2.3.3 Validation du modèle
Il existe un certain nombre de test qui rendent compte de la
significativité du modèle et des coefficients. Il s'agit entre
autre au test du rapport de vraisemblance du modèle et du pseudo R2 de
Mc-Fadden pour la significativité du modèle et du test de Wald et
du ratio de vraisemblance pour la significativité des coefficients. Bien
que ces tests soient d'une importance capitale, on ne les interprète que
peu souvent dans le cadre des variables qualitatives. Pour valider le
modèle, on s'intéressera plus au taux de bon classement de
l'échantillon d'apprentissage et de l'échantillon test et
à la courbe ROC. Nous présenterons ici ces derniers.
Taux de bonne prédiction ou taux de bon classement
(TBC)
On peut comparer les performances de deux modèles en
comparant leur pouvoir prédictif. On peut comparer les performances de
deux modèles en comparant leur pouvoir prédictif, c'est-a-dire
leur capacité à classer correctement les observations. Pour cela,
il faut définir une stratégie de prédiction ou
d'affectation sous la forme :
On décide que y i = k quand
pà i 3 p et y i = j
sinon.
En pratique, on divise l'échantillon en deux groupes :
- Un Echantillon qui permet d'élaborer le
modèle appelé échantillon d'apprentissage (environ 70% de
l'échantillon total)
- Un Echantillon qui permet de tester le modèle
nommé échantillon test (environ 30% de l'échantillon
total).
EVALUATION DE L'EFFICACITE DES MOUSTIQUAIRES
IMPREGNEES A LONGUE DUREE D'ACTION SUR LA REDUCTION DU PALUDISME DANS LA
LOCALITE DE
LIBAMBA
Juin
2013
Rédigé par Hokameto Rodrigue Junior
EDORH, Elève Ingénieur d'Application de la
Statistique, 4ème Année
28
On construit pour chacun des deux échantillons une matrice
de confusion :
Prédiction
Vrai
|
Positif
|
Négatif
|
Positif
|
Vrai positif (VP)
|
Faux Négatif (FN)
|
Négatif
|
Faux Positif (FP)
|
Vrai Négatif (VN)
|
|
Le taux de bon classement est :
|
TBC
|
|
VP+VN
|
|
|
|
|
VP+FP+FN+VN
Le "meilleur" modèle est celui avec le plus grandTBC
au niveau de l'échantillon d'apprentissage et de
l'échantillon test.
En marge du TBC il est nécessaire que le taux de vrai
positif (TVP) et de Vrai Négatif (TVN) soit également
élevé.
Le TVP encore appelé sensibilité est donné
par la formule :
TVP = Sensibilité
|
=
|
VP VP
|
|
|
Le TVN encore appelé spécificité est
donné par :
VN VN
TVN = Spécificité = =
Négatif FP+VN
Cependant cette méthode a des désavantages dans la
mesure où elle dépend de p . Par exemple, si on fixe le
seuil p =0,5, elle attribuera le même résultat à
deux individus ayant l'un une probabilité estimée de 0,45 et
l'autre une probabilité de 0,001.
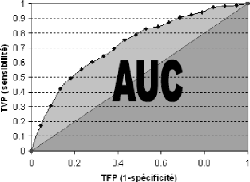
- Courbe ROC (Receiving Operating
Characteristics)
Elle vient pallier les désavantages de la méthode
précédente dans la mesure où le seuil p n'est
plus fixe mais il varie de 0 à 1.
On calcule pour chaque valeur de p E [ 0, 1] la
sensibilité et 1-spécificité (Taux de faux positif).
On trace ensuite la courbe de la sensibilité (en
ordonné) en fonction de 1-spécificité (en abscisse)
EVALUATION DE L'EFFICACITE DES MOUSTIQUAIRES
IMPREGNEES A LONGUE DUREE D'ACTION SUR LA REDUCTION DU PALUDISME DANS LA
LOCALITE DE
LIBAMBA
Juin
2013
Rédigé par Hokameto Rodrigue Junior
EDORH, Elève Ingénieur d'Application de la
Statistique, 4ème Année
29
Source : RAKOTOMALALA, 2013
AUC indique la probabilité pour que la fonction SCORE
(P(yi = 1)) place un positif devant
un négatif. Plus AUC est proche de 1, plus le pouvoir
prédictif du modèle est élevé. Il est souhaitable
qu'il se situe au dessus de 0,80). Si AUC est proche de 0,5 (la courbe est
confondue avec la diagonale) le modèle ne sert à rien.
Dans ce chapitre nous avons relaté la
méthodologie de notre travail en parlant de l'enquête
réalisée auprès des ménages de Libamba (EPUM) qui
s'est tenue du 4 au 6 avril 2010. Ensuite nous avons fait état de
comment se fait l'évaluation en épidémiologie. Nous avons
fini ce chapitre par la présentation du modèle de
régression logistique.
| 

