4.2.4 Explication d'une jointure entre
deux tables
Modifions une dernière fois notre requête, cette
fois-ci en faisant apparaître une jointure et expliquons-la.
EXPLAIN
SELECT t1.field1 FROM z_database1.table1 t1
INNER JOIN z_database1.table2 t2 ON t1.field1=t2.field1
WHERE t1.field1='123'
GROUP BY field1
Le principe de l'EXPLAIN ayant déjà
été expliqué, une représentation en schéma
suffira pour comprendre les différentes étapes.
· Les dépendances entre étapes :
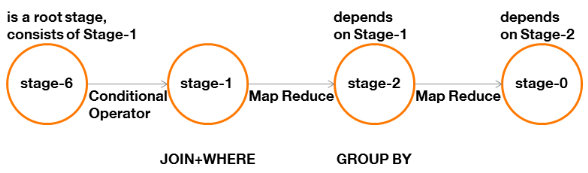
Figure 10 : graphe des
dépendances d'une requête avec jointure et
agrégation
Tout d'abord, nous remarquons la présence d'une
étape « racine » de type « Conditional
Operator » (Stage-6).
Cette étape est générée du fait de
la présence d'une jointure. Elle modifiera la manière dont sera
réalisée cette jointure (Stage-1) si certaines
conditions sont remplies (nous le verrons dans le prochain chapitre
consacré à l'optimisation).
· Le plan d'étapes :
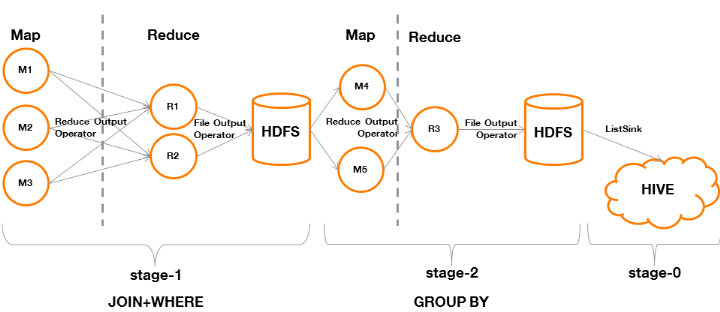
Figure 11 : processus de
traitement MapReduce d'une requête SQL avec jointure
- Stage-1
Par défaut, la jointure s'exécutera de
manière commune(Common-Join), il y aura une phase
« Map » durant laquelle les Mappers seront chargées
de balayer intégralement les deux tables à joindre pour
constituer un ensemble de clé/valeur. La clé choisie sera celle
de la jointure indiquée par l'utilisateur.
Ensuite, dans la phase « Partition &
Sort », chaque Mapper aura à répartir l'ensemble des
couples clé / valeurdes deux tables dans les partitions qui leur auront
été attribuées, puis à appliquer un tri par
clé.
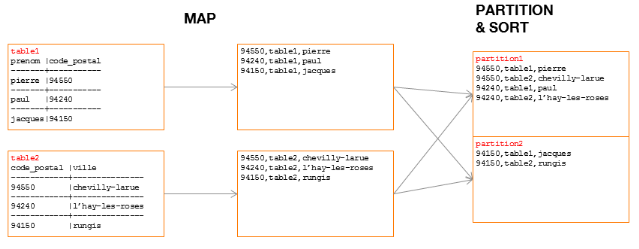
Figure 12 : phase
« Map » d'une jointure sur un Mapper
Dans la phase « Shuffle & Merge &
Sort », les partitions identiques de chaque Mapper seront
fusionnées entre-elles par les Reducers, puis, un nouveau tri par
clé sera appliqué à chaque partition fusionnée.
En fin de traitement, chaque Reducer aura écrit
indépendamment sur HDFS, un des fichiers composant la table temporaire
qui alimentera la prochaine étape.
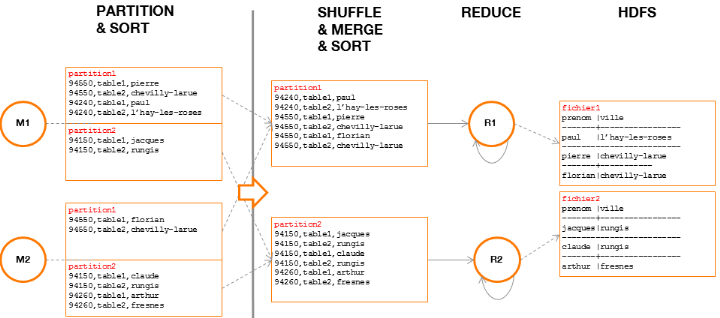
Figure 13 : phase
« Reduce » d'une jointure sur deux Reducers
- Stage-2
Cette étape est identique à l'exemple
précédent, en revanche notons que les données qu'elle
considérera sont celles en sortie du Stage-1.
| 

