3.2.9.2- Classification supervisée
Cette classification a été utilisée compte
tenu de la connaissance du terrain. Elle a consisté à identifier
visuellement un certain nombre d'éléments ou objets naturels ou
artificiels qui peuvent-être ponctuels, linéaires ou surfaciques
sur l'image. .
Ladite classification sous le logiciel de traitement d'image ENVI
4.3 se déroule en quatre (4) phases essentielles que sont :
- la définition de la légende ou le renseignement
du ROI (Regions Of Interest); - la sélection
des échantillons de parcelles d'entrainement (ou Regions);
- la description et renseignement des différentes
classes;
- Le choix de l'algorithme de classification.
La définition de la légende ou ROI, dans ENVI 4.3
est faite de la manière suivante : Overlay/Region of Interest
de la composition colorée. Dans ROI Tool
cliquer sur ROI Type.
Les éléments tels que forêt claire,
forêt galerie, savane boisée, savane arborée, savane
arbustive, champs et jachères et de l'eau ont été
définis pour la légende. Ce qui a
conduit à la sélection des parcelles
d'entrainement. Ainsi, différentes classes sont définies suivies
de l'attribution des couleurs.
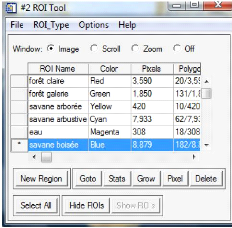
Figure 13: Fenêtre du ROI pour le renseignement de
la légende
L'algorithme Maximum Likelihood (maximum de
vraisemblance) est choisi pour la classification. Il permet de classer les
pixels inconnus en calculant pour chacune des classes la probabilité
pour que le pixel tombe dans la classe qui a la plus forte probabilité.
Cependant si cette probabilité n'atteint pas le seuil escompté,
le pixel est classé inconnu. Dans le menu principal, allez sur
Classification Supervised/Maximum likelihood, Spatial Subset ROI/EVF /
ROI / OK.
Pour éliminer les petits points, nous avons
appliqué à l'image classifiée, trois opérations de
filtrage à savoir : Sieve classes (pour éliminer
les pixels isolés) ; Clump classes (pour
homogénéiser les classes) ; Majority/minority/analysis
(pour lisser les classes après l'opération clump
classes).
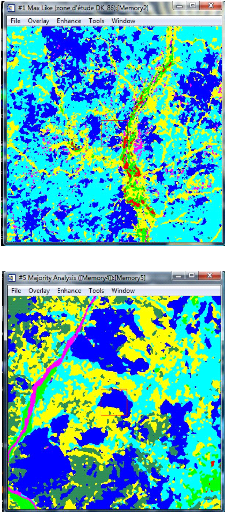
Figure 14: Image Landsat TM de 13-01-1986
classifiée
Figure 15: Image Landsat ETM + de 13-12-2000
classifiée
3.2.9.3- Validation de la classification par la matrice de
confusion
L'évaluation de la classification est basée sur
un tableau à deux dimensions appelée matrice de confusion. Ainsi
dans ENVI 4.3, aller au menu principal cliquer sur Classification /
Post Classification Confusion Matrix Using Ground Truth ROIs. La
fenêtre
classification Input File
apparaît, choix de l'image de notre classification et celle
de base du ROI dans
Open.
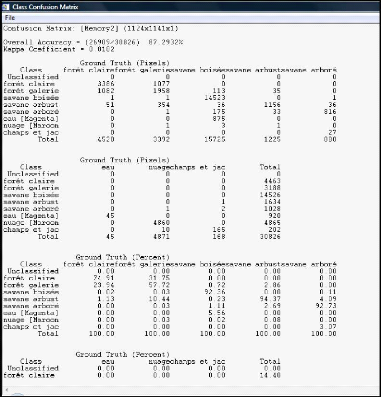
Figure 16: Fenêtre de la matrice de confusion de
l'image de 1986
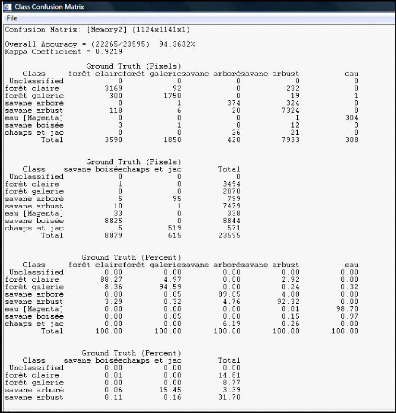
Figure 17: Fenêtre de la matrice de confusion de
l'image 2000
A partir des fenêtres de la matrice de confusion, deux
tableaux sont découlés pour interpréter les
résultats d'évaluation de la classification pour chacune des
classes (Unités d'occupation du sol).
Tableau III: Matrice de confusion des forêts
classées de Dogo-Kétou en 1986
|
TERRAIN
|
CLASSIFICATION
|
|
fc
|
fg
|
sb
|
sarbu
|
sarbo
|
eau
|
cj
|
ICV %
|
Erreur de commission %
|
|
forêt claire
|
74.91
|
31.78
|
0.02
|
0.08
|
0.00
|
0.00
|
0.00
|
88
|
12
|
|
forêt galerie
|
23.94
|
57.72
|
0.72
|
2.86
|
0.00
|
0.00
|
0.00
|
61
|
39
|
|
savane boisée
|
0.02
|
0.03
|
92.36
|
0.00
|
0.11
|
0.00
|
0.00
|
99
|
1
|
|
savane arbustive
|
1.13
|
10.44
|
0.23
|
94.37
|
4.09
|
0.00
|
0.60
|
71
|
29
|
|
savane arborée
|
0.00
|
0.03
|
1.11
|
2.69
|
92.73
|
0.00
|
1.19
|
79
|
21
|
|
eau
|
0.00
|
0.00
|
5.56
|
0.00
|
0.00
|
100.00
|
0.00
|
4.9
|
95.1
|
|
champs et jach
|
0.00
|
0.00
|
0.00
|
0.00
|
3.07
|
0.00
|
98.21
|
82
|
18
|
|
IPC%
|
88
|
58
|
92
|
94
|
93
|
100
|
98
|
|
|
Erreurs d'omission %
|
12
|
42
|
8
|
6
|
7
|
0
|
2
|
Indice de Kappa = 0.81 ICV : Critère
cartographique de validation
IPC : Indice de Pureté des Classes
ICV= Nombre total des pixels d'un theme bien classés
dans sa classe ci / Nombre total des pixels du thème Ti sur le
terrain
IPC= Nombre total de pixels bien classés dans une
classe ci / Nombre total de pixels de la classe Ci.
Erreur de commission = I - ICV
Erreur d'omission = I - IPC
Tableau IV: Matrice de confusion des forêts
classées de Dogo-Kétou en 2000
|
TERRAIN
|
CLASSIFICATION
|
|
fc
|
fg
|
sarbo
|
sarbu
|
eau
|
sb
|
cj
|
ICV%
|
Erreur de commission %
|
|
forêt claire
|
88.27
|
4.97
|
0.00
|
2.92
|
0.00
|
0.01
|
0.00
|
91
|
9
|
|
forêt galerie
|
8.36
|
94.59
|
0.00
|
0.24
|
0.32
|
0.00
|
0.00
|
85
|
15
|
|
savane arborée
|
0.00
|
0.05
|
89.05
|
4.08
|
0.00
|
0.06
|
15.45
|
47
|
53
|
|
savane arbustive
|
3.29
|
0.32
|
4.76
|
92.32
|
0.00
|
0.11
|
0.16
|
98
|
2
|
|
eau
|
0.00
|
0.00
|
0.00
|
0.01
|
98.70
|
0.37
|
0.00
|
90
|
10
|
|
savane boisée
|
0.08
|
0.05
|
0.00
|
0.15
|
0.97
|
99.39
|
0.00
|
99
|
1
|
|
champs et jachères
|
0.00
|
0.00
|
6.19
|
0.26
|
0.00
|
0.06
|
84.39
|
91
|
9
|
|
IPC%
|
88
|
95
|
89
|
92
|
99
|
99
|
84
|
|
|
Erreurs d'ommission %
|
12
|
5
|
11
|
8
|
1
|
1
|
16
|
Indice de Kappa = 0.92
ICV : Critère cartographique de
validation
IPC : Indice de Pureté des Classes
ICV= Nombre total des pixels d'un theme bien classés
dans sa classe ci / Nombre total des pixels du thème Ti sur le
terrain
IPC= Nombre total de pixels bien classés dans une
classe ci / Nombre total de pixels de la classe Ci.
Erreur de commission = I - ICV
Erreur d'omission = I - IPC
Les deux (2) tableaux de matrice de confusion montrent pour
chacune des classes, le niveau de fiabilité et les principales
confusions faits lors de la classification des images. Pour l'ensemble des
classes définies, il y a eu de confusion c'est-à-dire les pixels
de certaines unités d'occupation du sol ont été confondues
à d'autres. Mais avec l'indice de Kappa ( un indice qui permet de «
retirer » la portion de hasard ou de subjectivité de l'accord entre
les techniques), 0.81 et 0.92 que nous avons eu respectivement pour les deux
images, nous permettent de conclure que les résultats de ces
classifications sont statistiquement acceptables car selon Landis et Koch (5),
cet indice est Excellent quand il est égal à
0.81; il est Bon quand il compris entre 0.80 - 0.61; il est
Modéré quand il est compris entre 0.60 - 0.21;
il est Mauvais quand il est compris entre 0.20 - 0.0 et il est
Très Mauvais quand il est inférieur à
0.0.
| 

