4.2.2 Explication d'une projection avec
une restriction
Complexifions légèrement notre requête en
lui appliquant une restriction puis expliquons-la :
EXPLAIN EXTENDED
SELECT field1 FROM z_database1.table1
WHERE field1="123";
Le résultat de cet « EXPLAIN
EXTENDED » est :
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
z_database1
table1
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_TABLE_OR_COL
field1
TOK_WHERE
=
TOK_TABLE_OR_COL
field1
"123"
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: table1
filterExpr: (field1 = '123') (type: boolean)
Statistics:
...
GatherStats: false
Filter Operator
isSamplingPred: false
predicate: (field1 = '123') (type: boolean)
Statistics:
...
Select Operator
expressions: field1 (type: varchar(10))
outputColumnNames: _col0
Statistics:
...
File Output Operator
compressed: true
GlobalTableId: 0
directory:
hdfs://NAMENODE/tmp/hive/u_xxxx_yyy/.../-ext-10001
NumFilesPerFileSink: 1
Statistics:
...
Stats Publishing Key Prefix:
hdfs://NAMENODE/tmp/hive/u_xxxx_yyy/.../-ext-10001/
table:
input format:
org.apache.hadoop.mapred.TextInputFormat
output format:
org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
...
TotalFiles: 1
GatherStats: false
MultiFileSpray: false
Path -> Alias:
hdfs://NAMENODE/.../z_database1.db/table1 [table1]
Path -> Partition:
hdfs://NAMENODE/.../z_database1.db/table1
Partition
base file name: table1
input format:
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat
output format:
org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat
properties:
...
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Explications :
Le résultat de cet « EXPLAIN
EXTENDED » contient les 3 mêmes parties.
· (1) L'arbre syntaxique
abstrait
Nous remarquons qu'il contient un nouveau token
« TOK_WHERE » définissant notre restriction, nous
avons en effet à présent :
- TOK_QUERY : la racine de l'arbre
o TOK_FROM : la base et la table interrogées
o TOK_INSERT : la destination du résultat dans un
fichier temporaire
o TOK_SELECT : les champs sélectionnés
o TOK_WHERE : la restriction opérée sur un
champ
· (2) Les dépendances entre
étapes
Dans notre exemple, le plan de dépendance est devenu
plus complexe puisqu'il figure à présent deux
étapes :
- Stage-1: l'étaperacine
- Stage-0 : une étape dépendant
de l'étape racine
· (3) Le plan
d'étapes
Dans notre exemple :
- Stage-0 :
o est de type « Map Reduce »
o contient un arbre de traitements « Map Operator
Tree » décrivant une séquence de traitements :
§ TableScanFilter OperatorSelect OperatorFile Output
Operator
Où :
Ø TableScan : « balaye » la
table ligne par ligne
Ø Filter Operator : filtre la ligne parcourue
Ø Select Operator : projette le champ
sélectionné
Ø File Output Operator : définit la table
temporaire qui contiendra le résultat et notamment son emplacement
physique sur HDFS, ainsi que ses statistiques
Voici un schéma décrivant cette
étape :
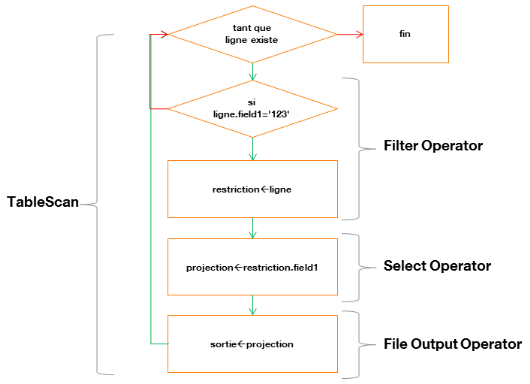
Figure 7 : diagramme de
traitement du parcours d'une table avec projection et restriction
- Stage-1 :
o est de type « Fetch Operator »
o contient un arbre de traitements « Processor
Tree » réalisant un unique traitement :
§ ListSink
Où :
Ø ListSink : transmet les données du
fichier temporaire à l' « executor »
Résumons :
- Le Stage-0 est chargé de construire
une table temporaire, réalisant la projection et la restriction d'une
table (phase Map).
- Le Stage-1 est chargé de
transférer les données de la table temporaire à
l' « executor » de Hive qui se chargera de les
acheminer au client qui aura effectué la requête.Dans cette
étape, l'absence de « TableScan » provient du fait
qu'il n'y plus aucune opération à réaliser (ni projection,
ni restriction), mis à part le transfert.
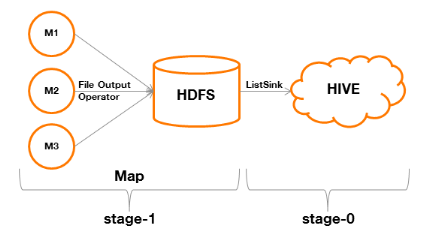
Figure 8 : processus de
traitement MapReduce d'une requête avec projection et restriction
Un tel fonctionnement est appelé « Map-Only
Job ». Sa particularité est de ne faire appel qu'à une
phase Map, épargnant ainsi notamment les étapes
« Partition & Sort » et « Shuffle & Merge
& Sort » préalables à la phase Reduce. C'est un
procédé qui permet dans tous les cas de figure de réaliser
un traitement avec le maximum de distribution sans avoir à
agréger les données sur un ensemble de Reducers.
Notons enfin, les sections « Path Alias » et
« Path Partition » qui s'ajoutent et qui donnent un
ensemble d'informations relatives à la table utilisée dans notre
requête :
· Path Alias : l'emplacement physique de la table dans
HDFS
· Path Partition : l'emplacement physique de la
partition dans HDFS(le rôle d'une partition sera expliqué dans le
prochain chapitre)
o input / output format : le format de la table
o properties
§ columns : la liste des champs de la table
§ columns.types : le type de chaque champ de la
table
o numFiles : la quantité de fichiers utilisés
par la table
o numRows : le nombre de lignes contenues par la table
o rawDataSize : la taille brute de la table (non
compressée)
o totalSize : la taille réelle de la table
(compressée)
| 

