CHAPITRE III : ESTIMATION
DES MODÈLES ET RESULTATS.
Ce chapitre se consacre, d'une part à l'estimation des
modèles (section 1), et d'autre part, à la
présentation des résultats (section 2).
Section 1 : Estimation des
modèles.
Dans cette section, il sera question de décliner
brièvement les différents facteurs qui fondent le choix de nos
modèles, les méthodes d'estimation ainsi que les
différents tests, dans un premier temps. Et dans un second temps, nous
exposons la source des données collectées.
1.1- Modèle linéaire dynamique :
 Choix de l'estimateur du modèle autorégressif de Pesaran
et al (1999). Choix de l'estimateur du modèle autorégressif de Pesaran
et al (1999).
Le modele retenu pour notre étude à savoir le
panel dynamique ARDL developpé par Pesaran et al (1999) renferme trois
(3) estimateurs différents : l'estimateur de groupe moyen (MG) de
Pesaran et Smith (1995), l'estimateur de groupe moyen
combiné (PMG) mis au point par Pesaran et al. (1999) et l'estimateur
dynamique à effets fixes (DFE).
Les trois (3) estimateurs tiennent compte de
l'équilibre à long terme et de
l'hétérogénéité du processus d'ajustement
dynamique (Demetriades et Law, 2006) et sont calculés selon le maximum
de vraisemblance. Par ailleurs, Blackburn et Frank (2007) ont souligné
la différence fondamentale entre les techniques d'estimations sus
mentionnées (MG, DFE et PMG).
Selon les deux auteurs, la technique MG estime N
régressions de séries chronologiques et fait la moyenne de leurs
coefficients. Cependant, cet estimateur ne tient pas compte du fait que
certains paramètres peuvent être les mêmes d'un groupe
à l'autre. Tandis que pour la technique DFE, les points à
l'origine peuvent différer d'un groupe à l'autre alors que tous
les autres coefficients et variances d'erreur sont contraints d'être
identiques. Quant à l'estimateur PMG, il implique la fusion de la mise
en commun de la moyenne des coefficients. Cet estimateur permet aux points
d'intersection, aux coefficients à court terme et aux variances d'erreur
de différer librement entre les groupes, mais limite les coefficients
à long terme à être les mêmes.
Cependant, pour opérer le choix entre les
méthodes MG, PMG et DFE, le test de Hausman est utilisé afin de
vérifier s'il existe une différence significative entre ces
estimateurs. Le point nul de ce test c'est que la différence entre
l'estimation de PMG et MG ou celle de PMG et DFE n'est pas significative.
Ainsi, si la valeur nulle n'est pas rejetée, l'estimateur PMG est
recommandé car il est efficace. L'alternative est qu'il existe une
différence significative entre PMG et MG ou PMG et DFE et que la valeur
nulle soit rejetée. S'il y a des valeurs aberrantes, l'estimateur moyen
peut avoir une grande variance et, dans ce cas, le test de Hausman aurait peu
de puissance.
La PMG sera utilisée si la valeur p est non
significative au niveau de 5 %. En d'autre part, s'il se trouve qu'il y'a une
valeur p significative, l'utilisation d'un estimateur MG ou DFE est
appropriée. Une autre question importante est que la structure de
décalage de l'ARDL devrait être déterminée par un
critère d'information cohérent.
 Etapes de l'estimation du modèle linéaire. Etapes de l'estimation du modèle linéaire.
Afin d'estimer la relation linéaire entre l'inflation
et le chômage à court et à long terme en zone CEMAC, nous
allons procéder en plusieurs étapes :
? Spécification du modèle :
La présente étude contribue au débat sur
la relation entre l'inflation et le chômage en ayant recours à
l'estimateur de panel ARDL. En effet, le choix d'un modèle dynamique
s'expliquerait par la nécessité d'intégrer les effets
dynamiques passés des variables liés aux multiples
évènements qui se seraient produits durant la période
considérée de notre recherche et qui auraient contribué
à la complexité du système économique des pays de
la CEMAC.
Ce modèle est particulièrement attrayant en ce
qu'il tient compte de l'hétérogénéité qui
peut être présent dans le panel (Shin et al, 2014). En effet, les
disparités structurelles des pays de l'échantillon pourraient
justifier l'application des estimateurs du panel ARDL, en ce sens que les pays
de l'échantillon n'ont pas les mêmes caractéristiques
structurelles. Cependant, il nous convient, au regard de la littérature
économique, d'ajouter l'opérateur des premières
différences (??) dans la spécification de notre
modèle :
??CHOi,t 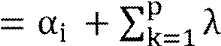 i,k ??CHOi,t-k i,k ??CHOi,t-k
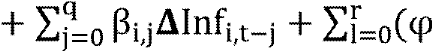 i,1,l
??Pibi,t-l + i,1,l
??Pibi,t-l +
öi,2,l??Invi,t-l + öi,3,l??Tinti,t-l +
öi,4,l??Tchi,t-l + öi,5,l??Popi,t-l ) + èi,1CHOi,t-1 +
èi,2Infi,t-1 +
èi,3Pibi,t-1 +
èi,4Invi,t-1 +
èi,5Tinti,t-1 +
èi,6Tchi,t-l +
????,7Popi,t-l +
??i,t
(11)
Avec,
ï Ä : opérateur de
différence première ;
ï ?? : constante ;
ï ??, ??, ??1, ??2, ... , ??5
: effets à court terme ;
ï ??1, ... , ??7: dynamique de long
terme du modèle ;
ï ?? ~ iid (0, ó) : terme d'erreur (bruit
blanc).
Comme pour tout modèle dynamique, nous nous servirons
des critères d'information (AkaikeAIC, Shwarz-SIC et Hannan-Quin) pour
déterminer les décalages optimaux (p, q, r) du modèle de
panel ARDL, par parcimonie (Jonas Kibala, 2018). De plus, nous retenons
également deux types d'hypothèses à partir de
l'équation (11), représentant la relation de long terme.
La première équation (10) représente
l'hypothèse nulle, pour l'absence de co-intégration (H0)
: ??1 = ??2 = ??3 = ??4
= ??5 = ??6 = ??7 = 0, alors que
l'hypothèse alternative est (H1) : ??1 ? ??2 ?
??3 ? ??4 ? ??5 ? ??6 ? ??7
? 0. Ensuite, la statistique F calculée est évaluée
avec la valeur critique (limite supérieure et inférieure)
donnée par Pesaran et al. (2001).
ï Statistique descriptive des variables :
Elle nous permet d'avoir une vision synoptique sur l'ensemble
de la série. Elle nous renseigne généralement sur les
caractéristiques de tendances centrales (Moyenne, Maximum et minimum)
mais aussi sur les caractéristiques de dispersion (Variance,
écart-type).
ï Matrice de corrélation des variables sur la
période 1994-2022 :
Le teste de corrélation permet de mesurer le
degré de liaison et de dépendance entre deux ou plusieurs
variables.
Test de multi-colinéarité :
La multi-colinéarité est un problème
fondamental dans l'analyse des séries multivariées. Elle apparait
lorsque deux ou plusieurs variables mesurent le même
phénomène. Dans une régression, la
multi-colinéarité est un problème qui survient lorsque
certaines variables de prévision du modèle mesurent le même
phénomène.
La multi-colinéarité est un problème
à ne pas négliger car elle peut augmenter la variance des
coefficients de régression, les rendant plus instables et difficiles
à interpréter. Pour tester la multi-colinéarité
entre nos variables, nous recourons au test de Klein.
Hypothèses :
H0 : présence de multi-colinéarité ;
H1 : absence de multi-colinéarité.
? Test d'homogénéité de Swamy (1970) :
Il est important dans l'analyse des séries en
données de panel de savoir si le processus générateur de
la série suit une spécification homogène ou
hétérogène. Cela revient donc à tester
l'égalité des coefficients dans la dimension individuelle.
Autrement dit, de voir s'il y'a ou non des spécificités
individuelles entre les éléments de l'échantillon. Cela
revient, dans ce cas, à vérifier si l'ensemble des pays de notre
échantillon présentent des caractéristiques identiques ou
au contraire, qu'ils présentent un caractère différent
d'un pays à l'autre. Pour ce faire, nous utilisons le test de Swamy
(1970), développé pour les panels où N est petit par
rapport à T et qui permet une
hétéroscédasticité de la section transversale.
Hypothèses :
H0 : homogénéité des coefficients entre
individus ;
H1 : hétérogénéité des
coefficients entre individus.
La règle de décision est que si la
probabilité de chi-2 est inférieure au seuil de risque de 5%,
cela montre que l'échantillon est hétérogène.
? Test d'endogénéité et de
spécification des effets individuels :
Le test de Hausman (1978) qui est essentiellement un test de
spécification, nous permet de voir quel type de spécification se
prête le mieux à nos données. En effet, ce test nous permet
de savoir si nos données obéissent à une
spécification à effets fixe ou à effets aléatoire.
Il est donc question de déterminer si les coefficients des deux
estimations (fixes et aléatoires) sont statistiquement
différents. De plus, c'est un test qui peut être appliqué
dans le traitement des problèmes d'endogénéité. De
ce fait, nous nous intéressons particulièrement à la
statistique du
Chi-2 ; dans ce cas, si cette statistique est
inférieure à 5% on accepte l'hypothèse nulle ; si par
contre elle est supérieure à 5%, on ne peut accepter cette
hypothèse.
Hypothèses :
H0 : modèle à effets fixe ;
H1 : modèle à effets aléatoire.
ï Test de dépendance interindividuelle :
La dépendance interindividuelle peut etre due à
des effets spatiaux ou pourrait etre due à des facteurs communs non
observés. C'est pourquoi il faut tester l'existence de telle
dépendance des variables et de panel. Puisque le panel
étudié a un N petit et un grand T, les tests de Lagrange
Multiplier de Breusch-Pagan (1980), CD de Pesaran (2004) et LM adj de Pesaran
et al (2004) vont etre mobilisés pour le cadre de cette étude. De
ce fait, si la probabilité Pr?5%, on accepter l'hypothèse nulle
d'indépendance individuelle. Ainsi, nous allons donc recourir aux tests
de première génération pour déterminer la
stationnarité de nos variables, dans le cas contraire les tests de
stationnarités de deuxieme génération seront utiles.
ï Test de stationnarité :
Les problèmes de non stationnarité sont l'un des
problemes fréquemment rencontrés dans l'analyse des séries
chronologiques. Le test de stationnarité ou test de racine unitaire
permet d'évaluer la tendance de chaque variable dans le temps. Son
objectif est de rechercher la présence de racine unitaire dans le but de
minimiser les risques de régressions fallacieuses (Engel et Granger,
1969).
De plus, il permet de définir l'ordre
d'intégration nécessaire avant l'application de toute technique
de co-intégration sur les données. Parmi les tests de
stationnarité, on distingue essentiellement les tests de première
génération (ces derniers supposent que les individus dans le
panel sont indépendants) d'une part, parmi lesquels on retrouve les
tests les plus usuels comme : le test de Levin-Lin-Chu (LLC, 1993), le test de
d'Im-Pesaran-Shin (IPS, 1997), le test de Fisher Chi-carré (ADF Fisher),
le test de Breitung et Das (2005), le test de Phillips et
Perron (PP) et, en d'autre part, les tests de deuxième
générations tels que le test de Bai et Ng (2004), Choi et Chue
(2007), Moon et Perron (2004), Phillips et Sul (2003) et Pesaran (2007).
Le choix du type de génération de test
dépend de l'hypothèse vérifiée dans le test de
dépendance interindividuelle.
ï Détermination du nombre de retards optimaux :
Pour éviter de choisir la mauvaise taille de
modèle, il est essentiel de connaître le nombre de retards du
modèle ARDL. Pour ce faire, nous utiliserons dans cette étude le
nombre minimum de retards pour le critère d'information d'Akaike (AIC)
et le critère d'information Bayesian (BIC).
ï Test de co-intégration :
Le test de co-intégration sert à
détecter s'il y a une ou plusieurs relations de long terme entre deux
ou plusieurs variables pouvant être combinées avec les dynamiques
de court terme du modèle. Dans la littérature, les relations
entre phénomènes sont généralement examinées
à l'aide des méthodes de co-intégration standards telles
que celle d'Enger et Granger (1987) et de Johansen (1988) entre autres.
Toutefois, ces tests de co-intégration usuels préconisent
l'utilisation de variables intégrées de même ordre I(0) ou
I(1). De plus, ils sont adaptés pour les échantillons de grande
taille.
Afin de pallier ces insuffisances, Pesaran et al. (2001) ont
développé une nouvelle approche plus flexible et moins
contraignante que les techniques précédentes appelée
modèle autorégressif à retards échelonnés
(ARDL). Elle est préférée aux méthodes d'Enger et
Granger ou de Johansen du fait de la présence de séries
intégrées à différents ordres, sur petit
échantillon et en présence de variables explicatives
endogènes (Narayan, 2005). Ainsi, l'ARDL donne la possibilité de
traiter simultanément la dynamique de long terme et les ajustements de
court terme. De ce fait, nous utiliserons pour cette étude, les tests de
Pedroni (2004) et de Westerlund (2007).
ï Estimation du modèle linéaire dynamique
à court et à long terme :
Après avoir vérifié que les variables ne
sont pas intégrées d'un ordre égal ou supérieur
à I(2) et que les séries sont co-intégrées,
l'étape suivante consiste à estimer la régression ARDL
linéaire de panel spécifiée par l'équation (12) au
moyen d'une estimation de groupe de moyennes regroupées (PMG), des
estimateurs à effets fixes et aléatoires (DFE) et de l'estimateur
du groupe de moyenne (MG). Ainsi, nous procéderons par une analyse des
résultats des estimations de court terme et de long terme
réalisés à travers les différentes méthodes
susmentionnées. La durée de décalage appropriée est
définie sur la base des critères d'information d'Akaike (AIC) et
d'information Bayesian (BIC).
ï Tests de diagnostic du modèle :
La validation du modèle est une étape cruciale
de l'estimation d'un modèle, car il permet de vérifier s'il n'y a
pas violation d'une des hypothèses de normalité des
résidus, d'autocorrélation des erreurs ou
d'hétéroscédasticité des erreurs. Cependant,
l'estimation du modèle de panel ARDL trouve son intérêt en
présence de violation d'une de ces hypothèses. En effet, ce
modèle est robuste aux problemes d'autocorrélation et
d'hétéroscédasticité ainsi, il permet d'obtenir des
résultats robustes indépendamment de la taille de
l'échantillon (Harris et al, 2003). A cet effet, nous ne
procèderons pas à la vérification de ces
hypothèses. En outre, il sera par contre question de corriger, en cas de
présence, le probleme de dépendance transversale en recourant aux
méthodes d'erreur standard de Driscoll et Kraay (1998).
Par ailleurs, le constat selon lequel la relation entre
l'inflation et le chômage semble être positive en temps normal et
négative pendant les cycles économiques (King et al, 1995 ;
Fisher, 1993) suggère qu'il peut y avoir des effets de seuil dans la
courbe de Phillips. Ainsi, au-delà de l'estimation de la relation
dynamique entre inflation et chômage dans le cas des économies de
la CEMAC, nous avons également tenté d'examiner cette
possibilité d'effets de seuil. Pour ce faire, nous allons utiliser la
régression non-linéaire de seuil à effets fixes
proposée par Hansen (1999).
1.2- Modèle non linéaire à effet de
seuil.
 Spécification du modèle non linéaire à
seuil de Hansen (1999). Spécification du modèle non linéaire à
seuil de Hansen (1999).
Le modèle de régression de seuil de panel (PTR)
non dynamique à effet fixe, développé par Hansen (1999) et
promu par Wang (2015), est adopté dans cette étude pour estimer
le seuil d'inflation optimal des pays de la CEMAC sur des données
allant de la période de 1994 à 2022. Le modèle est
implémenté en divisant les données en différents
groupes selon une variable observable qui peut être
considérée comme un paramètre de régime. Si au
moins une valeur seuil est trouvée dans un régime, cela implique
que la relation entre l'inflation et le chômage n'est pas
linéaire. Cela indique également l'exploration de la
possibilité d'autres régimes. Dans ce cas, le modèle
identifie les seuils de manière séquentielle (Manzoor Hussain et
al, 2021).
Ainsi, l'équation (10) est réécrite en un
modèle à seuil unique comme suit :
Yi,t = ???? +
â'Xi,t(?) + öZi,t +
åi,t
(12a)

Avec, Xi,t(?) = { Xi,t et ??' = (â1'
â2')
Xi,t( qi,t ? 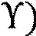
Où, Yi,t la variable dépendante qui
est dans le cas de notre étude le chômage, la variable seuil
qi,t , l'inflation, qui représente aussi notre variable
d'intérêt Xi,t , et ? le paramètre de seuil.
Quant à Zi,t, il représente le vecteur des variables
de contrôle (Pib, Inv, Tint, Tch, Pop). L'indice i indexe le
pays individuel tandis que l'indice t indexe l'année.
(
·) est la fonction indicatrice, qui est égale à 1 ou 0,
selon le terme de la condition.
L'équation ci-dessus divise les observations en deux
régimes, en fonction de la valeur relative de la variable de seuil
qi,t par rapport au paramètre de seuil ?. Les régimes
sont identifiés par les paramètres de pente â1 et â2.
Le paramètre åi,t est le terme d'erreur, qui est
supposé indépendant et distribué de manière
identique (iid) avec une moyenne nulle et une variance infinie. Pour des seuils
? donnés, la pente â peut être estimée par les
moindres carrés ordinaires.
La somme résiduelle des carrés (RSS) est
calculée à partir de l'équation estimée ci-dessus,
qui est également fonction du paramètre ?. Le seuil optimal est
obtenu lorsque RSS est minimal. La prochaine étape cruciale consiste
à déterminer la signification statistique du point de seuil dans
un tel modèle non linéaire.
L'équation (12a) ci-dessus peut etre
spécifiée ainsi qu'il suit :
CHOi,t = ???? +
â'infi,t(?) + öZi,t +
åi,t
(12b)
 Etapes de l'estimation du modèle non linéaire. Etapes de l'estimation du modèle non linéaire.
Afin d'analyser la relation non linéaire et de
déterminer les effets de seuil dans la relation entre l'inflation et le
chômage en zone CEMAC, le présent document adopte la
procédure suivante :
Étape 1 : Analyse graphique de non
linéarité entre l'inflation et le chômage dans les pays de
la
CEMAC.
Étape 2 : Un modèle à seuil unique est
ajusté pour tester la signification de l'effet de seuil. Ici, H0,
â1=â2. Sous H0 : il n'y a pas d'effet de
seuil dans le modèle (c'est-à-dire modèle
linéaire). Si H0 est rejeté, cela signifie que le modèle
n'est pas linéaire.
Étape 3 : Le nombre de seuils est
déterminé en estimant les effets de seuil des modèles de
manière séquentielle avec différents seuils. Le processus
de test se poursuit jusqu'à ce que l'hypothèse nulle soit
acceptée.
Etape 4 : Cette étape se consacre à l'estimation
de la régression de seuil dans le modèle de seuil retenu à
l'étape 3.
Etape 5 : Dans cette dernière étape, nous
effectuons des tests post-estimation afin de valider nos estimations. Nous
testons notamment la normalité des résidus,
l'autocorrélation des résidus et
l'hétéroscédasticité des résidus.
Source des données.
Les données utilisées dans cette étude
proviennent des rapports de la BEAC, des sites de la Banque Mondiale et du
FMI. L'étude couvre la période allant de 1994 à 2022 et
porte sur les six (6) pays de la CEMAC, soit un échantillon de taille
174.
Le choix de la période d'étude s'est fait en
tenant compte de la disponibilité des données. Par ailleurs,
l'étude a retenu comme logiciel statistique : Eviews13 et Stata15 pour
la réalisation des tests, des estimations et, des représentations
graphiques.
Nous utiliserons, pour cette étude, une double
démarche économétrique dans laquelle nous analyserons dans
un premier temps, la relation dynamique de court terme et de long terme entre
l'inflation et le chômage dans les économies de la CEMAC, puis
dans un second temps, nous adoptons une analyse non linéaire à
effets de seuil afin d'évaluer le niveau optimal d'inflation
au-delà duquel la relation entre l'inflation et le chômage en zone
CEMAC se détériore.
| 



