5.2 Optimisation
par la conception ou « design »
Si le tuning permet d'améliorer les temps
d'exécutiondes requêtesde manière mécanique,
l'importance de leur conception ne doit pas être occultée, en
particulier lorsqu'il est question de produire un « Use Case Big
Data ».
Un « Use Case Big Data » consiste à
produire de nouvelles données par croisement périodiquede
données sources (issues du SI mais aussi de données externes),
qui pourront être consommées par des tiers, afin de
répondre à un besoin métier spécifique.
Cette production de données consiste ainsi à
réaliser des requêtes sur le puits de données, à
éventuellement créer des tables intermédiaires, puis
à stocker le résultat final pour qu'il puisse être
utilisé.
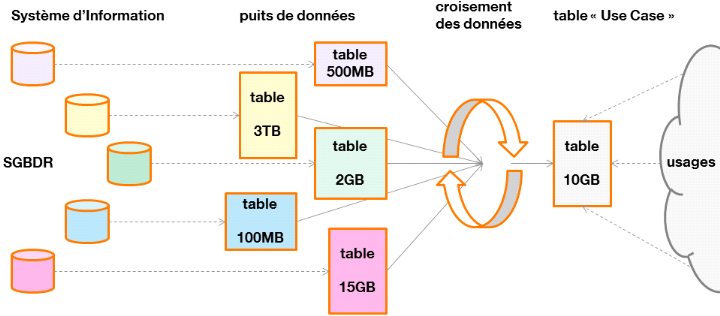
Figure 18 : du Système
d'Information au Use Case Big Data
Nous appellerons « plan de
requêtes », l'ensemble des requêtes permettant d'aboutir
au croisement des données du Use Case.
Un plan de requêtes qui ne tiendrait pas compte de la
spécificité des données à traiter (par exemple,
pour chaque table, le nombre de lignes et la répartition des clés
de jointures) ne pourra pas être optimisé.
En effet, en fonction de la typologie des données
à traiter, il sera possible d'utiliser différentes techniques de
requêtage.
Ainsi, cette partie se propose d'étudier ces
différentes techniques avec le souci d'expliquer les situations qui leur
seront particulièrement adaptées.
5.2.1 Utiliser les tables
partitionnées
Les tables du puits de données atteignent
régulièrement plusieurs TB. Lorsqu'une requête interroge
l'une d'elle, il est rarement utile d'avoir à parcourir
l'intégralité des données qu'elle contient.
Ces tables de grandes tailles sont ainsi partitionnées.
Le partitionnement consiste à disposer les fichiers qui les composent de
manière hiérarchisée dans le HDFS. Cette hiérarchie
est définie à la création de la table dont voici la
syntaxe :
CREATE TABLE z_database1.table1 (field1 string, ...)PARTITIONED BY (year string,month string, daystring);
Les champs définis dans la section « PARTITIONED
BY » définissent la hiérarchie de stockage dans le
HDFS.
Considérons la table « table1 » que
nous venons de définir, dont les fichiers sont sous cette
arborescence :
2.6TB /apps/hive/warehouse/z_database1.db/table1
La requête suivante précise une partition à
considérer :
SELECT * FROM z_database1.table1WHERE year="2018" AND month="01" AND day="01"
Les fichiers réellement considérés seront
donc sous cette arborescence :
5.9GB /apps/hive/warehouse/z_database1.db/table1/year=2018/month=01/day=05
Seuls 5.9GB des données seront ainsi manipulées
au lieu des 2.6TB de départ, ce qui épargnera le cluster HDFS (le
NameNode sera sollicité sur une plus faible quantité de fichiers)
et le cluster YARN (il ne sera pas nécessaire d'allouer une
quantité importante de containers).
Cette méthode n'est pas réservée aux
tables du puits de données, il est également intéressant
d'utiliser le partitionnement pour les tables qui seront produites dans le
cadre d'un « Use Case ». Dans ce cas, le partitionnement
devra être réalisé en considérant des colonnes de
faible cardinalité. En effet, des cardinalités trop importantes
impliqueraient la création de nombreux répertoires et fichiers,
ce qui, nous le savons à présent, est contre-productif.
Les partitions des tables du puits sont couramment
hiérarchisées par la date de chargement des données.
Le tableau suivant montre la répartition du nombre de
lignes insérées par jourde chargement dans la table
« table1 » (sur 6 mois de données).
|
|
0,25
|
0,5
|
0,75
|
0,9
|
0,95
|
0,99
|
|
centile
|
46 114 093
|
47 831 809
|
48 907 836
|
50 198 535
|
51 131 198
|
90 529 083
|
Tableau 2 :centiles du nombre
de lignes chargées par jour
Avec MIN=201 789 et MAX=108 132 735
Le tableau suivant montre la même répartition
mais à l'aide des dates fonctionnelles, par exemple la date à
laquelle a été passée une commande dans le cas d'une table
enregistrant des commandes de clients.
|
|
0,25
|
0,5
|
0,75
|
0,9
|
0,95
|
0,99
|
|
centile
|
16 130 510
|
38 035 331
|
42 779 757
|
45 833 922
|
47 710 421
|
49 173 539
|
Tableau 3 : centiles du nombre
de lignes par date fonctionnelle
Avec MIN=2 609 997 et MAX=49 361 016
Cette répartition est moins intéressante que la
première caril y a de plus grands écarts entre chaque centile. La
répartition des données est donc moins
régulière.
Une étude préalable de la répartition des
données est donc souhaitable avant de déterminer la
manière de partitionner une table.
Cette méthodologie pourra être appliquée
dès lors où il est nécessaire de partitionner une table
volumineuse et que plusieurs colonnes sont en concurrence pour en
établir la hiérarchie.
| 

