Nous avons vu que l'un des objectifs de l'analyse des
historiques de maintenance était d'optimiser les maintenances
préventives. L'une des méthodes pour le faire est l'analyse de la
fiabilité des équipements au cours du temps. Ce type
d'informations pourrait nous aider à préciser les points
suivants:
- Changer la périodicité des maintenances
préventives pour les faire correspondre au taux de panne.
- Détecter les équipements à
problèmes en examinant les taux de pannes.
- Changer les "Job Plan" afin de les faire correspondre aux
problèmes le plus fréquemment détectés.
Il existe un certain nombre de marqueurs de base de la
fiabilité que nous allons examiner dans ce chapitre (Fig.31). Ces
marqueurs sont tous basés sur des moyennes d'évènements et
doivent être utilisés avec circonspection. Bien entendu, ces
marqueurs sont tous basés sur l'analyse des maintenances correctives et
non des maintenances préventives. On peut citer:
- MTTF (Mean Time To Failure): Il s'agit de la
moyenne du temps de vie de l'équipement
avant la première panne. Il nécessite de
définir correctement l'état initial t=0.
- MTTR (Mean Time To Repair): C'est le temps
moyen de réparation d'un équipement.
Lorsque l'équipement possède plusieurs modes de
défaillance, on devra définir un taux
pour chacun d'eux.
- MDT (Mean Down Time): Est le temps moyen
entre un défaut et la remise en service de l'équipement.
- MUT (Mean Up Time): Est le temps moyen de
fonctionnement entre la dernière remise en service après
réparation et le prochain défaut.
- MTBF (Mean Time Between Failure): C'est le
temps moyen de fonctionnement entre deux défaillances de
l'équipement. MTBF=MDT+MUT.
- Taux de défaillance : Est l'inverse du
MTBF. ë=1/MTBF.
- Taux de réparation : Est l'inverse du
MTTR. ì=1/MTTR.
- Disponibilité: Elle est égale
au rapport MTBF/(MTBF+MTTR).
Marqueurs de base de la fiabilité
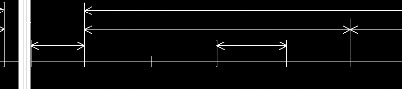
MTTR
t0 t1
t3
t2
t5
t4
End repair
Fault 2
Fault 1 Detection Start
repair
Return to service
MTBF
MDT
MUT
MTTF
t=0
time
Figure 31 Marqueurs de base de la
fiabilité.
Chacun de ces marqueurs est utilisé principalement pour
juger de la qualité de la maintenance dans les domaines suivants:
- Fiabilité: L'aptitude d'un équipement
à fonctionner dans des conditions données d'utilisation est
caractérisée par le MTBF et le MTTR.
- Disponibilité: L'aptitude d'un équipement
à fonctionner quand on le sollicite est caractérisée par
le MUT et le MDT.
- Maintenabilité: L'aptitude à être
entretenu et remis en fonctionnement est caractérisée par le MTBF
et MTTR.
- Sûreté: L'aptitude à fonctionner
tout en respectant les individus et l'environnement. Elle n'est pas
caractérisée par un de ces paramètres, mais est souvent
liée à une situation dépendante de l'état des
paramètres précédents.
Il convient aussi de se poser les questions et de
considérer les points suivants:
- Pour chacun de ces paramètres, il serait bon
d'introduire la valeur de l'écart type "" qui nous indiquera la
variabilité des valeurs autour de la moyenne. Les valeurs pouvant varier
de (Moyenne +- 2*ó). Un écart type faible indiquera une faible
variation autour de la moyenne.
- Il conviendra aussi de déterminer les conditions de
départ des calculs. Ferons-nous les calculs sur la totalité du
cycle de vie de l'équipement, entre les PM ou seulement sur une
année ? Un calcul sur plusieurs périodes permettrait de comparer
plusieurs périodes entre elles et de voir l'évolution.
- Au regard de l'organisation de l'arbre des
équipements, devrons-nous faire le calcul du MTBF et MTTR sur un
équipement seul ou sur l'ensemble des branches à partir de cet
équipement. La réponse est très dépendante de la
partie de l'arbre ou l'on se trouve. Un MTTR ou un MTBF sur l'ensemble du
chantier n'a pas de sens précis. Il n'a un intérêt que si
on l'associe à un sous équipement et surtout si l'on peut
catégoriser les types de défauts. L'objectif principal de ce type
d'information étant la gestion des maintenances préventives (PM).
On peut citer les règles de base suivantes:
· Trop de maintenances correctives et pas de PM:
Création de PM adaptées aux problèmes
rencontrés.
· Trop de maintenances correctives malgré les PM
existantes: Changement des périodicités ou du contenu des "Job
Plan".
· MTBF inférieur à l'intervalle entre PM:
Changement du contenu des Job Plans ou de la périodicité.
· MTTR trop important: Analyse des rapports de maintenance
pouvant justifier les délais.
Il existe aussi dans la littérature une notion de
"Fault Finding Interval" ou FFI [MOUB]. Le
but de cette valeur est de déterminer l'intervalle entre les
interventions à partir des informations de fiabilité des
équipements et si des possibilités de détection de pannes
potentielle existent. On part du principe que les défauts peuvent
être détectés avant qu'il se produise dans la mesure ou les
informations statistiques sont disponibles. Même si beaucoup de
défauts ne sont pas directement liés au temps de service de
l'équipement, il est souvent possible de détecter des
défauts en analysant un certain nombre d'alertes données par le
matériel lui-même. C'est ce que tente d'exprimer le diagramme
suivant (Fig.32).
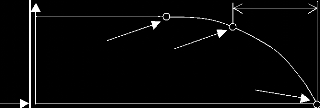
Condition P-F interval
P
Début du défaut
Point de détection possible du défaut
Le défaut s'est produit
F
Temps
Figure 32 Graphique P-F.
Entre le moment où commencent à se produire le
défaut et le point F ou il s'est produit, se trouve un ou plusieurs
points P permettant de détecter que le défaut va se produire. Il
peut exister plusieurs points P suivant la technique employée pour
détecter la faute. La zone P-F
dite zone d'alerte est celle pendant laquelle des
maintenances peuvent se produire avant le défaut complet de
l'équipement. On peut l'exprimer en unités différentes du
temps si la pratique le justifie. Si les maintenances préventives sont
faites à des intervalles supérieurs à cet intervalle, il
est possible de rater la détection. Si elles sont faites à des
intervalles trop courts, il s'agit plutôt d'une mauvaise utilisation des
ressources de la maintenance entraînant des coûts
supplémentaires.
Nous effectuerons les calculs à partir des
éléments suivants:
- Le ou les équipements ont subi des maintenances
préventives à un intervalle donné FFI et les
défauts ont été enregistrés pendant une
période donnée.
Temps total de service = Nombre d'équipement *
période de mesure des défauts. - Le MTBF a été
calculé avec les informations précédentes.
MTBF = Temps total de service / Nombres total de pannes pendant
la période.
Comme on ne sait pas si la panne se produira en début ou
en fin de période, on choisira le milieu de la période.
- Le taux de panne, %TDP doit être choisi par
l'utilisateur de l'équipement en fonction de critères qui lui
sont propres.
On calcule alors: FFI = 2 * %TDP * MTBF.
Ce type de calcul ne peut se faire en automatique que si l'on
connaît le %TDP désiré pour l'utilisateur. Ce
paramètre ne peut être défini facilement pour les 5000
équipements des chantiers. Il faudra utiliser le MTBF obtenu par le
prototype que nous allons créer ou par des données externes
fiables (constructeurs, bases de données de données de
fiabilité...) et choisir les équipements qui pourraient
être concernés par ce type de calcul. De la qualité des
données dépendra le résultat. Il faudrait aussi
considérer le cas des pannes multiples pour lesquelles ce type de calcul
n'est pas valable sauf si l'on calcule le MTBF des différents
éléments à considérer. Il faut savoir aussi que les
probabilités de pannes d'un équipement sont liées à
tous ses sous-équipements et non pas seulement aux branches de
l'arbre.
Il paraît donc difficile d'automatiser ce type de
calculs. Tout au plus pourrons-nous donner les informations de fiabilité
obtenues à l'aide des MTBF. Il restera à déterminer de
façon précise la fiabilité des données obtenues.
Données de Maximo:
Afin d'effectuer ces calculs, il nous faut disposer des
informations concernant l'état des équipements ainsi que le
détail des opérations concernant les interventions.
Dans Maximo, ces informations peuvent se trouver dans plusieurs
modules:
- Les historiques du statut des équipements pour les
arrêts (downtime). Cela ne concerne que les arrêts complets des
équipements et non les maintenances correctives. Donc, cette information
n'est pas utilisable telle qu'elle se présente.
- Un "Work Order" contient un certain nombre de champs qui nous
permettraient de retrouver ces informations.
· Le champ "Duration": Contient le
temps passé pour effectuer les opérations de maintenance, il est
facultatif et (rempli correctement 8 fois sur 10). Il devrait contenir le
nombre d'heures homme pour effectuer le travail. Toutefois, cette valeur pose
un problème, car rien n'indique le nombre de personnes ayant
effectué le travail. Nous pourrions calculer le MTTR à partir de
cette valeur, mais cette valeur sera à prendre avec précautions,
car elle correspondra à une moyenne d'un total d'heures et non à
une durée entre le démarrage des opérations et la fin des
opérations.
En pratique, à l'examen des données
entrées dans Maximo, on s'aperçoit que cette valeur correspond
plutôt au temps passé entre le début et la fin des
opérations de maintenance. Elle ne tient pas en compte le nombre de
personnes. Elle est évalué au jugé par les personnes
effectuant le travail ce qui le rend difficile à utiliser.
· Les champs "Start Date" et
"Finish Date": Doivent indiquer les dates de début et
de fin de la maintenance, mis à part la chronologie, ils ne sont pas
contrôlés et ne sont pas lié aux dates des statuts du WO.
Ce ne sont pas des champs obligatoires, mais ils sont remplis pratiquement
systématiquement. Cette valeur serait de meilleure qualité que le
champ "Duration" pour calculer le MTTR.
· Le champ "Status" associé aux
dates "Status date" ou "Reported date"
pourraient nous fournir des informations. Toutefois, il n'y a pas
forcement de lien temporel entre ces dates et celles des opérations sur
le terrain.
- Dans les historiques des "Work Order" se trouvent les dates
des différents états pris par un WO de maintenance corrective. Le
statut d'un WO ne préjuge pas des dates ni des durées de la
maintenance sur le terrain. Il n'y a pas forcement de lien temporel entre les
opérations de maintenance et les rapports effectués dans
Maximo.
- Dans notre version actuelle de Maximo, il n'existe pas de
méthode permettant de caractériser le mode de défaillance
de l'équipement. Tout calcul de MTTR se fera donc sur l'ensemble des
modes de défaillances.
- Un certain nombre de "Work Order" sont créés
pour sortir des consommables ou pour ajuster les stocks. Il ne s'agit pas de
travaux de maintenance sur les équipements. Il faudra trouver une
méthode pour les éliminer des moyennes. Il semble que le mot
REGULARIZATION soit toujours présent dans le texte de description de ce
type de WO. Toutefois, ce n'est pas une pratique formalisée et elle
pourrait être différente sur d'autres chantiers que ceux
examinés. Nous n'utiliserons pas cette méthode de filtrage.
En conclusion, seul le MTTR pourrait être
calculé d'une façon relativement précise, mais seulement
sur l'ensemble des modes de défaillances d'un équipement. Ce qui
limitera singulièrement son intérêt pour détecter
les parties des équipements générant le plus de
défaillances.
Il est difficile à partir des données de Maximo
de déterminer les dates exactes des évènements
étant intervenus sur un équipement. Ce qui rend difficile ou
approximatif le calcul des autres valeurs. Seule l'utilisation du champ
FAILDATE permettrait de palier au problème du MTBF. Il nous faudra faire
des essais d'extraction de données avec les approximations suivantes
pour pouvoir obtenir d'autres valeurs:
- Les dates les plus fiables sont les "Start Date"
et "Finish Date".
- Les temps t0, t1 et t2 seront confondus et
correspondront à "Start Date".
- Les temps t3 et t4 seront confondus et
correspondront à "Finish Date".
- Dans ce cas, le MDT=MTTR et
MTBF=MDT+MUT=MTTR+MUT.
Le résultat des calculs dépendra grandement de
la fiabilité des données entrées dans Maximo. Les
écarts types calculés pour les MTBF et MTTR nous permettront de
juger de la variabilité des valeurs autour des moyennes, mais pas de la
qualité des données. Les maintenances correctives sont par nature
aléatoires. Une forte variabilité peut aussi signifier: Des
pannes aléatoires ou des durées de réparation
aléatoires.
Proposition de prototype de calcul des marqueurs de base de
la maintenance:
Nous choisirons dans un premier temps de ne mettre que les
valeurs suivantes pour chaque équipement et pour chaque "Work Order"
CLOSE sur une période:
- Le nom du rapport sera EQPTSTAT1. L'indice laisse supposer
que nous pourrons créer d'autres rapports de mêmes types, mais
avec des affichages un peu différents. Ceci, pour la simple raison que
les paramètres de Maximo sont imités à 4.
- Les paramètres d'entrée seront les dates de
début et de fin de la période du rapport. - L'entête sera
celui utilisé en standard pour les rapports Maximo.
- Numéro de l'équipement. Le numéro
d'équipement sera décalé d'un nombre d'espaces égal
à sa profondeur dans l'arbre. On pourra au besoin choisir une autre
représentation du type " >" pour signifier le niveau.
- Classement par équipement et sous équipements.
Ce qui impliquera de reconstituer une
partie de l'arbre des équipements à partir des
données EQNUM et PARENT de la table
EQUIPMENT. Désignation de l'équipement
limitée aux 50 premiers caractères. - Le nombre de maintenances
correctives CLOSE pendant la période concernée. - Le nombre de
maintenances préventives associées à cet
équipement.
- Si l'équipement est lié à la
certification ISM. Cela permettra de vérifier d'une part que ces
équipements possèdent des maintenances
préventives et que leur taux de panne est faible.
- MTTR et variance des moyennes
trouvées. La variance est nommée SD pour "Standard
Déviation".
- MTBF et variance à partir du
premier "Work Order" CLOSE de la période. On lui donnera le nom de
MTBW (Mean Time Between Work order) afin de limiter
l'ambiguïté avec la valeur vraie qui n'utilise pas exactement les
mêmes dates.
- Seuls les équipements ayant eu au moins une maintenance
corrective seront affichés.
- Nous avons choisi pour ce premier prototype de calculer le
MTBF à chaque niveau de l'arbre et non de descendre dans chaque branche.
Il reste que cette autre logique devra être explorée aussi dans
une autre version. Dans ce cas, il doit être clair que certaines valeurs
n'auront pas de sens au fur et à mesure que nous remonterons dans
l'arbre. Un MTBF sur un groupement d'équipement de différents
types n'a pas de sens.
Analyses des données du prototype:
Après examen des données d'un des chantiers les
plus significatifs sous MS-Access, il s'avère que sur 5000
équipements, prés de 2000 sont concernés par les
maintenances correctives sur toute la durée de vie du chantier.
D'où un problème important de représentation des
résultats. Il faut donc limiter les affichages aux valeurs les plus
significatives et déterminer s'il est nécessaire de cumuler les
résultats à tous les niveaux de l'arbre.
Nous avons donc créé un prototype sous SQR qui
permet de sortir le format suivant: (Fig.33)
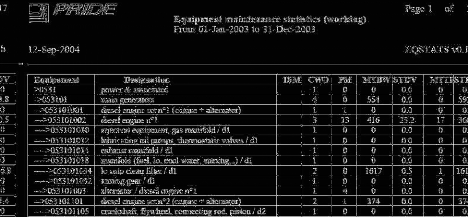
Figure 33 Exemple de tableau de
fiabilité.
L'affichage de tous les équipements donne plus de 80
pages de rapport. Une taille rédhibitoire pour un utilisateur standard.
Si on se limite aux équipements ayant eu des WO pendant la
période entrée en paramètres, on devrait obtenir une
quinzaine de pages sur une période d'un an.
On remarque les points suivants:
- La position d'une maintenance dans l'arbre des
équipements n'est pas claire. Certains utilisateurs mettent les WO
à la racine et d'autres dans les détails. Nous avons
trouvé certaines maintenances correctives à des niveaux de
l'arbre où elles n'auraient pas dû être.
- On peut noter une forte variance du MTBF sur certains
équipements. Cela peut vouloir dire soit des pannes aléatoires
soit des données fantaisistes. Nous avons trouvé beaucoup de
valeur du champ DURATION à 0 et parfois plusieurs maintenances
correctives identiques à quelques minutes d'intervalles. Il ne s'agit
pas de généralités, mais de points à surveiller.
- A l'inverse, une faible variance pourrait indiquer des
pannes récurrentes à intervalles réguliers. Dans ce cas,
il faudrait déterminer s'il existe un lien entre les pannes
rencontrées afin de pouvoir éliminer le problème s'il en
est. On pourra aussi vérifier la périodicité des PM ainsi
que le contenu des JP pour les adapter au problème.
- Le programme ne traite que les données brutes et non
des données censurées. Cela veut dire que les "Work Order" qui ne
sont pas des maintenances sont aussi traités comme des
défaillances.
- Ce rapport permet d'identifier les équipements
suivants:
· Ceux qui ont des maintenances correctives et pas de
maintenance préventive. Pour ceux la, il faudra vérifier que des
PM n'existent pas à des niveaux supérieurs de l'arbre et qu'elles
traitent les cas trouvés dans les CM.
· Ceux dont le MTBF est inférieur au temps entre
maintenances préventives. Certains
éléments pourraient
ne pas être traités dans les PM et devraient être
ajoutés au JP.
· Les équipements ISM à fort taux de
maintenances correctives ou sans maintenances préventives.
Nous avons présenté le prototype à
certains utilisateurs (TC, MSUP). Ils jugent ce type des données
difficiles à interpréter. Ils ne voient pas toujours
l'intérêt de ces informations qu'ils trouvent trop
théoriques.


