Dans cette partie « Empirique »,
on choisie d'utiliser le logiciel E-Views6 pour bien appréhender tout ce
qu'on avait vu dans la partie « Théorique ».
En effet, Eviews est un logiciel de système
d'exploitation Windows dans un des leaders mondiaux de logiciels
d'économétrie. Ce logiciel donne une prévision de
l'analyse des données scientifique, l'analyse financière, les
prévisions des ventes et les prévisions économiques. En
outre, les solutions logicielles Eviews matière de recherche et
d'enseignement, entreprise, organisme gouvernementaux et les utilisateurs des
étudiants à une analyse statistique puissant, de prévision
des outils de modélisation.
Pour ces raisons, nous utiliserons le logiciel Eviews
afin d'obtenir des résultats précises à propos de
modélisation de la série US/Euro Foreign Exchange Rate.
Introduction de la série US/Euro Foreign
Exchange Rate
L
es propriétés de long terme des
séries financières de prix de devise intéressent depuis
longtemps les financiers et les staticients. Dans ce travail empirique nous
réexaminons cette question à propos du taux de change à
partir de l'exemple de celui de l'Euro contre le Dollar.
En effet, le taux de change d'une devise (une monnaie)
est la cour (autrement dit le prix) de cette devise par rapport à une
autre. Dans notre travail le taux de change d'euro en dollar est le nombre de
dollar que l'obtient pour un euro. En outre, le taux de change est sans
contexte une macro-économique importante. Pour une petite
économique ouverte, l'ajustement de taux de change permet de lisser les
chocs affectant les termes de l'échange. Dans une économie moins
ouvert, il favorise l'ajustement des prix relatifs entre les secteurs des biens
échangeables et celui des biens non échangeables. Le taux de
change flottant varie alors en permanence et est déterminé par
l'offre et la demande de chacune des deux monnaies sur le marché des
changes.
L'objectif de notre étude alors de montrer
qu'il est possible de retrouver les bases théoriques fondamentale simple
permettant d'explique les déterminant à long terme de taux de
conversation US/Euro entre 1999 et 2010 afin d'avoir une prévision
à terme.
Ø Présentation des données : voir
ANNEXE 1
|
Title:
|
U.S. / Euro Foreign Exchange Rate
|
|
|
|
Series ID:
|
EXUSEU
|
|
|
|
|
|
Source:
|
Board of Governors of the Federal Reserve System
|
|
|
Release:
|
G.5 Foreign Exchange Rates
|
|
|
|
|
Seasonal Adjustment:
|
Not Applicable
|
|
|
|
|
|
Frequency:
|
Monthly
|
|
|
|
|
|
Units:
|
U.S. Dollars to One Euro
|
|
|
|
|
Date Range:
|
1999-01-01 to 2010-03-01
|
|
|
|
|
Last Updated:
|
2010-04-01 10:05 AM CDT
|
|
|
|
|
Notes:
|
Averages of daily figures. Noon buying rates in New York City
for
|
|
Cable transfers payable in foreign currencies.
|
|
|
|
|
|
|
|
|
Application par le logiciel Eviews
SECTION1 :
Prévision par la méthode de Lissage
exponentiel
Avant de pouvoir utiliser l'une des méthodes de lissage
exponentiel (simple, double, HoltWinters), nous devons tester
l'existence d'une éventuelle tendance ou/et d'une saisonnalité
dans notre série
Le Fisher calculé (8.530819) est largement
supérieur au Fisher tabulé (2.09), dans ce cas on rejette
l'hypothèse H0, la série est donc
saisonnière.
Notre série est à la fois affectée d'une
saisonnalité et d'une tendance, donc la méthode de lissage la
plus adéquate est celle de HoltWinters, allons opter pour le
modèle de Holt Winters additif.
1-Le modèle de Holt Winters additif
|
Date: 06/11/10 Time: 09:41
|
|
|
Sample: 1999M01 2010M03
|
|
|
|
Included observations: 135
|
|
|
|
Method: Holt-Winters Additive Seasonal
|
|
|
Original Series: VALUE
|
|
|
|
Forecast Series: VALUESM
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Parameters:
|
Alpha
|
|
1.0000
|
|
Beta
|
|
0.0000
|
|
Gamma
|
|
0.0000
|
|
|
|
|
|
Sum of Squared Residuals
|
|
0.122180
|
|
Root Mean Squared Error
|
|
0.030084
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
End of Period Levels:
|
Mean
|
1.356132
|
|
|
Trend
|
0.002721
|
|
|
Seasonals:
|
2009M04
|
-0.001826
|
|
|
|
2009M05
|
0.003471
|
|
|
|
2009M06
|
0.003077
|
|
|
|
2009M07
|
0.006083
|
|
|
|
2009M08
|
-0.001121
|
|
|
|
2009M09
|
-0.007087
|
|
|
|
2009M10
|
-0.010836
|
|
|
|
2009M11
|
-0.011539
|
|
|
|
2009M12
|
0.005040
|
|
|
|
2010M01
|
0.014847
|
|
|
|
2010M02
|
-0.000975
|
|
|
|
2010M03
|
0.000868
|
|
|
|
|
|
|
|
|
|
|
Les prévisions de notre série suivent la même
allure de tendance.
SECTION 2 : Prévision par la
méthode Box&Jenkins
1- Etude préliminaire de la
série :
1-1- l'examen du
graphe :
La première étape de l'étude d'une
série chronologique est la représentation graphique. Cette
visualisation donne des indications très précieuses pour choisir
un modèle
Pour illustre cette première phase de
modélisation, nous examinons le graphique
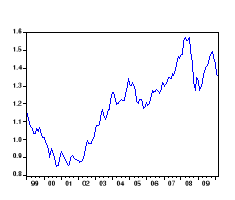
L'analyse visuelle du graphe montre à
première vue la présence d'une tendance. D'où il y a lieu
d'affirmer une présomption du non stationnarité
de notre série
1-2- L'examen du corrélogramme de la série
brute
· Corrélogramme de la série
brute
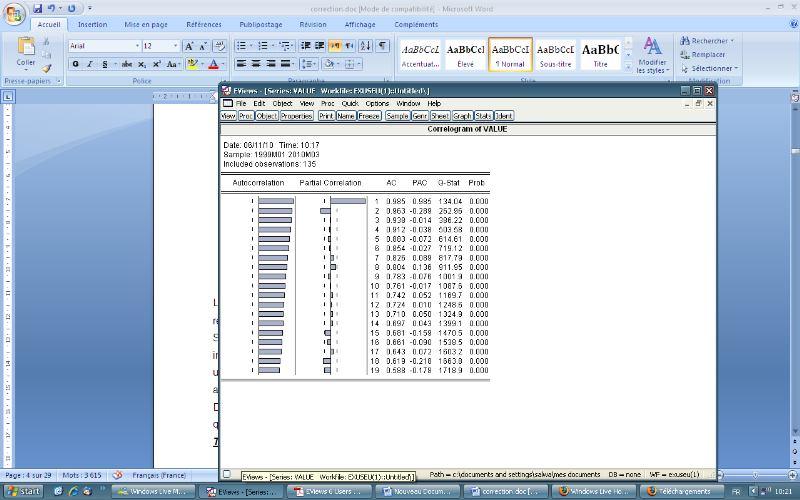
Le corrélogramme pressente (VALUE) est calculée
a l'aide du logiciel EVIEWS et sur 19 retard
Son examen pressente une décroissance de ses retards
(ce qui indique l'existence du facteur tendanciel). Les autocorrelation
s'annulent très lentement
Donc la série brute est effectuée de la
saisonnalité de la tendance, ce qui veut dire qu'elle est non
stationnaire on va confirmer avec le test qui suit :
|
Test for Equality of Means of VALUE
|
|
|
Categorized by values of VALUE
|
|
|
|
Date: 06/11/10 Time: 10:57
|
|
|
|
Sample: 1999M01 2010M03
|
|
|
|
Included observations: 135
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Method
|
df
|
Value
|
Probability
|
|
|
|
|
|
|
|
|
|
|
|
Anova F-test
|
(3, 131)
|
568.1851
|
0.0000
|
|
Welch F-test*
|
(3, 58.8123)
|
682.6354
|
0.0000
|
|
|
|
|
|
|
|
|
|
|
|
*Test allows for unequal cell variances
|
|
|
|
|
|
|
|
Analysis of Variance
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Source of Variation
|
df
|
Sum of Sq.
|
Mean Sq.
|
|
|
|
|
|
|
|
|
|
|
|
Between
|
3
|
4.907427
|
1.635809
|
|
Within
|
131
|
0.377150
|
0.002879
|
|
|
|
|
|
|
|
|
|
|
|
Total
|
134
|
5.284577
|
0.039437
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Category Statistics
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Std. Err.
|
|
VALUE
|
Count
|
Mean
|
Std. Dev.
|
of Mean
|
|
[0.8, 1)
|
33
|
0.913230
|
0.042021
|
0.007315
|
|
[1, 1.2)
|
31
|
1.101381
|
0.063266
|
0.011363
|
|
[1.2, 1.4)
|
51
|
1.285882
|
0.053150
|
0.007443
|
|
[1.4, 1.6)
|
20
|
1.479645
|
0.055876
|
0.012494
|
|
All
|
135
|
1.181128
|
0.198588
|
0.017092
|
|
|
|
|
|
|
|
|
|
|
On teste les hypothèses suivantes :
Fc : Fisher calculée.
D'où on rejette H0. Ce qui veut dire que la
série est affectée d'une tendance.
On peut conclure que la série brute value est non
stationnaire, puisque les tests d'existence de la saisonnalité et de la
tendance sont retenus
1-3- dessaisonaliser la
série :
Nous présentons dans le tableau suivant les
coefficients saisonniers pour chaque mois
|
Date: 06/11/10 Time: 11:19
|
|
Sample: 1999M01 2010M03
|
|
Included observations: 135
|
|
Ratio to Moving Average
|
|
Original Series: VALUE
|
|
Adjusted Series: VALUESA
|
|
|
|
|
|
|
|
Scaling Factors:
|
|
|
|
|
|
|
|
1
|
1.010803
|
|
2
|
0.998782
|
|
3
|
1.000776
|
|
4
|
0.998398
|
|
5
|
1.003183
|
|
6
|
1.005573
|
|
7
|
1.005131
|
|
8
|
1.000898
|
|
9
|
0.996231
|
|
10
|
0.988611
|
|
11
|
0.986794
|
|
12
|
1.005089
|
|
|
|
|
|
|
· Le graphe de la série
désaisonnalisée :
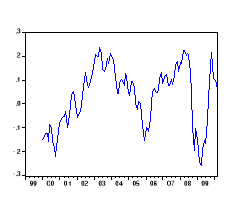
2-Etude de la stationnarité de la
série désaisonnalisée (valuesa)
** Test d'ADF sur la série
désaisonnalisée VALUESA** :
· Choix du nombre de retards optimal :
Avant de pouvoir appliquer le test de Dickey-Fuller, nous devons
déterminer le nombre de retards p qui minimise
les critères d'Akaike et Schwartz pour les trois modèles (avec
tendance et constante (trend and intercept), avec constante (intercept), sans
tendance ni constante (none)).
Les valeurs des critères d'Akaike et Schwartz sont
fournies par le logiciel Eviews et sont résumées dans le tableau
suivant :
|
Lags
|
Akaike
|
Schwarz
|
Lags
|
Akaike
|
Schwarz
|
Lags
|
Akaike
|
Schwarz
|
|
0
|
-4.233629
|
-4.288752
|
0
|
-4.312092
|
-4.246896
|
0
|
-3.977757
|
-3.999386
|
|
1
|
-4.364863
|
-4.277935
|
1
|
-4.319268
|
-4.221910
|
1
|
-4.127221
|
-3.982844
|
|
2
|
-4.349244
|
-4.240047
|
2
|
-4.288401
|
-4.178661
|
2
|
-4.109676
|
-3.912238
|
|
3
|
-4.332551
|
-4.200863
|
3
|
-4.266666
|
-4.134318
|
3
|
-4.070637
|
-3.994207
|
|
4
|
-4.312695
|
-4.158290
|
4
|
-4.250365
|
-4.095181
|
4
|
-4.108075
|
-3.952104
|
D'après le tableau nous constatons que le critère
d'Akaike est minimisé pour les trois modèles pour un nombre de
retard p = 1 tandis que le critère de Schwartz
est minimisé pour p = 0. En suivant le
principe de parcimonie nous retiendrons le nombre de retards qui permet
d'estimer le minimum de paramètres c'est-à-dire p = 0. Dans
ce cas on utilise le test de Dickey-Fuller simple (DF), donc il n'y a pas
d'autocorrélation des erreurs.
|
Null Hypothesis: VALUESA has a unit root
|
|
|
Exogenous: Constant, Linear Trend
|
|
|
Lag Length: 0 (Fixed)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t-Statistic
|
Prob.*
|
|
|
|
|
|
|
|
|
|
|
|
Augmented Dickey-Fuller test statistic
|
-2.620864
|
0.2719
|
|
Test critical values:
|
1% level
|
|
-4.027959
|
|
|
5% level
|
|
-3.443704
|
|
|
10% level
|
|
-3.146604
|
|
|
|
|
|
|
|
|
|
|
|
|
*MacKinnon (1996) one-sided p-values.
|
|
|
|
|
|
|
|
|
|
|
|
|
Augmented Dickey-Fuller Test Equation
|
|
|
Dependent Variable: D(VALUESA)
|
|
|
Method: Least Squares
|
|
|
|
Date: 06/11/10 Time: 12:12
|
|
|
|
Sample (adjusted): 1999M02 2010M03
|
|
|
Included observations: 134 after adjustments
|
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
VALUESA(-1)
|
-0.067131
|
0.025614
|
-2.620864
|
0.0098
|
|
C
|
0.057358
|
0.023058
|
2.487491
|
0.0141
|
|
@TREND(1999M01)
|
0.000347
|
0.000131
|
2.644404
|
0.0092
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
0.053536
|
Mean dependent var
|
0.001561
|
|
Adjusted R-squared
|
0.039086
|
S.D. dependent var
|
0.029396
|
|
S.E. of regression
|
0.028816
|
Akaike info criterion
|
-4.233629
|
|
Sum squared resid
|
0.108778
|
Schwarz criterion
|
-4.228752
|
|
Log likelihood
|
286.6531
|
Hannan-Quinn critter.
|
-4.207265
|
|
F-statistic
|
3.704956
|
Durbin-Watson stat
|
1.271757
|
|
Prob(F-statistic)
|
0.027216
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D'après ce tableau, on remarque que le coefficient de
la tendance est significatif, ce qui indique la présence de la
tendance.car la t-Statistique calculée est supérieur à
celle tabulée de DICKEY-FULLER (2.62)
Donc ça confirme qu'il y'a une non
stationnarité déterministe donc le type de la série
VALUESA est TS, et la meilleurs méthode pour la stationnarisée
est d'estimer la fonction de la tendance et de la retrancher de la série
VALUESA,
3-Stationnarisation de la série
valuesa
3-1- Estimation de la fonction de la
tendance :
|
Dependent Variable: VALUESA
|
|
|
|
Method: Least Squares
|
|
|
|
Date: 06/13/10 Time: 16:04
|
|
|
|
Sample (adjusted): 2000M01 2010M03
|
|
|
Included observations: 123 after adjustments
|
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
C
|
-0.012010
|
0.025537
|
-0.470286
|
0.6390
|
|
@TREND
|
0.000628
|
0.000315
|
1.996130
|
0.0482
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
0.031880
|
Mean dependent var
|
0.033831
|
|
Adjusted R-squared
|
0.023879
|
S.D. dependent var
|
0.125383
|
|
S.E. of regression
|
0.123877
|
Akaike info criterion
|
-1.322926
|
|
Sum squared resid
|
1.856812
|
Schwarz criterion
|
-1.277199
|
|
Log likelihood
|
83.35993
|
Hannan-Quinn critter.
|
-1.304352
|
|
F-statistic
|
3.984533
|
Durbin-Watson stat
|
0.133902
|
|
Prob(F-statistic)
|
0.048165
|
|
|
|
|
|
|
|
|
|
|
|
|
|
VALUESA = -0.0120096991311 +
0.000627953334795*@TREND
A présent il ne reste qu'à retrancher cette
équation de la série :
Stationnaire = Valuesa -
(0.0120096991311+0.000627953334795*(@TREND))
Donc notre série est stationnaire, on peu vérifier
par :
· Graphe de la série brute
désaisonnalisée et sans tendance VALUESA :
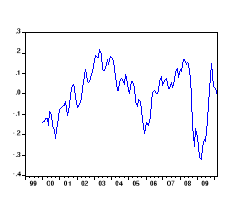
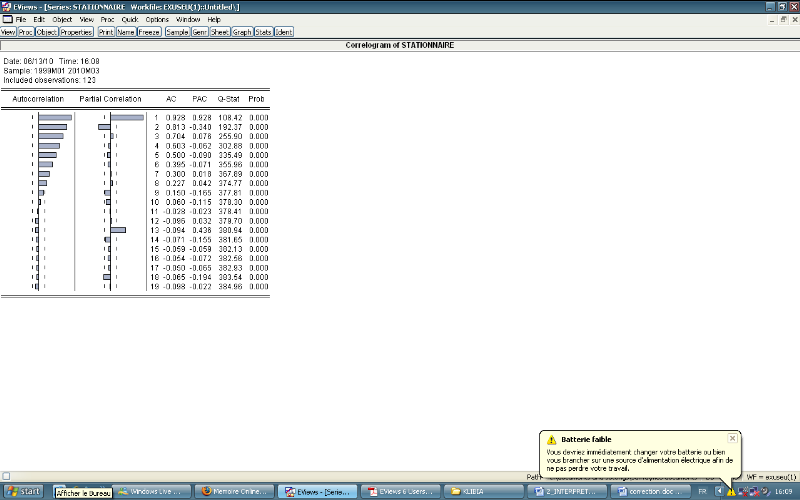
On remarque que les coefficients d'autocréation
qui s'annulent rapidement
Comme cette série est stationnaire
alors on effectue les 4 étapes de la méthodologie de Box
& Jenkins :
3-2-La méthodologie de Box &
Jenkins :
Ø Identification de modèle :
Cette étape consiste à identifier le modèle
susceptible de représenter la série
On va identifier à présent un model valide pour
faire notre prévisions, et pour cela on va estimer chaque model,
d'après les pics qui sont à l'intérieur de l'intervalle de
confiance
L'examen de ce corrélogramme montre deux pics
importants pour le terme « AR » dans
1,2,13 et six pics importants pour le terme «
MA » dans les retards 1,2,3,4,5,6.
Donc les modèles sont :
MA (1) AR(1) AR(2) MA(2) MA(3) MA(4) MA(5)
MA(6) MA(7) ARMA(1,1) ARMA(1.2) ARMA(1.3) ARMA(1.4)
ARMA(1.5)
ARMA(1.6) ARMA(1.7) ARMA(2.1) ARMA(2.2)
ARMA(2.3) ARMA(2.4) ARMA(2.5)
ARMA(2.6)
ARMA(2.7).
Pour pouvoir choisir un bon modèle parmi ceux
présenté ; on estime chaque modèle et en suite on
arrive à l'étape de validation ou applique le test de
L-JUNG BOX et les tests de normalité,
d'homogénéité.
Ø Estimation de modèle :
Nous estimons les paramètres de modèle qui
explique mieux nos observations.
Dans cet étape on test la signification des
coefficients des modèles par un simple test de Student
au seuil de 5% (on compare la statistique calculée avec la statistique
tabulée (1.96)). Si/ t-stat/>1.96 donc ce
modèle sera candidat à être valider.
|
Dependent Variable: STATIONNAIRE
|
|
|
Method: Least Squares
|
|
|
|
Date: 06/13/10 Time: 16:18
|
|
|
|
Sample (adjusted): 2000M02 2010M03
|
|
|
Included observations: 122 after adjustments
|
|
|
Convergence achieved after 2 iterations
|
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
AR(1)
|
0.927749
|
0.032615
|
28.44562
|
0.0000
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
0.869902
|
Mean dependent var
|
0.001160
|
|
Adjusted R-squared
|
0.869902
|
S.D. dependent var
|
0.123202
|
|
S.E. of regression
|
0.044438
|
Akaike info criterion
|
-3.381294
|
|
Sum squared resid
|
0.238940
|
Schwarz criterion
|
-3.358310
|
|
Log likelihood
|
207.2589
|
Hannan-Quinn critters.
|
-3.371958
|
|
Durbin-Watson stat
|
1.306086
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Inverted AR Roots
|
.93
|
|
|
|
|
|
|
|
|
|
|
|
|
On remarque que la t-statistique est supérieur
à 1.96 et les racines sont supérieures à
1 donc ce model est retenu, pour cela on va s'assurer avec des tests à
l'étape suivante :
Ø Validation de modèle :
Cette étape consiste à faire des tests de
validation qui sont comme suite :
1- test de L-Jung box (test d'absence
d'autocorrelation des résidus),
2- test de normalité (est ce que le
bruit blanc est gaussien ou pas)
3- test d'ARCH (l'homoscidasticité et
l'héteroscidasticité).
On commence par le test le plus utilisé qui est le test
de L-Jung box. Ce test est basé sur la comparaison
entre la dernière valeur de Q-stat calculée (sur
le corrélogramme) et la valeur tabulée de
Khi-deux de
(N-p-q) degré de liberté
/N : le nombre d'observation
p : l'ordre d'autorégressive
q : l'ordre de Moyen mobile
Si la statistique de Q-stat<X2 (N-p-q) on accepte
l'existante de l'absence d'autocorrelation des résidus, alors les
résidus constituent un bruit blanc ce qui nous donne un modèle
valide.
| 

