1.2 La méthode des moindres carrés
ordinaires
1.2.1 Estimateur des moindres carrés ordinaires
(EMCO)
Du modèle complet :
yi = ao + a1xi,1 + ... +
âpxi,p + åi
On va estimer les paramètres et obtiendra: yi =
âo+â1xi,1+...+âpxi,p
Les résidus estimés sont la différence entre
la valeur de y observée et estimée. Soit :
Définition åi yi yi
Le principe des moindres carrés consiste à
rechercher les valeurs des paramètres qui minimisent la somme des
carrés des résidus.
n n
Mémoire de Master II soutenu par : NGASSEU NOUPIE Elie

62
i=1 å2 1 ao,.,âp
i=1
min ? = min ? (yi - âo - â1xi,1 - ...
- âpxi,p)2
Ce qui revient à rechercher les solutions de = 0
Nous avons j = p + 1 équations, dites
équations normales, à résoudre.
La solution obtenue est l'estimateur des moindres
carrés ordinaires, il s'écrit :
Théorème - â = (X'X)-1 X'Y est
l'estimateur qui minimise la somme des carrés des résidus.
Avec X' la transposée de X
Démonstration
· = 0
· En passant l'opérateur de dérivation dans
la somme, on a j = 0, ...,p :
. (yi - âo - â1xi,1 - ... -
âpxi,p) = 0
· Il suffit alors d'écrire cette dernière
relation sous forme vectorielle :
X'(Y - Xâ) = 0
· X'Xâ = X'Y
· â = (X'X)-1 X'Y
Remarques :
· Pourquoi minimiser la somme des carrés
plutôt que la simple somme ? Cela tient, en partie, au fait que la
moyenne de ces résidus sera 0, et donc que nous disposerons de
résidus positifs et négatifs. Une simple somme les annulerait, ce
qui n'est pas le cas avec les carrés.
· Si les xj sont centrés, X'X correspond
à la matrice de variance - covariance des variables exogènes ;
s'ils sont centrés et réduits, X'X correspond à la matrice
de corrélation.
· Interprétation géométrique,
algébrique et statistique de l'estimateur MCO.
· L'estimateur MCO correspond à une projection
orthogonale du vecteur Y sur l'espace formé par les vecteurs X.
· L'estimateur MCO correspond à une matrice
inverse généralisée du système Y = Xa pour
mettre a en évidence. En effet, si on prémultiplie par
l'inverse généralisé
(X'X)-1X' on a : (X'X)-1 X'Y =
(X'X)-1 X'Xa = a

63
Mémoire de Master II soutenu par : NGASSEU NOUPIE Elie
? L'estimateur MCO est identique à l'estimateur obtenu par
le principe du
maximum de vraisemblance.
1.2.2 Propriétés des estimateurs
Si les hypothèses initiales sont respectées,
l'estimateur des MCO (Moindres Carrés Ordinaires) possède
d'excellentes propriétés.
A. Propriété en échantillons
finis
Propriété - L'estimateur MCO est sans biais,
c'est-à-dire. E(â) = a, sous les hypothèses H1, H2
et H5.
Preuve
E[â] = E [(X'X)-1 X'Y]
= E [a+(X'X)-1 X'å]
= a + (X'X)-1 X' E [å] sous H1 et
H5
= a + 0 sous H2
= a
Cette propriété se base seulement sur les
hypothèses d'espérance nulle des résidus. La
présence d'autocorrélation ou
d'hétéroscédasticité n'affecte pas ce
résultat.
Propriété - l'estimateur MCO est le meilleur
estimateur linéaire sans biais, sous les hypothèses H1
à H5
C'est-à-dire qu'il n'existe pas d'estimateur
linéaire sans biais de a qui ait une variance plus petite.
Cette propriété en anglais est désignée par BLUE,
pour best linear unbiased estimator. La preuve est donnée par
le Théorème de Gauss-Markov.
Propriété - l'estimateur MCO est distribué
selon une loi normale â ~ N (a,ó2 (X'X)-1) sous les
hypothèses H1, H2, et H6
B. Propriétés
asymptotiques
p
Propriété - l'estimateur MCO est convergent en
probabilité, c'est-à-dire â a, sous les
hypothèses H6, et H8 Preuve
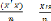
? Récrivons : â = a + ( )-1
64
? Prenons la limite en probabilité : plim â = a
+ plim (
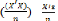
-1 )

Mémoire de Master II soutenu par : NGASSEU NOUPIE Elie
? Comme en a fait l'hypothèse 118 que tend vers une
matrice Q définie positive, la
limite devient :
Plim â = a + Q-1 plim ( )
? Il reste alors à étudier le comportement de .
Sous l'hypothèse 116, (ou plutôt sur une
forme plus restrictive E[xiåi] = 0) on peut
montrer que son espérance est nulle, et que sa variance tend
asymptotiquement vers 0, ce qui implique qu'il converge en moyenne quadratique
vers 0, et donc qu'il converge en probabilité vers 0.
? On a donc finalement :
Plim â = a + Q-1 . 0 = a
Propriété - l'estimateur MCO suit asymptotiquement
une loi normale â ~ N (a, ) sous les
hypothèses H1 à H5 et H8
Après cette présentation de notre méthode
d'estimation de l'incidence de productivité globale des facteurs sur la
pauvreté, il convient de présenter les estimations et nos
résultats.
| 

