitre sera consacré à la
présentation de l'ontologie qu'on a conçue dans le cadre de ce
projet, qui va nous aidez à créer une base de ressource
pédagogique selon des métadonnées. Elle
offre une perspective d'ajout, de recherche et d'affichage du contenu. La base
de ressources pédagogiques va nous permettre d'avoir un ensemble de
ressources indexer qui vont facilités l'apprentissage selon les besoins
de l'apprenant.
Notre travail va se dérouler comme suite :
· 1- Concevoir une ontologie d'application qui décrit
les ressources pédagogiques utilisés pour l'enseignement
d'algorithmique.
· 2- Créer une base de ressources pédagogiques
on se basant sur les métadonnées pour effectuer l'ajout et la
recherche des ressources pédagogiques dans la base.
II. Conception de l'ontologie de l'application
II.1. Choix d'une méthodologie de
construction
Pour construire l'ontologie d'application, la méthode
développée par [Bernaras et al, 1996] a
été utilisée, elle repose sur trois étapes :
· Spécifier l'application basée sur
l'ontologie en particulier les termes à collecter et les tâches
à effectuer en utilisant cette ontologie.
· Organiser les termes en utilisant les métas
catégories : concepts, relations, attributs, etc.
· Affiner l'ontologie et la structurer selon des
principes de modularisation et d'organisation hiérarchiques.
Ce choix peut être justifié par deux raisons :
· Cette méthode est conditionnée au
développement d'une application, en d'autres termes elle est
adaptée à la construction des ontologies d'application
plutôt que des ontologies de domaines.
· Elle s'articule autour d'un ensemble de termes qui doit
être transformé en une ontologie. Dans le cas de notre projet, on
disposait au début d'un ensemble de termes qui sont couramment
utilisés dans le milieu d'enseignement d'algorithmique.
Etape1 : préciser l'application basée sur
l'ontologie
L'ontologie sera construite dans l'esprit de fournir un
vocabulaire conceptuel, qui permet l'indexation sémantique (annotation)
des ressources pédagogiques et par conséquence la gestion de ces
déniées.
Etape 2 et 3 : de la collecte des termes à
l'affinement de l'ontologie
On ne peut pratiquement dissocier les étapes de
construction d'une ontologie, car il s'agit d'un processus non linéaire,
plusieurs allers-retours ont été fait lors du
développement de l'ontologie de ce projet, pour les raisons suivantes
:
· Il n'était pas possible de savoir dés le
départ, que les termes collectés sont suffisants pour
répondre à l'objectif pour lequel l'ontologie a été
construite, on a ajouté des nouveaux termes lorsque c'était
nécessaire, tout de même on a retiré des termes qu'on a
jugés inutiles.
· Il n'était pas toujours facile de prédire
qu'un terme va jouer le rôle d'une classe ou celui d'un attribut,
plusieurs modifications ont été effectuées dans ce
sens.
Pour représenter l'ontologie conceptuelle
réalisée, on a construit :
· Une liste de concepts.
· Une liste d'attributs.
· Une liste de relations.
· Une représentation hiérarchique des
concepts.
II.2. Respect des principes de construction
· Clarté et objectivité [Gruber93]
: pour répondre à ce principe, tous les termes
utilisés dans cette ontologie ont été associés par
des définitions.
· Complétude [Gruber93] : pour
répondre à ce principe les définitions des concepts et des
relations de notre ontologie ont été associés par des
conditions nécessaires.
· Extensibilité ontologique maximale
[Gruber93] : la définition d'un terme n'explique que le terme
lui-même, sa définition ne peut être la même que celle
d'un terme plus général, ou d'un terme plus
spécialisé.
II.3. Présentation de l'ontologie
II.3.1. Liste des concepts
Dans le tableau qui suit on va présenter les concepts
de l'ontologie ainsi que leurs définitions et leurs sur concepts :
|
concept
|
Sur concept
|
Définition du concept
|
|
Structure
|
Cours algorithmique
|
Structure est-un notion d'un cours algorithmique.
|
|
Type
|
Structure
|
Type est-un Structure. Un type détermine
la classe des valeurs possibles pour une donnée.
|
|
Genre
|
Structure
|
Genre est-un Structure. Le genre d'une structure peut être
séquentiel ou arborescence.
|
|
Graphe
|
Structure
|
Graphe est-un Structure. Un graphe est un ensemble d'objets
appelé sommet et de relation entre ses sommets.
|
|
Type simple
|
Type
|
Type simple est-un Type. Une donnée de type simple ne peut
contenir à un instant donné qu'une seule valeur.
|
|
Type structuré
|
Type
|
Type structuré est-un Type. On définit un type
structuré par le produit cartésien des types non
structurés ou structurés. Une variable de type structuré
peut contenir à un instant donné plusieurs valeurs.
|
|
Réel
|
Type simple
|
Réel est-un Type simple. Valeurs possibles pour une
donnée de type réel : numérique avec partie entière
et partie décimale.
|
|
Entier
|
Type simple
|
Entier est-un Type simple. Valeurs possibles pour une
donnée de type entier : numérique sans partie décimale.
|
|
Booléen
|
Type simple
|
Booléen est-un Type simple. Valeurs possibles pour une
donnée de type booléen : vrai/faux.
|
|
Caractère
|
Type simple
|
Caractère est-un Type simple. Valeurs possibles pour une
donnée de type caractère : élément de la table
ASCII
|
|
Chaîne
|
Type simple
|
Chaîne est-un Type simple. Valeurs possibles pour une
donnée de type chaîne : suite de caractères quelconques
encadrée par un caractère donnée.
|
|
Pointeur
|
Type simple
|
Pointeur est-un Type simple. Un pointeur est une variable
contenant une adresse mémoire
|
|
Regroupant des données du même
type
|
Type structuré
|
Type structuré regroupant des données de même
type est-un Type structuré. Toutes ces données sont du même
type.
|
|
Regroupant des données de différent type ou non
|
Type structuré
|
Type structuré regroupant des données de
différent type ou non est-un Type structuré. Toutes ces
données sont du même type ou de différant type.
|
|
Tableau
|
Regroupant des données de même type
|
Tableau est-un Type structuré regroupant des
données de même type Se distingue d'Enregistrement. Un tableau est
une collection ordonnée de variables ayant toutes le même type. On
accède à chacune de ces variables individuellement à
l'aide d'un indice ou iems indices.
|
|
Ensemble
|
Regroupant des données de même type
|
Ensemble est-un Type structuré regroupant des
données de même type.
|
|
Fichier
|
Regroupant des données de même type
|
Fichier est-un Type structuré regroupant des
données de même type. Un fichier est une collection d'informations
stockée sur un support physique : disque ; bande ; CD-ROM ; etc.
|
|
Enregistrement
|
Regroupant des données de différant type ou non
|
Enregistrement est-un Type structuré regroupant des
données de types différents ou non se distingue de Tableau. Un
enregistrement est une variable structurée avec plusieurs 'champs'. Les
champs sont des attributs ou caractéristiques de l'enregistrement.
|
|
Séquentiel
|
Genre
|
Séquentiel est- un Genre. Une structure genre
séquentiel est organisée de manière séquentiel.
|
|
Arborescence
|
Genre
|
Arborescence est-un Genre. Une arborescence est un ensemble de
noeud organisé d'une façon hiérarchique.
|
|
Liste
|
Séquentiel
|
Liste est-un Séquentiel. Une liste est une suite finie
d'éléments selon leur rang dans la liste.
|
|
Pile
|
Séquentiel
|
Pile est-un Séquentiel. L'ajout et le retrait dans une
pile se fait au sommet.
|
|
File
|
Séquentiel
|
File est-un Séquentiel. L'ajout à la fin et le
retrait au début.
|
|
Arbre binaire
|
Arborescence
|
Arbre binaire est-une Arborescence. Un arbre binaire a le nombre
de fils de chaque noeud limité à deux.
|
|
Arbre planaire
|
Arborescence
|
Arbre planaire est-une Arborescence. Le nombre de fils de chaque
noeud n'est pas limité.
|
|
Représenter par matrice
|
Graphe
|
Représenter par matrice est-un Graphe. Le graphe est alors
représenté par une matrice dite matrice d'adjacence.
|
|
Représenter par liste
|
Graphe
|
Représenter par liste est-un Graphe.
|
II.3.2. Liste des attributs
Dans le tableau qui suit on va présenter les attributs,
et s'il a des attributs hérités d'un concept père.
|
Concept
|
Hérite les attributs de concept
|
Attributs
|
Commentaires
|
|
Cours algorithmique
|
|
Nom
|
Le nom du répertoire
|
|
Nombre
|
Le nombre de répertoire
|
|
L'adresse
|
L'adresse ou est enregistré le répertoire
|
|
Structure
|
Cours algorithmique
|
|
|
|
Type
|
Cours algorithmique
|
|
|
|
Genre
|
Cours algorithmique
|
|
|
|
Graphe
|
Cours algorithmique
|
|
|
|
Type simple
|
Cours algorithmique
|
|
|
|
Type structuré
|
Cours algorithmique
|
|
|
|
Réel
|
Cours algorithmique
|
|
|
|
Entier
|
Cours algorithmique
|
|
|
|
Booléen
|
Cours algorithmique
|
|
|
|
Caractère
|
Cours algorithmique
|
|
|
|
Chaîne
|
Cours algorithmique
|
|
|
|
Pointeur
|
Cours algorithmique
|
|
|
|
Regroupant des données du même
type
|
Cours algorithmique
|
|
|
|
Regroupant des données de différent type ou non
|
Cours algorithmique
|
|
|
|
Tableau
|
Cours algorithmique
|
|
|
|
Ensemble
|
Cours algorithmique
|
|
|
|
Fichier
|
Cours algorithmique
|
|
|
|
Enregistrement
|
Cours algorithmique
|
|
|
|
Séquentiel
|
Cours algorithmique
|
|
|
|
Arborescence
|
Cours algorithmique
|
|
|
|
Liste
|
Cours algorithmique
|
|
|
|
Pile
|
Cours algorithmique
|
|
|
|
File
|
Cours algorithmique
|
|
|
|
Arbre binaire
|
Cours algorithmique
|
|
|
|
Arbre planaire
|
Cours algorithmique
|
|
|
|
Représenter par matrice
|
Cours algorithmique
|
|
|
|
Représenter par liste
|
Cours algorithmique
|
|
|
II.3.3. Liste des relations
Dans le tableau qui suit on va décrire les relations
qui existent entre les différents concepts de l'ontologie.
|
Relation
|
Prédécesseur
|
Successeur
|
Définition
|
|
A pour pré requis
|
Liste
|
Tableau
|
Liste a pour pré requis Tableau.
|
|
A pour pré requis
|
Liste
|
Pointeur
|
Liste a pour pré requis Pointeur.
|
|
A pour pré requis
|
Pile
|
Liste
|
Pile a pour pré requis Liste.
|
|
A pour pré requis
|
File
|
Liste
|
File a pour pré requis Liste.
|
|
A pour pré requis
|
Arbre binaire
|
Tableau
|
Arbre binaire a pour pré requis Tableau.
|
|
A pour pré requis
|
Arbre binaire
|
Pointeur
|
Arbre binaire a pour pré requis Pointeur.
|
|
A pour pré requis
|
Arbre planaire
|
Arbre binaire
|
Arbre planaire a pour pré requis Arbre binaire.
|
|
A pour pré requis
|
Type structuré
|
Type simple
|
Type structuré a pour pré requis Type simple.
|
|
A pour pré requis
|
Enregistrement
|
Type simple
|
Enregistrement a pour pré requis Type simple.
|
|
A pour pré requis
|
Représenter par matrice
|
Tableau
|
Représenter par matrice a pour pré requis
Tableau.
|
|
A pour pré requis
|
Représenter par liste
|
Pointeur
|
Représenter par liste a pour pré requis
Pointeur.
|
II.3.4. Représentation hiérarchique des
concepts
Algorithmique
Structure
Type
Type simple
Booléen
Réel
Entier
Caractère
Chaine
Pointeur
Type structuré
Type structuré regroupant des données de
même type
Tableau
Ensemble
Fichier
Type structuré regroupant des données de
différant type ou non
Enregistrement
Genre
Séquentiel
Liste
Pile
File
Arborescente
Arbre binaire
Arbre planaire
Graphe
Représenter par matrice
Représenter par liste
Fig7: Représentation hiérarchique de
l'ontologie
III. Création de la base de ressources
pédagogiques
Une base de ressources pédagogiques est un
entrepôt
de données regroupant des fiches descriptives de
métadonnées
d'
objets
d'apprentissage : elle permet d'interroger ces ressources
selon des critères spécifiques et d'y accéder. La base
fournit ainsi aux enseignants et aux
apprenants
de l'information qui est structurée et organisée.
III.1. Les métadonnées
Le terme de métadonnées est utilisé pour
définir l'ensemble des informations
techniques et descriptives ajoutées aux documents pour
mieux les qualifier.
Elles servent à décrire des objets
d'apprentissage, des ressources pédagogiques,
des unités d'enseignement, quelque soit leur
degré de granularité.
? Objectif
Les métadonnées ont pour objectifs de :
1. Permettre une description plus ou moins
détaillée des ressources.
2. Faciliter le repérage de l'information.
3. Permettre une évaluation rapide de la pertinence du
contenu d'un document.
4. Permettre la gestion des droits d'accès.
5. Faciliter l'organisation et la gestion de collections de
ressources.
? Choix des métadonnées
Il fallait définir un ensemble de
métadonnées pour décrire les concepts. LOM (Learning
Object Meta data) permet de décrire tout ce qui caractérise un
objet pédagogique. On a opté pour un sous ensemble de
métadonnée, qui sont :
? Niveau apprenant: Débutant, Moyen,
Bon
? Niveau de difficulté: Difficile,
Moyen, Facile
? Style d'apprentissage: Actif,
Réfléchi, Théoricien, Pragmatique
? Rôle pédagogique:
Définition, Remarque, Exemple, Exercice, Représentation
? Stratégie pédagogique:
Familiarisation, Clarification, Renforcement
? Durée d'apprentissage: Le temps
nécessaire pour assimilé le concept
? Type physique: Texte, image, son,
animation, vidéo
? Emplacement physique.
? Taille.
? Format.
? Auteur.
? Identifiant.
? Nature de traitement :
Itérative, Récursive.
? Nombre d'apprenant : Individuel,
groupe
? Traitement appliqué:
Rédaction, lecture, écoute
Ces métadonnées seront ajoutées dans la base
décrivant les ressources d'un concept puis stocker dans un emplacement
précis sous format XML car il est flexible et puissant pour
décrire les diverses composantes de la ressource pédagogique
voici un exemple d'une ressource :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<concept>
<nom_concept>pointeur</nom_concept>
<Niveau_Apprenant>Bon</Niveau_Apprenant>
<Style
d'apprentissage>Actif</Style d'apprentissage>
< Durée
d'apprentissage>2 heures </Durée
d'apprentissage>
<Niveau de
difficulté>Facile</Niveau de
difficulté>
<Stratégie
pédagogique>Familiarisation</Stratégie
pédagogique>
<Role
pédagogique >Définition</Role
pédagogique >
<Traitement
appliqué>Rédaction</Traitement
appliqué>
<Format>Word <Format>
<Taille>50Ko<Taille>
<Nombre
d'apprenant>individuel <Nombre d'apprenant>
<Type
physique>Texte</Type physique>
<Auteur>Kahoul</ Auteur>
<Nature traitement>Itérative</
Nature traitement >
<Identifiant>doc1</Identifiant>
<Emplacement
physique>C:\Pointeur.docx</Emplacement physique>
</concept>
Afin de maintenir une certaine cohérence dans la
description des ressources un vecteur de métadonnée est
sélectionné pour mettre l'accent sur l'aspect pédagogique
de la ressource. Ce vecteur est supporté par un ensemble de
règles préliminaire entre les différentes valeurs
associées aux métadonnées.
Par exemple il y a une règle
entre le type physique et l'emplacement physique.
« Si l'emplacement physique se termine par
« .doc » alors le type physique ne peut pas
être un son, une vidéo, une animation. »
On a limité la liste des règles entre:
· Le type physique et l'emplacement physique.
· Le type physique et le traitement appliqué.
· Style d'apprentissage et rôle pédagogique.
· Style d'apprentissage et stratégie
pédagogique.
IIV. Architecture de l'application développée
Notre système est doté d'une interface auteur,
via laquelle l'enseignant concepteur pourra mettre à jour la base de ces
ressources pédagogiques, relier à l'ontologie qui à
été conçu et intégré au système.

Auteur
Fig8 : Architecture du système
L'ajout : Se fait comme suite :
L'auteur va accéder à une interface ou il va
faire l'ajout d'une ressource pédagogique d'un concept, en remplissant
un formulaire qui contient plusieurs champs ou chaque champ représente
une métadonnée (exemple : comme le niveau de l'apprenant, le
temps, l'auteur, l'emplacement physique, le style d'apprentissage...etc). La
liste des concepts sera importer de l'ontologie, l'auteur va faire son choix et
puis il va remplir les champs. Les ressources seront codé sous forme XML
et ces seront stocker dans un même fichier.

Fig9 : L'ajout dans la base de ressources
pédagogiques
La recherche : Se fait comme
suite :
Pour la recherche l'auteur va formuler sa requête, selon
les valeurs de certaines métadonnées (choisie). Il y aura un
accès à la base de ressources pédagogiques puis un
filtrage des ressources qui va nous donner soit une réponse positif
(d'une ou plusieurs ressources candidates) soit négatif.

Fig10 : La recherche dans la base de ressources
pédagogiques
IIIV. Conclusion
Dans ce chapitre on a présenté les
différentes phases dans la conception de l'ontologie de ce projet,
où on a suivi la méthode développée par [Bernaras
et al, 1996]. L'ontologie conçue à été
détaillé ainsi que la création de la base de ressources
pédagogiques indexées.
L'architecture du système à été
présenté, certaine détailles d'implémentation
seront insérer dans ce qui suit du mémoire.
|
I. Introduction
Dans ce chapitre nous allons présenter le travail
d'implémentation qu'on a fait, qui consistait premièrement
à l'édition de notre ontologie sous le langage OWL, suivi par son
exploitation dans une application d'ajout et de recherche de documents
pédagogiques qui a été développée en
java.
II. Les outils et le langage utilisés
II.1. Protégé
Éditeur d'ontologie open source disponible à
l'adresse
http://protege.standford.edu
, développé au département d'Informatique
Médicale de l'Université de Standford.
L'éditeur d'ontologie « Protégé
version 3.2.1 », a été utilisé pour éditer
l'ontologie de ce projet dans l'objectif de générer
automatiquement le code OWL correspondant.
Il est à noter que « Protégé »
offre bien sure beaucoup de fonctionnalités, et on n'en a pas
certainement tous utilisés.
II.2. Jena
Jena est disponible à l'adresse :
http://jena.sourceforge.net/
Jena est un ensemble d'outils (une API) open source
développé par HP Labs semantic Web programme, permettant
de lire et de manipuler des ontologies décrites en RDFS ou en OWL et d'y
appliquer certains mécanismes d'inférences. Pour notre projet on
utilisé la version 2.5.7.
III. Implémentation
III.1. Edition de l'ontologie et
génération du code OWL
La première étape de l'implémentation
était bien l'édition de l'ontologie avec
«Protégé».
III.1.1. Choix d'un langage de
spécification
L'ontologie de ce projet a été codée
exactement en « OWL DL », car le codage d'une ontologie sous format
OWL présente l'avantage de rendre cette ontologie réutilisable,
grâce à l'utilisation des propriétés
d'équivalence, de disjonction entre les concepts et entre les
relations.
III.1.2. Les étapes de
l'édition
Dans ce qui suit nous allons présenter comment nous
avons édité l'ontologie de ce projet.
1) lancement de « Protégé 3.2.1» sous
Windows XP :
Fig11 : Lancement de Protégé
2) création d'un nouveau projet avec précision
respectivement de type de projet, d'espace des noms, de langage avec lequel
sera édité l'ontologie :
3) Après avoir spécifié les
propriétés on passe à l'édition de l'ontologie.
4) Commencer à éditer les classes, les
définitions de classes, les propriétés, les relations et
les relations inverses :
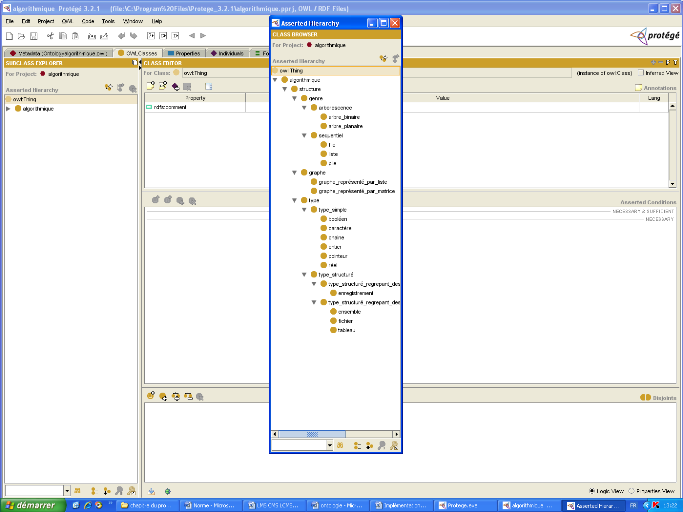
Fig12 : Les concepts et sous concepts
Fig13 : Propriétés et
relations
5) Après avoir terminé l'édition de
l'ontologie, on sauvegarde le projet.
III.2. Exploitation de code OWL dans un programme
JAVA
Après avoir générer le code OWL
correspondant à notre ontologie il a fallu l'exploiter dans un
programme JAVA, on s'est rendu compte qu'il existe une API appelée Jena
qui sert de lien entre un code OWL et un programme JAVA.
1) Installation de JDK 1.6.0.
2) Pour la configuration des JDKs et des Librairies avec
eclipse, il faut aller a Build Path et Add External Archives puis
sélectionné le lib de jena et l'ajouter.
VI. La démarche suivie pour l'ajout des
métadonnées
La démarche qu'on a suivi consistait à :
· Ajouter les métadonnées d'une ressource
décrivant un concept de l'ontologie d'application.
· Stocker les métadonnées de la ressource
dans un emplacement précis (dans notre cas le dossier nommé
« Mes Concepts »).
· Gérer l'accès aux documents grâce
à leurs ressources et aux métadonnées.
V. Exécution de l'application
V.1. Images d'exécution de
l'application
Dans ce qui suit nous allons présenter quelques
captures d'écran d'exécution de notre application.
V.1.1 L'ajout d'une ressource
L'ajout s'accompagne alors d'une étape de description
de la ressource (
indexation
manuelle) permettant au concepteur de caractériser sa
ressource selon des critères définis (saisie des champs des
métadonnées à l'aide d'un formulaire).
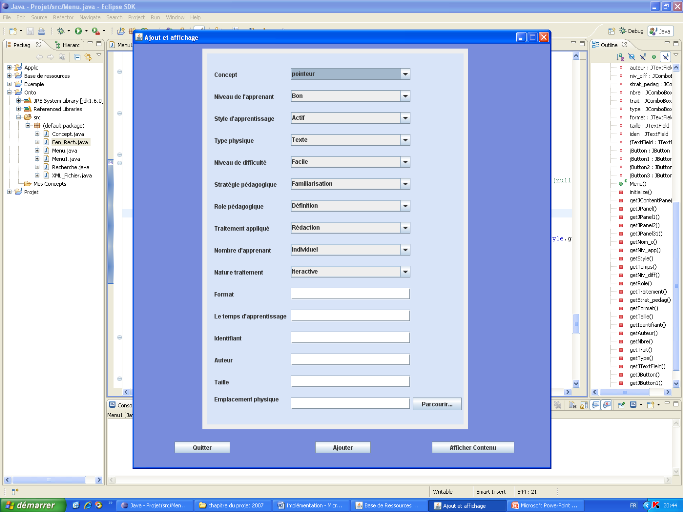
Fig14 : L'ajout d'une ressource
V.1.2. Recherche de documents
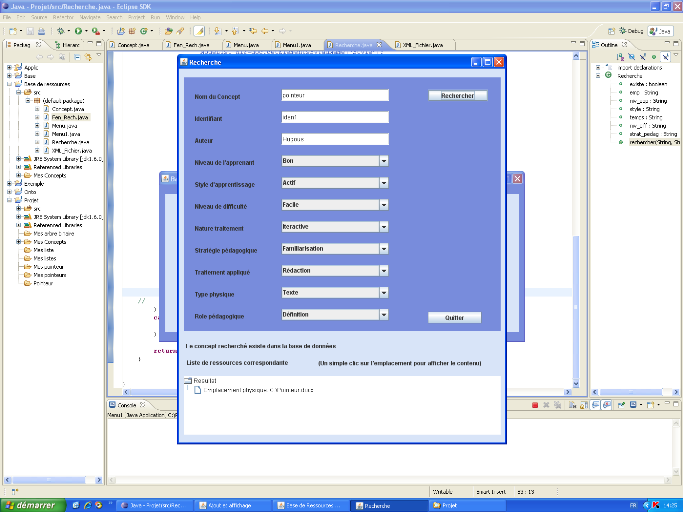
Fig15 : La recherche de documents
|
|
IV. Conclusion
Dans ce chapitre, nous avons présenté les
détails d'implémentation de l'application de ce projet ; On a
utilisé pour la réalisation de notre application :
· Système d'exploitation : Windows XP
· Outil de développement :
Protégé-3.2.1, eclipse-SDK-3.3.1
· Machine virtuelle JAVA
· Les bibliothèques : Jena version 2.5.7
L'application développée permet l'ajout,
l'affichage et la recherche des ressources à partir de leurs
descriptions (métadonnées) basées sur une ontologie.
Conclusion générale
Nous avons abordez dans notre projet une application qui
permet la création d'une base de ressources pédagogiques pour
l'apprentissage de l'algorithmique qui va nous permettre d'avoir un ensemble de
ressources indexer qui vont facilités l'apprentissage selon les besoins
de l'apprenant et ainsi fournir de l'information qui est structurée et
organisée de façon à faciliter les découvertes et
l'utilisation des documents elle permet d'interroger ces ressources et d'y
accéder.
Pour cela nous avons abordé dans ce travail quelques
concepts théoriques sur les normes et les standards, les plats formes et
les ontologies qui nous on aidé a mieux cerné les besoin de
l'apprentissage pour pouvoir choisir les métadonnées qui vont
répondre aux nécessités de l'apprentissage .
Bibliographie
[http1] :
http://www.wiki.univ-paris5.fr/wiki/Norme
[http2] :
http://www.fffod.org/fr/doc/R6/NormesStandards.rtf
[http3] :
http://www.wiki.univ-paris5.fr/wiki/LOM
[http4] : http://www_scormsoft_com-scorm-rte-api1.htm
[http5] : http://www.fr.wikipedia.org/wiki/SCORM
[http6] : http://www.wiki.univ-paris5.fr/wiki/SCORM
[http7] :
http://www.scorm.fr/?p=44
[http8] :
http://www_elearningpost_com-articles-archives-lcms_lms_cms_rlos-.htm
[http9] :
https://knol.google.com/k/jibril-touzi/les-lmslcms-et-leurs-rles-dans-le/
17euix69lwm49/3
[http10]
http://www.novantura.com/wiki/wakka.php?wiki=CMS#cms
[http11]
http://www.fr.wikipedia.org/wiki/Ontologie_(informatique)
[Sémé2006] : Alain Séméteys
« Formation à distance La norme
SCORM2004 »
http://www.educaweb.org/elearning/doc/scorm2004_avril2006.pdf
[Chet&Rou] Saloua & Amina Chettibi &
Rouibah
« Conception d'une ontologie pour une plate
forme d'enseignement à distance »
http://www.memoireonline.com/05/08/1145/m_conception-ontologie-plate-forme-enseignement-a-distance0.html
[Mbao2007] : Makhtar MBAO
« Distance sémantique et carte conceptuelle
»par Makhtar MBAO Aout 2007
http://www.lirmm.fr/~ducour/M2R/2006/Memoires/Rapport_M2R_07_Mbao.pdf
[Huy2003] HU?NH H?U HUNG
« Développement un outil efficace pour annoter
des documents Mars 2003 »
http://www.gdst.uqam.ca/Documents/Rapports/RapportHung.pdf
| 

