5.2.2 Optimiser les jointures
Les jointures constituent un challenge pour Hadoop. En effet,
comme nous l'avons vu, dans le contexte d'un Common-Join, la phase
« Shuffle & Merge & Sort » sollicite
énormément le cluster du fait des mouvements et des traitements
de données nécessaires pour réunir les données de
plusieurs tables.
La connaissance des données manipulées et la
compréhension des principaux mécanismes de jointure
implémentés par Hive sont deux atouts pour optimiser leur
fonctionnement.
5.2.2.1 Map-Join
Un Map-Join consiste à réaliser la jointure de
plusieurs tables en une seule étape « Map »(Map-Only
Job) au lieu d'une étape « Map Reduce »
(LeftyLeverenz, 2017). Son intérêt est de traiter avantageusement
le cas de plusieurs tables de tailles très différentes.
Ø Considérons un premier cas de figure avec
le« 2-way join » (jointure entre deux tables) impliquant
une « grande » table (table1) et une
« petite » table (table2).
SELECT *FROM table1INNER JOIN table2 ON table1.field1=table2.field1;
La directive suivante permet d'identifier automatiquement le
rôle de chaque table (grande ou petite) et convertira automatiquement un
Common-Join en Map-Join si la « petite »table est
suffisamment petite.
set hive.auto.convert.join=true
La directive suivante permet de fixer la taille maximum de la
petite table (en MB). Si la « petite » table est
suffisamment petite, celle-ci sera chargée en mémoire de tous les
Mappers assignés au traitement de la « grande »
table.
sethive.mapjoin.smalltable.filesize=25000000
Les dépendances entre étapes fournies par la
commande EXPLAIN deviennent alors :
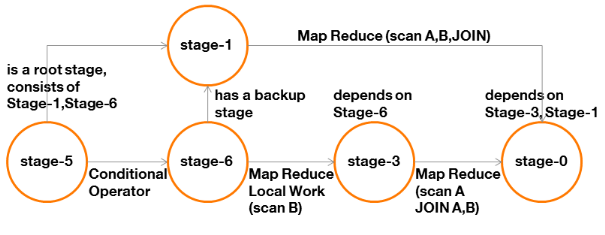
Figure 19 : graphe des
dépendances d'une requête SQL avec jointure
« Map-Only » (1/2)
Explication :
Le Stage-6 réalise un travail local
consistant à parcourir la petite table et à l'envoyer directement
aux Mappers du Stage-3. Ces derniers la chargeront en
mémoire sous forme de table de hachage et pourront alors parcourir la
grande table et réaliser la jointure à la volée.
Notons que le Stage-6 a un « plan
de secours ». En effet la détection de la petite table est
réalisée sur la base de statistiques et dans le cas où sa
taille dépasse effectivement la limite fixée, il sera possible de
basculer sur le Stage-1 qui réalisera un
« Common-Join ».
Ø Considérons à présent un
deuxième cas de figure avec le « n-wayjoin »
(jointures d'une grande table avec plusieurs tables de tailles
inférieures).
SELECT *FROM table1INNER JOIN table2 ON table1.field1=table2.field1;INNER JOIN table3 ON table1.field2=table3.field2;
Les directives suivantes permettent d'activer la conversion
automatique d'un Common-Join en Map-Join en considérant cette fois-ci
les N-1 plus petites tables de la requête.
set hive.auto.convert.join.noconditionaltask=trueset hive.auto.convert.join.nonconditionaltask.size=10000000
Ainsi, dans ce cas de figure, si la taille cumulée des
tables table2 et table3 est inférieure à 10MB, elles seront
chargées en mémoire de tous les Mappers assignés au
traitement de la « grande » table (Hao Zhu, 2016).
Les dépendances entre étapes fournies par la
commande EXPLAIN deviennent alors :
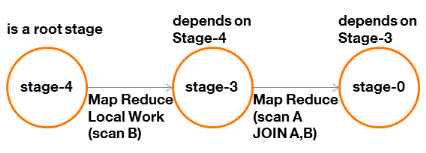
Figure 20 : graphe des
dépendances d'une requête SQL avec jointure
« Map-Only » (2/2)
Notons le retrait de d'étape préliminaire
« Conditional Operator », et donc l'absence de
« plan de secours ». Il faut donc être assuré
de la bonne tenue des statistiques des tables afin d'estimer correctement leur
taille. Dans le cas contraire, la jointure peut échouer et impliquer une
erreur à l'exécution.
5.2.2.2 Skew-Join
Une jointure de deux grandes tables est habituellement
réalisée par un traitement MapReduce qui commence par trier les
tables par la clé de jointure. Chaque Mapper communiquera ensuite les
lignes d'une clé particulière à un même Reducer
(Nadeem Moidu, 2015).
Le Skew-Join permet de différencier le traitement d'une
clé massivement représentée par rapport aux autres. Son
avantage est donc d'éviter que le Reducer en charge de cette clé
devienne un goulot d'étranglement pour le traitement Map Reduce.
Considérons une table table1 que nous souhaitons
joindre à la table table2 par la clé de jointure champ1.
SELECT * FROM table1 INNER JOIN table2 ON table1.champ1=table2.champ1
Une étude sur table1 montre que le nombre d'occurrences
des valeurs possibles de champ1 est relativement constant (entre 2457 et 2470),
à l'exception de la valeur « v1 », qui
apparaît3000 fois plus.
|
champ1
|
nombre d'occurrences
|
|
v1
|
7487662
|
|
v2
|
2470
|
|
v3
|
2469
|
|
...
|
2459
|
|
v5000
|
2457
|
Tableau 4 : exemple de
données « biaisées » ou
« skewed »
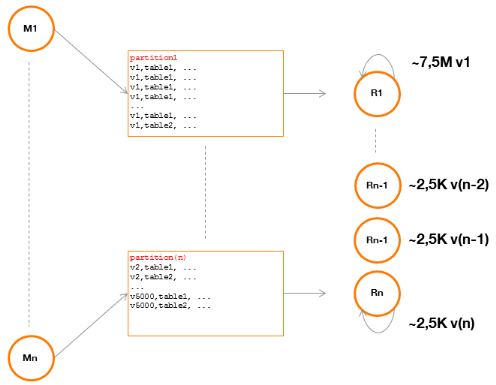
Figure 21 : Reducer devant
traiter une donnée « biaisée » ou
« skewed »
Dans ce schéma, nous remarquons que le Reducer R1 est
surchargé par rapport aux autres.
Ce cas de figure nécessite donc une approche
particulière.
Il serait envisageable, connaissant spécifiquement la
donnée « biaisée », de la
traiterséparément.
Considérons une table « table1 »
dont le champ « champ1 » est biaisé sur la
valeur « v1 » et une table
« table2 », ayant une répartition
homogène.
Nous procéderions ainsi :
SELECT * FROM table1INNER JOIN table2 ON table1.champ1=table2.champ1WHEREtable1.champ1<>"v1"
et dans un deuxième temps :
SELECT * FROM table1INNER JOIN table2 ON table1.champ1=table2.champ1WHEREtable1.champ1="v1"
La première requête génèrera un
Common-Join équilibré (la valeur « v1 » est
évitée), alors que la seconde sera facilement transformable en
« Map-Join ».
Cette approche conduit à réaliser deux
traitements, où il s'agira de lire plusieurs fois les mêmes
données ce qui n'est pas économique.Il est possible de
créer une table biaisée ou « Skewed Table »
très simplement :
CREATE TABLE table1 (champ1 string,champ2 string,...)SKEWED BY (champ1) ON ("v1")
Cette déclaration de table, permet d'indiquer
explicitement quel champ pourrait être biaisé (notions qu'il est
possible d'indiquer plusieurs champs potentiellement biaisés).
La directive suivante active le « Skew-Join »
:
set hive.optimize.skewjoin=true
Et celle-ci définit le seuil d'occurrences
déclencheur :
set hive.skewjoin.key=7500000
Lorsqu'un Skew-Join est effectivement détecté
durant l'exécution, un traitement Map Reduce sera opéré
sur l'ensemble des données, excepté pour la valeur biaisée
qui sera traitée séparément, évitant ainsi l'effet
« goulot d'étranglement ».
| 

