Agrégats de mots sémantiquement cohérents issus d'un grand graphe de terrain( Télécharger le fichier original )par Christian Belbèze Université Toulouse 1 Capitole - Doctorat en informatique 2012 |

4.3 Les méthodes de validation sémantiqueAfin, d'obtenir une estimation de la cohérence sémantique des agrégats, nous avons mis au point trois méthodes. La première méthode effectue une validation par comparaison des comportements de populations de requêtes identifiées (aléatoires, écrites par un utilisateur, etc.). Différents comportements statistiques sont étudiés en fonction du nombre de sites retournés par un moteur de recherche. Nommée MCCVS pour Méthode Comparative de Coefficient de Validation Sémantique (cette méthode est de notre invention). La deuxième méthode est une mesure de la capacité à améliorer la qualité des résultats retournés par un moteur de recherche en enrichissant la requête des mots d'agrégats associés aux mots de la recherche de base. Nous utilisons pour cela l'outil TREC-Eval. La troisième méthode est très proche de MCCVS dans sa construction. Simplement, au lieu de comparer le nombre de sites retournés nous comparons la distance entre les documents proposés par le moteur de recherche. 4.3.1 Méthode MCCVS ou « Méthode Comparative de Coefficient de Validation Sémantique »MCCVS permet la mesure de la qualité sémantique par comparaison du nombre de sites retournés par un moteur de recherche en utilisant comme requête des populations (par population nous entendons un ensemble noeuds partageant une caractéristique) de mots 4.3 : Les méthodes de validation sémantique 129 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure identifiées [Belbeze&al-2009-3]. Elle a l'avantage de donner un coefficient qui est l'équivalent d'une note. Nous considérons que si des mots sont associés dans une page web ou une requête par la volonté d'un auteur, ils sont associés « sémantiquement ». Les postulats à la proposition d'une technique de validation sémantique par comparaison de populations de mots identifiées sont les suivants : ? Internet est majoritairement constitué de sites web et de documents sémantiquement cohérents. Nous convenons qu'il existe des exceptions telles que des dictionnaires ou des listes d'objets en vente mais les considérons comme numériquement faible et donc peu représentative. De plus, la nature comparative de la méthode permet de baisser l'influence de tels éléments. ? Les utilisateurs de moteurs de recherche sur Internet ont une conscience et une expérience suffisante pour utiliser des mots-clés ayant un lien entre eux et avec le sujet recherché. Sur des ensembles de mots et de recherches suffisamment importants pour effectuer un traitement statistique, il devrait être possible d'observer un comportement différent, lorsque l'on compare le nombre de sites retournés par des requêtes utilisateurs à celui retourné par des requêtes combinant des mots de manière aléatoire. Afin d'éclairer notre propos, nous soumettons en tant qu'utilisateur, trois recherches de trois mots-clés au moteur de recherche Google.com et une recherche combinant un mot-clé de chacune de ces recherches utilisateurs (cette dernière étant notre recherche aléatoire). Comme on peut le constater dans les exemples illustrés dans le tableau 4.5 trois mots-clés pris aléatoirement dans un ensemble de requêtes donnent des résultats significativement inférieurs en nombre de sites retournés à des requêtes plus « sémantiquement cohérentes » proposées par un utilisateur. Ceci n'a bien sûr de valeur que d'un point de vue statistique ; rien n'interdisant à un monsieur « Besancenot » de placer une photo de lui-même sur Internet jouant du « B3 », modèle célèbre d'orgue de la fameuse marque Hammond, devant un plat d'épinards et de décrire celle-ci, sans que cela modifie nos observations.
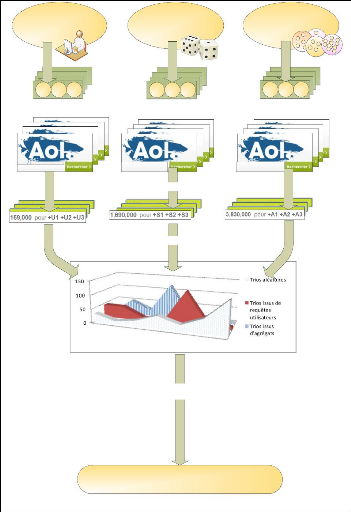
Tableau 4.5. Nombre de sites retournés par le moteur de recherche du site Google.com en fonction de la cohérence sémantique de la requête (Novembre 2010). 4.3 : Les méthodes de validation sémantique 130 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Recherche du coefficient « CVSC » ou Coefficient de Validation Sémantique Comparé. Notre but n'est pas de fournir une méthode de validation sémantique absolue, mais d'obtenir un indice de qualité sémantique. Cet indice est défini comme un ratio et n'a donc pas d'unité. Il permet d'évaluer des méthodes de regroupements et leurs évolutions (modifications apportées). Afin de créer cette mesure, nous proposons de comparer le nombre de sites retournés par le moteur de recherche du site AOL.com à partir de requêtes basées sur des combinaisons extraites des agrégats eux-mêmes avec le nombre de sites retrouvés (par le même moteur de recherche) à partir de requêtes basées sur des combinaisons aléatoires de mots-clés (combinaisons indépendantes des agrégats construits). Trois mots-clés représentent la taille minimale d'un agrégat (triade). Il est donc impossible de construire des recherches utilisant plus de trois mots-clés sans exclure de cette mesure les agrégats les plus petits. La validation des mots-clés par paires pourrait sans doute présenter un intérêt mais représenterait un nombre de combinaisons trop important. Nous avons donc choisi de présenter les mots-clés au moteur de recherche d' AOL.com par trio. Toutes les combinaisons de trois mots-clés de chaque agrégat seront soumises au moteur de recherche ainsi qu'un nombre équivalent de groupes de trois mots associés aléatoirement et enfin des groupes de trois mots issus de requêtes utilisateurs. Le moteur de recherche interrogé est soit AOL.com soit Bing.com selon les expérimentations. Nous n'avons pas pu conserver le même moteur de recherche sur la totalité d'entre-elles, AOL.com ayant mis en place un système de détection de robots en janvier 2009. Le moteur de recherche utilisé est précisé dans les conditions de mesure de chaque expérimentation. Nous comparons alors la distribution du nombre de sites retournés par chacun des groupes de trois mots, afin de comprendre si les trios de mots issus des agrégats sont plus proches du comportement des trios aléatoires ou des trios de mots issus des requêtes utilisateurs. 4.3 : Les méthodes de validation sémantique 131 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
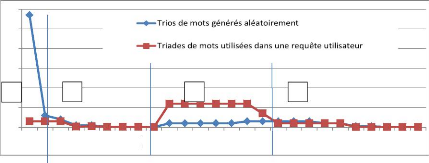
Requêtes utilisateurs +U1 +U2 +U3 Triades de mots issus de requêtes utilisateurs U1 U2 U3 Trios de mots utilisés comme requêtes dans un moteur de recherche Récupération du nombre de sites trouvés pour chaque requête Comparaison des distributions du nombre de sites retournés Création d'un indice de qualité sémantique comparée CVSC Trios de mots issus d'un tirage aléatoire +S1 +S2 +S3 Mots combinés aléatoirement S1 S2 S3 Trios de mots issus chacun d'un même agrégat +A1 +A2 +A3 Mots issus des agrégats A1A2A3 Figure 4.3 : Principe de création de l'indice sémantique. 4.3 : Les méthodes de validation sémantique 132 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Recherche d'un élément de comparaison Une représentation graphique du nombre de sites retournés en fonction d'une population se heurte à quelques difficultés. L'étendue des valeurs de retour et le nombre de valeurs différentes retournées sont trop considérables pour en proposer une vision graphique. Dans notre cas, nous allons de « 0 » site retourné à plus de 99 millions de sites pour certaines requêtes. Pour pallier ces difficultés, nous représentons les résultats selon une échelle semi-logarithmique en utilisant un regroupement des valeurs dans des classes. Un repère semi-logarithmique est un repère dans lequel l'un des axes, ici celui des ordonnées (y), est gradué selon une échelle linéaire alors que l'autre axe, ici celui des abscisses (x), est gradué selon une échelle logarithmique. L'avantage d'une représentation semi-logarithmique est son aptitude à représenter des mesures qui s'étalent sur des valeurs extrêmement larges. Des représentations semi-logarithmiques en puissance de 2 ont déjà été utilisées par Zipf dans des études sur l'occurrence des mots à l'intérieur d'un texte [Zipf-1935]. Ainsi, dans la figure 4.4, l'axe des abscisses est gradué en puissance de 2. En effet, pour pouvoir comparer les résultats obtenus, nous avons regroupé le nombre de sites retournés dans des classes exprimées dans un espace logarithmique. Si les échelles logarithmiques sont habituellement en puissance de 10, afin de présenter une échelle plus détaillée, nous avons choisi des classes par puissance de 2. L'axe des ordonnées représente alors le pourcentage de combinaisons trouvées par classe par rapport à l'ensemble des classes. Recherche d'une zone identifiable comme zone de comportement différentiable Nous comparons maintenant les deux courbes de réponses des deux espaces les plus éloignés sémantiquement selon le postulat posé au paragraphe précédent. Nous comparons la courbe issue des mots combinés aléatoirement (excluant des triades de mots utilisés dans une recherche) avec la courbe de référence issue du test de triades pour laquelle il existe au moins une recherche incluant ces trois mots-clés. Les regroupements de trois mots combinés aléatoirement ou les regroupements de trois mots extraits d'un même agrégat sont nommés trios de mots. Contrairement aux regroupements de trois mots ayant été conjointement utilisés dans une même requête utilisateur que nous nommerons triades. Ces derniers sont d'un point de vue graphique un ensemble de trois noeuds reliés deux à deux, ce qui n'est pas le cas pour les mots combinés aléatoirement et peut ne pas l'être pour des mots issus d'agrégats. Notre but est de comparer les distributions en fonction du nombre de sites retournés d'éléments le plus sémantiquement éloignés. Nous choisissons donc en suivant les postulats posés en début du paragraphe 4.2.1, les requêtes posées par un utilisateur et celles générées aléatoirement. La figure 4.4 est un exemple du résultat obtenu en comparant ces deux types de requêtes. En ordonnée de la figure 4.4 les valeurs représentent le pourcentage de la classe donné en abscisse. Ainsi la classe « 0 » ou « aucun site retourné » représente 57% de 4.3 : Les méthodes de validation sémantique 133 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure l'ensemble des tests effectués avec des trios de mots générés aléatoirement. De la même manière la classe notée 2^8 (qui correspond à un nombre de sites entre 129 et 256) correspond à 12 % de l'ensemble des tests pour les « triades de mots utilisées dans une requête utilisateur au moins ».
60 50 40 30 B C D A 10 0 0 2^0 2^1 2^2 2^3 2^4 2^5 2^6 2^7 2^8 2^9 2^10 2^11 2^12 2^13 2^14 2^15 2^16 2^17 2^18 2^19 2^20 2^21 2^22 2^23 2^24 Figure 4.4. Comparaison des deux courbes susceptibles d'être les plus éloignées sémantiquement et détermination des zones à fortes divergences. Dans cet exemple nous pouvons noter quatre zones distinctes. Les zones « B » et « D » n'offrent pas beaucoup d'intérêt, les courbes ne présentant pas de différence notable. La zone « A » est limitée à une seule valeur et ne peut donc représenter une étendue suffisante pour mener notre étude. Nous devons repérer la zone qui exprime le plus la différence de comportement entre les deux types de requêtes. Cela nous permettra d'affiner notre analyse en nous concentrant sur un comportement véritablement différencié. Dans notre exemple de la figure 4.4, la zone « C » (cf. figure 4.5) est la zone la plus « différenciée ». Elle est, en outre, d'une plage suffisante pour nous permettre une comparaison nuancée. Dans cet exemple, la zone « C » nous sert de zone de validation sémantique. Afin d'élaborer une comparaison rapide et arithmétique, nous allons définir un coefficient approprié.
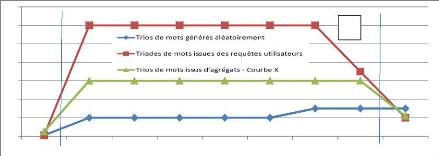
14 12 10 4 8 0 6 2 2^7 2^8 2^9 2^10 2^11 2^12 2^13 2^14 2^15 c Figure 4.5 : Courbe de distribution du nombre de sites retournés en fonction de la nature de la source du trio de mots constituant la requête dans la zone « C » et incluant une courbe X. 4.3 : Les méthodes de validation sémantique 134 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Calcul du CVSC (Coefficient de Validation Sémantique Comparée)
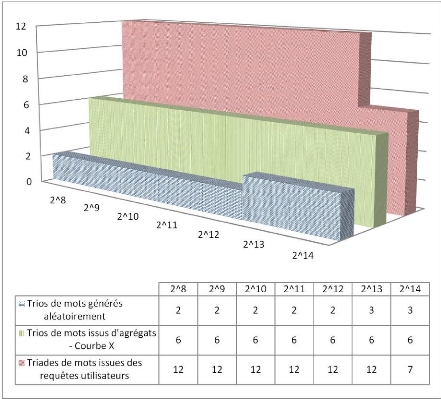
Figure 4.6 : Aires des distributions du nombre de sites retournés en fonction de la nature de la source du trio de mots constituant la requête dans la zone « C » et incluant une courbe X. Nous cherchons maintenant à calculer le coefficient de validation sémantique d'une courbe X qui provient des mesures effectuées à partir des trios de mots issus d'agrégats (cf. figure 4.5). Nous considérons que les classes en puissance de deux forment une échelle d'indice « un » et comparons l'aire prise par les histogrammes (cf. figure 4.6). Le CVSC, ou Coefficient de Validation Sémantique comparée, a alors la valeur « 1 » pour l'équivalence de l'histogramme des triades (de trois mots-clés) ayant été au moins une fois utilisées dans une même recherche et 0 pour la valeur de l'histogramme des triades aléatoires. La formule mathématique de CVSC sera donc définie pour une courbe particulière X comme suit : CVSCX = (AX - AA) / (AR - AA) Où AR définit l'aire de l'histogramme des triades dont tous les mots sont inclus au moins une fois tous ensemble dans une recherche. AR est défini comme suit : 4.3 : Les méthodes de validation sémantique 135 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure AR = Où AA définit la valeur de l'aire de l'histogramme des trios de mots combinés aléatoirement. AA est défini comme suit : AA = Où Ax définit la valeur de l'aire de l'histogramme des trios de mots à comparer. Ax est défini comme suit : AX = Dans notre exemple (cf. figure 4.5 et figure 4.6), les valeurs seraient les suivantes : AR = = 72 AA = = 42 AX = = 17 CVSCX = (AX - AA) / (AR - AA) = 0,441 |
|