Le but d'un projet de Machine Learning est de
développer des modèles d'apprentissage efficaces à partir
d'ensembles volumineux de données (les data-sets). La qualitéet
la quan-titédes données ont un impact direct sur
l'efficacitédu modèle résultant. Pour développer
leur capacitéà accumuler des connaissances et à prendre
des décisions de façon autonome, les machines ont en effet besoin
de consommer une grande quantitéd'informations : plus celles-ci sont
nombreuses et fiables, plus le résultat obtenu sera précis et
adaptéaux besoins de l'entreprise. C'est ainsi que pour notre sujet de
recherche, nous avons construit un jeu de donnée (data-set)
constituédes données de notes des évaluations
scolaires issues des bases de données des établissements
scolaires du Cameroun.
dans cette étape, nous avons commencépar tisser
des relations avec les détenteurs des logiciels de gestion des
établissements scolaires, car ce sont eux les sources de
génération des données. Cette étape a
étéla plus difficile de notre travail tout simplement à
cause de la confidentialitédes données des établissements
concernés, puisqu'elles (données) sont constituées des
informations financières, disciplinaires et scolaires (notes des
élèves par matières par classes).
Les données constituants notre data-set proviennent de
trois régions du Cameroun (Centre, Littoral et l'Ouest).
3.2. L'ACQUISITION (COLLECTE) DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 52 c~NJAMEN M.
ZELKIF 2020-2021
Nous avons collectéau total plus de 12.000
données issues des bases de données des établissements de
ces régions. Cependant après nettoyage et pré-traitement
sur ces données nous avons obtenu un data-set de 1000 données
à causes des bruits (les données qui disparaissent dans la BD
après une ou quelques années moins de quatre ans).
Ayant collectéles données de plusieurs sources
différentes, il nous a fallut réorganiser la base de
données suivant le schéma logique ci-dessous :
· Matières (CodeMat, NomMat)
· Enseignant(CodeEns, NomsEns, DateNais, SexeEns, CodeCls,
CodeMat)
· Élève(Matricule, NomsEl, DateNais, SexeEl,
CodeCls, CodeMat)
· Notes(CodeMat, CodeCls, CodeAnnee, E11, E12, E21,
E22, E31, E32)
· Classe(CodeCls, LibelleCls)
· Année(CodeAnne, Annee)
Les données collectées étant sur des
format différents, nous avons utiliséles requêtes SQL
(requêtes de jointures des tables) afin d'uniformiser une
représentation pour faciliter l'accessibilité, nous avons donc
obtenu le schéma ci-dessous 3.2 :
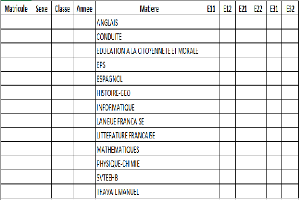
Figure 3.2 - Représentation des
données après requêtes SQL oùlesEij avec
i E {1, 2, 3} et j E {1, 2} sont
les différentes évaluations.
3.3. PRÉ-TRAITEMENT DES DONNÉES CHAPITRE 3.
DÉMARCHE MÉTHODOLOGIQUE
Mémoire de Master II en Informatique 53 c~NJAMEN M.
ZELKIF 2020-2021
Le but du processus de préparation de données
est l'obtention de données fiables, en quantitéet en
qualité, cohérentes et structurées afin que l'analyse soit
la plus performante possible.
Cependant, les problématiques liées à la
préparation des données que rencontrent les chercheurs sont
proportionnelles à la quantitédes données avec lesquelles
ils doivent travailler.
Parmi ces problématiques on peut citer entre autres
:
· Comment exploiter au mieux les données?
· Comment enrichir ses données avec des
données cohérentes?
· Comment s'assurer de la qualitédes
données?
· Comment nettoyer les données?
· Comment mettre à jour les données et les
modèles?
· Comment rendre le processus plus rapide?
· Comment réduire les coûts liés au
processus de préparation des données?




