4.2 Application du modèle spatial
développé
pour l'estimation de l'apparentement
Nous avons appliqué le modèle spatial pour
l'estimation de l'apparentement (voir Définition Modèle Spatial)
à des données simulées. Les données ont
été simulées de la manière suivante :
- nous avons d'abord simulé les fréquences
alléliques selon une loi de Dirichlet dont tous les paramètres
sont égaux à 1
- nous avons simulé ensuite les génotypes de 5
mères et 5 pères avec un nombre variable de locus (5, 10, 15, 20,
30, 50 et 100 locus) selon une loi multinomiale dont les probabilités
associées sont les fréquences alléliques au locus
- nous simulons après les génotypes de 20
enfants. Le nombre d'enfants pour chaque mère est obtenu par 20 tirages
aléatoires avec remise d'un élément parmi 5 et une fois
que le nombre d'enfants pour une mère est connue, l'assignation du
père est faite en fonction de la distance entre les pères et la
mère : le père d'un enfant est simulé selon une loi
multinomiale dont les probabilités associés sont égales
aux distances entre les pères et la mère
considérée. Le génotype d'un enfant à un
locus est ensuite obtenu par le tirage aléatoire d'un
allèle parmi les 2 allèles présents au locus
considéré chez sa mère et le tirage d'un allèle au
hasard parmi les 2 allèles présents au locus
considéré chez sont père. Les juvéniles sont enfin
positionnés autour de leur mère selon une gaussienne
centrée sur la mère et une variance de dispersion égale
à 0.1, 1, 10, 100 respectivement.
Nous nous proposons maintenant d'étudier d'abord
l'effet du choix des paramètres du prior, c'est à dire le choix
des paramètres de la loi de Dirichlet pour les deux modèles
(modèles spatial et non spatial), selon le nombre de locus
considéré avec 100 répétitions. Ensuite, nous
étudions l'effet de la variance de dispersion autour de la mère
pour le modèle spatial pour l'apparentement.
4.2.1 Étude de l'effet du prior
Comme pour tout modèle bayésien, le choix de la
loi a priori des paramètres est toujours délicat car il peut
influer sur la qualité de l'inférence des paramètres.
Classiquement, avec un modèle multinomial-Dirichlet, le prior qui est
choisi est une loi de Dirichlet D(1, 1, 1), qui correspond à un prior
uniforme. Cependant, avec peu d'observations, comme par exemple avec uniquement
5 locus, le choix de cette loi n'est pas approprié car les individus
non-apparentés sont sous-estimés et l'apparentement est donc
sur-estimé. En effet, si toutes les 5 observations ont un mode d'IBD qui
est S9 alors la loi a posteriori des probabilités d'IBD est une D(1, 1,
6), donc la moyenne a posteriori du paramètre d'intérêt qui
est le coefficient d'apparentement è vaut 1/8+ 1/16 donc 0.1875; ce qui
est assez élevé sachant que le coefficient d'apparentement entre
deux demi-frères par exemple vaut 0.12. Nous n'avons par
conséquent pas choisi ce prior. Nous nous proposons de comparer les
résultats obtenus pour deux lois a priori du vecteur des modes d'IBD :
une loi de Dirichlet D(10-5, 10-5, 10-5) et
une loi de Dirichlet D(0.1, 0.1, 0.1). La corrélation entre la vraie
valeur de l'apparentement et la valeur estimée en employant notre
modèle avec chacun des deux priors considérés est
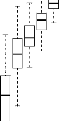
présentée à la Figure 4.15. Nous notons d'abord que la
corrélation entre la vraie valeur et la valeur estimée de
l'apparentement croît avec le nombre de locus pour les deux priors.
Ensuite, il y a clairement un effet du prior sur la corrélation entre
l'apparentement réel et l'apparentement estimé. Lorsque le nombre
de locus est faible, (par exemple avec 10 locus, ce qui se rapproche du cas de
nos données sur le karité) la corrélation moyenne entre
les vraies valeurs et les valeurs estimées est de près de 75%
avec le prior D(0.1, 0.1, 0.1) et ce résultat est assez convenable. Par
contre, avec le prior D(10-5, 10-5, 10-5), la
corrélation vaut à peine 60%. Lorsqu'on choisit comme loi a
priori D(10-5, 10-5, 10-5),
le nombre d'individus non-apparentés est en fait
sur-estimé. Ce qui justifie alors le choix de la loi priori D(0.1, 0.1,
0.1). Nous n'avons cependant pas une explication précise du fait que le
prior D(0.1, 0.1, 0.1) donne des résultats meilleurs que ceux
donnés par le prior D(10-5, 10-5,
10-5).
0.2 0.4 0.6 0.8 1.0
0.4 0.5 0.6 0.7 0.8 0.9 1.0


?
?
?
?
?
?
5 10 20 50 5 10 20 50
FIG. 4.15 - Corrélation entre l'apparentement
réel et l'apparentement estimé en fonction du nombre de locus et
du prior (la figure à gauche représente le cas avec une loi de
Dirichlet dont les paramètres sont égaux et très faibles
(10-5) et la figure de droite une loi de Dirichlet dont tous les
paramètres sont égaux à 0.1).
| 

