I.II- GENERALITES SUR LA DETECTION CFAR
I.II.1 INTRODUCTION :
Dans la vie quotidienne, on doit toujours prendre des
décisions. De même pour les problèmes de la
détection du signal radar, nous devrons prendre la décision de
l'existence ou de l'absence des cibles grâce à l'observation du
signal retourné. Le processus que le récepteur entreprend en
choisissant une règle de décision est classé sous le nom
de la théorie de la détection du signal [3].
Dans un radar, le signal utile est toujours accompagné
de bruit pour de nombreuses raisons et, en particulier, en fonction du niveau
de brouillage reçu. Si le niveau du bruit présent des variations
assez lentes, on peut modifier lentement le seuil pour maintenir la
probabilité de fausse alarme constante, mais ceci devient très
difficile lorsque les variations du niveau de bruit sont rapides. Actuellement
on utilise des récepteurs (CFAR) «Constant False Alarm
Rate », ce qui signifie une détection à taux de fausse
alarme constante: « Taux à Fausse Alarme Constante» (TFAC)
[1].
I.II.2 THEORIE DE LA DETECTION :
La détection est l'opération qui consiste
à prendre une décision sur l'existence ou pas de cibles dans
l'espace de recherche. Le principe de base de la détection d'une cible
est de comparer le signal reçu à un seuil de décision [6].
Ce problème se formalise généralement par un test
d'hypothèses binaires. La première hypothèse nulle
H0 représente un zéro (absence) où le signal
reçu est constitué de bruit seulement, et l'hypothèse
H1 représente un 1 (présence) où le signal
reçu provient des échos de la cible additionnés au
bruit.
H y t n t
: ( ) (
=
0
H y t s t n t
: ( ) ( ) ( )
= +
1
? ? ?
)
(É?1 1
Chaque hypothèse correspond à une ou plusieurs
observations qui sont représentées par des variables
aléatoires. Basé sur les valeurs d'observation de ces variables
aléatoires, l'ensemble des valeurs que la variable aléatoire
X prend constitue l'espace d'observation Z. Cet espace
d'observation est divisé en deux régions Z0 et
Z1.

)
fY/ H0
(y/ H0
)
fY/ H1 (y/ H1
MEMOIRE DEFIN D 'ETUDE LES DETECTEURS CA, OS et
ML-CFAR
Z
Z1:
Z0: décision H0 décision
H1
source
Figure I.13- Les régions de
décision
Les fonctions densité de probabilités
de Y correspondant à chaque hypothèse sont alors
notée
fY/H0(y/H0)et
fY/H1(y/H1).
On note que les deux hypothèses précédentes
donne quatre cas probabilistes possibles [3]:
1- Décidez H0 quand H0 est vrai.
2- Décidez H0 quand H1 est vrai.
3- Décidez H1 quand H0 est vrai.
4- Décidez H1 quand H1 est vrai.
L'objectif de la détection est de déterminer laquelle des deux
hypothèses est la plus vraisemblable, tout en minimisant les deux
erreurs suivantes :


Décider H0 alors que H1 est vraie. Dans
ce cas, on parle de non-détection, avec la probabilité p D H
p D H pD
( 0 / 1 ) = 1 - ( 0 / 1 ) = 1 - où PD représente la
probabilité de
détection;
Décider H1 alors que H0 est vraie. Dans ce cas,
on parle de fausse alarme, avec la probabilité
p(D1 /H0).
Dans la pratique, il est très difficile d'éviter
totalement ces erreurs, à moins de connaître parfaitement la
statistique de l'environnement du radar ainsi que la nature de la cible a
détectée [8].
|
MEMOIRE DEFIN D 'ETUDE LES DETECTEURS CA, OS et
ML-CFAR
|
|
|
|

(/ )
x H 1
1
> HP C C
0 10 00
( )
-
P C C
1 01 11
( )
-
0
(É?1 9
/ 1
H
f X
f X
x H 0
( / )
/ 0
H
<H
Ë= ( ) X
I.II.3 CRITERES DE DECISION :
1- Critère de Bayes :
En utilisant le critère de Bayes, deux suppositions
sont faites. Premièrement, les probabilités d'occurrence des deux
décisions sont a priori connues P(H0) et P(H1). P(H0)
est la probabilité d'occurrence pour l'hypothèse H0, et
P(H1) est la probabilité d'occurrence pour l'hypothèse
H1. On peut noter les probabilités a priori P(H0) et
P(H1) par P0 et P1 respectivement, avec:
La deuxième supposition est qu'un coût
Cij est assigné à chaque décision
possible (Di, Hi) avec les conditions :
Le but du critère de Bayes est de déterminer la
règle de décision qui mène à un coût moyen
minimum.
La fonction coût de Bayes, appelé aussi fonction
risque, R=E(c) est donnée par :
1 1
R E C C ij P D i H j
= =
( ) ( , )
?? (É?14
j i
= =
0 0
A partir de la règle de Bayes :
P D i H j = P D i H j P H
j
( , ) ( , ) * ( ) (É?1 5
R P C P D H P C P D H P C D H P C P D H
= + + +
( / ) ( / ) ( / ) ( / ) ( É ? 1 6)
0 00 0 0 1 01 0 1 0 10 1 0 1 11 1 1
(É?1 7
Les probabilités conditionnelles P(Di / Hj );
i,j=0, 1 en fonction des régions d'observation sont :
P(Di / Hj
)=P{décider Di /Hj est vraie} = f x H
j dx
? X / H 1 ( / )
Zi
R P C P C P C C f x H P C C f x H dx
= + + ? - - - }
{
0 10 1 11 1 01 11 / 1 1 0 10 00 0
( ) ( / ) ( ) ( / ) ( É ? 1 8
X H
Z0
Nous observons que la quantité
P0C10+P1C11 est constante, indépendamment de la façon
dont nous assignons les points dans l'espace d'observation.
En conséquence, le risque est réduit au minimum en
choisissant la région de décision Z0, pour
inclure seulement les points de Y, pour lesquels la deuxième limite est
plus grande [3].
|
MEMOIRE DEFIN D 'ETUDE LES DETECTEURS CA, OS et
ML-CFAR
|
|
|
|
Où :
Ë (X) : est le rapport de vraisemblance. P C
C
( )
-
ç = : est le seuil de décision.
0 10 00
P C C
1 01 11
( )
-
2- Critère de Neyman-Person :
Pour construire le test de Bayes, à partir du
coût moyen d'une décision, il est nécessaire de
connaître les probabilités a priori Pi , qui
déterminent la valeur du seuil auquel le rapport de vraisemblance seras
comparé. Dans la plupart des applications, ces valeurs ne sont pas
connues, et on ne peut pas appliquer l'approche de Bayes, où encore,
même si elles sont connues, le critère ajusté au
problème n'est pas obtenu à cause de ce qui se passe pour tout
l'ensemble des situations possibles. Les tests de Neyman-Person constituent,
dans ces cas, une approche alternative.
Dans ce critère, les probabilités à priori
ainsi que les coûts associés à chaque décision
sont
connus. Le test de Neyman-Person suppose que la Pfa est
fixée à une valeur a désirée, tandis
que la probabilité de détection est
maximisée. Du fait que P m = (1- Pd), donc
maximiser Pd revient à minimisé
Pm . Alors on peut former la fonction objective J comme
suit [2] :
J(ë)=Pm+ë(Pfa-á)
(É-20
Où: ë ( ë = 0) est le multiplicateur de
Lagrange. On note que pour un espace d'observation Z donné, il y a
plusieurs régions de décision Z1 pour lesquelles Pfa
OE. Donc le problème est de déterminer ces régions de
décision pour lesquelles Pm est minimale
En conséquence, nous récrivons la fonction
objective J en termes des régions de décisions pour obtenir:
J f x H dx f x H dx
ë ë á
= + ? - ?
( ) ( / ) ( / )
? ? ? ( É ? 2 1
X H X H
/ 1 1 / 0 0
?
Z 1 ? Z 1 ?
Donc l'équation (É ?2 1) devient :
J a f x H f x H dx
( ) (1 ) ( / ) ( / )
ë ë ë
= - + ? - ]
[ ( É ? 23
X H X H
/ 1 1 / 0 0
Z 0

MEMOIRE DEFIN D 'ETUDE LES DETECTEURS CA, OS et
ML-CFAR
J est réduit au minimum quand les valeurs pour lesquelles
fX/H1 (x/H 1 )
>f X / H 0 (x/H0) sont
assigné à la région Z1 de décision [3]. La solution
de l'inégalité est:

)
0 0
( /
x H
fX H /
Et nous pouvons donner la règle de décision :
H 1
( /
x H
/ 1 1 ) >
H
f X
Ë =
( )
X ë
f X
)
( /
x H 0
<H
0
/ 0
H
f x H
( / )
X H
/ 1 1 < ë
(É?24
(É?25
fX/H0 (x/ H0)
représente la probabilité conditionnelle de X sous
l'hypothèse H0. Où ë est choisi de telle
façon à satisfaire la contrainte [2].
8
Pfa f X 0 / H 0 ( x / H
0 ) dx
= ? = á (É?26
ë
I.II.4 LE DETECTERUR CFAR :
La probabilité de fausse alarme est très
sensible aux changements de la variation de la puissance du bruit, c'est pour
cette raison que l'utilisation d'un seuil fixe à la détection
classique n'est pas applicable. Une augmentation de la probabilité de
fausse alarme d'un facteur de l'ordre de 1 0-4 est provoquée
à cause d'une petite augmentation dans la puissance du bruit de l'ordre
de 3 dB comme il est montré dans la figure suivante [2].
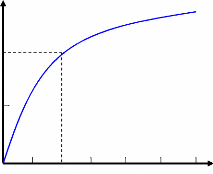
2 4 6 8 10 12
Pfa
10-4
10- 6
10- 8
Puissance du bruit (dB)
Figure I.14- Effet de l'augmentation de la puissance du
bruit
sur la probabilité de fausse alarme.
|
MEMOIRE DEFIN D 'ETUDE LES DETECTEURS CA, OS et
ML-CFAR
|
|
|
|
Le CFAR est un modèle qui se place dans la partie
traitement du signal du récepteur radar; après réception
et démodulation des échos radar, ceux-ci parcourent une
série de cellule qui sont de nombres impairs.
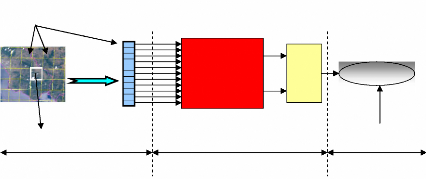
Cellules
de références
comparaison
étape1 :traitement du signal étape2:
estimation du Clutter et décision
sous test sous test
cellule
matrice à vecteur
Paramètre
d'Estimation
Seuil
Décision
cellule
Figure I.15- Schéma d'un détecteur
CFAR.
La "cellule sous test " est la cellule centrale, elle
comporte le signal à détecter. Deux fenêtres regroupant des
cellules dites "de références" qui servirons à
estimer la puissance du clutter, sont placées de part et d'autre de la
cellule de test, celle à droite est désignée par la lettre
U; et l'autre à gauche par la lettre V. Pour des raisons de
sécurité, les"cellules de garde" sont des cellules
voisines à la cellule sous test, utilisées pour éviter
tout débordement du signal mais qui ne sont pas incluses dans la
procédure d'estimation [2].
I.II.5 LES DIFFERENTS TYPES DE DETECTEURS
CFAR:
IL existe plusieurs procédés de détection
CFAR, dont la différence réside dans la méthode retenue
pour effectuer l'estimation de la puissance du clutter selon le type
d'environnement.
1)-Le détecteur CA-CFAR :
Le premier détecteur CA-CFAR (Cell
Averaging) qui a été proposé par Finn et Johnson est
illustré dans la Figure (I.16). Les échantillons à la
sortie du détecteur quadratique passent
|
MEMOIRE DEFIN D 'ETUDE LES DETECTEURS CA, OS et
ML-CFAR
|
|
|
|
dans un registre formé par un ensemble de cellules de
référence. Le niveau du clutter est estimé par la moyenne
arithmétique des échantillons dans les fenêtres de
références.
Il existe plusieurs variantes du détecteur CA-CFAR pour
lesquelles on prend soit le maximum soit le minimum des deux fenêtres, on
trouve alors :
a)-Le détecteur GO-CFAR :
Le détecteur GO-CFAR (Greatest of) a
été proposé par Hansen et sawyers. Ce détecteur
utilise le maximum des sommes des sorties des deux fenêtres du
CA-CFAR.
b)-Le détecteur SO-CFAR :
Le détecteur SO-CFAR (Smallest of) utilise le
minimum des sommes des sorties des deux fenêtres. Ce détecteur a
été proposé par Trunk.
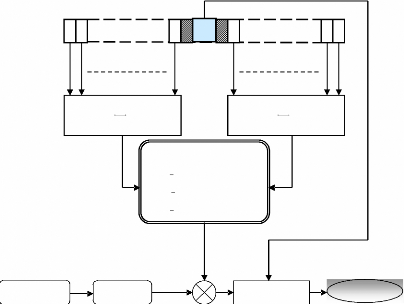
Pfa désirée
q1
U 2
=
Calcul T
N
?
i
qi
QCA
QGO
Q SO
Sélection logique
qN/2 qN/2+1
CFAR
CFAR
CFAR
Q
q0
=
= MIN U V
( , )
= MAX U V
( , )
U V
+
Comparateur
V 2
=
N
?
i
qi
qN
Décision
Figure I.16- Détecteurs CA, GO et
SO-CFAR.
26
Calcul T
Pfa désirée
MEMOIRE DEFIN D 'ETUDE LES DETECTEURS CA, OS et
ML-CFAR
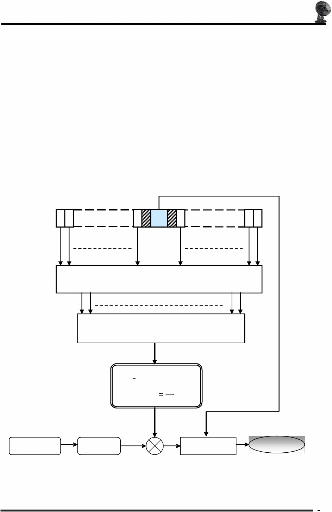
2)-Le détecteur OS CFAR :
Rohling a proposé le détecteur OS-CFAR
(Order static's), pour lequel les échantillons des cellules de
références sont ordonnés d'une façon croissante et
la puissance du bruit est prise égale au Kiéme
échantillon. Ce rang est choisi de manière à maximiser la
probabilité de détection.
3)-Le détecteur CMLD :
Rickard et Dillard ont proposé le CMLD (Censored
Mean Level Detector), afin d'éliminer les échantillons
supérieures à l'échantillon K et de faire l'estimation
à base les échantillons restants [2].
q0
qN/2 qN/2+1
q1
qN
Algorithme de classement
q q q
N
(1) (2) ( )
< < <
Algorithme de classement
q (1) < q (2) <
<q(K)
Q OS
QCMLD
CFAR
=
Q
= =
Q q
K
1
?=
i 1
k
( )
K
q i
Q
Figure I.17- Détecteurs CMLD et
OS-CFAR.
Comparateur
Décision
|
MEMOIRE DEFIN D 'ETUDE LES DETECTEURS CA, OS et
ML-CFAR
|
|
|
|
I.III. CONCLUSION:
Dans ce chapitre, nous avons étudié, le principe
de fonctionnement du system radar, ses différents composants et les
types de radars utilisés dans différents environnements.
Plusieurs méthodes de détection des cibles ont été
proposées ici ainsi que les problèmes rencontrés et les
difficultés liées à la furtivité, la fluctuation
des cibles et la présence du clutter. Généralement la
connaissance de l'environnement est un paramètre essentiel pour faire la
détection. II est à noter que le critère le plus
utilisé est celui de Neyman-Person qui consiste à maximiser la
probabilité de détection en fixant la probabilité de
fausse alarme pfa à une valeur désirée. Ce
critère est lié à la détection CFAR qui a fait
l'objet de la deuxième partie de ce chapitre.
Actuellement, plusieurs détecteurs ont été
proposés pour estimer le niveau du bruit, qui présente un
critère important pour la qualité de la détection.
A la fin de ce chapitre plusieurs types de détecteur ont
été proposés et leurs différents avantages et
inconvénients ont été exposés.
II.1.

INTRODUCTION :
Dans la détection automatique du radar, le
problème essentiel est la présence du bruit et du clutter dans
l'environnement dans le quel est faite cette détection. En plus les
paramètres statistiques liés au bruit sont
généralement inconnus.
Dans ce chapitre nous allons analysé la
détection CFAR pour les détecteurs CA-CFAR, OSCFAR et ML-CFAR
dans un environnement où les échantillons du bruit total
(bruit+clutter) sont statistiquement indépendants et identiquement
distribués. Dans un environnement réel, les échantillons
du bruit ne sont pas tous identiquement distribués (environnement non
homogène), ceci est dû à la présence d'échos
parasites dont les origines sont des cibles d'interférences
c'est-à-dire des cibles qui ne sont pas concernées par la
détection [6].
L'objectif de ce travail est l'étude du cas du clutter de
mer, où les échantillons (cellules) sont distribués
suivant une distribution Weibull.
II.2. LA DISTRIBUTION WEIBULL :
La fonction densité de probabilité Weibull est
la fonction la plus adaptée pour représenter les clutter de mer
et de terre à angle de rasage bas ou dans des situations de haute
résolution. La fonction densité de probabilité du Weibull
est une distribution à deux paramètres et pour laquelle la
distribution Rayleigh est un cas spécial.
Notre étude traite cette situation et suppose que le
milieu peut être décrit par une fonction densité de
probabilité Weibull.
C C
- 1
C ? x ? ? ? x ?
?? -
exp ? ?? ??
B ?? B ? ? B
p ( )
x

x=0; C=0; B=0 (ÉÉ?1)
,
?
?
??
Où :
x : La variable aléatoire
B : Le paramètre d'échelle, et
C : Le paramètre de forme.

II.3. ANALYSE DU DETECTEUR CA-CFAR :
La méthode d'estimation du bruit dans ce détecteur
consiste à faire la moyenne arithmétique de l'ensemble des
cellules de référence.
Si l'on considère que le bruit présente une
forme Weibull et que les amplitudes sont identiques et indépendants,
alors le détecteur quadratique dépend en X2 et la
fonction densité de probabilité est donnée par
l'équation suivante:
C -
C
1
C
)
2
P z =
( ) 2
. . exp(
z z
2 -
(ÉÉ ?2
|
En utilisant l'équation suivante:
( ) ( ) ( . ) exp( ( . ) )
r CB
. NC 1 C
N
p x = r x B r x
- -
N N
|
(ÉÉ ?3
|
Nous pourrons déterminer le seuil T utilisé dans le
CA-CFAR par l'intégrale suivante:
8 8
Pfa P X 0 TX p X dx exp b Tx p x dx
? ( ) ( ) ? [ ] ( )
C
= = = - ( ÉÉ ? 4
N N
0 0
La probabilité de fausse alarme est définie par:
Pfa =
?
?
??
T ?
+ ?
1 ?? r ??
Tel que:
r =
(ÉÉ ? 6
? + 2 ? ? ? NC ??
N N
. ( ). 1
? + 2 ?
?? C ??
Dans le cas où C est égale à 2, l'expression
de la Pfa seras donnée par:
Le facteur multiplicatif T utilisé pour satisfaire la
probabilité de fausse alarme est alors donné par:

|
T
|
=
|
2
[ ] ?
Pfa N
- 1 / N - ? +
1 2 / .
C
?? C ??
N N
? +
( ) ??
2 ?
. . 1
?? C
|
(ÉÉ ? 8
|
N
Le seuil Tz peut être écrit sous
la forme :
T Z q i T
= ?
1 .(ÉÉ?9
1
N
· L'estimateur "Optimal Weibull
:
L'estimateur "OW" a été proposé par
Anastassopoulos et Lampropoulos [9]. Cet estimateur est dérivé
à travers la distribution d'une nouvelle variable t
définie comme,
1 / C
N
? 1 C ?
t î . ??
= ?= xi ( ÉÉ ? 1 0
?? N i 1
Où:
2
î 1
= ? +C ?
?? ?? ( ÉÉ ? 1 1
Sa probabilité de fausse alarme est donnée par:
( ) N
-
C / 2
1 î
? T ?
ow .
Pfa = + ( ÉÉ ? 1 2
?? ??
N
? ?
[N
Alors, le seuilTow est donné par:
=
( 1) 2 / C
1 /
Pfa - N - (ÉÉ?1 3
? + ?
?? 1 C ??
T ow 2
Les équations précédentes montrent
clairement que l'estimateur varie en fonction du nombre
de cellules N, la
probabilité de fausse alarme Pfa, le facteur multiplicatif
Tow et le paramètre
de forme C.
Le seuil Tz peut être écrit sous
la forme :
T z = t . T ow (ÉÉ?14

II.4. ANALYSE DU DETECTEUR OS-CFAR :
Ce détecteur est basé sur la statistique
ordonnée, il consiste à classer les échantillons par ordre
croissant et le Kiéme échantillon est choisi pour
l'estimation du niveau de bruit. Le rang K est
généralement choisi égale à 3N/4 ou bien 7N/8
(supérieur à N/2), tel que N est le nombre de cellules de
références qui sont ordonnées suivant le niveau de
sortie.
X1 = X2 = =
XN (ÉÉ ? 1 5
Du fait que le détecteur quadratique dépend en
X2, pour cela on considère que le paramètre
d'échelle de Weibull B est égal à 1,
Donc:
|
2
? X ?
z X
= ? ? B ?? =
|
2
|
(ÉÉ?1 6
|
Et la fonction de probabilité :
C C
- 1
P z =
( ) 2
. . exp(
z z
2 -
) (ÉÉ?17
C
2
Le seuil Tz est donné par:
T z =á .zk
(ÉÉ?1 8
Pour des échantillons d'amplitude Xi
sont indépendants, identiquement distribué (IID) avec
une fonction densité de probabilité de Rayleigh,
Rohling a montré que la relation entre la fausse alarme et le facteur
d'échelle est donnée par [10]:
N N K
! !
( á + ?
( ! ( !
N K N
- +
á
Pfa = (ÉÉ ? 1 9
On supposant des échantillons d'amplitude pour un
milieu décrit par un (IID), et X est la variable
aléatoire avec une PDF Weibull donnée par
l'équation (ÉÉ ? 1 7 . Alors en choisissant le
paramètre de forme C=2, la fonction densité de
probabilité Weibull se réduit à une fonction
densité de probabilité Rayleigh.
La figure suivante montre la Pfa
représentée comme une fonction de C quand le facteur
d'échelle a été mis pour une Pfa= 1
0-5.

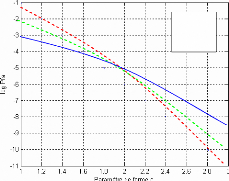
K=10
K=14
K=16
Figure II.1- Le paramètre de forme en fonction
de log Pfa.
La valeur nominale Pfa=10-5et
C=2.
On peut utiliser l'analyse de Rohling, en faisant une
substitution supplémentaire et définir la variable
aléatoire y:
la PDF exponentiel pour laquelle Rohling a
exécuté son analyse est :
P(y) = exp(-y) (ÉÉ ? 2
1
Le seuil pour y:
T y = á .yk
(ÉÉ?22
Où :
T z T y 2/C
= (ÉÉ?23
La probabilité de fausse alarme est alors définie
par:
|
Pfa
|
8 8
= - -
? ? [ ]
?
? exp( / 2 )
z C
0 ? ? á . ( )
Z K
|
?
dzp z dz
? ( K ) K
( ) ( )
? ?
|
(ÉÉ?24
|
Après le calcul de l'intégral, la
probabilité de fausse alarme est donnée par :

C / 2+ -
NK! (ÉÉ?25

!
N
( á
=
!
Pfa
(
N K
-
Cette relation est obtenue de la même manière que la
probabilité de détection en posant S=0. Tel que S ou SCR
est le rapport signal sur clutter.

N!
Pd
=
.
(N
K)!
-
?+ - C / 2 ?
? N K
? !
? 1 + S ?
á C / 2 ?
? N ? !
? 1 + S ?
á
?+
(ÉÉ ? 26
On peut écrire les deux équations
précédentes comme suit: La probabilité de détection
:

1
-
K
N i
-
=
Pd
?
(ÉÉ ? 27
i=
0 / 2
á C
N i
-
+
|
La probabilité de fausse alarme :
|
1 +
|
S
|
1
-
K
N i
-
Pfa
C
/2
á
= ? i = - +
N i
0
(ÉÉ ? 28
Ce qui nous permettons d'étudier la sensibilité de
l'algorithme de l'OS-CFAR original aux changements du paramètre de
forme.
1)- Le premier cas (C connu) :
Dans ce cas, le seuil de détection est donné
par:
T Z = T.z(K)
(ÉÉ ? 29
Où:
T 2 / C
= á(ÉÉ?3 0
Et á représente le facteur multiplicatif pour une
distribution Rayleigh.

2)- La deuxième cas (C inconnu) :
Toutes les équations précédentes sont
appliquées lorsque le paramètre de forme C est connu. Mais
lorsque le paramètre de forme est inconnu, l'analyse sera
complètement changée. Pour cela, nous allons fixés un
estimateur de C, ?, pour calculer la probabilité de détection.
L'estimateur utilisé est celui de "Dubey" [10].
Cet estimateur propose deux échantillons ordonnés
Xi et Xj , tel que :
? ln ln 1 ln ln 1
[ ( [ ( )
- - - - -
h h ( ÉÉ ? 3 1
j i
C =
ln ln
X X
-
j i
|
Où:
|
i j
hi et
=h j = ( ÉÉ ? 3 2
N + 1N+1
|
On remplaçant C par ? dans l'équation
(ÉÉ -1 7 et on pose K= i. Alors le seuil de
détection seras donné par:
â
? z ?
j
Z z .
T i z z
1? â â
( ÉÉ ? 3 3
z i
= ? ? = i j
? ?
Où:
lná i
â = ( ÉÉ ? 3 4
ln ln 1 ln ln 1
[ ( j [ ( i
- - h - - - h
| 

