Apprentissage sur des données académiques en vue de faciliter l'orientation et l'aide à la décisionpar Zelkifilou NJAMEN MOUNGNUTOU Université de Douala - Master 2 recherche en informatique appliquée option SIS 2020 |

2.3.3.1 Principe du K-PPV
on peut choisir la distance euclidienne de. Soient deux données représentées par 2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA LITTÉRATURE deux vecteurs x et y , la distance entre ces deux données est donnée par :
Mémoire de Master II en Informatique 26 c~NJAMEN M. ZELKIF 2020-2021 Ainsi, pour une nouvelle observation (y, x) le plus proche voisin (y1-x1) dans l'échantillon d'apprentissage est déterminépar : d(x, x1) = mini(d(x, xi)) Et y = y1, la classe du plus proche voisin, est sélectionnée pour la prédiction de y. 2.3.3.2 Avantages de la méthode des K-PPVLa méthode des k plus proches voisins représente des avantages tels que: 1. L'algorithme K-NN est robuste envers des données bruitées. Selon SOLLAH [20]
2.3.3.3 Inconvénients de la méthode des K-PPVLa méthode des k plus proches voisins comporte des inconvénients tels que :
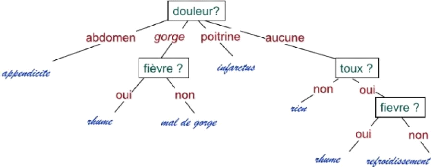
2.3.4 Les Arbres de décision 2.3.4.1 Généralités sur les arbres de décisionL'apprentissage par arbre de décision est une méthode classique en apprentissage automatique. Son but est de créer un modèle qui prédit la valeur d'une variable-cible depuis 2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA LITTÉRATURE Mémoire de Master II en Informatique 27 c~NJAMEN M. ZELKIF 2020-2021 la valeur de plusieurs variables d'entrée. Une des variables d'entrée est sélectionnée à chaque noeud intérieur (ou interne, noeud qui n'est pas terminal) de l'arbre selon une méthode qui dépend de l'algorithme. Chaque arête vers un noeud-fils correspond à un ensemble de valeurs d'une variable d'entrée, de manière que l'ensemble des arêtes vers les noeuds-fils couvrent toutes les valeurs possibles de la variable d'entrée. Chaque feuille (ou noeud terminal de l'arbre) représente soit une valeur de la variable-cible, soit une distribution de probabilitédes diverses valeurs possibles de la variable-cible. La combinaison des valeurs des variables d'entrée est représentée par le chemin de la racine jusqu'àla feuille. L'arbre est en général construit en séparant l'ensemble des données en sous-ensembles en fonction de la valeur d'une caractéristique d'entrée. Ce processus est répétésur chaque sous-ensemble obtenu de manière récursive, il s'agit donc d'un partitionnement récursif. La récursion est achevée à un noeud soit lorsque tous les sous-ensembles ont la même valeur de la caractéristique-cible, ou lorsque la séparation n'améliore plus la prédiction. Ce processus est appeléinduction descendante d'arbres de décision (top-down induction of decision trees ou TDIDT), c'est un algorithme glouton puisqu'on recherche à chaque n ?ud de l'arbre le partage optimal, dans le but d'obtenir le meilleur partage possible sur l'ensemble de l'arbre de décision. C'est la stratégie la plus commune pour apprendre les arbres de décision depuis les données. En fouille de données, les arbres de décision peuvent aider à la description, la catégorisation ou la généralisation d'un jeu de données fixé. L'ensemble d'apprentissage est généralement fourni sous la forme d'enregistrements du type: (x,Y ) = (x1,x2,x3,...,xk,Y ) La variable Y désigne la variable-cible que l'on cherche à prédire, classer ou généraliser. Le vecteur X est constituédes variables d'entrée x1, x2, x3 etc. qui sont utilisées dans ce but. Selon Wikipédia [24], Un arbre de décision est une structure graphique sous forme d'un arbre (feuilles et branches) qui illustre un ensemble de choix pour aider à la prise de décision et classer un vecteur d'entrée X. Cet algorithme est très utilisédans les fouilles de données et la sécurité. 2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA LITTÉRATURE Mémoire de Master II en Informatique 28 c~NJAMEN M. ZELKIF 2020-2021 2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA LITTÉRATURE Mémoire de Master II en Informatique 29 c~NJAMEN M. ZELKIF 2020-2021 Chaque noeud de l'arborescence contient une comparaison de fonction simple par rapport à un champ (exemple : x = female?). Le résultat de chaque comparaison est vrai ou faux, ce qui détermine si nous devons continuer vers la feuille gauche ou vers la droite du noeud. Une feuille correspond à la décision. Chaque instance est décrite par un vecteur d'attributs/valeurs En entrée : un ensemble d'instances et leur classe (correctement associées par un »expert») Les arbres de décision sont également connus sous le nom d'arbres de classification et de régression (CART). D'après Alain [14] Les arbres de décision sont des classifieurs pour des instances représentées dans un formalisme attribut/valeur.
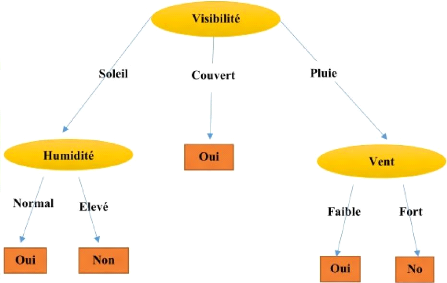
Figure 2.5 - Classification avec un Arbre de
Décision sur le jeu de donnée Jouer |
|