2.2.1.3 Apprentissage par renforcement
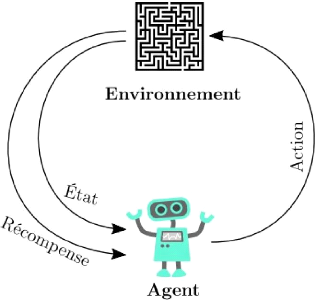
L'apprentissage par renforcement, au sens
général, est un cadre formel qui modélise des
problèmes décisionnels séquentiels. Au sein de ce cadre,
un agent apprend à prendre des décisions optimales en
interagissant avec l'environnement selon Matthieu [15].
En intelligence artificielle, plus précisément
en apprentissage automatique, l'appren-tissage par renforcement consiste, pour
un agent autonome (robot, etc.), à apprendre les actions à
prendre, à partir d'expériences, de façon à
optimiser une récompense quantitative au cours du temps. L'agent est
plongéau sein d'un environnement, et prend ses décisions en
fonction de son état courant. En retour, l'environnement procure
à l'agent une récompense, qui peut être positive ou
négative. L'agent cherche, au travers d'expé-riences
itérées, un comportement décisionnel
(appeléstratégie ou politique, et qui est une fonction associant
à l'état courant l'action à exécuter) optimal, en
ce sens qu'il maximise la somme des récompenses au cours du temps
d'après Wikipédia [17].
L'apprentissage par renforcement repose sur l'utilisation de
données indirectement étiquetées par des
récompenses. Cet étiquetage est moins informatif qu'en
apprentissage superviséselon Matthieu [15].
2.3 Les Algorithmes de Machine Learning
Marketing prédictif, maintenance industrielle,
reconnaissance faciale et vocale, éducation (orientation scolaire et
professionnelle). Les applications de Machine Learning (ou apprentissage
automatique) sont aujourd'hui de plus en plus nombreuses au sein des
organisations. À la croisée des statistiques, de l'intelligence
artificielle et de l'informatique, cette technologie consiste à
programmer des algorithmes pour permettre aux ordinateurs d'apprendre par
eux-mêmes.
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 20 c~NJAMEN M. ZELKIF
2020-2021
Figure 2.1 - Illustration du cadre
général de l'apprentissage par renforcement. Adaptédepuis
Wikipédia [17].
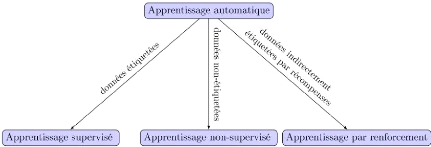
Figure 2.2 - Les trois grandes classes
d'apprentissage automatique. Schéma De
Matthieu [15]
En reconnaissance de formes, les phases d'apprentissage et de
classification constituent des étapes fondamentales qui conditionnent en
grande partie les performances du système. Classifier des formes ou
individus (par exemple des objets, des images, des phonèmes, ...)
décrits par un ensemble de grandeurs caractéristiques (taille ou
masse de l'objet, pixels de l'image numérisée, spectre acoustique
du phonèmes, ...), c'est les ranger en un certain nombre de
catégories ou classes définies à l'avance. La
classification c'est l'action de ran-
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 21 c~NJAMEN M. ZELKIF
2020-2021
ger par classes, par catégories des objets avec des
propriétés communes. Il existe deux catégories de
classification : classification supervisée et classification non
supervisée. La classification est l'élaboration d'une
règle de décision qui transforme les attributs
caractérisant les formes en appartenance à une classe; passage de
l'espace de représentation vers l'espace de décision. La
classification consiste alors à identifier les classes auxquelles
appartiennent les formes à partir des caractéristiques
préalablement choisies et calculés. L'algorithme ou la
procédure qui réalise cette application est
appeléclassifieur. Dans la littérature scientifique, plusieurs
méthodes de classification ont
étéprésentées. Dans cette partie, nous allons
présenter quelques techniques: Machines à vecteurs de support,
arbres de décision, les k-ppv, classification Naïve
Bayésienne et réseau de neurones.
Les algorithmes de Machine Learning se classent en quatre
familles ou types principaux:
· Régression
La régression sert à trouver la relation d'une
variable par rapport à une ou plusieurs autres. Dans l'apprentissage
automatique, le but de la régression est d'estimer une valeur
(numérique) de sortie à partir des valeurs d'un ensemble de
caractéristiques en entrée. Autrement dit, l'objectif est de
déterminer une fonction f qui étant donnéun
nouveau x E R prédise correctement y E R. Par exemple,
estimer le prix d'une maison en se basant sur sa surface, nombre des
étages, son emplacement, etc. Donc, le problème revient à
estimer une fonction de calcul en se basant sur des données
d'entrainement. deuxième exemple : Estimer la série (Scientifique
ou Littéraire) d'un élève en se basant sur ses
performances académiques, etc. Les principaux algorithmes de
régression sont : Régression Linéaire,
Polynomiale, Logistique, Quantile etc... tiréde GitHub [18].
Outre ces algorithmes, nous pouvons aussi avoir les arbres de
décision, SVR (Support Vector Regression ou Régression
Vectorielle de Soutien), les réseaux de neurones...
· Classification
Un problème de classification survient lorsque la
variable de sortie est une
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 22 c~NJAMEN M.
ZELKIF 2020-2021
catégorie, telle que « rouge » ou « bleu
» ou « maladie » et « pas de maladie » ou «
Scientifique » et « Littéraire » dans le cadre de
l'orientation scolaire. Un modèle de classification tente de tirer des
conclusions à partir des valeurs observées. Étant
donnéune ou plusieurs entrées, un modèle de classification
tentera de prédire la valeur d'un ou plusieurs résultats. Par
exemple, lors du filtrage des e-mails « spam » ou « pas de spam
», lors de la consultation des données de transaction, «
frauduleux » ou « autorisé». En bref, la classification
prédit les étiquettes de classe catégorielles ou classe
les données (construisez un modèle) en fonction de l'ensemble
d'apprentissage et des valeurs (étiquettes de classe) dans la
classification des attributs et l'utilise pour classer les nouvelles
données. Il existe plusieurs modèles de classification. Les
modèles de classification incluent la régression
logistique, l'arbre de décision, la forêt aléatoire,
l'arbre amplifiépar gradient, le perceptron multicouche, l'un contre le
repos et Naive Bayes. selon Lima [19]
· Partitionnement des données
Le partitionnement de données (ou data clustering en
anglais) est une méthode en analyse des données. Elle vise
à diviser un ensemble de données en différents «
paquets » homogènes, en ce sens que les données de chaque
sous-ensemble partagent des caractéristiques communes, qui correspondent
le plus souvent à des critères de
proximité(similaritéinformatique) que l'on définit en
introduisant des mesures et classes de distance entre objets.
Pour obtenir un bon partitionnement, il convient d'àla
fois :
- minimiser l'inertie intra-classe pour obtenir des grappes
(cluster en anglais) les plus homogènes possibles;
- maximiser l'inertie inter-classe afin d'obtenir des
sous-ensembles bien différenciés.
· Réduction de dimensions.
Le nombre de variables prédictives (features) pour un
set de données est ap-pelésa dimension. La réduction de
dimensionnalitéfait référence aux techniques
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 23 c~NJAMEN
M. ZELKIF 2020-2021
qui réduisent le nombre de variables dans un ensemble
de données, ou encore projettent des données issues d'un espace
de grande dimension dans un espace de plus petite dimension.
L'ensemble de données peut être un data-set
contenant un grand nombre de colonnes et un tableau de points constituant une
grande sphère dans un espace tridimensionnel. La réduction de
dimensionnalitéconsiste donc à réduire le nombre de
colonnes et à convertir la sphère en un cercle dans un espace
bidimensionnel respectivement.
Notre problème étant celui de classification,
nous allons parler des algorithmes de classification.
2.3.1 Algorithmes de Classification
2.3.2 Classification Naïve
Bayésienne
Les méthodes de classification na·ýve
Bayésienne sont un ensemble d'algorithmes d'ap-prentissage automatique
supervisébasés sur l'application du théorème de
Bayes avec l'hypothèse d'une forte indépendance
na·ýve entre chaque paire de features.
En d'autres termes, un classifieur bayésien naïf
suppose que l'existence d'une caractéristique pour une classe, est
indépendante de l'existence d'autres caractéristiques!
Problème :
Supposons que nous devions classer le vecteur A =
a1?an en in classes,
B1?Bm.
Nous devons calculer la probabilitéde chaque classe
possible sachant A pour que nous puissions étiqueter A
avec la classe Bi de plus grande probabilité.
Le théorème de Bayes nous permet de calculer la
probabilitéconditionnelle grâce à la formule
Pr[A B] = P r[B|A]P
r[A]
P r[B] C
où:
· Pr[B A, C] est la vraisemblance de
l'événement B si A et C sont
vérifiés;
· Pr[A C] est la probabilitéa priori
de l'événement A sachant C ;
· Pr[B C] est la probabilitémarginale de
l'événement B sachant C ;
· 2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 24 c~NJAMEN
M. ZELKIF 2020-2021
Pr[A|B, C] est la probabilitéa posteriori de
A si B et C.
Dans cette formulation de la règle de Bayes, C
joue le rôle de la connaissance que l'on
a.
2.3.3 Algorithme des K-PPV (K-Plus Proches Voisins) ou en
anglais KNN (K-Nearest Neighbors)
La méthode des plus proches voisins
(notéparfois k-PPV ou k-NN pour K-Nearest-Neighbor) consiste à
déterminer pour chaque nouvel individu que l'on veut classer, la liste
des plus proches voisins parmi les individus déjàclassés.
L'individu est affectéà la classe qui contient le plus
d'individus parmi ces plus proches voisins. Cette méthode
nécessite de choisir une distance, la plus classique est la distance
euclidienne, et le nombre de voisins à prendre en compte selon (SOLLAH
[20]).
La méthode K-PPV suppose que les données se
trouvent dans un espace de caractéristiques. Cela signifie que les
points de données sont dans un espace métrique. Les
données peuvent être des scalaires ou même des vecteurs
multidimensionnels selon les auteurs 'Eric and Michel [4]],[ SOLLAH [20].
La méthode des k plus proches voisins est
utilisée pour la classification et la régression. Dans les deux
cas, l'entrée se compose des k données d'entraînement les
plus proches dans l'espace de caractéristiques (SOLLAH [20]).
L'algorithme K-NN est l'un des plus simples de tous les
algorithmes d'apprentissage automatique. Il est un type d'apprentissage
basésur l'apprentissage paresseux (lazy learning).
En d'autres termes, il n'y a pas de phase
d'entraînement explicite ou très minime. Cela signifie que la
phase d'entraînement est assez rapide.
L'algorithme K-PPV figure parmi les plus simples algorithmes
d'apprentissage artificiel. Dans un contexte de classification d'une nouvelle
observation x, l'idée fondatrice simple est de faire voter les
plus proches voisins de cette observation. La classe de xest
déterminée en fonction de la classe majoritaire parmi les k
plus proches voisins de l'ob-servation x.
La méthode K-NN est donc une méthode à
base de voisinage, non-paramétrique, Ceci signifiant que l'algorithme
permet de faire une classification sans faire d'hypothèse sur la
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE
LA LITTÉRATURE
Mémoire de Master II en Informatique 25 c~NJAMEN M.
ZELKIF 2020-2021
fonction
y = f(x1, x2, ...,
xp) qui relie la variable dépendante aux variables
indépendantes.
Cette méthode utilise principalement deux
paramètres : une fonction de similaritépour comparer les
individus dans l'espace de caractéristiques et le nombre k qui
décide combien de voisins influencent la classification. Les choix de la
distance et du paramètre k sont primordiaux pour le bon fonctionnement
de cette méthode.
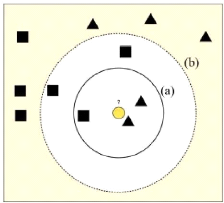
Figure 2.3 - Exemple de classification avec un
KPPV : (a) k= 3, (b) k=5. Tiréde
SOLLAH [20]
| 



