CHAPITRE III:
ANALYSE ECONOMETRIQUE

49
Réalisé et soutenu par Ulysse Vital A.
NANGBE
SECTION 1 : ANALYSE DES SERIES CHRONOLOGIQUES
1.1 Stationnarité d'un processus et résultats
des tests de stationnarité
Stationnarité d'un processus
Une série temporelle est dite stationnaire si sa
moyenne et sa variance sont constantes dans le temps et si la valeur de la
covariance entre deux périodes de temps ne dépend que de la
distance ou écart entre ces deux périodes et non pas du moment
auquel la covariance est calculée. Une telle série temporelle est
qualifiée de faiblement stationnaire.
Cette définition se traduit comme suit pour une
série Yt :
i) Moyenne : E(Yt )= u
ii) Variance: V(Yt ) = E(Yt - u)2 = ó2
iii) Covariance: Cov(Yt , Yt+k ) = E[ (Yt - u)( Yt+k - u)] =
ãk
De façon pratique, la non stationnarité
s'explique par deux phénomènes que sont la présence de
tendance déterministe et/ou de tendance aléatoire dans la
structure de la série temporelle étudiée.
Il existe plusieurs tests pour détecter la
stationnarité. Nous aborderons le plus utilisé dans les travaux
empiriques, à savoir le test de Dickey-fuller Augmenté.
Toutefois, il convient de faire remarquer que l'analyse du
corrélogramme de la série peut donner une première
indication sur la nature probable de la série.
Analyse du corrélogramme
Si les coefficients d'autocorrélation simple et les
coefficients d'autocorrélation partielle sont à
l'intérieur de la zone de confiance délimitée par les
pointillés, alors la série est stationnaire.
Test de Dickey-Fuller Augmenté(ADF)

Le test de Dickey-Fuller Augmenté est une version
améliorée du test de Dickey-Fuller simple, par l'introduction
dans les modèles du test des valeurs retardées de la série
destinées à corriger une éventuelle autocorrélation
du terme d'erreur.
Les trois modèles s'écrivent comme suit :
Modèle 1 : AYt = pYt-1 + E cjAYt-1 + Et
Modèle 2 : AYt = pYt-1 + a0 + E cjAYt-1 + Et
Modèle 3 : AYt = pYt-1 + a0 + a1t + E cjAYt-1 + Et
La procédure à suivre pour réaliser le test
est le suivant :
1-) Il faut commencer par le modèle 3 et rechercher le p
optimal sur la base du critère d'information d'akaike ou schwarz.
2-) Sur la base du p retenu, il faut estimer le
modèle.
3-) Voir si la tendance déterministe (t) est
significative. Si la tendance n'est pas significative, la retirer et estimer de
nouveau le modèle. C'est-à-dire le modèle 2.
4-) Vérifier si la constante est significative. Si la
constante n'est pas significative, la retirer et estimer de nouveau le
modèle. C'est-à-dire le modèle 1.
5-) Faire le test de racine unitaire à partir de la
statistique de Dickey Fuller Augmenté et du niveau retenu pour la marge
d'erreur a. En général, on retient a=5%.
Si le résultat conclut à une non
stationnarité de la série, alors il faudra différencier la
série et effectuer de nouveau le test jusqu'à aboutir à un
résultat stationnaire. Dans ce cas, on dit que la série
temporelle est intégrée d'un ordre égal au nombre de fois
qu'elle a été différenciée avant d'être
stationnaire. Soit d le nombre de fois que la série a été
différenciée. On note Yt -->I(d).

51
Réalisé et soutenu par Ulysse Vital A.
NANGBE

Résultats des tests de
stationnarité
La lecture des résultats du test se fait en deux
étapes :
Etape1 : la significativité ou non du trend. Elle est
appréciée à partir de la statistique calculée ou la
probabilité attachée à cette statistique (elle est
comparée à 5%).
Etape2 : la présence ou non de racine unitaire. A cet
effet, on teste l'hypothèse nulle Ho contre l'hypothèse
alternative H1. Les hypothèses sont :
Ho : Présence de racine unitaire ; H1 : Absence
de racine unitaire.
- Si ADF Test Statistic > Critical Value, alors on accepte Ho
: la série a une racine unitaire.
- Si ADF Test Statistic < Critical Value, alors on accepte H1
: la série n'a pas de racine unitaire.
Tableau 3 : Résultat des tests de
stationnarité
|
Variables
|
Ordre de stationnarité
|
|
L(1+idh)
|
Stationnaire en différence première
|
|
Ldpie
|
Stationnaire en différence première
|
|
Ldpis
|
Stationnaire en différence première
|
|
Ldpiso
|
Stationnaire en différence première
|
Source: Nos réalisations
Dépenses publiques en infrastructures de base et
indicateur de développement humain (IDH) 1.2 Analyse de la
cointégration entre les variables
Test de cointégration
Le concept de cointégration fournit un cadre
théorique de référence pour étudier les situations
d'équilibre et de déséquilibre qui règnent
respectivement à long et
à court terme. Si les variables sont
cointégrées, elles admettent une spécification dynamique
de type correction d'erreur, qui transforme le problème initial de
régression sur les variables non stationnaires. La cointégration
permet d'identifier la relation véritable entre deux variables en
recherchant l'existence d'un vecteur de cointégration et en
éliminant son effet, le cas échéant.
Deux séries Yt et Xt sont dites cointégrées
si les deux conditions suivantes sont vérifiées :
-Elles sont affectées d'une tendance stochastique de
même ordre d'intégration d : Yt ? I(d) et Xt ? I(d) ;
-Une combinaison linéaire de ces séries permet de
se ramener à une série d'ordre d'intégration
inférieur:
á1Yt + á2Xt > I(d-b) avec d?b>0.
Ce test se fait en deux étapes :
ère
1 étape : tester l'ordre d'intégration des
variables
Une condition nécessaire de cointégration est que
les séries soient intégrées de même ordre. Cette
condition n'est valable que pour le test Engel et Granger.
Dans le cas contraire la cointégration n'est pas
possible. Il convient donc de déterminer l'ordre d'intégration
« d » de chacune des variables étudiées. Dans la mesure
où les séries sont intégrées du même ordre,
on passe à la seconde étape.
2ème étape : estimation de la relation de
long terme
Si la condition nécessaire est vérifiée, on
estime par les MCO la relation de long terme entre les variables :
Yt = á+ â Xt +
åt
Pour que la relation de cointégration soit
acceptée, le résidu de la régression de
Y sur X doit
être stationnaire. Il suffit de procéder à un test de
stationnarité sur le
résidu (DF, ADF ou PP). Dans ce cas, nous
pouvons estimer le modèle à correction

53
Réalisé et soutenu par Ulysse Vital A.
NANGBE
d'erreur.
Mais le concept de cointégration ne s'applique pas de
la même manière lorsqu'on est en présence de plusieurs
variables explicatives. Compte tenu du risque de cointégration entre les
variables, il est conseillé de faire le test de cointégration
proposé par Johannsen (1988) entre les variables d'intérêt.
Ce test est basé sur le rang de la matrice A des coefficients du vecteur
des variables d'intérêt (Y) à leur plus grand retard dans
le modèle :
Yt = A0 + AYt-p + A1 Yt-1 + A2 Yt-2 +..+ Ap-1 Yt-p+1 + Et
La statistique calculée est ensuite confrontée
aux valeurs d'une distribution tabulée par Johannsen et Juselius (1990)
pour une décision par exclusion progressive d'hypothèses
alternatives.
S'il n'existe qu'une relation de cointégration entre
les variables alors la méthode de cointégration avec deux
variables peut s'appliquer au cas où il y a plus de deux variables.
Le test de Johannsen comporte un test portant sur la trace et
un autre sur les valeurs propres maximales. Le test de la trace sera
effectué en supposant l'absence de tendance dans la relation de
cointégration et la présence d'une constante dans le
modèle à correction d'erreur (ECM).
Tableau 4 : Résultat du test de la trace des
valeurs logarithmiques
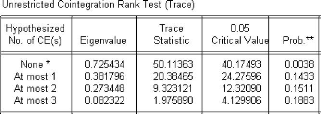
Source : Nos calculs sur Eviews5

54
Réalisé et soutenu par Ulysse Vital A.
NANGBE

Tableau 5: Résultat du test de la valeur propre
maximale
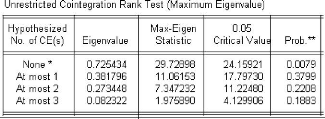
Source : Nos calculs sur Eviews5
L'analyse des tableaux 2 et 3 permet de déduire qu'il
existe une seule relation de cointégration entre les variables.
Par conséquent, il convient d'estimer la relation entre
les variables à travers un modèle à correction d'erreur
(ECM) par la méthode à deux étapes de Engel et Granger.
| 

