4.7.2.4.3. Estimation des paramètres
Pour estimer les paramètres, il suffit de trouver la
relation mathématique qui existe entre la variable dépendante et
les variables indépendantes. Les valeurs qui déterminent cette
relation constituent les coefficients ou paramètres du modèle.
Une fois les paramètres estimés, il faut les évaluer
à partir d'un certain nombre de tests statistiques. Des tests seront
élaborés afin de décider, à partir des
hypothèses formulées, si ces paramètres sont
statistiquement significatifs.
Quatre (4) tests seront réalisés au niveau de la
régression :
· Test de signification pour les paramètres
estimés ;
· Test de l'ensemble des paramètres ;
· Test de détection de
l'hétéroscédasticité ;
· Test de normalité des résidus.
4.7.2.4.3.1. Test
de signification pour les paramètres estimés (Student)
Apres avoir estimé les coefficients de
régression, on doit les tester. Ce test est réalisé pour
déterminer si les coefficients estimés sont statistiquement
différents de 0 chacun. La distribution de Student avec n-k
degrés de liberté sera mise en oeuvre pour tester les
hypothèses sur les estimateurs et construire les intervalles de
confiance correspondants.
Le terme signification marginale est employé pour la
variable explicative au sens que lorsqu'une variable supplémentaire est
ajoutée, quelle sera sa contribution dans la variabilité de la
variable dépendante. Ce travail sera fait par la comparaison entre la
valeur de t-statistique calculée et t-statistique tabulée. Il
s'agit alors de tester les hypothèses suivantes :
H0 : ai=0, i=1......n
H1 : au moins un des paramètres est non
nul
La formule permettant de calculer le t-Student
s'écrit :
T= 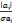 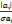 ; cette valeur est distribuée selon la loi de Student
avec n-k-1 degrés de liberté au seuil de signification 5 %. ; cette valeur est distribuée selon la loi de Student
avec n-k-1 degrés de liberté au seuil de signification 5 %.
Règle de décision :
Rejeter H0 si |T| > |Tá/2 :n-k-1|
R2 : Coefficient de
détermination multiple
Il permet de mesurer la proportion dans laquelle le
modèle explique la variabilité dans la variable expliquée
(Y). Il définit la proportion de la variabilité totale de
« Y expliquée » par la régression par rapport
aux variables explicatives.
R2=SCR/STC il varie de 0 à 1
SCR : somme totale des carrés de la
régression
STC : somme totale des carrés des écarts
à la moyenne
Si R2=0, l'équation de régression
n'explique en rien la variabilité de y ; si R2=1, il n'y
a pas de résidus ; plus c'est proche de 1, plus les variations dans
la variable y sont expliquées par les variations dans les variables
x.
| 

