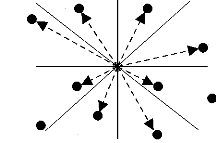
1.1.2.1/ Plus proches voisins
Le plan sur lequel se situe le point à interpoler est
découpé en octants. La méthode de calcul consiste en une
interpolation sur les huit points de référence les plus proches
du point à interpoler, répartis dans les octants. L'importance
d'un point de référence est d'autant plus grande dans le
résultat du calcul que sa distance au point à interpoler est
faible.
P8(v8)
P1(v1)
P2(v2)
Pi(vi)
P3(v3)
P7(v7)

8
)
d Pi Pm
( ,
? ?
vk
1
8
=
k
1
m
m k
?
=
vi
8
8
)
d Pi Pm
( ,
? ?
1
=
k
1m
m k
?
P6(v6)
P5(v5)
P4(v4)
L'algorithme est efficace lorsque l'on dispose de beaucoup de
points bien répartis dans la fenêtre de calcul.
On peut imaginer découper l'espace en plus ou moins huit
parties et prendre plus qu'un point observé par partie. C'est en cela
que l'on se rapproche de la méthode qui suit.
1.1.2.2/ Méthode de l'inverse des distances
La première étape est d'effectuer une recherche
des sites qui vont intervenir dans l'estimation. On peut par exemple se fixer
un rayon de recherche dont le centre est la localisation de la valeur à
estimer. On ne retiendra que les sites Si appartenant au cercle.
Dans un deuxième temps on attribue à chaque site
Si retenu un poids inversement proportionnel à la distance
entre ce site et le point à estimer S0. Considérons que
l'on a retenu n0 données dans le cercle alors on obtient comme
estimateur :
Z S
( )
i
S S
-
i 0
à
Z S
0 0 1
S S
-
i 0
?
i = 1
où |.| désigne la distance.
Les deux méthodes précédentes ont
l'inconvénient de prendre en compte uniquement la distance qui
sépare les sites entre eux. Cela donne un poids important au groupement
de données, alors qu'il n'est pas nécessairement
justifié.
1.1.3/ Résumé
Les méthodes ci-dessus ont la caractéristique de
traiter uniquement les données de la variable étudiée.
Toutes définissent la valeur recherchée en un point comme une
combinaison linéaire pondérée des mesures disponibles.
Ce sont des méthodes implémentées dans la
plus part des logiciels de Système d'Information Géographique
(SIG).
Ces techniques présentent néanmoins des
défauts. Elles ignorent la structure spatiale de la variable et
produisent du coup des surfaces interpolées très lisses. Des
situations locales très spécifiques peuvent alors être
omises (zones de fortes ou de très faibles valeurs). Nous prenons le
risque d'aboutir à des cartes peu réalistes. Enfin, aucun
critère statistique pour juger de la précision de ces cartes
n'est formulé.
Si l'on veut optimiser la précision des estimations, il
faudra utiliser d'autres outils qui feront appel à des modèles
probabilistes. La géostatistique et le krigeage en font partie. Nous
allons les étudier dans la suite.
| 

