Conclusion partielle
Dans cette partie, nous venons d'analyser les résultats
de notre enquête en étudiant les relations du revenu des agents de
proximité avec leurs caractéristiques sociodémographiques
et économiques. Ainsi, l'analyse bivariée a
révélé que les variables sociodémographiques
à savoir le « nombre de personnes en charge », « les
caractéristiques socioprofessionnelles », et la « satisfaction
tirée du service » sont liées au revenu des agents de
proximité.
Somme toute, l'analyse bivariée des résultats de
l'enquête avait pour objectif de mettre en évidence les variables
qui ont une relation de dépendance avec le revenu des agents de
proximité. Les liens décelés lors de la dite analyse
seront approuvés ou non à l'aide d'une autre analyse plus
poussée : analyse multivariée.
73 | P a g e
VI.3.- Analyse explicative
Dans cette partie du travail, nous sommes
intéressés à déterminer les facteurs pouvant
expliquer le revenu des agents de proximité du M-Banking à partir
d'une analyse explicative. Cette approche, à savoir l'analyse
explicative, consiste à vérifier l'association entre les
variables afin de confirmer les tendances observées lors de l'analyse
bivariée en utilisant un modèle économétrique
approprié. Il est à noter que la variable « satisfaction
tirée du service » ne sera pas considérée dans
l'analyse multivariée.
VI.3.1.- Méthode explicative utilisée
Pour pouvoir mettre en exergue les variables pertinentes dans
l'étude des déterminants du revenu qui constitue la toile de fond
de ce travail, il convient de recourir à la modélisation. Vu que
la variable dépendante de l'étude, le revenu, est
catégorielle et de mesure ordinale, nous avons opté dans ce cas
pour un modèle à variable expliquée qualitative
multinomiale. Plus précisément, un modèle polytomique
univarié ordonné qui peut être un logit ou un probit
ordonné. C'est un modèle dans lequel on a une variable
dépendante ayant plusieurs modalités et un ordre naturel sur ces
modalités. Ces dernières proviennent d'un découpage en
tranche d'une variable numérique en l'occurrence le revenu.
VI.3.1.1.- Principes d'application du modèle
L'application du modèle polytomique univarié
ordonné répond au critère suivant :
- Premièrement, la variable expliquée doit
être une variable qualitative polytomique ordonnée (ayant au moins
trois modalités et de mesure ordinale) à l'instar de notre
variable dépendante. Par conséquent, pour un agent
évoluant dans l'aire métropolitaine de P-au-P, nous avons trois
options possibles : soit il a un revenu journalier élevé
(Revmoy=1), soit il a un revenu journalier moyen (Revmoy=2), soit il a un
revenu journalier faible (Revmoy=3).
- Secondement, les variables indépendantes peuvent
être quantitatives ou catégorielles, mais toutes les
modalités de ces variables doivent être dichotomisées avant
de les introduire dans le modèle. La modalité de
référence ne doit pas être introduite dans le
modèle.
74 | P a g e
Choix entre un modèle logit ou
probit
Il n'existe pas de différences significatives entre les
modèles logit et probit du fait de la proximité des fonctions de
répartition des lois normales centrées réduites et des
lois logistiques simples ou transformées. Par conséquent, les
modèles probit et logit donnent généralement des
résultats relativement similaires. Ainsi, à priori, la question
du choix entre les deux modèles ne présente que peu d'importance
bien que Amemiya (1981, cité dans Gujarati, 2004) affirme qu'il existe
des différences entre eux. De ce fait, nous avons choisi, dans le cadre
de ce travail, d'utiliser un modèle logit pour pouvoir identifier les
déterminants du revenu des agents de proximité dans l'aire
métropolitaine de P-au-P.
Présentation du modèle polytomique
ordonné Spécification du modèle
Cette étude concernant le mobile banking vise à
modéliser la variable revenu des agents de proximité en fonction
d'un certain nombre de caractéristiques sociodémographiques
(variables) et économiques (variables). Etant donné la nature des
données, le revenu de chaque agent est inobservable et seule son
appartenance à l'une des trois catégories est observée
:
- Yi=1 si le revenu moyen journalier de l'agent de
proximité i est élevé
- Yi=2 si le revenu moyen journalier de l'agent de
proximité i est moyen
- Yi=3 si le revenu moyen journalier de l'agent de
proximité i est faible
Selon l'étude de David et Legg (1975) portant sur
l'acquisition d'un bien immobilier, la variable polytomique yi=1, 2, 3 est
modélisée selon l'appartenance d'une variable yi* à trois
classes distinctes :
- Yi=1 si yi*< c1
- Yi=2 si c1 = yi* < c2, ? i = 1.., N
- Yi=3 si yi* > c2
où la variable latente44 yi* est
distribuée selon une loi normale N (xif3, ó2),
où le vecteur xi comporte l'ensemble des caractéristiques de
l'agent de proximité. On suppose que le vecteur xi ne comporte pas de
constante. Le problème consiste donc à estimer les
paramètres structurels c1, c2, ó et les K paramètres du
vecteur f3. Nous avons, dans ce cas, K+3 paramètres structurels à
estimer. Les probabilités associées aux trois modalités
sont définies de la façon suivante:
- Prob (yi = 1) = Prob (yi* < c1) = Prob (Xf3+ åi
<c1), car yi*~N (xif3, ó2)
=> Prob (yi* < c1) = F (c1/ó - xif3/ó),
avec F (.) la fonction de répartition de la loi logistique multinomiale
et Prob (yi = j), (i?j), étant la probabilité pour un agent de
proximité i de se trouver dans la catégorie de revenu j.
44 Une variable latente est une variable non
observable mais que l'on sait qu'elle existe.
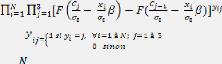
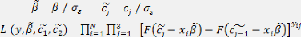
- Prob (yi=2) =Prob (c1 = yi* < c2) =Prob (c1= Xf3 +
åi < c2) = F (c2/a - xif3/a) - F (c1/a -
xif3/a).
- Prob (yi=3) = Prob (yi* > c2)= Prob (Xf3+ åi >
c2)=1- F (c2/a - xif3/a)=F (-c2/a + xif3/a)
Fonction de vraisemblance
Dans les modèles Logit ou Probit multinomial
ordonné nous ne pouvons pas observer le ratio de chance; ce qui rend
impossible l'utilisation d'un modèle MCO pour l'estimation des
paramètres. Dans ce cas, nous avons recours à la méthode
du maximum de vraisemblance car elle est une méthode d'estimation
alternative à la méthode des moindres carrés qui consiste
à trouver la valeur des paramètres qui maximisent la
vraisemblance des données. La vraisemblance en économétrie
est définie comme la probabilité jointe d'observer un
échantillon, étant donné les paramètres du
processus ayant généré les données. Pour le
modèle en question, dans le cadre de ce travail, la vraisemblance
associée à l'observation i s'écrit:
=
L (y, f3, c1, c2, a)
Avec
Où représente le nombre d'individus ou le nombre
d'agents de proximité interrogés et 3 étant le nombre de
modalités de la variable qualitative , F(.) est la fonction de
répartition de la loi


logistique. Avec, par convention, et
La procédure du maximum de vraisemblance fournit alors une
estimation pour les K + 2
paramètres , et . Dès lors, on ne peut pas dans ce
cas identifier la variance a du fait de la
normalisation imposée par le choix de la distribution
normale. Par conséquent, l'estimation de ce modèle ne permet pas
d'identifier les paramètres de seuil c1, c2 et les paramètres f3,
mais
seulement les transformées , et .
Avec = et = . La fonction de vraisemblance devient alors:
=
75 | P a g e
Définition des variables du
modèle
Dans cette partie du travail, il convient de définir
les variables qui rentrent dans l'estimation du modèle logit
multinomial. Les variables sociodémographiques ont surtout
été tirées de notre cadre théorique. Par contre,
celles d'ordres économiques ont été prises en compte suite
à une
76 | P a g e
visite exploratoire réalisée auprès de
quelques agents de proximité évoluant dans l'aire
métropolitaine de P-au-P. Toutes les variables considérées
dans le cadre de cette étude sont catégorielles.
Ainsi, la variable sous-étude est le revenu journalier des
agents de proximité notée REMOY et
est définie comme suit:
Yi = 1 si le revenu moyen journalier de l'agent est
élevé
Yi = 2 si le revenu moyen journalier de l'agent est de niveau
moyen
Yi = 3 si le revenu moyen journalier de l'agent est faible
Toutes les variables de l'étude ne seront pas
considérées dans l'analyse multivariée. Nous n'avons pris
en compte que les variables de l'analyse bivariée en vue de
vérifier les résultats trouvés. Elles sont
subdivisées en deux groupes :
- Les variables sociodémographiques
- Les variables dites économiques
Les variables
sociodémographiques
? Groupe d'âge de l'agent
Plusieurs études ont révélé qu'il
existe une relation de dépendance entre l'âge et le revenu. En
effet, l'étude menée par Amisial Ledix et Clermont Dieuconserve
portant sur les déterminants de revenu des conducteurs de Moto-Taxis aux
Gonaïves a montré que la tranche d'âge 20-24 ans a un impact
négatif sur le revenu journalier net des conducteurs contrairement
à celle de Rose Anne Dévlin (2001) qui, à partir de son
modèle Probit, a pu faire ressortir l'incidence de la variable Age,
prise quantitativement, sur le revenu. Elle comporte trois modalités :
moins de 30 ans, entre 30 et 35 ans, plus de 35 ans. Donc, nous créons
deux variables Dummy qui sont :
- Groupag1=1 si l'agent de proximité à moins de
30 ans et 0 sinon.
- Groupeag2=1 si l'agent de proximité a plus de 35 ans
et 0 sinon.
La catégorie de référence est donc le
groupe d'âge « entre 30 et 35 ans ».
? Niveau d'instruction
Dès que nous parlons de Niveau d'instruction, nous
faisons référence à l'investissement au capital humain car
ce dernier se définit, d'après Gary Becker45, comme
étant l'ensemble des connaissances et compétences dont on peut
tirer un revenu par le travail. Par ailleurs, l'étude de
45 Les fondements théoriques du Capital
humain écrit en 1964 par Gary Becker, Prix Nobel d'économie 1992
77 | P a g e
Sébastien LAURENT46 montre qu'il y a un lien
étroit entre le niveau d'éducation et l'obtention d'un emploi.
Donc, quant le niveau d'éducation augmente, l'agent de proximité
a beaucoup plus de chance d'accroître son revenu. Par conséquent,
nous nous attendons à un signe positif entre le revenu et le niveau
d'instruction. Le niveau d'instruction comporte trois modalités:
Universitaire, secondaire et professionnel. De ce fait, les dummy
créés à partir de cette dernière sont:
- Nivp= 1 si l'agent de proximité est de niveau
professionnel et 0 sinon
- Nivs=1 si l'agent de proximité est de niveau secondaire
et 0 sinon.
Le niveau Universitaire est retenu comme modalité de
référence d'après le processus de création des
variables dichotomiques.
? Catégories socioprofessionnelles
Il existe un lien naturel entre Catégories
socioprofessionnelles et Niveau d'éducation.
Donc, nous pouvons nous attendre à un signe positif entre le revenu et
la catégorie socioprofessionnelle. Cette variable compte six
modalités. De ce fait, nous avons défini cinq variables Dummy qui
nous permettront de mesurer l'effet de chaque modalité sur la variable
d'intérêt. Les Dummy sont :
- Catspl=1 si l'agent de proximité exerce une
profession libérale et 0 sinon
- Catsent=1 si l'agent de proximité est un entrepreneur
et 0 sinon.
- Catsar=1 si l'agent de proximité est soit un artisan,
soit un commerçant ou un agriculteur et 0 sinon.
- Catsaut =1 si l'agent de proximité pratique une
activité professionnelle autre que celles précitées et 0
sinon.
La modalité retenue comme catégorie de
référence est « employé » car
cette dernière à une plus grande représentativité
en termes de nombre d'agents exerçant une profession.
? Nombre de personnes en charge
A l'instar de l'étude de Sébastien LAURENT, le
nombre d'enfants ou le nombre de personnes en charge semble jouer
négativement sur le revenu des agents de proximité du M-Banking.
A mesure que le nombre de personnes en charge augmente, les dépenses
familiales vont croître. Ce qui aura, à coup sûr, une
incidence négative sur le revenu des agents. Le nombre de
personnes en charge noté « nper » est une variable
qualitative ayant trois modalités. De ce fait, nous avons
créé deux dummy permettant de mettre en évidence l'effet
de chacune des modalités sur la variable expliquée. Ces dummy
sont :
- Nper1=1 si l'agent de proximité a moins de deux
personnes et 0 sinon
- Nper2 =1 si l'agent de proximité a plus de 5 enfants
et 0 sinon
46 Capital humain, emploi et salaire en Belgique et
ses régions. Reflets et perspectives de la vie
économique, 2001/1 Tome XL, p. 25-36. DOI :
10.3917/rpve.401.0025
78 | P a g e
La modalité 3 à 5 personnes est
considérée comme catégorie de référence pour
les mêmes raisons évoquées précédemment.
? Nombre d'années dans la pratique des
affaires
Cette variable tient compte de l'expérience de l'agent
de proximité dans la pratique des affaires. Elle comporte trois
modalités. A partir de ces dernières, nous allons créer
deux variables dummy qui sont :
- Nbpa1=1 si l'agent de proximité a moins de 5 ans dans la
pratique des affaires et 0 sinon
- Nbpa2=1 si l'agent de proximité a plus de 10 ans dans la
pratique des affaires et 0 sinon La modalité « 5 à 10 ans
» est prise comme référence du fait de sa plus grande
représentativité en termes d'agents ayant une certaine
expérience en affaires.
Les variables dites économiques ?
Liquidité disponible
Pour un meilleur fonctionnement du service, l'agent doit
toujours disposer de la liquidité pour faire face à la demande de
retrait de cash. Un manque de liquidité peut en quelque sorte affaiblir
la clientèle. Ce qui pourrait engendrer une incidence néfaste sur
la rentabilité de l'entreprise donc sur le revenu des agents de
proximité. Cette variable dite dichotomique a pour valeur 1 si l'agent
de proximité a de l'argent disponible pour faciliter les transactions de
retrait et 0 sinon. Son appellation dans le modèle est « Liquidis
».
Justification de la catégorie de
référence
L'Institut National de la Statistique et des Etudes
Economiques(INSEE), dans un document titré « L'Econométrie
et l'Etude des Comportements : Présentation et mise en oeuvre de
modèles de régression qualitatifs »47, traite de
l'utilité et du choix de la catégorie de référence
par le biais de D. LE BLANC, S. LOLLIVIER, M. MARPSAT et D. VERGER. Il est
écrit dans le document qu'aucun critère mathématique ne
dicte le choix de la situation de référence et qu'on se laissera
guider par des impératifs « esthétiques » : il est plus
simple de choisir comme situation de référence une situation
courante. Ainsi, chaque lecteur acceptera comme naturel le choix qui lui est
proposé et le commentaire sera facilité par le fait que l'on
opposera des « minorités » bien caractérisées
à la population plus « standard ». Le précepte conduira
souvent à prendre comme référence la situation «
modale » (modalité rassemblant le plus d'effectifs) mais il ne
s'agit en
47 Document paru en Janvier 2000
79 | P a g e
aucun cas d'une obligation. Rappelons toutefois qu'il est
dangereux de choisir une modalité de référence ayant des
effectifs trop faibles. Outre la perte de précision déjà
mentionnée, cela peut entraîner un défaut de convergence.
Ceci étant, une référence ainsi choisie pour chacun des
critères peut conduire à une intersection des situations modales
très minoritaire dans l'échantillon. Dans le cadre de cette
étude, les catégories de référence ont
été choisies en accordant priorité aux situations
modales.
La validation des résultats de
l'estimation
? Le pseudo R2 détermine le pouvoir
prédictif du modèle, c'est-à-dire la contribution du
modèle dans l'explication du revenu des agents de proximité.
? Par ailleurs, le modèle logit multinomial fournit
pour chaque variable introduite dans l'équation une probabilité
qui indique le niveau de signification du paramètre qui lui est
associé. Ainsi, nous allons vérifier la significativité
individuelle des paramètres de chacune des variables du modèle
à travers le test de Wald (Voir
Annexe).
? La significativité globale du modèle va
être mesurée à travers le test du rapport des
maxima de vraisemblance (Voir Annexe). La statistique LRT (Likelihood
Ratio Test) correspond alors tout simplement à l'écart des
log-vraisemblance.
? L'écart de risque est calculé à partir
du rapport de cote appelé en anglais Odds ratio ou OR.
Lorsque le rapport de cote est inférieur à 1, les agents de
proximité ayant la caractéristique de la modalité
considérée de la variable explicative ont ((1 -OR)*100) % moins
de risque (ou de chance) que leurs homologues de la modalité de
référence de réaliser l'événement. Lorsque
le rapport de risque est supérieur à 1, cela signifie que les
agents appartenant à la modalité considérée de la
variable explicative courent OR fois plus le risque de subir
l'évènement ou ((OR - 1)*100) % fois moins le risque de subir cet
évènement.
? En dernier lieu, nous analysons les effets marginaux qui
peuvent être définis comme étant la sensibilité de
la probabilité de la variable explicative yi=1 par rapport à la
variation des variables indépendantes xi. Donc, les effets
marginaux s'écrivent mathématiquement de la manière
suivante :
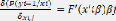
f3 étant les coefficients associés aux variables
indépendantes xi qui indiquent le signe des relations
estimées.
Cette équation dépend de xi et de la forme de la
fonction. Donc, pour le modèle Logit, cette
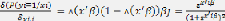
fonction s'écrit comme suit: f3j. Avec A (.) la
fonction de répartition de la loi logistique.
80 | P a g e
Les résultats de l'estimation du modèle
initial
Les résultats du modèle logit multinomial
réalisé sur SAS sont présentés dans le tableau
ci-dessous :
(Modèle initial)
|
Parameter
|
DF
|
Estimate
|
Standard Error
|
Wald Chi-Square
|
Pr > ChiSq
|
|
Intercept 1
|
1
|
-6.3425
|
4.2559
|
2.221
|
0.1361
|
|
Intercept 2
|
1
|
2.7526
|
4.5901
|
0.3596
|
0.5487
|
|
Comcar
|
1
|
3.6008
|
2.691
|
1.7905
|
0.1809
|
|
Compet
|
1
|
-1.1223
|
3.3433
|
0.1127
|
0.7371
|
|
Comcit
|
1
|
1.2306
|
2.1947
|
0.3144
|
0.575
|
|
Comtar
|
1
|
3.3640
|
2.8862
|
1.3586
|
0.2438
|
|
Compaup
|
1
|
-2.2547
|
1.8473
|
1.4897
|
0.2223
|
|
Groupag1
|
1
|
-0.9737
|
2.9519
|
0.1088
|
0.7415
|
|
Groupeag2
|
1
|
1.7025
|
2.3827
|
0.5106
|
0.4749
|
|
Smcel
|
1
|
1.5061
|
1.7741
|
0.7207
|
0.3959
|
|
Smfi
|
1
|
-1.0213
|
2.4922
|
0.1679
|
0.682
|
|
Smautre
|
1
|
-7.7398
|
4.6583
|
2.7606
|
0.0966
|
|
Nivp
|
1
|
2.4308
|
1.6554
|
2.1562
|
0.142
|
|
Nivs
|
1
|
-1.3317
|
1.7497
|
0.5793
|
0.4466
|
|
Catspl
|
1
|
1.6343
|
1.8345
|
0.7937
|
0.373
|
|
Catsent
|
1
|
-0.1339
|
1.8728
|
0.0051
|
0.943
|
|
Catsaut
|
1
|
4.7629
|
3.1656
|
2.2638
|
0.1324
|
|
**Catsar
|
1
|
5.4027
|
2.6424
|
4.1803
|
0.0409
|
|
Nbpa1
|
1
|
-0.5238
|
1.3466
|
0.1513
|
0.6973
|
|
Nbpa2
|
1
|
-4.3184
|
2.4765
|
3.0406
|
0.0812
|
|
Nper1
|
1
|
2.5176
|
1.9221
|
1.7156
|
0.1903
|
|
Nper2
|
1
|
-1.8360
|
2.1994
|
0.6968
|
0.4038
|
|
**Liquidis
|
1
|
3.0885
|
1.5583
|
3.9281
|
0.0475
|
* Significatif à moins de 1% Likelihood ratio = 74.2253
Pr> Chsq: 0.0003
**Significatif à moins de 5% AIC 136.59 N: 82
BIC 141.404 Pseudo-R2=0.4402
Source : Enquête réalisée dans le cadre de ce
travail, Août 2012
81 | P a g e
VI.3.2.- Validation des résultats du modèle
VI.3.2.1.- Analyse du pseudo-R2
Le pseudo-R2 est de 0.4402, ce qui est un
résultat acceptable en termes de qualité d'ajustement du
modèle. De ce fait, nous pouvons dire que les variables
indépendantes sont assez pertinentes dans l'explication du revenu des
agents de proximité.
| 

