1.3 L'analyse de corpus
1.3.1 Une approche exploratoire
Nous avions dans notre mémoire de maîtrise (DRUON
(2000)) fait un exposé du fonctionnement de quelques connecteurs
consécutifs du français. Or nous savions déjà (et
nous l'avions remarqué) que la relation de conséquence
était susceptible d'être exprimée autrement que par la
présence d'un connecteur. Notre objectif cette fois-ci était de
couvrir au moins en partie les moyens d'expression de la conséquence en
français. Nous essaierons donc de nous détacher des marques
lexicales que sont les connecteurs pour essayer de repérer l'ensemble
d'indices, plus complexe, qui permettent l'interprétation
consécutive.
Nous avons donc décidé d'aborder la question avec
une approche de corpus, une approche exploratoire.
Afin d'étudier la relation de conséquence, nous
avons parcouru nos corpus avec l'intention de repérer intuitivement
toutes les relations de conséquence qui s'y trouvaient. L'idée
était qu'à partir de ce premier repérage, on pouvait
déjà avoir une vue d'ensemble sur les moyens d'expression de la
relation de conséquence dans les textes procéduraux et
scientifiques (dont nos deux corpus sont respectivement constitués).
Cette première vue d'ensemble, et cela explique le côté
exploratoire de notre approche, est obtenue par une recherche dans le corpus,
donc sans a priori sur les moyens d'expression de la conséquence.
1.3.2 Corpus utilisés
|
1. Cadre global et méthodologie
|
|
disponibles sous format électronique:
- Des textes procéduraux, en fait un ensemble de quelques
manuels d'utilisation de Linux: les «howto»;
- Le texte d'une revue de type « revue de vulgarisation
scientifique »: le numéro 335 de La Recherche.
Après analyse manuelle, nous avons obtenu l'analyse
quantitative présentée en page suivante.
1.3.3 Méthodologie
Une fois les corpus choisis, nous avons mis en oeuvre cette
approche exploratoire en plusieurs étapes:
1. Nous commençons par l'annotation manuelle de la
relation de conséquence dans les corpus, en prenant bien soin de
délimiter ses arguments et de noter pour chaque relation trouvée
quel argument se trouve être la cause et lequel est la
conséquence. Ainsi, nous pouvons extraire du texte annoté toutes
les relations de conséquence des corpus, ce qui permet une analyse plus
rapide et facile;
2. À partir de cet ensemble d'extraits
présentant des relations de conséquence, nous obtenons
après analyse une première grille des indices permettant de
repérer une relation de conséquence (connecteurs, aspect, temps
des verbes...);
3. Afin d'affiner l'analyse, nous avons extrait
automatiquement des corpus ces indices8 avec leur contexte (les
propositions qui les entourent), ce qui permet de voir dans quel cas cet indice
n'induit pas une relation de conséquence;
8Nous nous sommes pour l'instant limité
à l'extraction d'indices facilement repérables correspondant
à des mots entiers (comme les connecteurs ou les verbes modaux
devoir et pouvoir), ou bien à des formes facilement
repérables par une expression régulière comme les
participes présents.

|
Autre indice
|
|
|
Aucun indice
|
|
ceci/cela ce qui
|
pt. pr.
|
|
et
|
juxt.
|
|
analysemanuelle
|
26 16,0%
|
7 4,3%
|
2 1,2%
|
17
|
10,4% 19
|
11,6%
|
|
total
|
|
21,5%
|
|
|
22%
|
|
|
ainsi
|
|
alors
|
ce faisant
|
Connecteur
ce q fait q dans ce cas
|
|
donc
|
par csq
|
pour cette r.
|
|
23
|
14,1%
|
11
|
6,7%
|
1 0,6%
|
3 1,8% 4 2,5%
|
42
|
25,8%
|
7 4,3%
|
1 0,6%
|
|
|
|
|
|
56,5%
|
|
|
|
|

analyse manuelle
total
FIG. 1.2 - Analyse quantitative du corpus
Howto-Linux-Text-Terminal
|
1. Cadre global et méthodologie
|
|
4. Une fois déterminées ces nouvelles contraintes
sur la relation, on peut à nouveau extraire automatiquement les indices
avec leur contexte, en tenant évidemment compte de ces contraintes;
5. On obtient ainsi (en combinant la grille des indices et
les contraintes sur ces indices obtenues par une analyse plus poussée)
une description précise des éléments que nous pouvons
utiliser pour repérer automatiquement dans un texte une relation de
conséquence.
Nous avons synthétisé cette méthodologie
dans la figure 1.3 présentée en page suivante.
Notre démarche est à rapprocher de la
méthode d'exploration contextuelle de l'équipe de Jean-Pierre
Desclés (voir à ce propos MINEL et al. (2001) et DESCLÉS
et al. (1997)). En effet, ils définissent la méthodologie de
l'exploration contextuelle comme suit (elle s'applique quelle que soit la
catégorie textuelle envisagée) :
1. Identifier l'information sémantique pertinente et ses
indicateurs linguistiques;
2. Identifier le segment de contexte C nécessaire pour
prendre en compte la polysémie;
3. Écrire les étapes procédurales pour
trouver les indices linguistiques pertinents en explorant le contexte C de
façon à résoudre les ambiguïtés.
DESCLÉS et al. (1997)
Nous aborderons donc notre étude dans le même
état d'esprit, en essayant tout d'abord de trouver des indices en
présence desquels il est possible d'avoir une relation de
conséquence puis nous les compléterons avec des règles sur
le contexte de ces indices.
Nous allons maintenant poser quelques préalables
théoriques qui nous paraissent indispensables à l'étude de
la conséquence.
|
1. Cadre global et méthodologie
|
|
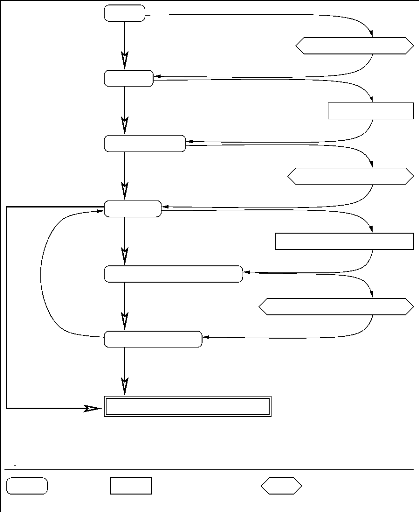
texte brut
annotation manuelle du corpus
texte annoté
extraction des relations
ensemble de relations
analyse manuelle des arguments
grille d'analyse
Ensemble d'indices avec leur contexte
contraintes sur les indices
ANALYSE COMPLÈTE DE LA RELATION
extraction d'indices avec leur contexte
analyse de la conformité avec la relation
Légende
Texte
Opération manuelle
Opération automatique
FIG. 1.3 - Méthodologie
| 

