Conclusion
L'échantillon de test pour la méthode de
validation MCVSV est à adapter s'il provient de très grands
graphes de mots, particulièrement si ceux-ci sont « pollués
» par un grand nombre d'erreurs ou de mots vides. Le choix
d'écarter les mots correspondant aux 20 % les plus marginaux doit
être considéré en se remémorant que MCVSV est une
méthode comparative. Ainsi, si les conditions de mesure sont les
mêmes pour l'ensemble des courbes repères et les
éléments issus des agrégats et que les courbes de
référence (aléatoires et utilisateurs) sont suffisamment
différenciées, la méthode nous semble rester
pertinente.
Avec une valeur de CVSC de .899, nous obtenons une
excellente valeur du Coefficient de Validation Sémantique Comparé
(en basant toujours la limite sur la valeur médiane de 0.5). La
méthode d'agrégation est validée comme ayant sur des
Méga-graphes de mots, la capacité à créer des
agrégats qui ont statistiquement une cohérence sémantique
certaine et cela depuis un réseau non préalablement
filtré.
4.4.4 Rigidification Régulée sur le
réseau « 100 mots dans AOL » avec validation par MCSDR.
Dans cette expérimentation nous utilisons la
méthode de mesure de MCSDR ou « Méthode de Comparaison de la
Similarité entre Documents Retournés » (cf. paragraphe
4.4 : Résultats des regroupements et validation
sémantique 169
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
4.3.3) sur le réseau « 100 mots dans AOL » et
les agrégats créés par la méthode de Rigidification
Régulée (cf. paragraphe 4.4.3).
Filtrer les mots avant l'évaluation
sémantique ?
De la même manière que dans la méthode de
validation MCCVS (cf. paragraphe 4.4.3), pour le réseau « 100 mots
dans AOL », nous avons choisi de supprimer les mots qui sont dans la liste
des mots vides et les mots qui ont été faiblement
utilisés. Le filtre est identique à celui de
l'expérimentation sur ce réseau avec la méthode de
validation MCCVS. Le lecteur peut se reporter au paragraphe 4.4.2 pour la
description de ce filtre. Les mots conservés correspondent à 80%
des usages.
La phase d'acquisition des articles de
Wikipédia
Nous avons testé 6716 trios de mots pour les trois
types de requêtes (aléatoires, agrégats, utilisateurs). Les
dix premiers articles de Wikipédia valides (entre 200 et 15000 mots)
retournés pour chaque requête ont été
indexés. Le nombre de 10 représente une valeur maximale, une
requête peut en retourner moins. Un total de 33845 articles a
été indexé, 280530 mots différents ont
été trouvés.
Résultats
Les articles retournés par le moteur de recherche pour
une même requête sont comparés deux à deux. Nous
observons ensuite la distribution pour la moyenne de la valeur de
similarité des articles retournés par une même
requête. Si un seul article est présent la valeur de
similarité est considérée comme nulle.

|
|
|
|
|
A
|
|
B
|
|
Trios de mots aléatoires
|
|
|
Triades de mots issues de requêtes utilisateurs Trios de
mots issus des agrégats
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 0,04 0,08 0,12 0,16
0,2 0,24 0,28 0,32 0,36
0,4 0,44 0,48 0,52 0,56
0,6 0,64 0,68 0,72 0,76
0,8 0,84 0,88 0,92 0,96
1
1,00E-i-00 9,00E-01 8,00E-01 7,00E-01 6,00E-01 5,00E-01 4,00E-01
3,00E-01 2,00E-01 1,00E-01 0,00E-i-00
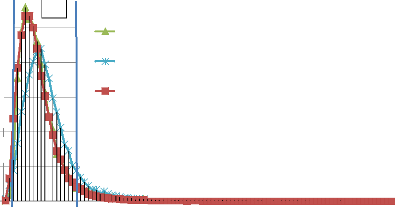
Figure 4.26 : Distribution de la moyenne des
similarités entre documents retournés par les trois types de
requêtes en « inter-requêtes ».
4.4 : Résultats des regroupements et validation
sémantique 170
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
A l'analyse de la figure 4.26, on remarque deux zones :
· la zone A est la zone présentant une certaine
disparité entre les courbes de référence (aléatoire
et utilisateur). Cette zone est extrêmement étroite ;
· la zone B qui ne fait pas ressortir de différence
notable entre les courbes de référence.
Comme on peut le constater, la différence principale
entre les courbes réside dans le pourcentage de requêtes n'ayant
pas retourné de site. Afin de replacer cette zone dans un espace de
lecture où l'estimation des courbes est possible, nous comparons les
courbes en supprimant pour chacune d'elles les requêtes ayant
retourné moins de deux articles. Nous notons ensuite (toujours pour les
requêtes ayant retourné au moins deux articles) la distribution
des moyennes de la similarité inter-requêtes et
intra-requête comme nous l'avions défini dans notre protocole de
validation. La mesure des distances inter-requêtes issues des
agrégats se fait entre des requêtes d'agrégats
différents. Au total plus de 10 millions de comparaisons de documents
ont été effectuées.
A
B
C
Triades de mots issues de requête utilisateurs
intra-requête
riades de mo
Trios de mots aléatoires intra-reu
rios de mots aléatoires
ntra-requête
Triaes de mots issues d'agrégats intra-requête
ros de mots issus d'agrégats
inter-requêtes
1,20E-01
1,00E-01
8,00E-02
6,00E-02
4,00E-02
2,00E-02
0,00E+00
0,00001 0,00005 0,00009 0,00013 0,00017 0,00021 0,00025
0,00029 0,00033 0,00037 0,00041 0,00045 0,00049 0,00053 0,00057 6,10E-04
0,00065 6,90E-04 7,30E-04 7,70E-04 8,10E-04 8,50E-04 8,90E-04 9,30E-04
9,70E-04
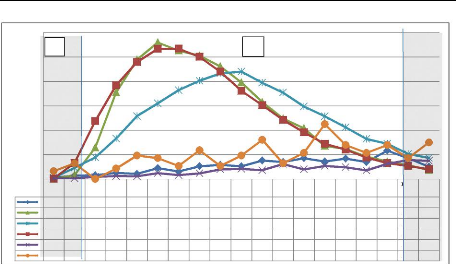
Figure 4.27 : Distribution de la moyenne des
similarités entre documents retournés par les trois types de
requêtes [intra-requête].
La zone B est la zone choisie comme zone «
différenciatrice » sur les deux courbes de référence
(cf. figure 4.27)
1,20E-01
A
B
1,00E-01
8,00E-02
6,00E-02
4,00E-02
2,00E-02
0,00E+00
0,0000
0,0000
,0001
0,0001
1
2
8
9
1,16E-0 2,71E-0
,71E-0 1,01E-0
9,65E-0 3,14E-0
,13E-0 7,43E-0
1,08E-0 9,14E-0
,05E-0 0,01735
3,82E-0 1,31E-0
,07E-0 8,08E-0
6,05E-0 6,05E-0
,55E-0 1,49E-0
6,42E-0 0,0128
,71E-0 3,00E-0
|
0,0000
3
|
0,0000
4
|
0,0000
5
|
0,0000
6
|
0,0000
7
|
0,0000
8
|
0,0000
9
|
0,0001
|
0,0001
1
|
0,0001
2
|
0,0001
3
|
0,0001
4
|
0,0001
5
|
0,0001
6
|
0,0001 0 7
|
|
3,10E-0
|
5,04E-0
|
4,27E-0
|
8,92E-0
|
6,20E-0
|
1,05E-0
|
1,16E-0
|
1,05E-0
|
1,51E-0
|
1,40E-0
|
1,71E-0
|
1,43E-0
|
1,67E-0
|
1,40E-0
|
2,33E-0 1
|
|
2,58E-0
|
7,11E-0
|
9,78E-0
|
1,12E-0
|
1,05E-0
|
1,01E-0
|
9,23E-0
|
7,92E-0
|
6,30E-0
|
4,95E-0
|
4,16E-0
|
2,72E-0
|
2,46E-0
|
1,84E-0
|
1,44E-0 1
|
|
1,78E-0
|
3,33E-0
|
5,16E-0
|
6,21E-0
|
7,29E-0
|
8,05E-0
|
8,66E-0
|
8,81E-0
|
7,89E-0
|
7,09E-0
|
5,95E-0
|
5,15E-0
|
4,24E-0
|
3,28E-0
|
2,89E-0 2
|
|
4,76E-0
|
7,69E-0
|
9,59E-0
|
1,07E-0
|
1,07E-0
|
1,00E-0
|
8,79E-0
|
7,23E-0
|
6,05E-0
|
4,85E-0
|
3,83E-0
|
2,89E-0
|
2,41E-0
|
1,76E-0
|
1,30E-0 1
|
|
1,82E-0
|
2,42E-0
|
2,22E-0
|
4,84E-0
|
3,23E-0
|
4,64E-0
|
7,87E-0
|
8,27E-0
|
7,26E-0
|
1,23E-0
|
7,87E-0
|
1,07E-0
|
9,69E-0
|
7,06E-0
|
1,25E-0 1
|
|
5 0
|
8,57E-0
|
0,01927
|
1,71E-0
|
1,07E-0
|
2,36E-0
|
1,07E-0
|
0,01927
|
3,21E-0
|
0,01285
|
2,14E-0
|
4,50E-0
|
2,78E-0
|
2,14E-0
|
2,78E-0 1
|
4.4 : Résultats des regroupements et validation
sémantique 171
|
|


