Analyse de l'accès à l'éducation à Kinshasa( Télécharger le fichier original )par Hence Mathodi Lumbu Université de Kinshasa - Licence 2007 |

Chapitre troisième :DETECTION DES VARIABLES EXPLICATIVES DE L'EDUCATION ET APPLICATION DE LA METHODE CARTDans ce chapitre, nous présenterons une analyse empirique sur notre échantillon issu de l'enquête nationale 1-2-3. Ce chapitre contient l'essentiel de notre travail en terme d'explication du phénomène que nous étudions. Ce chapitre commence par une brève présentation de la méthode CART et son application dans le cas de la ville province de Kinshasa et sera bouclé par l'interprétation des résultats de notre recherche et une petite comparaison avec les résultats des régressions de type « logit » à la dernière section.
1. la méthode CART27(*) La régression consiste à produire un modèle qui permet de prédire ou d'expliquer les valeurs d'une variable à prédire (endogène) à partir des valeurs d'une série de variables prédictives (exogènes). La régression linéaire est certainement l'approche la plus connue en analyse des données, mais d'autres méthodes, moins connues en Économétrie mais plus populaire dans le domaine d'apprentissage automatique, permettent de remplir cette tâche. C'est le cas de l'arbre de décision qui de son coté est l'outil par excellence d'aide à la décision et à l' exploration des données. Il permet de modéliser simplement, graphiquement et rapidement un phénomène mesuré plus ou moins complexe. Sa lisibilité, sa rapidité d'exécution et le peu d'hypothèses nécessaires à priori expliquent sa popularité actuelle dans les universités occidentales. Dans le domaine d'aide à la décision ( informatique décisionnelle et datawarehouse) et du data mining, certains algorithmes produisent des « arbres de décision », utilisés pour répartir une population d'individus (de clients par exemple) en groupes homogènes, selon un ensemble de variables discriminantes (l'âge, la catégorie socio-professionnelle, ...) et en fonction d'un objectif fixé et connu (chiffres d'affaires, réponse à un mailing, ...). À ce titre, cette technique fait partie des méthodes d' apprentissage supervisé. Il s'agit de prédire avec le plus de précision possible les valeurs prises par la variable à prédire (objectif, variable cible, variable d'intérêt, attribut classe, variable de sortie, ...) à partir d'un ensemble de descripteurs (variables prédictives, variables discriminantes, variables d'entrées, ...). Cette technique est autant populaire en statistique qu'en apprentissage automatique. Son succès réside en grande partie à ses caractéristiques : · lisibilité du modèle de prédiction, l'arbre de décision, fourni. Cette caractéristique est très importante, car le travail de l'analyste consiste aussi à faire comprendre ses résultats afin d'emporter l'adhésion des décideurs ; · capacité à sélectionner automatiquement les variables discriminantes dans un fichier de données contenant un très grand nombre de variables potentiellement intéressantes. En ce sens, un arbre de décision constitue une technique exploratoire privilégiée pour appréhender de gros fichiers de données. C'est dans le souci d'appliquer ces méthodes qui ne sont pas vraiment d'usage dans nos Universités congolaises que s'inscrit cette section de notre travail. La méthode CART a été développée par Brieman, Friedman, Olshen et Stone en 1984. Cette méthode se fonde sur deux idées clés : · Partitionnement récursif d'un ensemble de variables indépendantes ; · Elagage (pruning) en utilisant des données de validation. Considérons un ensemble de variables
catégorielles Par exemple soit la variable L'idée est de créer n rectangles de telle sorte que l'ensemble de données contenu dans un rectangle soit homogène c'est-à-dire, contient des éléments qui ont les mêmes propriétés. Un exemple est donné par le graphique 1 avec deux variables X1 (income ou revenus) et x2 (lot size ou surface en pieds par mètre carré). Ces variables composées des propriétaires (owners) et des non-propriétaires (non-owners). Graphique 9 : représentation des séries
L'application de l'algorithme CART va diviser l'espace (X1, X2) en deux sous rectangles à partir d'une valeur telle que les deux sous rectangles soient les plus homogènes que possible ( voir graphique 2). Pour choisir la variable de segmentation sur un sommet, l'algorithme s'appuie sur une technique très fruste : il teste toutes les variables potentielles et choisit celle qui maximise un critère donné. Il faut donc que le critère utilisé caractérise la pureté (ou le gain en pureté) lors du passage du sommet à segmenter vers les feuilles produites par la segmentation. Il existe un grand nombre de critères informationnels ou statistiques, les plus utilisés sont l'entropie de Shannon et le coefficient de Gini et leurs variantes. Graphique 10 : le premier partitionnement
A noter que la division a créé deux rectangles qui sont plus homogènes que le rectangle avant la division (Split). Le rectangle supérieur contient des points qui sont davantage des propriétaires (9 propriétaires et 3 non propriétaires) tandis que le rectangle inférieur contient davantage de non propriétaires (9 non propriétaires et 3 propriétaires). Pour décider de cette division particulière, CART a examiné chaque variable et toutes les valeurs possibles de division pour chaque variable de façon à trouver la meilleure division. Les meilleures valeurs de division pour une variable sont simplement les points-milieux entre des pairs de valeurs consécutives pour la variable. Ces points de division sont rangés d'après la façon dont ils réduisent l'«impureté» (hétérogénéité de composition). La réduction de l'impureté est définie par l'impureté du rectangle avant la division moins la somme des impuretés des deux rectangles qui résultent de la division. On peut écrire mathématiquement : IG (avant sep.)-[IG (fils1)+IG (fils2)] Avec: § IG (avant sep.): l'impureté du rectangle avant la division § IG (fils1) + IG (fils2) : la somme des impuretés des deux rectangles qui résultent de la division. Il existe plusieurs manières de mesurer l'impureté. On va décrire la mesure la plus populaire de mesurer cette impureté: l'indice de Gini. Si on dénote les classes par k, k=1, 2, ..., C, où C est le nombre total de classes pour la variable y, l'indice d'impureté de Gini pour le rectangle A est défini par :
Où Les divisions des variables vont se poursuivre jusqu'à ce que tous les rectangles deviendront homogènes. On peut voir alors comment le partitionnement récursif permet d'affiner l'ensemble des rectangles pour devenir plus purs de la manière dont procède l'algorithme. Le graphique 3 illustre le dernier partitionnement avec 9 rectangles purs. On note que chaque rectangle est pur, il contient les points de données de juste une des deux classes. Graphique 11 : nème partitionnement
La raison pour laquelle la méthode est appelée algorithme d'arbre de classification est que chaque division peut être figurée comme la division d'un noeud en deux noeuds successeurs. La première division est montrée comme un branchement du noeud racine de l'arbre. Il est utile de noter que le type d'arbres développés par CART (appelés arbres binaires) ont la propriété que le nombre de noeuds feuilles est exactement un de plus que le nombre de noeuds de décision. La seconde idée clé dans la procédure CART, est celle qui utilise des données de validation pour élaguer à posteriori l'arbre qui a grandi à partir des données d'entraînement utilisant des données de validation indépendantes. Cela a été une vraie innovation. Auparavant, les méthodes ont été développées de telle sorte qu'elles étaient basées sur l'idée d'un partitionnement récursif mais elles ont utilisé des règles pour éviter un grossissement excessif de l'arbre et le sur-apprentissage (over-fitting) des données d'entraînement. L'objectif étant de produire des groupes homogènes lors de la construction d'un arbre, il paraît naturel de fixer comme règle d'arrêt de construction de l'arbre la constitution de groupes purs du point de vue de la variable à prédire. En effet, nous travaillons souvent sur un échantillon que l'on espère représentatif d'une population. Tout l'enjeu est donc de trouver la bonne mesure entre capter l'information utile, correspondant réellement à une relation dans la population, et ingérer les spécificités du fichier sur lequel on est en train de travailler (l'échantillon dit d'apprentissage), correspondant en fait à un artefact statistique. Autrement dit, il ne faut jamais oublier que la performance de l'arbre est évaluée sur les données mêmes qui ont servi à sa construction : plus le modèle est complexe (plus l'arbre est grand, plus il a des branches, plus il a des feuilles, plus l'on court le risque de voir ce modèle incapable d'être extrapolé à de nouvelles données, c'est-à-dire de rendre compte de la réalité que nous essayons justement d'appréhender). En effet, si dans un cas extrême on décide de faire pousser notre arbre le plus loin possible, nous pouvons obtenir un arbre composé d'autant de feuilles que d'individus dans l'échantillon d'apprentissage. Notre arbre ne commet alors aucune erreur sur cet échantillon puisqu'il en épouse toutes les caractéristiques : performance égale à 100%. Dès lors que l'on applique ce modèle sur de nouvelles données qui par nature n'ont pas toutes les caractéristiques de notre échantillon d'apprentissage (il s'agit simplement d'un autre échantillon) sa performance va donc se dégrader pour à la limite se rapprocher de 0%. Ainsi, lorsque l'on construit un arbre de décision, on risque ce que l'on appelle un « sur-ajustement » du modèle c'est-à-dire que le modèle semble performant (son erreur moyenne est très faible) mais il ne l'est en réalité pas du tout. Il va nous falloir trouver l'arbre le plus petit possible ayant la plus grande performance possible. Plus un arbre est petit et plus il sera stable dans ses prévisions futures (en statistiques, le principe de parcimonie prévaut presque toujours) ; plus un arbre est performant, plus il est satisfaisant pour l'analyste. Il ne sert à rien de générer un modèle de très bonne qualité, si cette qualité n'est pas constante et se dégrade lorsque l'on applique ce modèle sur un nouvel ensemble de données. Autrement dit, pour éviter un sur-ajustement d'un arbres (c'est également vrai de tous les modèles mathématiques que l'on pourrait construire), il convient d'appliquer un « principe de parcimonie » et de réaliser des « arbitrages performance/complexité » des modèles utilisés. À performance comparable, on préfèrera toujours le modèle le plus simple, si l'on souhaite pouvoir utiliser ce modèle sur de nouvelles données totalement inconnues. Pour réaliser cet arbitrage performance/complexité des modèles utilisés il faut, évaluer la performance d'un ou de plusieurs modèles sur les données qui ont servi à sa construction (l'échantillon d'apprentissage), mais également sur ce que l'on appelle un (ou plusieurs) échantillon de test, c'est-à-dire des données à notre disposition mais que nous décidons volontairement de ne pas utiliser dans la construction de nos modèles[]. Tout se passe comme si ces données de test étaient de nouvelles données, la réalité. C'est notamment la stabilité de la performance de nos modèles sur ces deux types d'échantillon nous permettra de juger de son sur-ajustement potentiel et donc de sa capacité à être utilisé avec un risque d'erreur maîtrisé dans des conditions réelles où les données ne sont pas connues à l'avance. Dans le cas des arbres de décisions, plusieurs types de solutions algorithmiques ont été envisagées pour tenter d'éviter autant que possible un problème de sur-ajustement potentiel des modèles : il s'agit des techniques dites de pré ou de post élégage des arbres. Certaines théories statistiques (voir les travaux du mathématicien russe Vladimir Vapnik) vont même jusqu'à avoir pour objet de trouver l'optimum entre l'erreur commise sur l'échantillon d'apprentissage et celle commise sur l'échantillon de test. La théorie de Vapnik Chervonenkis, «Structured Risk Minimization (SRM)», en utilisant une variable appelée « VC dimension », fournit une modélisation mathématique parfaite de la détermination de l'optimum d'un modèle, utilisable par conséquent pour générer des modèles qui assurent le meilleur compromis entre qualité et robustesse du modèle. Dans tous les cas, ces solutions algorithmiques sont complémentaires des analyses de performances comparées et de stabilité effectuées sur les échantillons d'apprentissage et de test. La première stratégie utilisable pour éviter un sur-ajustement massif des arbres de décision consiste à proposer des critères d'arrêt lors de la phase d'expansion. C'est le principe du pré-élagage. Nous considérons par exemple qu'une segmentation n'est plus nécessaire lorsque le groupe est d'effectif trop faible ; ou encore, lorsque la pureté d'un sommet a atteint un niveau suffisant, nous considérons qu'il n'est plus nécessaire de le segmenter ; autre critère souvent rencontré dans ce cadre, l'utilisation d'un test statistique pour évaluer si la segmentation introduit un apport d'information significatif quant à la prédiction des valeurs de la variable à prédire. La seconde stratégie consiste à construire l'arbre en deux temps : produire l'arbre le plus pur possible dans une phase d'expansion en utilisant une première fraction de l'échantillon de données (échantillon d'apprentissage à ne pas confondre avec la totalité de l'échantillon, en anglais « growing set » est moins ambigu) ; puis effectuer une marche arrière pour réduire l'arbre, c'est la phase de « post-élagage », en s'appuyant sur une autre fraction des données de manière à optimiser les performances de l'arbre. Selon les logiciels, cette seconde portion des données est désignée par le terme d'échantillon de validation ou échantillon de test, introduisant une confusion avec l'échantillon utilisé pour mesurer les performances des modèles. Le terme qui permet de le désigner sans ambiguïté est « échantillon d'élagage », traduction directe de l'appellation anglo-saxonne « pruning set ». Une fois l'arbre construit, il faut préciser la règle d'affectation dans les feuilles. A priori, si elles sont pures, la réponse est évidente. Si ce n'est pas le cas, une règle simple est de décider comme conclusion de la feuille la classe majoritaire, celle qui est la plus représentée. Cette technique très simple est la procédure optimale dans un cadre très précis : les données sont issues d'un tirage aléatoire simple dans la population Généralement, les modèles logistiques sont utilisés pour la détermination des variables explicatives de l'accès. Mais plusieurs remarques sont formulées à l'attention de ces modèles. 1. Ils ne permettent pas de faire des inférences correctes s'il y a des variables inobservées et qui déterminent simultanément les deux variables dont on cherche à déterminer la corrélation : exemple des préférences intergénérationnelles du ménage pour l'éducation agissent tant sur l'éducation des parents que sur ceux des enfants ; 2. Ils ne permettent pas de faire des inférences correctes en cas de présence d'effets d'interaction entre les variables. Dans ces cas de figure, on est en présence d'endogénéités qui rendent biaisées les estimations, si on n'inclut pas une variable instrumentale approprié. Avec la méthode CART ce problème d'endogénéités ne se pose plus car : 3. CART est simple, il ne pose aucune hypothèse sur la distribution des séries à utiliser ; 4. CART permet non seulement d'identifier les variables explicatives de l'accès, mais aussi de les classer par ordre d'importance. 2. analyse empirique des données : Dans cette dernière section de notre travail, il sera essentiellement question de déterminer les variables qui expliquent l'accès à l'éducation au sein des ménages. Cette analyse s'intéressera seulement à 1911 (soit 87,4%) individus de notre échantillon qui ont fréquenté au moins l'école primaire. Pour ce faire, nous estimerons d'abord par la méthode de maximum de vraisemblance un modèle logit qui nous permettra de sélectionner les variables significatives de ce phénomène (accès à l'éducation dans notre cas) qui seront comparés avec celles qui seront déterminants après construction de notre arbre de régression par la méthode CART. Ensuite suivront l'interprétation des résultats globaux de l'étude et une conclusion qui viendront mettre fin respectivement à notre chapitre et à notre travail tout entier. L'étude de l'économétrie des variables qualitatives date des années 1940-1950. Ses premières applications ont été menées dans le domaine de la biologie, la sociologie, et de la psychologie. Ce n'est finalement que récemment, que ces modèles (probit, logit et tobit) ont été utilisés pour décrire les données économiques avec notamment les travaux de Mac-Fadden(1971) et Heckman(1976). Le modèle de choix binaire ou dichotomique de type « logit » admet pour variable expliquée, non pas un codage quantitatif associé à la réalisation d'un événement (comme dans le cas d'une spécification binaire), mais la probabilité de cet événement, conditionnellement aux variables exogènes. Ainsi on considère le modèle suivant :
Dans le cas du modèle logit, la fonction de
répartition F(.) appelé aussi courbe en S, correspond à la
fonction logistique
Il existe certaines propriétés du modèle
logit qui sont particulièrement utiles pour simplifier les calculs ainsi
que l'interprétation économique des résultats d'estimation
des paramètres â associés aux variables explicatives. Tout
d'abord, si l'on note On peut écrire cette équation sous la
forme : D'où :
Ce qui donne enfin : Etant donné que le modèle logit définit
la probabilité associée à l'événement Avec a. Estimation : La spécification binaire d'une variable expliquée soulève certains problèmes pour l'application de la méthode des moindres carrés ordinaire afin d'estimer le modèle. 2. Le choix du codage de la variable est totalement arbitraire. Ce qui fait que le paramètre â du modèle n'est pas interprétable ; 3. L'erreur ne peut prendre que deux valeurs, elle suit donc une loi discrète, l'hypothèse de normalité des erreurs est donc violée ; 4. La variance des erreurs est 5. Enfin, nous devons imposer une contrainte au
modèle : Tous ses éléments indiquent clairement que nous sommes dans l'impossibilité d'appliquer la méthode des MCO. Dans ce cas, les paramètres des modèles logistiques sont estimés par la méthode de maximum de vraisemblance (MV). b. Elasticité, effet marginal et odds ratio : 1. On définit l'élasticité
2. Si l'on note f(.) la fonction de densité des
résidus du modèle dichotomique logit, l'effet marginal
associé à la jième variable explicative
Puisque par définition f(.)>0, le signe de cette
dérivée est donc identique à celui de 3. De façon générale, la quantité
c. Interprétation des résultats : Les résultats s'interprètent de la manière suivante : · La signification des coefficients à l'aide du ratio z-statistique, · La significativité globale de l'ajustement ( · Le pseudo- Il est de coutume d'appliquer les modèles logit de choix binaire (ou encore modèles dichotomiques) dès que la variable à expliquer ne peut prendre deux modalités. Mais dans la pratique, une variable qualitative peut prendre aussi plusieurs modalités comme par exemple : le choix entre autant de candidats lors de la présidentielle de 2005 en RDC. Alors dans ce cas, les modèles à choix multiple sont exigés. Les modèles à choix multiple sont une généralisation des modèles binaires. Dans ces modèles la variable à expliquer, qualitative, n'est donc plus binaire (0 et 1), mais polytomique (ou multinomiale). Nous différencions, en fonction du type de la variable à expliquer les modèles ordonnés et les modèles non ordonnés. Dans ces modèles, les valeurs des coefficients des modèles ne sont pas directement interprétables en terme de propension marginale, seuls les signes des coefficients indiquent si la variable agit positivement ou négativement sur la variable latente28(*). Les résultats d'estimation s'apprécient de la même manière que pour les modèles de choix binaire. 3. Présentation des résultats : De ce qui suit, pour parvenir aux résultats de notre étude, cinq régressions logistiques ont été faites dont quatre sont de type binaires et un multinomiale ordonné. Enfin, nous avons construit un arbre de régression pour hiérarchiser les variables selon l'ordre d'importance dans l'explication du phénomène sous étude. · La première régression sur notre variable expliquée qui est le niveau d'étude atteint par l'enfant (m13b-ens) a porté sur l'enseignement primaire. La variable endogène qui avait quatre modalités (selon que (1) l'enfant a un niveau primaire, (2) niveau secondaire, (3) suit un programme non formel, (4) niveau universitaire) a été codifié binaire comme suit, 1 : l'enfant a un niveau primaire et 0 : autres niveaux. · La deuxième régression a porté sur le niveau secondaire et la variable endogène est codifiée comme suit, 1 : niveau secondaire et 0 : autres niveaux. · La troisième régression, 1 : l'enfant suit un programme non formel et 0 : autres niveaux. · La quatrième régression, 1 : niveau universitaire et 0 : autres niveaux. Pris globalement, tous les modèles sont statistiquement
valables, les Les valeurs estimées des paramètres d'un modèle logistique ne sont pas directement interprétables en terme de propensions marginales. C'est ainsi qu'on s'intéresse seulement à leurs signes. Un signe positif (négatif respectivement) indique qu'une augmentation de la variable explicative considérée augmente (baisse respectivement) la chance de scolariser un enfant dans le ménage. Toutefois pour mesurer et comparer les effets des variables explicatives sur la probabilité qu'un enfant soit scolarisé, nous avons calculé les effets marginaux, les élasticités et les cotes odds. Dans ce modèle, la statistique de la log vraisemblance
LR=305,96 avec une probabilité associée au Sur le plan économique, 1. la taille du ménage agit négativement sur l'éducation des enfants ; Les enfants issus de familles nombreuses ont moins de chance d'être scolarisé. 2. la télévision est un facteur qui influence négativement l'éducation au niveau primaire ; Les ménages qui ont au moins un téléviseur ont moins de chance de scolariser leurs enfants par rapport à ceux qui n'ont pas de téléviseur ; 3. le sexe de l'enfant et la religion de ses parents influencent positivement la probabilité de scolariser un enfant dans le ménage ; les garçons sont favorisés par rapport aux filles et plus un chef de ménage appartient à une confession religieuse, plus il augmente la chance de scolariser ses enfants. 4. le sexe et l'age du chef de ménage agissent négativement ; les chefs de ménage femmes ont moins de chance de scolariser leurs enfants par rapport aux hommes. Plus le chef de ménage est avancé en âge, moins ses enfants ont la chance d'être scolarisé. 5. le type d'école fréquenté par l'enfant agit positivement sur la probabilité d'être à l'école ; mais pour cela, l'école doit être de type « publique conventionnée ». Globalement, on dira que le type d'école fréquentée par l'enfant est significatif (le test en annexes donne p=0,0381). 6. le niveau d'étude du chef de ménage influence négativement la scolarisation des enfants au primaire ; les parents qui ont un niveau soit programme non formel, soit secondaire, soit universitaire ont moins de chance de scolariser leurs enfants au primaire. On dira ensuite, au regard des tableaux en annexes, l'augmentation d'une unité de taille de ménage baisse la chance que les enfants soient scolarisés au primaire de 0,95%, l'augmentation d'une unité d'école publique conventionnée augmente cette chance de 7%, le même raisonnement pour les autres variables. Enfin, trouver au moins une télévision dans un ménage a 0,595 fois plus de chance de se réaliser que de ne pas se réaliser. On a en plus 1,24 fois plus de chance de trouver un chef de ménage masculin dans un ménage que ne pas le trouver, un raisonnement similaire s'applique aux autres variables. Au niveau secondaire, la statistique de la log likelihood LR=161,51 avec une probabilité p=0,0000. De ce fait, on rejette l'hypothèse nulle d'égalité des coefficients associés aux variables. Le test Gof de Pearson donne une probabilité largement significative p=0,3080, le modèle est statistiquement validé. Sur le plan économique, toutes les variables sont significatives à 5% de signification, à l'exception du type d'école fréquentée par l'enfant qui le devient à 10%. Ces variables sont la taille du ménage, la télévision, l'âge et le sexe du chef de ménage,le type d'école fréquentée, l'éducation du chef de ménage et influencent positivement la probabilité de scolariser un enfant dans le ménage. Une augmentation d'une unité de taille de ménage augmente la chance qu'un enfant soit scolarisé au niveau secondaire de 0,8%, l'augmentation d'une unité de télévision augmente cette chance de 8,7%, l'augmentation d'une unité de chef de ménage masculin de son côté augmente cette probabilité de 21%, ainsi de suite. La chance de trouver au moins une télévision dans un ménage est de 1,43 fois plus de chance que ne pas le trouver, trouver un chef de ménage de sexe masculin dans un ménage a 2,359 fois plus de chance que ne pas le trouver. Enfin, trouver un chef de ménage de niveau secondaire a 1,1 fois plus de chance de se réaliser que ne pas se réaliser. Dans ce modèle, toutes les variables sont significatives à 5% de signification avec la statistique LR=30,30 associée à une probabilité p=0,0000, on rejette donc l'hypothèse nulle d'égalité des coefficients associés aux variables exogènes. Le test Gof de Pearson (avec une probabilité p=0,8658) justifie que le modèle est bon statistiquement. Du point de vue économique on voit que le statut d'occupation du logement et l'âge du chef de ménage influencent positivement l'éducation dans les ménages au niveau du programme non formel. La part du revenu consacrée à l'éducation a une influence négative. Plus cette part augmente, moins on a des préférences pour ces types de formation ; on préfère alors les formations formelles. Ces variables ont des effets marginaux très faibles sur l'éducation ; mais les cotes odds sont très élevées (1,447 pour le statut d'occupation du logement, 0,356 pour la part de revenu consacrée à l'enseignement, 1,053 pour l'âge du chef de ménage). Dans ce modèle, toutes les variables sont significatives au seuil de 5% avec LR=190,75 (p=0,0000). On rejette l'hypothèse nulle d'égalité des coefficients associés aux variables exogènes. Le test Gof de Pearson donne une probabilité p=0,3353. D'où le modèle est statistiquement bon. Dans ce modèle les variables télévision, part du revenu consacrée à l'éducation dans le ménage, les dépenses journalière du ménage, l'âge et l'éducation du chef de ménage (surtout universitaire), influencent positivement l'éducation. Par contre, la religion du chef de ménage et le type d'école fréquenté par l'enfant influencent négativement. L'augmentation d'une unité de type d'école diminue la probabilité de scolariser de 1,6%, l'augmentation d'une unité de télévision dans le ménage augmente cette probabilité de 2% au niveau universitaire. Enfin, avoir une télévision dans un ménage a plus de chance de se réaliser que de ne pas se réaliser, ainsi de suite. Pris ensemble, avec une variable endogène à quatre modalités, la régression de choix multiple avec le logiciel stata 9.2 nous donne le résultat suivant : La statistique de la log likelihood LR=30,30 avec p=0,0000. On rejette encore une dernière fois l'hypothèse nulle. Toutes les variables sont significatives à 10% de signification. D'où, le modèle est globalement bon. Le test Gof de Pearson donne une probabilité p=0,9000. On voit que la part du revenu consacré à l'enseignement influence négativement la probabilité qu'un enfant fréquente un quelconque niveau d'étude dans les ménages. Le statut d'occupation du ménage et l'âge du chef de ménage par contre influencent positivement. Cette régression donne le même résultat que le programme formel. La lecture du tableau 14 nous renseigne qu'il y a une seule variable qui est significative dans toutes les régressions. Les autres variables sont discriminées selon les niveaux d'enseignement à l'exemple de taille de ménage qui influence l'éducation au primaire et au secondaire seulement, pas ailleurs. La part du revenu consacré à l'enseignement n'influence que le programme non formel et le niveau universitaire, le sexe de l'enfant n'influence qu'au primaire. Nous devons retenir que les signes des coefficients changent par rapport au niveau d'étude considéré (voir tableau 14). La méthode CART donne un meilleur traitement aux variables d'étude que le font d'autres méthodes et les résultats d'estimation sont présentés sous forme d'algorithmes ou « arbre » dont « les branches » représentent les modalités des variables. Ce classement des variables est fait selon le degré d'homogénéité des modalités en deux sous groupes selon qu'elles augmentent ou diminuent la probabilité d'occurrence de l'événement sous étude. Dans notre étude c'est le niveau d'étude atteint par l'enfant. L'algorithme ci-dessous présente les résultats de notre étude : Algorithme d'arbre de régression par la méthode CART:
Classifier performances
* 27 Classification And Regression Tree de Breiman et al. * 28 Bourbonnais Regis, Econométrie, 6è édition, Dunod, 2005 |
| |||||||||||||||||||||||||||||||


 .
Le partitionnement récursif divise l'espace des p variables en n
rectangles qui ne se chevauchent pas. Cette division est accomplie
récursivement.
.
Le partitionnement récursif divise l'espace des p variables en n
rectangles qui ne se chevauchent pas. Cette division est accomplie
récursivement. et une valeur
et une valeur  de cette variable. On
trouve que le partitionnement où
de cette variable. On
trouve que le partitionnement où  <
<  et
et  >
> 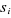 sépare bien les
données en deux ensembles disjoints. Ensuite une des deux parties est
à son tour divisée par une valeur de
sépare bien les
données en deux ensembles disjoints. Ensuite une des deux parties est
à son tour divisée par une valeur de  ou par la valeur d'une
autre variable. On aboutit à n rectangles si on continue la division n-1
fois.
ou par la valeur d'une
autre variable. On aboutit à n rectangles si on continue la division n-1
fois.


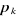 est la fraction
d'observations dans le rectangle A qui appartiennent à la classe k. On
note que I (A) = 0 si toutes les observations appartiennent à une classe
unique et I(A) est maximisé quand toutes les classes apparaissent en
proportion égales dans le rectangle A. Sa valeur maximale est
est la fraction
d'observations dans le rectangle A qui appartiennent à la classe k. On
note que I (A) = 0 si toutes les observations appartiennent à une classe
unique et I(A) est maximisé quand toutes les classes apparaissent en
proportion égales dans le rectangle A. Sa valeur maximale est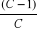 .
.
 Où F(.) est la fonction de répartition .
Où F(.) est la fonction de répartition .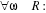


 , étant
donné la définition de la loi logistique, on remarque que
plusieurs égalités permettant de simplifier les calculs peuvent
être établies comme suit :
, étant
donné la définition de la loi logistique, on remarque que
plusieurs égalités permettant de simplifier les calculs peuvent
être établies comme suit :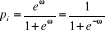
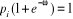



 , comme la valeur de la
fonction de répartition de la loi logistique considérée au
point
, comme la valeur de la
fonction de répartition de la loi logistique considérée au
point , on peut
écrire :
, on peut
écrire : 
 la probabilité relative du choix
la probabilité relative du choix .
. ce qui suggère de
fait une héteroscedasticité. Cependant, nous ne pouvons pas
appliquer la méthode des moindres carrés
généralisés car
ce qui suggère de
fait une héteroscedasticité. Cependant, nous ne pouvons pas
appliquer la méthode des moindres carrés
généralisés car 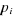 dépend du
paramètre â du modèle ;
dépend du
paramètre â du modèle ;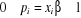 qui peut se révéler non compatible avec les données.
qui peut se révéler non compatible avec les données. comme la variation en
pourcentage de la probabilité de survenue
comme la variation en
pourcentage de la probabilité de survenue 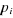 de
l'événement codé
de
l'événement codé , suite à une
variation de 1% de la jième variable explicative
, suite à une
variation de 1% de la jième variable explicative  :
: 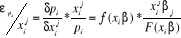 .
Sachant que
.
Sachant que ,
l'élasticité devient :
,
l'élasticité devient : ,
,
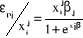 .
. est défini
par :
est défini
par : .
. .
.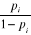 représente le
rapport de la probabilité associée à
l'événement
représente le
rapport de la probabilité associée à
l'événement  à la probabilité de non survenue de cet
événement : il s'agit de la cote
« odds ». Dans un modèle logit, cette cote
correspond simplement à la quantité
à la probabilité de non survenue de cet
événement : il s'agit de la cote
« odds ». Dans un modèle logit, cette cote
correspond simplement à la quantité 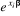 :
:  =
= qu'est « la cote
odds » ou « odds ratio ».
qu'est « la cote
odds » ou « odds ratio ». =0) par la statistique
=0) par la statistique 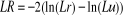 qui suit sous
l'hypothèse nulle Ho, une distribution d'un
qui suit sous
l'hypothèse nulle Ho, une distribution d'un 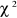 à k degré de
liberté.
à k degré de
liberté. est donné
par :
est donné
par :  Avec,
Lr : valeur de la fonction du log-vraisemblance contrainte sous Ho. Et
Lu : valeur de la fonction du log-vraisemblance non contrainte.
Avec,
Lr : valeur de la fonction du log-vraisemblance contrainte sous Ho. Et
Lu : valeur de la fonction du log-vraisemblance non contrainte. sont
largement significatifs. Les pseudo-
sont
largement significatifs. Les pseudo- de tous les modèles
sont très faibles, mais il est tout de même important de savoir
que des tels résultats sont typiques des analyses transversales. Ce
travail ayant d'abord un objectif méthodologique, nous travaillerons
tout de même avec ces pseudo-
de tous les modèles
sont très faibles, mais il est tout de même important de savoir
que des tels résultats sont typiques des analyses transversales. Ce
travail ayant d'abord un objectif méthodologique, nous travaillerons
tout de même avec ces pseudo- .
. significative. De ce fait,
nous rejetons l'hypothèse nulle d'égalité des coefficients
associés aux variables du modèle. Toutes les variables sont
significatives à 5% de signification, à l'exception de la
variable religion qui le devient à 10%. Le test Gof (goodness-of-fit
test) de Pearson atteste que le modèle est donc bon sur le plan
statistique.
significative. De ce fait,
nous rejetons l'hypothèse nulle d'égalité des coefficients
associés aux variables du modèle. Toutes les variables sont
significatives à 5% de signification, à l'exception de la
variable religion qui le devient à 10%. Le test Gof (goodness-of-fit
test) de Pearson atteste que le modèle est donc bon sur le plan
statistique.
