CHAPITRE 2: CADRE METHODOLOGIQUE ET PRESENTATION DES
RESULTATS
2.1-HYPOTHESES DE RECHERCHE
En fonction de nos questions de recherche et à partir
de nos recherches documentaires, nous nous sommes proposés deux
hypothèses de recherche qui feront l'objet de vérification. Il
s'agit de :
L'hypothèse 1, qui stipule que le
modèle de marché de Sharpe, modèle utilisé
fréquemment pour estimer les bêtas, est un modèle
fonctionnel et est adapter pour l'estimation des bêtas
L'hypothèse 2, indique qu'il existe
une relation linéaire positive entre les rendements des actifs
financiers et leur risque systématique.
2-2- METHODOLOGIE
Dans le souci de procéder à la
vérification des hypothèses que nous avons émises dans le
cadre de notre recherche, nous avons adopté une méthodologie
quantitative. Celle-ci correspond à celle utilisée
généralement par la plupart des chercheurs lorsqu'il s'agit de
vérifier empiriquement un modèle. Cette méthodologie a
été adoptée en deux étapes, chacune visant à
tester une hypothèse donnée. La première étape est
consacrée à la vérification de l'hypothèse 1 selon
laquelle le modèle de marché répond à certains
critères de qualité statistique qui le rendent
fonctionnelle ; les bêtas estimés par ce modèle sont
donc dignes d'être utilisés. A cet effet, nous allons estimer les
bêtas de chaque titre par le modèle de marché de Sharpe qui
est exprimé généralement comme suit (Sharpe 1963,
1964) :
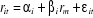 
Les estimations des paramètres 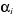 et et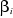 sont obtenues par l'application de la méthode des moindres
carrées ordinaires (OSL). sont obtenues par l'application de la méthode des moindres
carrées ordinaires (OSL).
Les erreurs 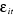 sont supposées satisfaire les hypothèses habituelles du
modèle de la régression simple : sont supposées satisfaire les hypothèses habituelles du
modèle de la régression simple :
1-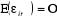 , l'espérance mathématique de , l'espérance mathématique de 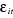 est 0 est 0
2-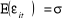 , la variance de , la variance de 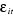 est la même pour toutes les valeurs de t. est la même pour toutes les valeurs de t.
3- 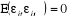 pour i pour i  s les s les 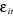 sont indépendants les unes des autres. sont indépendants les unes des autres.
4- 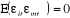 , , 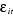 est indépendante de Rm. est indépendante de Rm.
Si les hypothèses précédentes ne sont
pas respectées, de sérieux problème de fiabilité de
la valeur des coefficients de la régression notamment 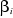 seront constatés. Par exemple si l'hypothèse de
l'homoscédasticité est violée, les estimateurs du
modèle sont sans biais et cohérents, mais ils ne sont ni
efficaces ni asymptotiquement efficaces. En présence
d'homoscédasticité les variances des coefficients de
régression sont moins précises, la matrice estimée des
covariances sera biaisée et les tests statistiques standards ne seront
pas valides. Le problème est alors identique à celui de
l'autocorrélation. La violation de la quatrième hypothèse
crée des problèmes économiques sérieux, car
l'estimation des coefficients du modèle sera biaisée et non
fiable. Si l'hypothèse de normalité des résidus n'est pas
vérifiée, nous ne seront pas en mesure d'utiliser les tests
statistiques standards. Nous devrons aussi mentionner les difficultés
rencontrées en présence de la non spécification du
modèle. seront constatés. Par exemple si l'hypothèse de
l'homoscédasticité est violée, les estimateurs du
modèle sont sans biais et cohérents, mais ils ne sont ni
efficaces ni asymptotiquement efficaces. En présence
d'homoscédasticité les variances des coefficients de
régression sont moins précises, la matrice estimée des
covariances sera biaisée et les tests statistiques standards ne seront
pas valides. Le problème est alors identique à celui de
l'autocorrélation. La violation de la quatrième hypothèse
crée des problèmes économiques sérieux, car
l'estimation des coefficients du modèle sera biaisée et non
fiable. Si l'hypothèse de normalité des résidus n'est pas
vérifiée, nous ne seront pas en mesure d'utiliser les tests
statistiques standards. Nous devrons aussi mentionner les difficultés
rencontrées en présence de la non spécification du
modèle.
Nous allons tester la violation des hypothèses
fondamentales du modèle du marché. Ainsi pour l'étude du
modèle de marché, nous devons appliquer plusieurs tests
statistiques de validité relative :
1-Test de normalité
2-Test d'autocorrelation
3- Test d'hétéroscédasticité
4-Test de spécification
5-Test de stabilité du modèle du
marché
1-Test d'éloignement de la normalité des
résidus.
A cause des résultats possibles de perturbations non
normales, nous devrons déterminer si ces perturbations proviennent de la
distribution normale. Nous avons testé la normalité des
résidus du modèle de marché en utilisant le test
statistique proposé par Jarque et Bera (1980)
Le test statistique est donné par la formule :
N - k / 6 (s² + ¼ (k - 3)²
Où N est le nombre d'observations de la
série
K est le nombre de variables de la
régression
S représente l'obliquité de la distribution
K représente la dissymétrie (kyrtosis) de la
distribution.
Sous l'hypothèse nulle de normalité, la
statistique de Jarque et Bera est distribuée selon 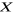 . .
2. Test
d'autocorrélation.
Nous avons utilisé le test Durbin Watson
Cette statistique est une mesure d'autocorrélation de
premier ordre et elle est donnée par la formule :
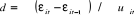
où 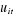 Sont les résidus de la régression du modèle de
marché. Sont les résidus de la régression du modèle de
marché.
3-Tests de l'incidence de
l'hétéroscédasticité : le critère de
White (1980).
Afin de tester
d'hétéroscédasticité en utilisant le test de White,
on doit d'abord estimer les résidus du modèle du marché et
ensuite on applique la régression sur le terme constant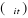 , le taux de rendement du marché , le taux de rendement du marché 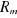 et et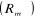 . On calcule ensuite la statistique nR², où n est le nombre
d'observations et R² est le coefficient de détermination de la
régression précitée. Si la valeur calculée est plus
petite que . On calcule ensuite la statistique nR², où n est le nombre
d'observations et R² est le coefficient de détermination de la
régression précitée. Si la valeur calculée est plus
petite que 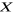 pour un niveau de signification statistique donné, nous
concluons que le modèle est homoscédasticité. Nous devons
noter que le test de White est un critère plus général
étant donné qu'il détermine si la forme fonctionnelle de
la spécification utilisée est correcte. pour un niveau de signification statistique donné, nous
concluons que le modèle est homoscédasticité. Nous devons
noter que le test de White est un critère plus général
étant donné qu'il détermine si la forme fonctionnelle de
la spécification utilisée est correcte.
4- Test de spécification.
Les différentes apparitions
d'hétéroscédasticité, d'autocorrélation, de
non normalité, de non stabilité des séries temporelles, de
non linéarité du modèle de marché,
d'instabilité de la moyenne et de la variance des régressions et
de non stabilité des bêtas tombent dans la même
catégorie générale de problème. Ramsey (1969A)
sépare en trois groupes les erreurs de spécification :
Le Groupe A comprend des omissions de variables ou une forme
fonctionnelle incorrecte ou une dépendance stochastique de X et U (non
orthogonalité). Ces erreurs introduisent des biais ou une
inconstance.
Le Groupe B présente des cas
d'hétéroscédasticité et d'autocorrection qui
influence la variance et la covariance des résidus.
Le Groupe C met en évidence les cas de non
normalité des résidus qui influence la distribution des
estimateurs. Ramsey a monté (1974 B) que quelles que soient les erreurs
de spécification pré-citées, il résulte une moyenne
différente de 0 pour le terme stochastique d'erreur.
Ainsi l'hypothèse nulle et son alternative sont
expriméEs comme suit :
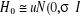 ) )
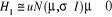
L'hypothèse nulle a été testée en
utilisant la statistique LR (Ratio de similitude) qui est distribuée
comme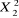 . .
1-Test pour la stabilité du modèle de
marché
La stabilité temporelle du modèle de
marché a été testée en utilisant les tests
statistiques F et LR. L'échantillon est divisé en deux
sous-ensembles et il est alors testé pour savoir si les coefficients
estimés sont statistiquement différents pour la sous
période en question.
La formule du test F est :
F =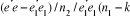 ) )
ou 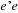 est la somme résiduelle des carrés quand
l'équation s'ajuste à toutes les observations de
échantillon n ; est la somme résiduelle des carrés quand
l'équation s'ajuste à toutes les observations de
échantillon n ; 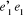 est la somme résiduelle des carrés quand
l'équation s'ajuste aux observations de échantillon est la somme résiduelle des carrés quand
l'équation s'ajuste aux observations de échantillon 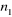 et k est le nombre de coefficients de l'équation estimée.
Pour le calcul du ratio de similitude (LR) nous utilisons de l'information
à la fois de la fonction de similitude réduite et de la fonction
non réduite. La statistique LR est distribuée comme et k est le nombre de coefficients de l'équation estimée.
Pour le calcul du ratio de similitude (LR) nous utilisons de l'information
à la fois de la fonction de similitude réduite et de la fonction
non réduite. La statistique LR est distribuée comme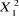 . .
La deuxième étape est consacrée à
la vérification de l'hypothèse 2 selon laquelle il existe une
relation linéaire croissante entre les rendements des actifs financiers
et leur risque systématique. Nous allons donc régresser les
rendements moyens de chaque titre sur leur bêta respectif obtenu
précédemment par le modèle de marché de Sharpe.
En s'appuyant sur le modèle théorique du CAPM,
nous avons
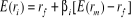
Nous définissons 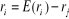 et et 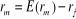
Nous avons finalement 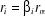
Maintenant un test évident de la forme traditionnelle
du CAPM est d'ajuster
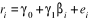
Nous supposons par ailleurs que :
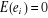 pour tout i pour tout i
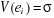 pour tout i pour tout i
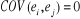 pour tout i différent de j pour tout i différent de j
Il suit que l'estimation d'un tel modèle devrait
aboutir au résultat suivant : 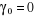 et et 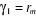
| 

