2.2. Méthodologie
Nous utiliserons une approche théorique pour expliquer
l'investissement local. L'analyse macroéconomique de la décision
d'investir dans sa version la plus complète, fait appel à
l'épargne. Beaucoup d'études empiriques ont montré la
relation d'hétérogénéité entre
l'investissement et l'épargne. Mais au niveau des collectivités
locales, l'investissement n'est pas seulement de l'épargne mais il est
lié à la fois à l'épargne brute, aux besoins en
équipement, en matériel des collectivités locales et aux
différents coûts de ces besoins. Ces besoins sont exprimés
tous en termes monétaires incorporant donc les coûts de leur
réalisation. Comme Douglas et Cobb ont proposé et testé la
relation, le lien entre les intrants et les extrants dans le cadre de la
fonction de production en 1928 cite par Stadelmann (2005), du fait de la taille
des données de notre analyse et les effets d'élasticités
des facteurs entrant dans la réalisation de ces dépenses, nous
postulons que les dépenses réalisées en investissement
local peuvent être considérées comme une fonction
transformant les besoins en équipement, en matériel et
l'épargne brute en investissement réalisé qui est
considéré ici comme le produit issu de la transformation. En
effet le modèle se présente comme suit :
t= *( )a( )b( )c (1.1) avec Ai>0,
0<a+b+c+<1 Ou , , , sont toutes
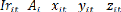
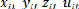
( )+1=Ai( +1)a(1+ )b( )c .
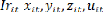
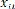
positives et désignent respectivement les besoins
prévus en matière d'investissement et la ressource disponible
pour leur financement au niveau de la commune i et de l'année t avec i
variant de 1 à N et t de t0 à T. Ils sont tous exprimés en
termes monétaires. Le coefficient Ai est un facteur qui traduit le
niveau de la politique adoptée dans la combinaison de ces facteurs pour
la commune i. Compte tenu des questions d'analyse, de la structure de nos
données et du fait que les fonctions d'expressions respectives f(x) et
f(x+1) ont les mémes propriétés et qu'elles ont la
méme fonction dérivée, nous postulons que le modèle
suivant établit la relation fonctionnelle pouvant exister entre
l'investissement local, les besoins et l'épargne brute de la
collectivité. Ledit modèle se présente comme suit :

Ce modèle sera utilisé de diverses manières
tout au long de notre étude et nous vérifierons également
les différentes hypothèses émises pour sa
validité.
Par ailleurs, la technique de l'économétrie des
données de panel est de plus en plus répandue pour évaluer
les effets des facteurs explicatifs. Elle est utilisée dans de
situations où des sources d'informations sont de plus en plus
constituées par des échantillons où les individus sont
observés de façon répétée. Le recours
à cette méthode pour la variable dépendante s'explique par
le fait qu'elle est observée sur plusieurs individus et sur six
années. De plus la relation fonctionnelle entre elle et les variables
indépendantes est la relation qui est décrite par notre
modèle théorique qui se présente de la façon
suivante :
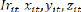

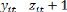
( )+1=Ai( +1)a(1+ )b( )c
Après avoir appliqué le logarithme
népérien à ce modèle, on obtient une relation
linéaire entre la variable dépendante et les variables
indépendantes.
En effet on appelle donnée de panel une combinaison des
séries temporelles simples (données portant sur un individu
observé sur une période) et des données en coupes
instantanées (données portant sur plusieurs individus
observés à un moment donné). Un panel présente donc
un ensemble d'individus observés sur une période donnée.
En plus du fait qu'elles permettent de prendre en compte à la fois les
données indexées sur le temps et celles sur les individus, les
données de panel permettent également d'avoir plus de
donnée, plus de variabilité et moins de
colinéarités. Une caractéristique fondamentale des
données est leur double dimension. Cette double dimension,
généralement individuelle et temporelle, permet d'étudier
simultanément la dynamique et
l'hétérogénéité des comportements des
individus (Nerlove et Balestra, 1995)
Mais lorsqu'on considère un échantillon de
données de panel, la toute première chose qu'il convient de
vérifier est la spécification homogène ou
hétérogène du processus générateur de
données. Sur le plan économétrique, cela revient à
tester l'égalité des coefficients du modèle
étudié dans la dimension individuelle. Sur le plan
économique, les tests de spécification reviennent à
déterminer si l'on est en droit de supposer que le modèle
théorique étudié est parfaitement identique pour toutes
les communes ou au contraire s'il existe de spécificités propres
à chaque commune.
13
Réalisé par : Bernadin
AKODE

'
...,
Décentralisation et investissement local au
Bénin
2.2.1. Procédure de tests de
spécification
On considère un échantillon de T observations de N
processus individuels
. Par suite, on notera { } et { } ces deux processus. On
suppose que le processus { } est défini de façon
générale par la relation linéaire suivante,
dimension (K,1). On considère ainsi un vecteur de K
variables explicatives : = (
Les innovations sont supposées être identiquement et
indépendamment distribuées
de moyenne nulle et de variance égale à ó?
2 i [1, N]. Ainsi on suppose que les
paramètres et du modèle peuvent différer
dans la dimension individuelle, mais l'on
suppose qu'ils sont constantes dans le temps.
Procédure
générale
Si l'on considère le modèle (1.1) plusieurs
configurations sont alors possibles :
Les N constantes et les N vecteurs de paramètres âi
sont identiques : = , âi=â
i [1, N]. On qualifie alors le panel de panel homogène
Les N constantes et les N vecteurs de paramètres sont
différents selon les individus. On
a donc N modèles différents, on rejette donc la
structure de panel.
Les N constantes sont identiques, = , i [1, N] , tandis que les
vecteurs de
paramètres diffèrent selon les individus. Dans ce
cas, tous les coefficients du modèle à
l'exception des
constantes sont différents selon les individus. On a donc N
modèles différents.
Les N vecteurs de paramètres sont identiques, =â, i
[1, N], tandis que les
constantes diffèrent selon les individus. On obtient un
modèle à effets individuels.
, ,
'+ (1.1) où = (â1i, â2i, , )' est un vecteur
de
i N, t Z, = +
Pour discriminer ces différentes configurations et pour
s'assurer du bien fondé de la structure de panel, il convient d'adopter
une procédure de tests d'homogénéité
emboités. La procédure générale dans Hsiao (1986)
cité par Christophe Hurlin et Valerie Mignon (2010) dans «
Econométrie des Données de Panel, Modèles Linéaires
Simples » ; est décrite de la façon suivante :
Test H01 = , â i [1,
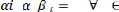
H01vraie
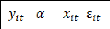
= +â' +
H01 rejetée
Test H02 =â i [1,
H02rejetee
H02vraie
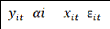
= +âi +
Test H03 = i [1, N]
H03rejetée
H03vraie

= +â' +?it
= +â' +
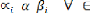
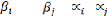
Dans une première étape, on teste
l'hypothèse d'une structure parfaitement homogène (constantes et
coefficients identiques) : H01 : = , =â i [1, N]
Ha1 : (i, j) [1, N] / ? ou ?
On utilise alors une statistique de Fischer pour tester ces
(K+1)*(N-1) restrictions linéaires. Si l'on suppose que les
résidus sont indépendamment distribués dans les
dimensions
i et t, suivant une loi normale d'espérance nulle et de
variance finie ó? 2, cette statistique suit
une distribution de Fischer avec (K+1)*(N-1) et NT-N*(K+1)
degré de liberté. Les

15
Réalisé par : Bernadin
AKODE


conclusions de ce test sont les suivantes : si l'on accepte
l'hypothèse nulle H01 d'homogénéité, on
obtient alors un modèle de pooled totalement homogène =
+â' + .
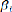
Si en revanche, on rejette l'hypothèse nulle, on passe
à une seconde étape qui consiste à déterminer si
l'hétérogénéité provient des coefficients
.
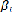
La seconde étape consiste à tester
l'égalité pour tous les individus pour les K composantes des
vecteurs

H02: â, i [1, N], Ha2 :
(i, j) [1, N] / ?
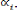
Sous l'hypothèse nulle, on n'impose aucune restriction sur
les constantes individuelles De la même façon, on construit une
statistique de Fischer pour tester ces (N-1)*K
restrictions linéaires. Toujours sous l'hypothèse
d'indépendance et de normalité des résidus,
cette
statistique suit une loi de Fischer avec (N-1)*K et NT-N*(K+1) degré de
liberté. Si l'on
rejette l'hypothèse nulle H02
d'homogénéité des coefficients, n rejette la structure
de

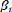
panel, puisque au mieux seules les constantes ái peuvent
être identiques entre les individus : = +âi + (2.4)
On estime alors les paramètres vectoriels en utilisant les
modèles différents individu
par individu. Si en revanche l'on accepte l'hypothèse
nulle H02 d'homogénéité des
coefficients ,
on retient la structure de panel et l'on cherche alors à
déterminer dans une
troisième étape si les constantes ái ont une
dimension individuelle.
La troisième étape de la procédure consiste
à tester l'égalité des N constantes individuelle sous
l'hypothèse de coefficients âi communs à tous les individus
:

H03 : = , i [1, N], Ha3 : (i, j)
[1, N] / ?
Sous l'hypothèse nulle, on impose
âi=â. Sous l'hypothèse d'indépendance et
de normalité des résidus, on construit une statistique de Fischer
pour tester ces N-1 restrictions linéaires. Cette statistique suit une
loi de Fischer avec (N-1)*K et N*(T-1)-K degré de liberté.
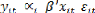
Si l'on rejette l'hypothèse nulle
d'homogénéités des constantes ái, on obtient alors
un modèle de panel avec effets individuels
= + + (2.5)
Dans le cas où l'on accepte l'hypothèse nulle H0
3, on retrouve alors une structure de panel totalement
homogène (modèle de pooled). Le test H03 ne sert
qu'à confirmer ou infirmer les conclusions du test H01,
étant donné que le fait de réduire le nombre de
restrictions linéaires permet d'accroitre la puissance du test de
Fischer.
Ces différents tests nous confirment la structure de
panel de notre échantillon. Ainsi nous abordons, en matière des
données de panel, les deux types de modèles à savoir : les
modèles à effets communs et les modèles à effets
individuels.
2.2.2. Les modèles a effets communs
Les modèles à effets communs sont ceux
formulés sous l'hypothèse d'uniformité des comportements
entre les individus. Ceci revient à supposer que les différents
coefficients du modèle sont indépendants du temps et identiques
entre les individus. Ce type de modèle peut s'écrire de la
façon suivante.
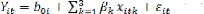
(2.1)

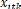
b0i=ordonnée à l'origine, i désigne un
individu quelconque tel que i {1,2,..., N} ; k désigne le nombre de
variables exogènes et la période considérée tel que
k {1,2,...,K} t €{1,2,...,T} et représente la valeur de la variable
exogène.
| 

