4.2.3 TREC-Eval
Le but initial de TREC-Eval est la comparaison entre
différents moteurs de recherche. TREC-Eval peut comparer une liste de
documents retournés par un moteur de recherche à une liste de
documents théorique parfaite. Pour cela, on demande à des
utilisateurs de formuler des requêtes. Les documents indexés sont
ensuite classés par ordre de pertinence, manuellement par les
utilisateurs. En rejouant les requêtes, les résultats
retournés par les moteurs de recherche en évaluation sont ensuite
comparés à la liste « idéale » proposée
par les utilisateurs. Pour chaque couple {requête, document}, une note de
pertinence est donnée. Ces notes sont stockées dans un fichier
QREL « Query Relevance Judgments » . Chaque année une campagne
de cinquante requêtes est rajoutée. La campagne s'effectue sur 300
000 articles. TREC-Eval est disponible en téléchargement sur le
site : http://trec.nist.gov/
Mais, cinquante requêtes incluant juste quelques mots
sur des sujets très différents sont insuffisantes pour
créer des graphes suffisamment connectés et avec des
pondérations signifiantes comme cela serait nécessaire pour
créer des agrégats. Afin d'avoir plus de matière nous
avons utilisé cinq campagnes de TREC-Eval et nous avons rajouté
en tant que requête la description de la requête elle-même.
Cette description est un texte court de quelques mots. La base disponible est
donc au total cinq cents requêtes (250 requêtes correspondant au
requêtes Trec-val et 250 requêtes correspondant à la
description) et 150 000 articles.
4.3 : Les méthodes de validation sémantique 128
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
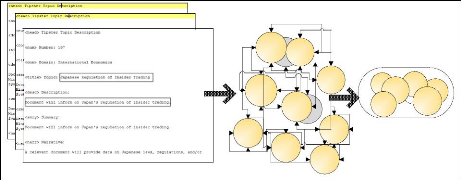
Fichier Topic Graphe
document
japanese
regulation
trading
insider
of
insider
trading
japan
insi of
panes
trading
Agré
japan
Agrégat
document
Figure 4.2 : Processus de création du
réseau à partir des fichiers «Topics» de
TREC-Eval.
Les requêtes et leur description sont stockées
dans des fichiers « Topics » correspondant à chacune des
campagnes annuelles. En excluant les requêtes d'un seul mot, il reste 199
requêtes et 250 descriptions pour un total de 944 mots-clés.
L'ensemble du réseau est utilisé, aucun filtre n'est
appliqué.
| 

