Stratégies d'optimisation de requêtes SQL dans un écosystème Hadoop( Télécharger le fichier original )par Sébastien Frackowiak Université de Technologie de COmpiègne - Master 2 2017 |

4.2.3 Explication d'une projection avec une restriction et une agrégationComplexifions à nouveau notre requête en lui ajoutant une agrégation puis expliquons-la : EXPLAIN EXTENDED SELECT field1 FROM z_database1.table1 WHERE field1="123" GROUP BY field1 Rappelons qu'un « GROUP BY colonne1, ... colonneN » regroupera sur une même ligne chaque partition d'une liste de colonnes. Il est donc nécessaire que cette liste de colonnes apparaisse immédiatement suite au « SELECT ».L'usage habituel est d'ajouter ensuite des fonctions d'agrégation comme « COUNT », qui s'appliqueront à chacune des partitions listées. Notre exemple n'utilise pas de telles fonctions, pour ne pas ajouter de complexité inutile. Le résultat de cet « EXPLAIN EXTENDED » est : ABSTRACT SYNTAX TREE: ... STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 depends on stages: Stage-1 STAGE PLANS: Stage: Stage-1 Map Reduce Map Operator Tree: TableScan alias: table1 filterExpr: (field1 = '123') (type: boolean) Statistics: ... GatherStats: false Filter Operator isSamplingPred: false predicate: (field1 = '123') (type: boolean) Statistics: ... Reduce Output Operator key expressions: field1 (type: varchar(10)) sort order: + Map-reduce partition columns: field1 (type: varchar(10)) Statistics: ... tag: -1 auto parallelism: false Path -> Alias: hdfs://NAMENODE/.../z_database1/table1 [table1] Path -> Partition: hdfs://NAMENODE/.../z_database1/table1 Partition ... Reduce Operator Tree: Group By Operator keys: KEY._col0 (type: varchar(10)) mode: complete outputColumnNames: _col0 Statistics: ... File Output Operator ... Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: ListSink Nous ne reviendrons ni sur l'arbre syntaxique abstrait (qui ajoute à l'exemple précédent un nouveau token « TOK_GROUPBY ») ni sur les dépendances entre étapes (qui sont strictement identiques à l'exemple précédent : Stage-1Stage-0). Détaillons en revanche le plan d'étapes : - Stage-0
- Stage-1
Résumons :
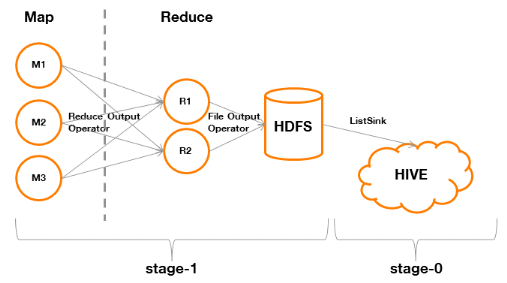
Figure 9 : processus de traitement MapReduce d'une requête SQL avec agrégation Nous identifions que le Stage-0implique l'exécution d'une phase Map (A) puis d'une phase Reduce (B). A. Phase Map Dans « Map OperatorTree », le « File Output Operator » de l'exemple précédent est remplacé par un « Reduce Output Operator ». Cela veut dire que la sortie ne s'effectuera pas sur un fichier du HDFS mais au travers du réseau vers les noeuds réalisant la phase Reducer. Le « Reduce Output Operator » définit plusieurs éléments fondamentaux pour la suite. · key expressions Une expression (Ki) peut être une simple colonne ou une combinaison de plusieurs colonnes dans une formule (concaténation de deux colonnes par exemple). Par exemple, nous pourrions avoir : K1 = field1 ou bien K1 = concat(field2, field3) Une « key expressions » est l'ensemble des expressions composant la clé qui sera utilisée durant toutes les phases du Map Reduce. Chaque clé peut être ainsi considérée comme un n-uplet (K1, ..., Kn). Nous aurions ainsi des couples clé (K) / valeur (V) de la forme suivante : ((K1, ..., Kn), (V1, ..., Vm)) Notons que le framework MapReduce définit une clé comme un seul élément (il en va de même pour la valeur), cela implique donc l'utilisation de mécaniques de sérialisation par Hive afin d'assurer la compatibilité entre ces deux environnements ( annexe). · sort order Il s'agit du sens du tri (« + » pour ascendant et « - » pour descendant) qui sera appliqué à la clé durant les phases de « Partition & Sort » et « Shuffle & Merge & Sort ». Il est à noter qu'il y aura autant de « + » ou de « - » que d'expressions définissant la clé (le premier ordre s'applique à K1, le n-ième ordre à Kn). · map-reduce partition columns Il s'agit de l'ensemble des colonnes qui définiront le partitionnement qui sera utilisé durant les phases « Partition & Sort & Shuffle » et « Merge & Sort ». Le partitionnement permet d'affecter chaque ligne parcourue à un Reducer. Il garantit que toutes les lignes identiques sur cet ensemble de colonnes seront traitées au sein d'un même Reducer. Dans notre exemple, la définition de la clé est identique au partitionnement. Il s'agit du cas d'application classique du paradigme MapReduce. Il est cependant possible de distinguer la clé et le partitionnement en utilisant notamment les instructions suivantes en fin de requête : DISTRIBUTE BY <ci, ..., cn> SORT BY <cj, ..., cm> ou bien CLUSTER BY <ci, ..., cn> « DISTRIBUTE BY » indique l'ensemble de colonnes qui définira le partitionnement ( annexe). « SORT BY » indique le sens du tri sur chaque colonne ou expression définissant la clé. « CLUSTER BY » consiste en un « DISTRIBUTE BY » et « SORT BY ». B. Phase Reduce : Dans « Reduce Operator Tree », il figure un bloc « Group By Operator » qui définit les éléments suivant : · keys Il s'agit de l'ensemble des Ki composant la clé défini durant le « Map Operator Tree » et qui sera utilisée durant la phase Reduce qui traitera donc séparément chaque n-uplet. · mode Dans le contexte du « GROUP BY », il indique si le mode est : - complete
- mergepartial
Dans notre exemple, l'agrégation est « complete ». · outputColumnNames Il s'agit des noms des colonnes qui seront retournées dans la table temporaire. |
|