Conclusion
La méthode d'évaluation MCCVS est basée
sur le postulat que statistiquement les documents présents dans Internet
et les recherches effectuées par les utilisateurs sont des
éléments possédant tous deux une cohérence
sémantique certaine. Le postulat inclut un autre point qui est que,
statistiquement, des requêtes constituées aléatoirement
présentent une cohérence sémantique plus faible que celles
écrites par un utilisateur.
Si tel est bien le cas, nous devrions voir émerger sur
un nombre important de requêtes une distribution du nombre de documents
trouvés différente entre des requêtes sémantiquement
cohérentes qui sont celles créées par des utilisateurs et
des requêtes créées aléatoirement.
Cette différence de comportement, si on accepte le
postulat, devient alors un élément nous permettant de valider la
méthode elle-même. En effet, si la différence de
comportement est suffisamment sensible, cela permet de valider que les
requêtes sont bien de nature
4.3 : Les méthodes de validation sémantique 136
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
différente. Cette nature est liée à la
source des requêtes : soit il s'agit d'un esprit humain animé par
une intention soit c'est un système d'association aléatoire.
En respectant des conditions de mesure identiques pour les
trois sources de requêtes, en opérant sur un nombre de
requêtes statistiquement significatif et en vérifiant que la
différence entre les deux sources de référence
(utilisateur et aléatoire) est sensible, il est alors possible de
créer un coefficient pour évaluer la nature sémantique de
la source des requêtes.
La méthode MCCVS que nous proposons, permet en
respectant des conditions et un protocole de mesure de donner une valeur CVSC
sur la cohérence sémantique des agrégats.
4.3.2 Méthode TREC-Eval : enrichissement de
requêtes
Le principe de mesure
TREC-Eval est un outil basé sur un ensemble de
requêtes et de documents destiné à évaluer la
qualité d'un moteur de recherche en fonction de la pertinence des
documents retournés. Mais, ce n'est pas là notre objectif avec
TREC-Eval. En effet, nous allons utiliser un seul moteur de recherche, mais
nous allons modifier les requêtes utilisateurs en les enrichissant avec
des mots trouvés dans les agrégats et nous comparerons la «
qualité » des requêtes originales avec celles enrichies.
Nous utilisons comme moteur de recherche «
Terrier ». Ce moteur est disponible sur le site :
http://terrier.org/
La démarche consiste à enrichir des
requêtes utilisateurs avec les mots des agrégats associés
aux mots déjà présents dans la requête et à
comparer la pertinence des documents obtenus.
TREC-Eval permet, en effet, de comparer la qualité des
résultats obtenus entre deux requêtes. Si cet outil est
généralement utilisé pour comparer des moteurs de
recherche sur une même requête, rien n'empêche d'utiliser un
seul moteur de recherche et de comparer la « qualité » de
requêtes différentes.
Pour chaque requête effectuée par Terrier nous
sauvegardons les résultats dans un fichier au format attendu par
TREC-Eval. Ce type de fichier est nommé fichier « Run ». Pour
chaque requête TREC-Eval possède une liste de réponses
« idéales ». Cette liste de réponses a
été constituée manuellement et stockée dans un
fichier « Qrel ». En comparant les résultats obtenus par la
requête (fichier « Run ») et ceux de la réponse
idéale (fichier « Qrel ») TREC-Eval note la qualité du
résultat obtenu (cf. figure 4.7).
4.3 : Les méthodes de validation sémantique 137
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
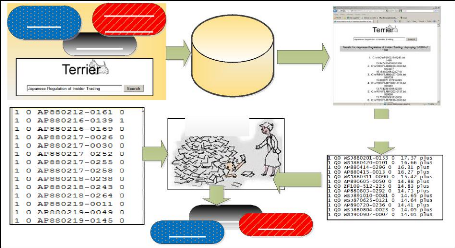
Topics
Fichier « Orel »
Agrégats
Requêtes
enrichies
M.A.P M.A.P.
Index : 1500000 articles
Trec_eval
Fichier « Run »
Figure 4.7 : Comparaison de résultats entre des
« Topics », des agrégats et des « Topics » enrichis
comme requêtes dans un même moteur de recherche « Terrier
» avec TREC-Eval.
Résultat de la recherche
avec Terrier
Le fichier « Run » est constitué de la liste
des documents retournés par le moteur de recherche Terrier. Nous
utilisons la note de pertinence ou «Rank Note» donnée par
Terrier comme note dans le « Fichier « Run ».
Dans TREC-Eval une requête utilisateur est nommée
« Topic ». Nous pouvons, pour une requête utilisateur de
référence ou « Topic », comparer les résultats
obtenus en utilisant comme requête :
M.A.P.
? le « Topic » seul ;
? le « Topic » enrichi avec des mots issus
d'agrégats ;
? l'agrégat lui-même utilisé comme
requête.
Paramétrage de Terrier
Le paramétrage de Terrier dans notre cas est
très limité. Il consiste à définir le nombre de
documents maximum retournés pour chaque requête. Afin de pouvoir
détecter des variations fines sur la qualité des requêtes,
nous avons paramétré Terrier pour retourner les 1000 premiers
articles. Ce paramétrage a déjà été
utilisé avec succès par Chris Buckley et Ellen M.
Voorhees [Buckley&al-2004].
La mesure de la qualité de la
requête
TREC-Eval est capable de mesurer un grand nombre de
paramètres de cohésion entre la requête et les
résultats retournés. Dans nos tests nous avons choisi de mesurer
les valeurs de M.A.P. (Mean Average Precision) valeur de comparaison
généralement la plus utilisée. La
4.3 : Les méthodes de validation sémantique 138
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
valeur M.A.P. est définie comme la moyenne des
précisions obtenues chaque fois qu'un document pertinent est
retrouvé. Si d'autres mesures sont possibles il convient d'en
relativiser l'importance ici. En effet, nous mesurons comparativement des
populations de requêtes. Le choix du type de mesure n'a donc comme
contrainte principale que celle de posséder la capacité à
notifier une évolution de qualité.
La précision est définie en Recherche
d'Information (R.I.) comme le nombre de documents pertinents retrouvés,
rapporté au nombre total de documents retrouvés. Pour une
requête q, Rq étant le nombre de documents
retournés et Pq le nombre de documents pertinents, la
précision se définit comme suit :
La Mean Précision ou correspond à un calcul de
la moyenne des précisons calculée pour chaque document pertinent
retourné.
Supposons un Topic pour lequel il existe cinq documents
pertinents appartenant à l'ensemble Pt défini comme suit
:
Pt = {dp1 ; dp2 ; dp3 ; dp4 ; dp5}
Supposons un ensemble de documents retourné Rqt
par une requête sur ce même Topic défini comme suit
:
Rqt = {dp1 ; dp4 ; da ; db ; dp5 ; dp3 ; dc ; dd ; de ;
dp2}
La précision sera pour chaque document pertinent la
suivante :
|
dp1
|
dp4
|
da
|
db
|
dp5
|
dp3
|
dc
|
dd
|
de
|
dp2
|
|
1
|
1
|
-
|
-
|
0.6
|
0.833
|
-
|
-
|
-
|
0.5
|
La Mean Precision étant la moyenne des
précisions rencontrées est dans notre exemple : MP =
(1+1+0.6+0.833+0.5) / 5= 0.7866
Pour un ensemble de requêtes, la MAP ou Mean Average
Precision est la moyenne de l'ensemble des Mean Precision de l'ensemble des
requêtes du jeu de test.
| 

