2.3.6.5 Les réseaux de neurones
célèbres
Il y a de très nombreuses sortes de réseaux de
neurones actuellement. Personne ne sait exactement combien. De nouveaux
réseaux (ou du moins des variations de réseaux plus anciens) sont
inventés chaque semaine. On en présente ici de très
classiques.
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2.
REVUE DE LA LITTÉRATURE
Mémoire de Master II en Informatique 40 c~NJAMEN M. ZELKIF
2020-2021
2.3.6.6 Le Perceptron
Le perceptron est considérécomme le premier
modèle des réseaux de neurones, il fut mis au point dans les
années cinquante par Rosenblatt (1957-1961) dans Inside Machine Learning
[30].
Selon Hervé[31], Le perceptron se compose de deux
couches de neurones la rétine (n'est pas comptéd'oùle nom
de perception monocouche) et la couche de sortie. La fonction seuil de
Heaviside est utilisée comme fonction d'activation des neurones de la
couche de sortie. La figure 2.12 montre un exemple de perceptron.
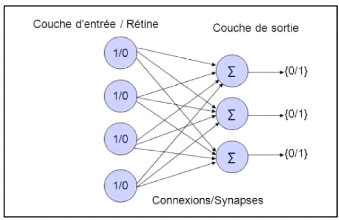
Figure 2.12 - Un exemple de perceptron
tiréde Hervé[31]
Les cellules de la première couche sont binaires,
répondent en oui / non (0/1).
Les cellules d'entrée sont reliées aux neurones
de sortie grâce à des liens synaptiques wij
d'intensitévariable.
La règle d'apprentissage du perceptron est la
règle de Widrow Hoff selon Alain [14] :
wt+1
ij = wt ij + ij(tj -
oj)xi = wt ij + /wij
· Äwij : Changement à effectuer pour
la valeur wij.
· xi : Valeur de sortie (0 ou 1) de la
ième cellule de la
rétine.
·
2.3. LES ALGORITHMES DE MACHINE LEARNING CHAPITRE 2. REVUE DE LA
LITTÉRATURE
Mémoire de Master II en Informatique 41 c~NJAMEN M. ZELKIF
2020-2021
oj : Réponse de la
jème cellule de sortie (0
ou 1).
· tj : Réponse théorique ou
(désirée) de la
jème cellule de sortie (0
ou 1).
· wt ij : Intensitéde la connexion entre
la ième cellule
d'entrée et la jème
cellule de sortie, au temps t (les valeurs
w(0)
ij sont généralement choisies au
hasard).
· : D'après les auteurs JURI'Predis [28]],[
Wikipédia [29]],[ Deeply Learning [32], Une constante positive
généralement comprise entre 0 et 1, sa valeur influe, en effet,
sur la vitesse d'apprentissage.
2.3.6.7 Le perceptron multicouches
Dans le modèle du Perceptron Multicouches, les
perceptrons sont organisés en couches. Les perceptrons multicouches sont
capables de traiter des données qui ne sont pas linéairement
séparables. Avec l'arrivée des algorithmes de
rétro-propagation, ils deviennent le type de réseaux de neurones
le plus utilisé. Les MLP sont généralement
organisés en trois couches, la couche d'entrée, la couche
intermédiaire (dite couche cachée) et la couche de sortie.
L'utilitéde plusieurs couches cachées n'a pas
étédémontrée dans Wikipédia [13]
Les PMC utilisent, pour modifier leurs poids, un algorithme
d'apprentissage, il existe une centaine mais le plus populaire est la
rétro-propagation du gradient, qui est une généralisation
de la règle de Widrow-Hoff. Il s'agit toujours de minimiser l'erreur
quadratique, on propage la modification des poids de la couche de sortie
jusqu'àla couche d'entrée, donc cet algorithme passe par deux
phases:
· Les entrées sont propagées de couche en
couche jusqu'àla couche de sortie.
· Si la sortie du PMC est différente de la sortie
désirée alors l'erreur est propagée de la couche de sortie
vers la couche d'entrée en modifiant les poids durant cette
propagation.
| 



