3.3 Pré-traitement des données
Le pré-traitement des données est une technique
d'exploration de données qui est utilisée pour transformer les
données brutes dans un format utile et efficace.
Les données réelles sont souvent
incomplètes, incohérentes et / ou dépourvues de certains
comportements ou tendances, et sont susceptibles de contenir de nombreuses
erreurs. Le prétraitement des données est une méthode
éprouvée pour résoudre ces problèmes. Le
prétraitement des données prépare les données
brutes à un traitement ultérieur. Les données passent par
une série d'étapes pendant le prétraitement.
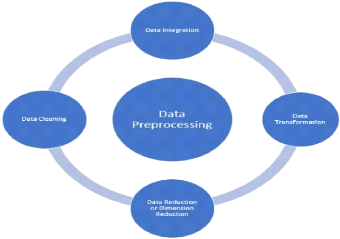
Le processus de traitement des données est
illustrépar le schéma ci-après 3.3 :
· Nettoyage des données : les données sont
nettoyées par des processus tels que le remplissage des valeurs
manquantes, le lissage des données bruyantes ou la résolution des
incohérences dans les données.
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 54 c~NJAMEN M.
ZELKIF 2020-2021
Figure 3.3 - Processus d'acquisition et
Pré-traitement des données Medium [38]
· Intégration des données : les
données avec différentes représentations sont
rassemblées et les conflits au sein des données sont
résolus.
· Transformation des données : les données
sont normalisées, agrégées et
généralisées.
· Réduction des données : cette
étape vise à présenter une représentation
réduite des données dans un entrepôt de données.
· Dans Science [39], la discrétisation des
données : implique la réduction d'un certain nombre de valeurs
d'un attribut continu en divisant la plage d'intervalles d'attribut.
3.3.1 Nettoyage des données
Les données peuvent comporter de nombreuses parties
non pertinentes et manquantes. Pour gérer cette partie, un nettoyage des
données est effectué. Cela implique le traitement des
données manquantes, des données bruitées, etc selon Lima
[40].
Le processus de Nettoyage de données est fondamental
à la préparation des données. Il permet d'améliorer
la qualitédes données en supprimant ou en modifiant les
données erronées.
Le but est d'éviter de retrouver dans la base de
données des données incorrectes. Les données peuvent
être incorrectes pour plusieurs raisons :
·
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 55 c~NJAMEN M. ZELKIF
2020-2021
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Erreurs de saisies
· Erreurs lexicales
· Erreurs de formats
· Doublons
· Données manquante
· Erreurs sémantiques
Le nettoyage des données est une étape cruciale
dans la préparation des données car toute erreur liée aux
données se répercutera inévitablement dans l'analyse des
données, c'est pourquoi les équipes portent une attention
particulière à cette étape et nous aussi.
L'augmentation de la quantitédes données
provoquent une augmentation des données incorrectes, ce qui oblige les
entreprises à adopter une multitudes de méthodes afin de les
éliminer.
Parmi ces méthodes on peut citer par exemple l'audit
de données, l'élimination des doublons par Algorithme ou encore
l'analyse syntaxique.
· (Une) ou Des. Données manquantes:
cette situation se produit lorsque certaines données
sont manquantes dans les données. Le problème des données
manquantes peut être traitéde diverses manières telles que
:
1) Ignorer les tuples
cette approche ne convient que lorsque l'ensemble de
données dont nous disposons est assez volumineux et que plusieurs
valeurs sont manquantes dans un tuple. Exemple : Au début de l'analyse
de notre data-set, nous hésitions entre considérer ou ne pas
considérer l'attribut sexe et pour finir nous avons supprimécette
colonne dans le data-set pour éviter d'avoir un modèle sexiste.
Cependant si nous avions décidéautrement, et que par exemple nous
avions eu des données manquantes pour cet attribut, nous aurions
procédécomme ci-dessous par exemple en considérant la
valeur la plus représentée si c'est F on aurait
remplacépar F et autrement par M dans le cas des M.
2) Remplissez les valeurs manquantes :
Mémoire de Master II en Informatique 56 c~NJAMEN M. ZELKIF
2020-2021
Il existe différentes manières d'effectuer cette
tâche. Vous pouvez choisir de remplir les valeurs manquantes
manuellement, par moyenne d'attribut ou par valeur la plus probable.
Par Exemple : dans notre data-set il y a eu des données
manquantes à cause de la mobilitédes élèves dans
les établissements scolaire. Certains commencent l'année dans un
établis-
sement et la termine dans un autre ce qui cause ce
problème de données manquantes. Dans ce cas, puisque ce sont des
données numériques, nous avons remplacépour chaque valeur
manquante d'un attribut, par la moyenne de toutes les valeurs de cet
attribut.
· Données bruyantes:
les données bruyantes sont des données
dénuées de sens qui ne peuvent pas être
interprétées par les machines. Elles peuvent être
générées en raison d'une mauvaise collecte de
données, d'erreurs de saisie de données, etc. Exemple dans notre
data-set, nous avons considérécomme données bruyantes les
attributs comme le TM, l'EPS etc car pour un début nous n'avons pas vu
comment ces attributs devaient contribuer ou faciliter le processus
d'orientation.
1. Méthode Binning: Cette méthode fonctionne
sur des données triées afin de les lisser. L'ensemble des
données est diviséen segments de taille égale, puis
diverses méthodes sont exécutées pour accomplir la
tâche. Chaque segmentéest traitéséparément.
On peut remplacer toutes les données d'un segment par sa moyenne ou les
valeurs limites peuvent être utilisées pour terminer la
tàache.
2. Régression : Ici, les données peuvent
être lissées en les adaptant à une fonction de
régression. La régression utilisée peut être
linéaire (ayant une variable indépendante) ou multiple (ayant
plusieurs variables indépendantes).
3. Clustering : Cette approche regroupe les données
similaires dans un cluster. Les valeurs aberrantes peuvent ne pas être
détectées ou elles tomberont en dehors des clusters.
| 



