Test de co-intégration
Après le test de co-intégration au sens de
Johansen, nous avons obtenu les résultats suivants :
Tableau n°3 : Test de co-intégration
|
Eigen value
|
LR
|
CV (5%)
|
CV (1%)
|
Hypothèse NO of CE(S)
|
|
0.650
|
77.597
|
47.21
|
58.46
|
Aucun**
|
|
0.521
|
35.565
|
29.68
|
35.65
|
Au moins 1*
|
|
0.143
|
6.151
|
15.41
|
20.04
|
Au moins 2
|
|
6.67E-05
|
0.003
|
3.76
|
6.65
|
Au moins 3
|
Source: Estimation des données avec le logiciel Eviews
3.1
LR : ratio de Likelihood
CV : valeur critique
*(**) signifie qu'au seuil de 1% et 5% nous rejetons
l'hypothèse de l'existence de plusieurs vecteurs de
co-intégration.
Nous rejetons l'hypothèse H0 c'est à
dire il existe plusieurs vecteurs de co-intégration aux seuils de 1% et
5%. Soit l'hypothèse H1 d'une co-intégration est
acceptée pour le produit intérieur brut réel et ses
variables indépendantes.
Comme l'hypothèse d'une co-intégration est
acceptée alors nous allons procéder à l'estimation de la
relation de long terme par la méthode de moindres carrés
ordinaires, qui est un modèle capital dans notre analyse.
A partir de l'estimation des données avec le logiciel
Eviews 3.1, nous avons obtenu la relation de long terme suivante :
Log(Y/L)=1.010 + 0.001*Infl - 0.051*RInfl + 0.008*TE
(10.50) (0.89) (-1.009)
(5.962)
R2 = 0.57 n = 41
F-Stat. = 16.663
R2 ajusté = 0.54 Prob.
(F-Stat.) = 0.000001 DW = 0.335
Le signe (+) de coefficient de variable
« inflation » signifie qu'en R.D Congo lorsque le taux
d'inflation augmente d'un pour cent, le log(Y/L) augmente aussi de 0.001 pour
cent.
Les valeurs entre parenthèses présentent la
significativité des variables. Pour notre modèle, les variables
indépendantes expliquent à 57% et 54% le comportement du produit
intérieur brut réel de la R.D Congo; car R2 et
R2 ajusté sont respectivement de 57% et 54%. La statistique
de Durbin-Watson (0.335) tend vers zéro pour notre modèle, montre
que les résidus sont corrélés.
Les valeurs t de student nous montrent que le taux d'inflation
est significativement égal à zéro tandis que les
coefficients de ratio de taux d'inflation par rapport au produit
intérieur brut réel, soit -1.009 et 5.961 pour le terme
d'échanges influencent significativement le produit intérieur
brut réel par tête en R.D Congo. La statistique F de Fisher
(16.663), nous montre que le modèle est globalement significatif et que
la variable dépendante est expliquée à raison de 57% et
54% par les variables indépendantes. En tenant aussi compte de la
probabilité de F de Fisher (0.000001 ou 0.0001%), nous pouvons dire que
le modèle est généralement significatif au seuil de 5%.
Après cette estimation de la relation de long terme entre
les variables, il nous est important d'estimer le modèle à
correction d'erreur selon l'approche à deux étapes de Engle et
Granger. La première étape consiste à estimer la relation
de long terme que nous venons de présenter au paragraphe ci haut (soit
le modèle de long terme). La seconde étape consiste à
récupérer les résidus de cette relation de long
terme « et » pour afin estimer le
modèle à correction d'erreur ou relation à court terme.
Avant d'estimer ce modèle, nous allons d'abord commencer par analyser la
stationnarité de résidus en niveau.
Tableau n°4 : Test de stationnarité des
résidus
|
Variable
|
Stat.ADF
|
VC (5%)
|
Conclusion
|
|
et
|
-1.55
|
-3.52
|
NS
|
|
D (et)
|
-7.17
|
-3.53
|
I (1)
|
Source : Calculs effectués à partir des
données avec le logiciel Eviews 3.1
Nous remarquons que nos résidus ne sont pas stationnaires
en niveau plutôt ils sont stationnaires en différences
première. Le modèle à court terme ne peut pas être
estimé par la méthode de moindres carrés ordinaires.
D'une manière générale, les variables
indépendantes choisies dans nos modèles, soit l'inflation, ratio
d'inflation et terme d'échanges total ; expliquent de 57% et 54% la
variable dépendante à long terme et à court terme, ils
n'ont aucune influence sur cette dernière.
Après une brève présentation et
interprétation de nos résultats sur l'estimation de fonction de
produit potentiel, il nous est important de faire la même chose pour
l'estimation de la fonction linéaire du produit intérieur brut
réel et le taux de chômage.
Nous avons retenu le test de Johansen pour déterminer
le nombre de relation de co - intégration entres nos variables dont les
résultats sont les suivants :
Tableau n°5: Test de co-integration
|
Eigen value
|
LR
|
CV (5%)
|
CV (1%)
|
Hypotheses et No of CE(S)
|
|
0,320
0,052
|
17,604
2,157
|
12,53
3,84
|
16,31
6,84
|
Aucun **
Au moins 1
|
Source: Estimation des données avec logiciel et Eviews
3.1
Nous rejetons l'hypothèse Ho c'est-à-dire qu'il
y a plusieurs vecteurs de co-intégration aux seuils de 1% et 5 %. Pour
la variable concernée dont LR est supérieur à CV (soit
17, 60418 supérieur à 12,53 et 16,31) Il y a un vecteur de
co-intégration. L'hypothèse H1 c'est-à-dire il existe une
relation de co-intégration, est acceptée pour la variable
« variation des produits intérieur bruit réel au tour
des son produit potentiel en pourcentage» et sa variable explicative
(variation du taux de chômage autour de son taux naturel).
En effet, comme l'hypothèse d'une relation de
co-intégration est acceptée, alors nous devons procéder
à l'estimation de la relation de long terme par les méthodes de
moindres carrés ordinaires.
Nous avons obtenu la rédaction de long terme ci-dessous
présentée à partir de logiciel Eviews 3.1. Cette
dernière est la suivante :
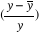 = 3,335 -
2,141 (U - Un) = 3,335 -
2,141 (U - Un)
(0,896) (-2,155)
R2 = 0.106 F - Stat = 4.645
R2 = 0.084 Prob (F - Stat) = 0.037
DW = 0.430
Les valeurs entre parenthèses présentent les
« t » de student calculés ou la
significativité de variables. Pour notre modèle, la statistique
de Durbin - Watson (0.430) tend vers zéro et cela signifie que les
résidus sont corrélés. Le coefficient de
détermination et celui ajusté sont successivement de 10.64% et
8,35%. La variable indépendante a un faible pouvoir explicative sur la
variable dépendante soit elle explique à 10.64% et 8.35% le
comportement de la variation de produit intérieur brut réel
autour de son produit potentiel en pourcentage.
Les valeurs « t » de student nous montrent
que la variation de taux de chômage autour de son taux naturel influence
significativement la variation de produit intérieur brut autour de sa
tendance en pourcentage. En R.D Congo. La probabilité F de Fisher
(0.037) montre clairement que notre modèle est a ce point significatif,
soit 3.73% < 5% (seuil utilisé). La statistique F de Fisher (4,65)
traduit que le modèle est significatif. La variable dépendante
est expliquée par la variable indépendante à raison de
10.64%, soit ce coefficient est non significatif.
Le signe attendu (-) pour la variable « variation de
taux de chômage autour de son taux naturel » est
confirmé dans notre modèle. Comme R2 = 10.64% et
R2 = 8.35%, cela veut dire que la variation du taux de chômage
n'explique pas significativement la variation du produit intérieur brut
autour de son produit potentiel en R.D Congo.
Apres cette estimation de long terme, il nous est important
d'estimer la relation de court terme, à partir du modèle de
correction d'erreur. Comme déjà fait pour le cas de fonction de
produit potentiel, nous allons faire autant, c'est - à - dire notre
modèle de correction d'erreur va s'effectuer en deux étapes.
Avant d'estimer ce modèle, nous allons d'abord
commencer par analyser la stationnarité de résidus en niveau.
Tableau n°6 : Test de stationnarité des
résidus
|
Variable
|
Stat.ADF
|
VC (5%)
|
Conclusion
|
|
et
|
-2.10
|
-1.9492
|
l (0)
|
Source : Calculs effectués à partir des
données avec le logiciel Eviews 3.1
Nous remarquons que nos résidus sont stationnaires en
niveau.
Après cette analyse de stationnarité sur les
résidus, nous avions estimé le modèle à court terme
à partir toujours de la méthode de moindres carrés
ordinaires dont les résultats sont les suivants :
D 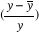 = 0.414 -
3.050 D (U - Un) - 0.236*et-1 = 0.414 -
3.050 D (U - Un) - 0.236*et-1
(0.162) (-1,640)
(-2.089)
R²= 0.124 F- stat= 2.623
R²= 0.077 Prob (F- stat) = 0.086
DW=2.125
Généralement, les modèles estimés
ne semblent pas intéressant dans la mesure où la
probabilité F de Fisher est égale à 8.6% qui est
supérieur au seuil de 5 %, c'est-à-dire que , selon ce
critère, le modèle n'est pas bon. Le coefficient de
détermination et celui ajusté s`établissent à 12.4%
et 7.7%. La valeur de DW (2.125) montre que les erreurs sont
indépendantes. Pour notre modèle, les signes attendus, (-,-),
pour la variation de taux de chômage autour de son taux naturel et les
résidus sont aussi bien confirmés à court termes
qu'à long termes. Par rapport à nos analyses, cette relation
traduit qu'en R.D Congo, la variation de produit intérieur bruit autour
de son produit potentiel en pourcentage est une fonction décroissante
ou négative de la variation du taux de chômage autour de son
taux naturel. En d'autres termes, lorsque le taux de chômage diminue
autour de son taux naturel, le produit intérieur brut réel
augmente autour de son produit potentiel à court terme en R.D Congo.
Les coefficients de correction d'erreurs sont statistiquement
significatifs et présentent les signes attendus. La force de rappel
(coefficient de résidus) qui est de - 0.236, traduit l'effet
d'ajustement de la variation de produit intérieur brut réel
autour de son produit potentiel à chaque période vers
l'équilibre.
En considérant la valeur de t de student de la
variable « variation de taux de chômage autour de son taux
naturel », qui est de -1,640 inférieur au t de student
tabulaire, nous pouvons conclure qu'à court termes la variation de taux
de chômage autour de son taux naturel n'est pas statistiquement
significative. Mais son signe prédit par la loi d'Okun se confirme
aussi bien à court terme qu'à long terme.
| 

