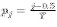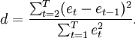Impact de l'adoption des indices Masi et Madex sur la capitalisation boursière de la bourse de Casablanca : utilisation de la régression segmentée( Télécharger le fichier original )par SAHIBI Youness - AMINE Amar Université Hassan II - Rapport de stage 2010 |

Chapitre 3: Etude d'impact1) Présentation des donnéesAfin d'étudier l'impact de la création des deux nouveaux indices Masi et Madex en 2002 nous aurons besoin des données de la capitalisation boursière. Pour cela nous avons eu recours à une base de données riche en terme d'information statistique et accessible au niveau de la Direction de la Statistique i. La série sur la capitalisation boursière : Dans notre étude, nous avons utilisé les données de la capitalisation boursière. On a opté pour des données mensuelles associées à la période allant de 1997 à 2009. 2) Vérification empiriquei. Technique utilisé : La régression segmentée La régression segmentée est une technique statistique utilisée pour mesurer l'effet d'un ou plusieurs évènements sur une série de mesures répétées dans le temps, surtout dans le cas où il n'est pas possible d'avoir un groupe contrôle en parallèle. L'évènement survenu peut être : · Intervention volontaire (ex : mise en vente d'un vaccin pour la prévention d'un cancer sur l'incidence des dépistages de ce cancer.). · Imprévu (ex : un attentat du World Trade Center sur l'indice du Dow Jones). La variable d'intérêt doit être mesurée à intervalles réguliers dans le temps. Elle peut être quantitative :
La régression segmentée est une méthode qui peut être appliquée pour étudier plusieurs phénomènes que ça soit dans l'agriculture, la pêche, la médecine ,la finance ou autres .Par exemple, Yeh et al (1983), en utilisant ce concept de la régression segmentée, a discuté l'idée d'un «seuil anaérobie » où les muscles d'une personne qui effectue un travail ne peuvent pas obtenir suffisamment d'oxygène. Dans ce cas, un modèle à deux segments est suggéré. Des exemples de ce genre dans des contextes différents sont donnés par Sprent (1961), Dunicz (1969), Schuize (1984). Dans certaines situations, même si un modèle de segmentation est considéré comme adapté, le nombre approprié de segments peuvent ne pas être connue. En générale la régression segmentée présente les avantages suivants : · Simple à mettre en place · La technique étant non paramétrique on est peut contraint par la nature des données. · On obtient d'office la sélection des variables à utilisées en tenant compte d'éventuelles interactions. · Résultats éligibles dans la mesure où les coefficients représente variation immédiate dans le temps · Obtention des intervalles de confiance pour les variations associées au facteur influent · La méthode est très extensive : on peut ainsi avoir deux segmentation ou plus, et en cas de relation non linéaire on peut appliqué des transformations sur les variables. · Cette régression peut prendre en compte plusieurs éléments lors de la construction du modèle, notamment l'inspection visuelle des données, effets retardés, autocorrélation et la saisonnalité. · Elle permet d'avoir une robustesse vis-à-vis des données erronées ou des valeurs aberrantes. Enfin pour appliquer la régression segmentée, nous aurons besoin d'effectuer les étapes de développement suivantes : Ø Observer graphiquement les données Ø Construire un modèle complet Ø Supprimer les variables non significatives Ø Ajouter les variables d'ajustement Ø Tester autocorrélation et ajouter un terme si besoin Ø Vérifier autres points de contrôles spécifiques au modèle (résidus, normalité...) ii. Construction du modèle Le modèle de régression linéaire segmentée fait l'hypothèse d'un lien linéaire entre le temps et la variable d'intérêt ; capitalisation boursière dans chaque segment. Considérons une seule intervention : la création de deux nouveaux indices : le MASI et le MADEX. Le modèle s'écrit sous la forme :
Où :
Pour mettre en pratique l'approche adoptée, nous utilisons le logiciel R. iii. Interprétation des résultats Call: lm(formula = CB ~ t + intervention + après) Residuals: Min 1Q Median 3Q Max -602527 -96473 -11935 56922 623409 Coefficients: EstimateStd. Error t value Pr(>|t|) (Intercept) 562079 106987 5.254 7.44e-06 *** t -8876 8931 -0.994 0.327 intervention -85604 148150 -0.578 0.567 après 132985 13146 10.116 6.27e-12 *** --- Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 Residual standard error: 230300 on 35 degrees of freedom Multiple R-squared: 0.9151, Adjusted R-squared: 0.9078 F-statistic: 125.8 on 3 and 35 DF, p-value: < 2.2e-16 dwtest(reg) Durbin-Watson test data: reg DW = 0.3919, p-value = 2.404e-13 alternative hypothesis: true autocorrelation is greater than 0
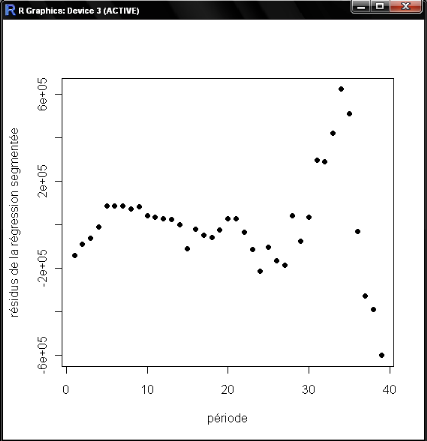
251658240les résultats montrent que le modèle de la régression segmentée explique bien les données de la capitalisation boursière (un R2 de l'ordre de 91% et un test de significativité de Fisher qui montre la validité du modèle globale) .
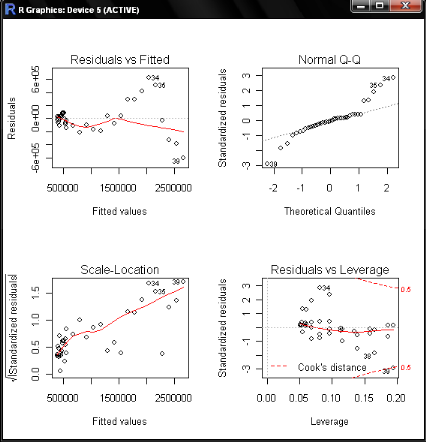
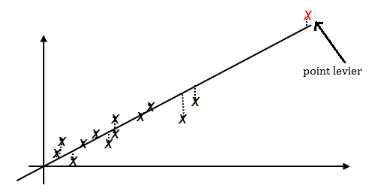
Le test de durbinwatson montre la non autocorrélation des résidus. Les graphiques Q-Q plot et les points de levier montrent la validité des hypothèses du modèle. Plus concrètement, on peut conclure que l'instauration des deux indexes a permis d'expliquer une grande part de la tendance haussière de la capitalisation boursière. Les raisons économiques de cet effet sont expliquées dans la partie précédente. Nous rappelons qu'un point levier dans la régression est une observation i qui influence considérablement les estimations parce que ses valeurs par rapport aux variables explicatives diffèrent beaucoup du reste des données. Ainsi, les observations qui présentent un grand effet de levier correspondent à des points isolés du groupe principal des données. Dans la pratique, une observation est considérée comme point levier s'elle dépasse 2P/n.
Le Q-Q Plot (ou Quantile to Quantile Plot) est un graphique
dont l'objectif est de tester la conformité entre la distribution
empirique d'une variable et une distribution théorique données.
Nous l'appliquerons au test de conformité à la distribution
normale. ou
La procédure de construction du graphique est la suivante: 1. Standardisation des observations Plus la répartition empirique se rapproche de la répartition d'une loi normale, plus les points apparaissent alignés le long d'une droite appelée droite de Henry. Le test de durbinwatson est utilisé pour détecter la présence d'autocorrélation des résidus dans l'analyse d'une régression. On peut dire que le risque d'autocorrélation des résidus augmente surtout dans les modèles estimés sur des séries chronologiques et sera encore plus grand si la périodicité est courte. Si åt est le résidu associé à l'observation au moment t, alors la statistique de test est :
Depuis d est approximativement égale à 2 (1 -r), où R est l'autocorrélation échantillon des résidus, d = 2 indique qu'il n'ya pas d'autocorrélation. La valeur de d est toujours comprise entre 0 et 4. Si d > 2 ça veut dire, qu'il y a autocorrélation négative, ce qui peut impliquer une sous-estimation au niveau du modèle. iv. Améliorations de l'approche utilisée Le modèle de régression segmentée fait une hypothèse d'indépendance entre les observations. Cette hypothèse est peu réaliste, surtout pour des données longitudinales. En plus, elle surestime la significativité des estimateurs. L'autocorrélation peut être testée soit par : ü Le biais de la visualisation graphique, en représentant les résidus Vs le temps. Ainsi, une tendance suggère une autocorrélation. ü La statistique de Durbin-Watson. Pour prendre en considération l'autocorrélation et l'introduire dans le modèle (si nécessaire), il faut estimer le paramètre correspondant. Une limite de l'approche adoptée est le liée au fait que la variable d'intérêt peut être influencée par des facteurs autres que l'intervention et le temps : ü Ex : Nombre d'interventions chirurgicales est lié au taux d'infections ü L'effet des co-variables d'ajustement. Le modèle peut être amélioré par l'introduction de plusieurs interventions, ainsi que par le fait d'effectuer des analyses stratifiées en sous-groupes. |
|


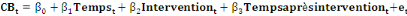
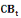
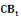 : Capitalisation boursière
: Capitalisation boursière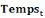
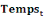 : Numéro du trimestre
: Numéro du trimestre
 : Variable binaire qui vaut 0 avant l'intervention et 1 au début
de l'intervention.
: Variable binaire qui vaut 0 avant l'intervention et 1 au début
de l'intervention.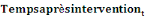
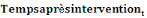 : Numéro du trimestre depuis le début de l'intervention
: Numéro du trimestre depuis le début de l'intervention