Agrégats de mots sémantiquement cohérents issus d'un grand graphe de terrain( Télécharger le fichier original )par Christian Belbèze Université Toulouse 1 Capitole - Doctorat en informatique 2012 |

Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
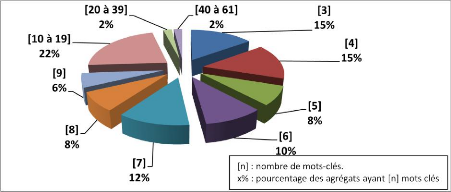
Figure 4.28 : Distribution de la moyenne des similarités entre documents retournés par les trois types de requêtes inter-requêtes et intra-requête (zone B). La valeur du QCSC (Quotient de Centralité Sémantique Comparé) est sur la Zone « B » telle que définie au paragraphe 4.3.3 de 0.89864. ConclusionAvec une valeur de QCSC supérieure à 0.89, la qualité des agrégats semble excellente. Cependant, la méthode utilise un moteur de recherche du marché ( bing.com) dont nous ne contrôlons pas le système d'ordonnancement. Les dix premiers sites retournés le sont par des algorithmes d'ordonnancement du moteur de recherche qui prennent en compte d'autres mesures que la simple présence des mots clés. La méthode est complexe et coûteuse sur le plan computationnel. De plus, de nombreuses difficultés techniques apparaissent. Par exemple, filtrer le code « HTML » est, quel que soit le « parser » utilisé, une opération jamais réussie à 100% sur l'ensemble des pages. De plus, nous limitons cette évaluation à une bibliothèque de documents ( wikipedia.org) qui représente aussi une limite sur l'ensemble des sujets abordés. Mais une partie de ces difficultés est compensée par la nature comparative de la méthode. Ainsi, si l'erreur est constante ou proportionnelle elle n'influe que faiblement sur la comparaison des différentes courbes. 4.4 : Résultats des regroupements et validation sémantique 172 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure 4.4.5 Rigidification Régulée sur réseau eDonkey-10-semaine et validation manuelleSpécificité du réseau étudié Ce réseau inclut des recherches effectuées par des pédophiles. Il est fourni sous contrat de confidentialité par une unité de recherche du CNRS spécialisée dans la détection d'activités pédophiles sur Internet (cf. paragraphe 4.2.2.). La grande majorité des mots est anonymisée. Paramétrage et particularité de l'algorithme Le but de cette expérimentation est de proposer à un expert des agrégats qui sont susceptibles de contenir des mots à connotation « pédophile ». Le réseau de départ contient un certain nombre de termes pédophiles « bien connus ». L'expert espère trouver dans les agrégats, en plus du lexique « bien connu », de nouveaux mots pouvant être classés comme « utilisés par des pédophiles » ou susceptibles de l'être. Il souhaite aussi, en plus de se voir proposer des mots correspondant à de nouveaux usages, être en mesure de valider la méthode, par la présence de « mots bien connus » supplémentaires. Le nombre maximal de mots dans un agrégat est défini à 80. Cela peut sembler important puisque dans un agrégat ayant une bonne cohérence sémantique ce nombre a été déterminé comme étant entre 30 et 40 mots (cf. paragraphe 4.4.2). La raison est que dans le cadre de cette expérimentation nous voulons proposer le plus de termes possible à notre expert. Si certains d'entre eux ne sont pas à connotation pédophile, la validation manuelle pourra le détecter. Mais en aucun cas, nous ne voudrions omettre un mot susceptible d'être classé comme « nouveau mot utilisé par les pédophiles ». Ce nombre de 80 est une valeur maximale qui a une faible incidence sur notre résultat : Seuls 2% des agrégats dépassent la taille de 39 mots. Valeur de départ de Val-Min-CFL et de Val-Activ-CFL A la différence de l'expérimentation menée avec la méthode de Rigidification Régulée sur le réseau « 100 mots dans AOL », il n'est pas possible de déterminer les valeurs de départ par une observation comportementale de mots aux caractéristiques sémantiques connues (mots vides et mots monosémiques). Les valeurs de départ sont donc sélectionnées par tests successifs. Les valeurs de Val-Min-CFL et Val-Activ-CFL sont choisies extrêmement basses. Puis elles sont testées sur un échantillon du graphe et augmentées jusqu'à ce que les paramètres de Val-Min-CFL et Val-Activ-CFL permettent de créer des graphes avec un certain équilibre. Ce qui signifie que nous créons des agrégats de taille variée et que dans certains agrégats créés, nous avons la capacité d'incorporer des mots à fort et faible usage. La valeur de départ de Val-Min-CFL est de 3% et la valeur de départ de Val-Activ-CFL est de 10%. 4.4 : Résultats des regroupements et validation sémantique 173 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Résultats Nous créons 173 agrégats répartis de la sorte et incluant 1549 mots-clés.
Figure 4.29 : Répartition des agrégats selon le nombre de mots-clés.
Tableau 4.13 : Agrégats incluant les huit mots « bien connus » comme étant utilisés par les pédophiles.
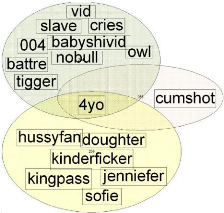
Figure 4.30 : Exemple d'agrégat autour du mot 4yo. 4.4 : Résultats des regroupements et validation sémantique 174 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
14239 2065 1838 A-178 A-194 21847 1231 1 07 34973 4301 9 1108 467 2162 84 A-181 Figure 4.31 : Exemple d'agrégats avec des recouvrements importants. Estimation de la validité sémantique des agrégats La validation est laissée à l'entière appréciation de l'expert. Le rôle d'expert est ici joué par Matthieu Latapy. Monsieur Latapy est responsable du projet « Measurement and Analysis of P2P Activity Against Paedophile Content » dont on peut trouver la description sur le site http://antipaedo.lip6.fr/. Ce projet est soutenu par l'Union Européenne, l'ANR, le CNRS, l'UPMC, l'UCC, l'UL, le FDN and l'INRIA. Cette évaluation a été faîte sans système de « note » ou de comparaison. L'expert détermine simplement que les agrégats « présentent une cohérence sémantique » ou pas et s'il découvre de nouveaux mots susceptibles d'être des mots utilisés spécifiquement dans le cadre de requêtes à caractère pédophile. |
|