
République Algérienne Démocratique
et Populaire
Ministère de l'Enseignement Supérieur et de la
Recherche Scientifique
Université des Sciences et de la Technologie
Houari Boumediene
Faculté des
mathématiques
Département de probabilités et
statistique
Thème
Implémentation d'une nouvelle méthode
d'estimation
de la matrice VAR-COV basée sur le modèle
GARCH
multivarié.
Simulation par Backtesting de stratégies
d'investissements.
Réalisé par :
Mr: M. Al lamine Ahmat Alhabo Mr: Khaled
Layaida
Promotrice : Proposé par:
Mme H. Guerbyenne Mr Y. Vernaz
Devant le jury :
Mme. DJ. SEDDIKI Présidente de
jury
Mme H. GUERBYENNE Promotrice
tièes
Mr. A.AKNOUCHE Examinateur
Mr. F . HAMDI Examinateur
Mr. H.BELBACHIR Examinateur
Promotion 2007/2008
Remerciements
Louange à ALLAH, le miséricordieux, sans Lui
rien de tout cela n'aurait pu être.
Nous remerciement ALLAH qui nous a
orienté au chemin du savoir et les portes de la
science. Nous tenons
à remercier vivement tous ceux qui nous ont aidés de prés
ou de loin à
l'élaboration de ce mémoire ; on pense
particulièrement à :






Notre promotrice Mme Guerbyenne qui nous a beaucoup
guidé avec ses précieux conseils et orientations, et qui a
donné tout son temps pour réaliser ce mémoire.
Notre encadreur Mr Yann Vernaz qui nous a beaucoup
aidé avec ses conseils et orientations précieuses.
A notre jury Mr F.Hamdi, Mr H.Belbachir, Mr M.Aknouche, et
Mme la présidente D.Seddiki.
Mr H.Benbouteldja et Mr N.Layaida qui nous ont beaucoup
aidés pour la réalisation de ce mémoire.
Nos enseignants Mme H. Guerbyenne, Mme O.Sadki, Mme
K.Djaballah, Mr Assem, Mr et Mme Yahi, Mme Djemai, Mr A.Rebbouh, Mr
M. Tatachak, Mr Astouati, Mr M. Djeddour, Mr M.El Bahi, Mme
H.Saggou, Mme Madani et à tous les autres enseignants du
département de Probabilités et Statistique.
Nous remercions également nos familles respectives qui
nous ont aidés, encouragés et soutenus dans les moments
difficiles tout au long de la préparation de cette thèse.
TABLE DES MATIERES
INTRODUCTION 6
PERTINENCE DU SUJET 7
LA SOCIETE RAISEPARTNER 8
Chapitre 1: Processus aléatoires
I. PROCESSUS ALEATOIRES STATIONNAIRES ET PROCESSUS ARMA 10
I.1 DEFINITION D'UN PROCESSUS STOCHASTIQUES 11
I.2 PROCESSUS STATIONNAIRES 11
PROCESSUS BRUIT BLANC 13
I.2.2 Fonction d 'autocovariance 14
I.2.3 Fonction d 'autocorrélation 15
I.2.4 Fonction d 'autocorrélation partielle 16
I.2.5 Opérateurs 17
I.3 TOPOLOGIE DES MODELES ARMA 18
I.3.1 Processus autorégressif d'ordre p AR (p)
18
I.3.2 Processus moyenne mobile d'ordre q (Moving Average) MA
(q) 19
I.3.3 Processus autorégressif moyenne mobile d'ordre
(p, q) ARMA (p, q) 20
II. PROCESSUS ALEATOIRE NON STATIONNAIRE 21
II.1 COMPOSANTES DES SERIES TEMPORELLES 22
II.2 METHODE GRAPHIQUE 22
II.3 METHODES ANALYTIQUES 23
II.3.1 Analyse de la tendance 23
V. Analyse de la saisonnalité 26
III. EXTENSION DES MODELES ARMA 28
AUX METHODES EXPOSEES CI-DESSUS (POUR RENDRE LA SERIE
STATIONNAIRE). 28
III.1 PROCESSUS AUTOREGRESSIF MOYENNE MOBILE INTEGRE D'ORDRE
(P,D,Q) 29
III.2 PROCESSUS AUTOREGRESSIF MOYENNE MOBILE INTEGRE SAISONNIER
29
III.3 MODELES SAISONNIERS MIXTES SARIMA 29
III.4 MODELES SAISONNIERS PURS (SARMA) 30
Chapitre2: La méthodologie de Box et
Jenkins
I. INTRODUCTION 31
II. DEMARCHE DE LA METHODE DE BOX ET JENKINS 32
II.1. ANALYSE PRELIMINAIRE 32
II.3. L'IDENTIFICATION DU MODELE ADEQUAT 32
II.3 ESTIMATION DES PARAMETRES DU MODELE 33
II.4 VALIDATION 33
II.4.1 Tests concernant les paramètres 34
II.4.2 Tests sur les résidus 34
II.4.3 Choix du Meilleur Modèle 40
II.5 PREVISION 42
Application de la méthodologie de Box et
Jenkins
MODELISATION DE LA SERIE SPY 45
MODELISATION DE LA SERIE IEV 62
MODELISATION DE LA SERIE QQQQ 77
MODELISATION DE LA SERIE GLD 88
Chapitre 3: Lissage exponentiel
I INTRODUCTION 101
II PRINCIPE DE BASE 101
III DESCRIPTION DE LA METHODE 101
IV LISSAGE EXPONENTIEL SIMPLE 102
V CHOIX DU COEFFICIENT DE LISSAGE 104
VI LISSAGE EXPONENTIEL DOUBLE 105
VII METHODE DE HOLT-WINTERS 105
Application lissage exponentiel
ETUDE DE LA SERIE QQQQ 107
ETUDE DE LA SERIE IEV 109
ETUDE DE LA SERIE GLD 111
ETUDE DE LA SERIE SPY 113
COMPARAISON DES METHODES : 115
Chapitre4 :Les Modèles
Hétéroscédastiques Univariés
INTRODUCTION 117
I. DIVERSES MODELISATIONS 117
I.1 MODELE ARCH (Q) 117
I.2 MODELE GARCH (P, Q)( BOLLERSLEV [1986 ]) 118
II. ESTIMATION, PREVISION [CHRISTIAN GOURIEROUX] 122
II.1 ESTIMATION 122
II.1.1 Estimation par le pseudo maximum de vraisemblance
(PMV) 122
II.2 PREVISION 124
II.2.1 Forme des intervalles de prévision 124
III. EXTENSIONS DES MODELES ARCH / GARCH LINEAIRES ET NON
LINEAIRES 126
III.1 MODELE IGARCH 126
III.2 MODELE GARCH-M 127
III.3 MODELE EGARCH 128
III.5 MODELE TGARCH 131
IV SERIES DE RENDEMENTS 132
Application des séries de rendements
ANALYSE ET ESTIMATION DES SERIES DE RENDEMENTS 135
Chapitre5 :Les Modèles
Hétéroscédastiques Multivariés
I. INTRODUCTION 142
II. MODELE VEC 142
III. MODELE BEKK 145
IV. MODELE CCC 146
ESTIMATION DE LA MATRICE DE CORRELATION 147
IV.1 TEST DE CONSTANCE DE CORRELATION 147
V. MODELE DCC (DYNAMIC CONDITIONAL CORRELATION) 149
V.1 ESTIMATION DES PARAMETRES 151
IV.2 ESTIMATION DE LA CORRELATION CONDITIONNELLE 152
V.2 PROPRIETES ASYMPTOTIQUES DE LA METHODE DU PMV 153
V. APPROCHE THEORIQUE DE LA GESTION DE PORTEFEUILLE : 154
V.2 DEFINITION D'UN PORTEFEUILLE 155
RENDEMENTS D'UN PORTEFEUILLE : 156
RISQUE D'UN PORTEFEUILLE ET ATTITUDE DE L'INVESTISSEUR : 156
1. Mesure de risque : 156
2. Risque d'un portefeuille : 157
APPLICATION DE LA METHODE MULTIVARIEE 162
SIMULATION PAR BACKTESTING DE STRATEGIES
D'INVESTISSEMENTS 172
CONCLUSION GENERALE 193
ANNEXE A : SYMBOLES ET TABLEAU 196
ANNEXE B : ALGORITHMES 199
BIBLIOGRAPHIE 211
A. OUVRAGES 211
B. MEMOIRES 213
C. INTERNET 214
Introduction
Les cours des actifs financiers ont subi, au cours de ces
dernières années, de très fortes fluctuations. Ces
mouvements spectaculaires ont ravivé l'intérêt porté
à la question de la volatilité des marchés financiers par
les cercles académiques, comme par les praticiens et les
autorités de régulation et de contrôle. L'analyse de ces
phénomènes est d'autant plus justifiée que les chocs
boursiers ne sont pas sans conséquences en termes de stabilité
financière et qu'ils peuvent s'accompagner de répercussions sur
la sphère réelle.
Cependant la classe des modèles ARCH et GARCH constitue
une réponse appropriée pour prendre en compte les
spécificités de la volatilité qui ne peuvent pas
être prises en compte par les méthodes
«traditionnelles». Initialement, ce type de modèles est
développé dans un cadre univarié. De fait, il laisse une
large place à l'aspect descriptif plutôt qu'explicatif.
L'extension de cette classe de modèles à un cadre
multivarié a permis de remédier aux critiques des modèles
univariés qui se révélaient insuffisants pour justifier la
composition du portefeuille. En effet, la théorie financière
postule que les covariances entre les actifs jouent un rôle
déterminant dans la prise de décision des investisseurs dans
leurs stratégies de placement. Or, les modèles univariés
négligent cet aspect, qui demeure essentiel dans le choix du
portefeuille. On remarque, cependant, que le développement des
modèles ARCH et GARCH multivariés conduit à une inflation
des paramètres à estimer. Ils sont donc devenus difficilement
exploitables, si aucune contrainte supplémentaire n'est imposée.
Ainsi, différentes méthodes de paramétrisation furent
développées dont deux ont connu plus de succès que les
autres. Il s'agit des méthodes proposées par Bollerslev (1990) et
par Engle (2002).
Bollerslev (1990) a suggéré d'adopter des
modèles où les corrélations conditionnelles entre les
perturbations sont constantes dans le temps (Constant conditional correlation).
L'intérêt de cette hypothèse est qu'elle réduit
considérablement le nombre de paramètres à estimer dans la
classe des modèles ARCH et GARCH multivariés. Quant à
Engle (2002), il a conçu une nouvelle approche (Dynamic conditional
correlation), en deux étapes, selon laquelle les corrélations
sont dynamiques. Cette nouvelle classe de modèles GARCH
multivariés se distingue par sa simplicité dans le sens où
des spécifications GARCH univariées sont estimées pour
chaque série séparément. Et les corrélations
dynamiques sont estimées, dans une seconde étape, à partir
des résidus standardisés issus de la première
étape.
Les méthodologies adoptées sont celles des
corrélations conditionnelles Constantes CCCGARCH, de Bollerslev et des
corrélations conditionnelles dynamiques, conçue par Engle. Le
principal avantage de l'utilisation des modèles DCC-GARCH tient au fait
que la détection de
plausibles changements des liens entre les variables demeure
sous-jacente aux données utilisées.
Pertinence du sujet
La modélisation de la covariance est un thème
central en finance ainsi que dans de nombreux domaines. Plusieurs utilisations
sont possibles en biologie, économie, et en écologie, puisque la
modélisation de la dépendance entre différentes variables
est primordiale pour mieux comprendre l'impact de la modification d'une de ces
variables sur un système donné.
Dans ce mémoire, nous nous intéressons à
l'utilisation financière de la matrice de covariance. La gestion des
risques d'un portefeuille d'actifs requiert une juste mesure de la matrice de
variance covariance.
Donc la problématique du stage se situe dans le cadre de
la gestion de portefeuilles financiers qui consiste à allouer des fonds
sur différentes catégories d'actifs financiers. Ces actifs
peuvent être des actions de sociétés cotées en
bourse, des matières premières (or, pétrole, produits
agricoles,...) ou encore des bons du trésor d'états. Cette
allocation a pour but de chercher à obtenir un rendement,
c'est-à-dire des gains, de ces fonds en les plaçant de
manière appropriée sur des catégories d'actifs bien
choisis.
La théorie moderne de la gestion de portefeuilles est une
théorie financière développée en 1952 par Harry
Markowitz. Elle expose comment des investisseurs rationnels utilisent la
diversification afin d'optimiser leur portefeuille, et quel devrait être
le prix d'un actif étant donné son risque par rapport au risque
moyen du marché. Dans ce modèle, le rendement d'un actif est une
variable aléatoire et un portefeuille est une combinaison
linéaire pondérée d'actifs. Par conséquent, le
rendement d'un portefeuille est également une variable aléatoire
et possède une espérance et une variance.
L'optimisation du portefeuille est aujourd'hui une composante
importante de la finance quantitative moderne. Les méthodes
d'optimisation existantes permettent de résoudre la plupart des
problèmes posés par les praticiens de l'investissement.
Deux paramètres jouent un rôle fondamental dans la
qualité des résultats obtenus : les rendements anticipés
et la matrice de variance covariance.
Pour estimer la matrice de variance-covariance le
modèle GARCH multivarié s'avère être actuellement le
plus efficace pour prendre en compte la dynamique des interdépendances.
Cependant l'estimation de ces matrices reste un problème difficile car
très instable ce qui a comme conséquence une dégradation
des résultats de l'optimisation (forte variabilité des
portefeuilles obtenus). Ce stage se propose de mettre en place une
procédure d'estimation robuste de ces matrices de variance-covariance et
de tester son efficacité sur des cas pratiques.

La société RaisePartner
Présentation
La société RaisePartner1, a
été fondée en juillet 2001. Comme son nom
l'indique2, RaisePartner
a comme coeur de métier la fourniture à ses clients
(des gestionnaires de portefeuilles) d'outils d'optimisation visant à
accroître leur performance. A ces outils, RaisePartner propose
d'adjoindre des services adaptés aux clients.
Juridiquement, RaisePartner est une SAS3. Un des
intérêts de ce statut juridique est de permettre aux dirigeants de
bénéficier du régime de protection des salariés.
Elle se compose de seize personnes4, réparties en quatre
équipes (comme mentionné sur la figure 1). Si le siège
social, ainsi que l'équipe de R&D, se situent à Grenoble, les
équipes de consultants et de commerciaux se trouvent à Paris et
New York. Enfin, elle projette d'élargir son marché au
Moyen-Orient en créant une antenne à Dubaï en 2008.
Actuellement, RaisePartner a comme clients réguliers les
branches Assets Managements de grandes banques aussi bien que des hedge
funds.
Ses solutions
Voici les principaux produits que propose la
société à ses clients.




Figure -1- Organigramme de la
société RaisePartner.
1http ://
www.raisepartner.com
2RaisePartner vient de l'anglais to raise augmenter,
et partner partenaire.
3Société par Actions Simplifiées
: forme de société commerciale créée en 1994, qui
tient à la fois de la société anonyme et de la
société à responsabilité limitée.
4Un «business angel» aide de plus au
financement de la société.
La librairie NORM Asset Management
NORM (pour Numerical Optimization for Risk management) est une
librairie de finance. Elle permet d'optimiser des portefeuilles de façon
robuste, en tenant compte de multiples contraintes.

Elle se compose de quatre modules :
1. Analyse du risque et de la performance (Performance &
risk analysis).
2. Optimisation robuste de portefeuille (Robust asset
allocation).
3. Corrélation et agrégation de risque
(Correlation & risk aggregation).

RP Quant Advisory
A cette librairie, des services appelés RP Quant Advisory
sont adjoints : c'est la branche consulting de la société qui
s'en
charge. Il s'agit d'accompagner les utilisateurs dans leur
création de stratégie d'investissement en les aidant à se
servir de NORM, et de leur fournir une analyse de leurs univers
d'investissement.
PRISM

Prism est l'acronyme de Platform of Risk and Investment Strategy
Management. Il s'agit d'un futur produit développé au sein de
l'équipe R&D de RaisePartner. Cette plateforme de services Web
utilise la librairie de mathématique financière NORM As set
Management permettant d'effectuer de l'analyse
de performance et de risque, ainsi que l'optimisation et de
l'évaluation de prix. Ce nouveau produit clef en main propose ainsi aux
clients un panel de services liés à la gestion, à
l'analyse et à l'optimisation de portefeuille.
Cette plateforme est développée avec la technologie
J2EE5, Le développement de PRISM étant dans la phase
de développement, sa commercialisation est prévue pour 2008.
5 JAVA 2 Entreprise Edition : outils permettant le
développement d'une plateforme web à partir du langage JAVA.
I. Processus Aléatoires Stationnaires et
Processus ARMA
Introduction
La statistique se préoccupe de porter des jugements sur
une population à partir de l'observation d'un échantillon de
cette population. La plupart du temps l'ordre dans lequel sont
échantillonnées les observations n'a pas d'importance. L'exemple
le plus simple que l'on puisse prendre est celui des sondages d'opinions.
L'analyse des séries temporelles est très
différente de l'analyse statistique habituelle car l'ordre des
observations revêt une importance primordiale. Une série
temporelle est définie comme une suite d'observations indexées
par le temps. On peut prendre comme exemple en économie ou en finance
une série : de prix, de taux d'intérêt, etc. Mais on peut
trouver bien d'autres exemples dans les autres disciplines. Les séries
temporelles peuvent être observées de manière continue ou
discrète. Dans ce mémoire, on ne considère que des
séries discrètes observées à intervalles
réguliers. Certaines séries peuvent être observées
à tout moment, même si on choisit de ne les observer qu'à
certains moments. Par exemple les prix, les taux d'intérêt, . . .
Ce sont des flux. Par contre d'autres séries sont définies comme
des accumulations de valeurs et doivent être observées à
intervalles fixes. Ce sont des stocks. Essayez de comprendre la
différence entre une observation trimestrielle du PIB et une observation
annuelle de celui-ci. La différence entre ces deux types de
séries peut être importante quand il s'agira de les
modéliser. On a le sentiment en observant un graphique de ces
séries que la valeur prise au temps t dépend
fortement de la valeur prise au temps t -1. Le processus qui
les engendre est dynamique. Le problème est alors de trouver le
modèle pratique qui approchera le plus possible le processus
théorique et ensuite de l'estimer.
Une fois cette étape franchie, on pourra faire de la
prévision ou du contrôle avec ce modèle. Les types de
modèles que l'on peut considérer sont nombreux. En statistique on
va s'intéresser à modéliser une série
univariée par exemple au moyen d'un modèle ARMA, ou bien
considérer plusieurs séries à la fois et les
modéliser conjointement dans un modèle multivarié ou
modèle VAR.
La modélisation statistique usuelle suppose que les
séries sont stationnaires. Cependant la plupart des séries que
l'on traite sont non stationnaires, c'est à dire par exemple qu'elles
croissent dans le temps. Il est en général toujours possible de
trouver une transformation ou
un filtre qui puisse rendre stationnaire les séries non
stationnaires. Mais la détermination exacte de ce filtre n'est pas
triviale. Le but est de prendre en compte la nature non- stationnaire des
données économiques ou financières en montrant les
problèmes que cela pose. C'est toute la question des racines unitaires
et de la cointégration. Dans ce chapitre on présente le cas
univarié, certains outils mathématiques et modèles simples
employés par la statistique des séries temporelles.
La branche de la statistique mathématique qui
s'intéresse aux séries temporelles a développé
plusieurs modèles de représentation, dont nous allons
brièvement rappeler les plus simples. Il s'agira de préciser
quelques notions sur les modèles AR, MA, ARMA et quelques outils
mathématiques qui leurs sont reliés.
I.1 Définition d'un Processus stochastique
Un processus stochastique est une suite de variables
aléatoires réelles indexées par le temps
{X t , tE cents ?
Ici t appartient à un espace discret, ce
qui définit un processus en temps discret. Un processus stochastique est
donc une famille de variables aléatoires { X t , t E
cents } c'est à dire de
fonctions mesurables de l'espace S des échantillons
à valeurs dans . Pour chaque point s de l'espace des
échantillons S, la fonction qui à t associe X
t (s) est appelée la trajectoire du
processus. Les observations successives forment l'histoire
(information) du processus.
I.2 Processus stationnaires
La notion de stationnarité joue un rôle central dans
la théorie des processus aléatoires, et particulièrement
en analyse des séries chronologiques. Dans plusieurs problèmes du
monde réel, on rencontre des processus aléatoires qui
évoluent dans un état d'équilibre statistique, dans le
sens où les propriétés probabilistes et statistiques des
processus ne changent pas dans le temps, de tels processus sont dits
stationnaires.
On commence par donner la définition d'un processus
stationnaire au sens strict, et ensuite celle de la stationnarité du
second ordre.
· Processus strictement stationnaire
(stationnarité forte) :
Grossièrement, un processus aléatoire est dit
strictement stationnaire si sa loi de probabilité est invariante par
translation dans le temps. Mathématiquement, le concept de
stationnarité stricte est donné par la définition
suivante:
Définition :
Un processus stochastique {Xt,te
Z} est dit strictement (ou fortement) stationnaire si pour
tout ne *, et pour tout n-uples (
t1 , ..., tn)e Z
n , la distribution de probabilité conjointe du
vecteur(Xt1+h,...,Xtn+h) est la
même que celle de ( Xt1 ,..., Xtn
),Vhe Z . Autrement dit, si on a :
P(Xt1 x1,...,X4,
xn)=P(Xt1+h
x1,...,Xtn+h
xn),V(x1,...,xn)e
Rn,Vhe Z
On note que toutes les caractéristiques (c'est à
dire tous les moments) d'un processus strictement stationnaire si elles
existent sont invariantes dans le temps. Cette définition de la
stationnarité est, cependant, trop forte et très exigeante et
repose sur la connaissance de la loi conjointe du processus qui ne peut
être connue en pratique, sauf dans des cas très spéciaux.
Toutefois, plusieurs propriétés essentielles des processus
aléatoires peuvent être obtenus à partir des moments du
premier et du second ordre.
La stationnarité de ces deux moments peut donc être
suffisante pour expliquer la stationnarité du processus. Pour cette
raison, on a besoin d'un concept de stationnarité moins fort et qui peut
être rencontré dans la pratique.
· Processus faiblement stationnaire (du second
ordre) :
Considérons un processus stochastique de second
d'ordre{ Xt,te Z} .
Définition Un processus est stationnaire
au second ordre si: E(Xt ) =
E(Xt+h ) = it (de moyenne
constante).
Vte Z,
E(Xt2)< oo
cov(Xt,Xt+h )=
EL(Xt--
pt)(Xt+h--pt+h)1=
y(h )
La fonction y(h) est dite fonction
d'autocovariance du processus. Remarques
-- 1. La fonction d'autocovariance d'un processus faiblement
stationnaire dépend seulement de la différence des instants.
-- 2. Dans la classe des processus du second ordre, il est
clair que la stationnarité stricte implique la stationnarité
faible (la réciproque n'est pas vraie, sauf pour les processus dits
Gaussiens).
Un processus{ Xt , t
Z} est dit Gaussien si toute sous-famille finie du
processus constitue un vecteur Gaussien. Autrement dit, pour tout ( )
n E N t t n E Z ,
le vecteur( X t 1 ,..., X t n )
* , 1 ,..., n
est Gaussien.
Théorème de Wold
Un processus stochastique non paramétrique se
définit à partir de la distribution conjointe des observations ou
de ses premiers moments. Un processus stochastique paramétrique se
définit au contraire à partir d'un mécanisme de
génération qui est indexé par des paramètres.Il est
possible de caractériser ce mécanisme de manière
très générale au moyen du théorème de Wold
(1954). Ce théorème montre que tout processus stationnaire peut
être représenté de manière unique par la somme de
deux composantes indépendantes, une composante régulière
parfaitement prévisible parfois appelée déterministe et
une composante stochastique.
Théorème 1 Soit un processus
stationnaire? t ) t
y . Il est toujours possible de trouver une
composante régulière dt et une
composante stochastique z t telle que:
yd z
t t t
= +
|
?
z b ?
t i t i
= ? ?
i o
=
|
Où ? ?t , tE cents}un
bruit blanc.
|
Ce théorème est à la base de la
modélisation des séries temporelles stationnaires. La composante
stochastique est exprimée sous la forme de ce que l'on appelle un
processus moyenne mobile infini. Un des buts de la modélisation consiste
à approximer cette moyenne mobile infinie par un processus ayant un
nombre fini de paramètres. C'est ce que l'on verra en étudiant
les processus AR, MA et ARMA.
· Processus bruit blanc (White
noise)
Plus simple processus stationnaire en analyse des séries
temporelles est appelé : processus bruit blanc 6 {
ct , tE Z } qui est une
séquence de variables aléatoires non corrélées
de
moyenne nulle et de variance constantea? 2
.
6 Ce terme de la physique, faisant référence au
spectre de la lumière blanche.
Le fait que les variables aléatoires (
t ) t
c soient mutuellement non
corrélées (hypothèse d'orthogonalité), nous permet
de donner la fonction d'autocovariance de ce processus par:
r
2 0
y C
si h
( ) cov( , ) ( )
h E C
®~
C C + C C +
t t h t t h ~ 0 sinon.
Par conséquent, la fonction d'autocorrélation est
donnée par :
|
PC
|
r
1 0
si h
( )
h ®~ ~ z
0 0
si h
|
I.2.2 Fonction d'autocovariance
La suite de toutes les autocovariances d'une série
contient toutes les informations sur la mémoire de cette série.
On l'estime au moyen de :
t 1
y à( )
h
T h
-
~
( )( )
X X X X
t t h
- -
-
1
T
Avec
1 T
X X
~
t
T
t 1
On utilise T observations pour calculer la moyenne et la
variance, alors que pour calculer y(h) on utilise seulement
T - h observations. Donc quand h --* T,
l'estimateur de y(h) tend
vers zéro si le processus est stationnaire en covariance.
Si cette condition de stationnarité est vérifiée, alors
l'estimateur yà(h) est un estimateur consistent de
y(h).
Propriétés
a) La fonction d'autocovariance
y(h) satisfait la propriété suivante :
y(-h)=y(h) VhE Z;
(fonction paire).
Donc on peut, dans la pratique, se restreindre aux
autocovariances aux retards positifs, c'està-dire que l'on peut, sans
perte de généralité, prendre h E .
b) On peut facilement, en utilisant
l'inégalité de Cauchy Schwartz, vérifier la
propriété suivante :
y (h) ~y(0)=Var(X
t ) Vt,hEZ.
I.2.3 Fonction d'autocorrélation
La fonction d'autocorrélation de retard h : p
(h) ; Vh E Z, d'un processus du second
ordre, faiblement stationnaire de moyenne p = E(X t
) et de variance Var(X t ) = y(0);
notée p(h) est définie par :
( , ) ( )
Cov X X h
h y
= = Vh E Z
t t h
-
p ( )
O O y (0)
X X
t t h
-
Il est facile de vérifier que la fonction
d'autocorrélation satisfait les deux propriétés suivantes,
qui découlent directement des deux propriétés
a) et b) de la fonction d'autocovariance.
Propriétés
1) p(-h)=p(h) ; VhE
Z..
Donc on peut dans la pratique se restreindre aux
autocorrélations pour h =0: p(0) =1 VhE
Z.
? Autocorrélation empirique
L'estimateur de la fonction d'autocorrélation,
pà(h) est obtenu en remplaçant, dans
l'expression de p (h), y (0) et y
(h) par leurs estimateurs yà(0)
etyà(h) , respectivement. En effet, on a :
à ( ) ( )
p
h y à h
= VhEZ.
( )
y à 0
Ce qui peut s'écrire, en tenant compte de la
définition de l'estimateur empirique de la fonction d'autocovariance,
sous la forme explicite suivante :

=
T T h
-
y $( )
h
p u( )
h = y $( )
0
( )( )
X X X X
t t h
- -
-
?
T
? ( )
X X
t -
2
Vh
cents
E
,
t
t h
-
1
t = 1
Fonction d' autocorrélation partielle
Elle mesure la corrélation entre X t
et Xt-h , l'influence des variables
Xt-h+ i , ayant été retirée.
Soit la matrice des corrélations symétriques formées des
(h-1) premières autocorrélations.
1
. P h
-
P1
.
hE .
P h
=
1 1
?
. P h 2
- ?
1 ]
P1
1
1
.
P P
h 1 h 2
- -
P h *
P hh = P h
La fonction d'autocorrélation partielle est donnée
par :
La fonction P h * est le déterminant de la
matrice P h * obtenue à partir de P h ,
en
remplaçant la dernière colonne de celle-ci par le
vecteur (P1,.. .,Ph) ainsi :
P*
h
? 1 ...
P P ?
1 1
? ?
P P
1 ...
? 1 2 ?
? . ?
? ?
.
? ?
? ?
? ?
? ?
? P P
...
h - 1 h ?
On peut se passer de ce calcul matriciel qui n'est souvent pas
facile à faire ; pour cela on a recours à une écriture
récurrente de Pii tel que :
? P si i = 1
1
? i - 1
? P P P
i i j i j
- ? - -
1 ,
Pii
= ? j = 1
i 1
i h
= 2 , ,
?
1
P P
i j j
- 1 ,
? - ?
j
? ? = 1
Avec P ij P i j P ii P i i j j
i
= - - - - = -
1 , 1 , , 1, . . . , 1 et i = 2,..., h .
Cet algorithme résolvant les équations de
Yule-Walker de manière récursive est appelé algorithme de
Durbin (1960).
Remarques
1. La représentation graphique de p (h)
est appelée : corrélogramme.
2. Si p(h) décroît rapidement
quand le nombre de retard augmente, cela signifie que la série est
stationnaire, sinon elle est sans doute non stationnaire ou de mémoire
longue.
I.2.5 Opérateurs
· Opérateurs retard
(Backward)
L'opérateur retard est un opérateur
linéaire noté B, tel que : BX t = X t
-1.
· Opérateurs avance (Forward)
Par analogie, l'opérateur d'avance, noté F est
tel que : F X t = X t ? 1.
Propriétés
1- Ces opérateurs sont inversibles tels que : -1 -1
F = B et B= F.
2- -
B X t = X t net FX t = X t
? n
n n
n n
3- () a B i
i
|
X a X _
= Cette égalité décrit l'action sur le
processus { Xt , t Ecents } d'un
t i t i
|
|
i i
= =
1 1
polynôme en B, on peut évidemment
déduire celui en F.
4- Ces opérateurs ont des propriétés qui
permettent de les manipuler comme des séries entières
habituelles, en particulier, on peut les sommer ou les composer entre eux.
? Opérateur de différence
ordinaire
On note V opérateur de différence ordinaire
associé à un processus { Xt , tE
cents } tel que :
VX = X X = B X t
t t -
t -1 (1 - ) .
On définit le ème
dopérateur de différence ordinaire par : (1- )
V X t = B X t
d d
· Opérateur de différence
saisonnière On note VS l'opérateur de
différence saisonnière associé à un processus {
Xt , t E cents } tel que :
VX = B X t = X t X t s
(1 - ) - - .
S
S t
On définit le ème
D opérateur de différence
saisonnière par : (1 )
V S X t = -- B X t
D S D
I.3 Classe des modèles ARMA
I.3.1 Processus autorégressif d'ordre p AR
(p)
a- Définition
Le processus( t ) t
X satisfait à une représentation AR
d'ordre p, noté AR(p), s'il est solution
de l'équation aux différences stochastique suivante
:
p
e X ? X ?
t t j t j
= ??
j ? 1
Ou encore
e t =b(B)X t Avec
2
? B ? ? ? B ? ? B -- -- çb
p B et q5 p ?
( ) 1 1 2 ... pE .
Où qi (B) représente le
polynôme de retard et et est un bruit blanc de
moyenne nulle et de variance 2
c7e .
b- Théorème (condition de
stationnarité)
Une condition nécessaire et suffisante pour que le
processus autorégressif soit stationnaire du second ordre est que les
racines de l'équation caractéristique suivante
q(Z) = 0 soient à l'extérieur du cercle
unitaire.
c- Caractéristiques d'un processus AR
(p)
- Le corrélogramme simple est caractérisé
par une décroissance géométrique de ses termes. - Le
corrélogramme partiel à ses seuls p premières termes
différents de zéro.
Remarque
On peut ajouter au modèle une constante qui ne modifie pas
ses caractéristiques stochastiques et qui peut être utile pour
expliquer quelques phénomènes économiques.
Cas particulier : soit le processus stationnaire
AR (1) : X t = ?X t ? 1 + e
t
Ce processus est dit processus de Markov car l'observation
Xt dépend seulement de l'observation
précédente Xt ? 1 .
d- Les équations de Yule-Walker
Soit le processus autorégressif stationnaire d'ordre p
suivant:
p
... (I), avec et bruit blanc de variance
notée 2
o-e .
X ? X -- e
t i t i t
= ? +
i = 1
En multipliant (I) par X t on obtient : 2
X t
mathématique, on aura :
p
et en prenant l'espérance
= ? +
q5 X -- X e X
i t i t t t
i = 1
p
E X y ? y i ? e
? ? = = ?
? ? ?
2 2
( ) ( )
0
t i
i = 1
D'où :
?e 2
y ( )
0
p
1 --?
? p
i
( )
i
i = 1
En multipliant maintenant (I) par X t -- h ,
h > 0 et prenant l'espérance, ensuite divisant par
p
y (0), on obtient :
En écrivant cette équation pour h =
1,...., p on
p h q5 p h i h
( ) ( ), 0.
= ? -- ? ?
i
i = 1
obtient les équations dites de Yule-Walker suivantes:
1 (1) (2) . . ( 1)
p p p p --
p p p p
(2) (1) 1 (1) . . ( 2)
? p --
. .
= ? .
? ?
p (1)
? ?
? ?
? ?
? ?
? ?
.
? ?
? ?
p ( )
p
?
? ?
1
?
. ?
?
. ?
?
?
? 2 ?
?
? ?
. . ?
? -- ? ?
? p ( p 1) . . . (1) 1 p
p ?
? ?
I.3.2 Processus moyenne mobile d'ordre q
(Moving Average) MA (q) a-
Définition
Le processus{ Xt , t cents }
satisfait à une représentation moyenne mobile d'ordre q,
noté : MA(q), s'il est solution de
l'équation aux différences stochastique suivante :
q
X e ? e --
t t j t j
= +?
j 1
En introduisant le polynôme de retard nous obtenons
X t =O(B) e t Où ( ) 1
1 et
? B O B O q B O J ?
= + + ...+ E
q
et est un bruit blanc de moyenne nulle et de
variance 2
ae .
Remarque
Le modèle moyenne mobile d'ordre q (MA (q)),
explique la valeur de la série à l'instant t par une moyenne
pondérée d'aléas et , jusqu'à
la qéme période qui sont
supposés être générés par un processus de
type bruit blanc.
b- Théorème (condition
d'inversibilité)
Une condition nécessaire et suffisante pour que le
processus moyenne mobile soit inversible est que les racines de
l'équation caractéristique suivante : o(Z) = 0
soient à l'extérieur du cercle unitaire.
Soit le processus MA(1) : X t = oe t ?
1 + e t
1 o Z 0
-- =
=:Z

Z
> =::
1
o < 1
1
= =
o
c- Caractéristiques d'un processus MA
(q)
Un processus moyenne mobile d'ordre q est toujours stationnaire,
car il est une combinaison linéaire finie d'un processus
stationnaire{et , tE cents }.
Pour le corrélogramme simple seuls ses q premiers termes
sont différents de zéro. La fonction d'autocorrélation est
dite tronquée au-delà du ié m e
qretard puisque la fonction
d'autocorrélation est définie par :
q
=
?
?
??
? ? ??
P o
k ?
0 pour k > q
?
qk?
i
?
0
i
?
o i o i k
+
0
i
2
pour k=0,...,q
Le corrélogramme partiel est caractérisé par
une décroissance exponentielle de ses termes.
Remarques
1- Un processus autorégressif est toujours inversible.
2- Il y a équivalence ente processus MA (1) et processus
AR (p) avec p infini. I.3.3 Processus autorégressif moyenne
mobile d'ordre (p, q) ARMA (p, q) a- Définition
Le processus ARMA (p, q) est généré
par une combinaison des valeurs passées et des erreurs passées et
présentes; on l'exprime par l'équation :
q5(B)X t = o (B) e t
Avec :
{et, t e T} : est un bruit
blanc de variance ae2 .
Et
0(B)=1+01B+02B2
+
·
·
· + 0qBq t
(B)=1 -- (1B -- t
2B2 --
·
·
·
-- t q
0i e , Vi=1,....,q et t
i e , Vi=1,...,p.
b- Théorème (condition de
stationnarité et d'inversibilité)
1)- Une condition nécessaire et suffisante pour que le
processus autorégressif moyenne mobile d'ordre (p, q) soit
stationnaire est que les racines de l'équation caractéristique
suivante : t (Z) = 0 soient à l'extérieur du
cercle unitaire.
2)- Une condition nécessaire et suffisante pour que le
processus autorégressif moyenne mobile d'ordre (p,q) soit
inversible est que les racine de l'équation caractéristique
suivante: 0(Z) = 0 soient à l'extérieur du cercle
unitaire.
c- Caractéristique d'un processus ARMA (p,
q)
Les corrélogrammes : simple et partiel sont un
mélange des fonctions exponentielles et sinusoïdales amorties.
Cependant l'identification des paramètres p et q à partir de
l'étude des fonctions d'autocorrélations empiriques
s'avère plus délicate.
Remarques
1- Les processus AR, MA et ARMA ne sont représentatifs
que de séries stationnaires en tendance et corrigées des
variations saisonnières. De plus ces modèles ne tiennent pas
compte d'une éventuelle variable exogène.
2- dans un contexte ultérieur, nous allons exposer une
extension de la classe des modèles ARMA.
II. Processus aléatoire non
stationnaire
La plupart des résultats et méthodes
utilisés dans l'analyse des séries chronologiques sont
basés sur l'hypothèse de la stationnarité du second ordre,
lorsque cette hypothèse n'est pas satisfaite, ce qui est souvent
rencontré en pratique dans diverses disciplines de recherche, en
particulier, l'économie d'hydrologie, la
météorologie...des transformations sont appliquées
(différence ordinaire, différence
saisonnière, différence mixte, transformation de Box-Cox ...)
pour assurer la stationnarité du second ordre.
Pour que ces transformations soient adéquates il faut
à priori pouvoir détecter correctement la nature des variations
de la série. Pour répondre à ce besoin, plusieurs
techniques ont été mises au point afin de détecter la
tendance, la saisonnalité, la rupture,... .
II.1 Composantes des séries
temporelles
Avant le traitement d'une série chronologique, il
convient d'en étudier ses caractéristiques stochastiques (son
espérance et sa variance), si elles se trouvent modifiées dans le
temps la série est considérée non stationnaire.
L'analyse des séries temporelles des
phénomènes économiques permet de distinguer quatre types
d'évolution des séries dans le temps appelées «
composantes de la série temporelle » qui sont :
(a) Tendance
C'est un mouvement persistant dans un sens
déterminé pendant un intervalle de temps assez long, il traduit
l'allure globale du phénomène, qu'il soit à la baisse ou
à la hausse, ce mouvement est fonction du temps.
(b) Saisonnalité
Elle se manifeste à travers des fluctuations
périodiques plus au moins régulières (sous réserve
de la variabilité du nombre de jours dans le mois, du nombre de jours
fériés dans la semaine). Ce mouvement est donc une fonction du
temps et est indépendant de la tendance.
Néanmoins, l'explication de ce mouvement se trouve dans
des déterminismes extérieurs à l'activité
économique elle-même (particularités du temps astronomique,
rythme des saisons, rythme des activités sociales dont les
caractères institutionnels s'imposent à l'activité
économique).
(c) Cycle
Cette composante décrit un mouvement à moyen terme
caractérisé à la fois par la périodicité et
par la cyclicité, c'est-à-dire par la régularité de
son amplitude comportant une phase croissante et une autre
décroissante.
II.2 Méthode graphique
La représentation graphique de la chronique permet de
détecter la présence d'une tendance, d'un cycle, d'une
saisonnalité ou d'une modification de structure (rupture).
Aussi, l'étude de la fonction d'autocorrélation
(corrélogramme) : qui consiste à analyser le corrélogramme
simple permet de détecter si :
- Des pics marquants apparaissent aux retards S, 2S, 3S..., ce
qui fait penser de la présence d'une saisonnalité de
période S.
- La fonction d'autocorrélation ne décroît
pas d'une manière rapide vers zéro, ce qui fait croire à
la présence d'une tendance.
II.3 Méthodes analytiques
II.3.1 Analyse de la tendance
Certaines variables économiques peuvent avoir des
évolutions analogues, dont il peut exister une corrélation entre
ces variables sans que celle-ci exprime une quelconque liaison à
caractère explicatif, donc il convient d'enlever cette tendance et voir
si une telle liaison existe. En analyse des séries chronologiques, on
distingue deux types de tendances : déterministe et stochastique. Dans
cette optique, Nelson et Plosser (1982), ont développé deux
sortes de processus non stationnaire : TS (Trend Stationnary) et DS (Differency
Stationnary).
a- Processus TS
(Trend
Stationnary)
Il arrive que les valeurs prises par les variables d'un
processus stochastique décrivent une allure déterministe qui peut
être représentée à travers une fonction polynomiale
(linéaire ou non linéaire) du temps, de la façon suivante
:
X t =ft+U t .
avec ft : Fonction polynomiale par rapport au temps.
Ut : Processus stationnaire.
Un exemple simple est : X t = a + bt
+ U t
Avec : 2
Var ( X t ) = ?? et
cov(X t , X s ) = 0, s ~
t.
Dans ce cas Xt est dit : un
processus non stationnaire de type déterministe. Cela veut dire
que l'effet produit par un choc (ou par plusieurs chocs aléatoires)
à un instant t est transitoire, la chronique retrouve son mouvement de
long terme dicté par les valeurs de la fonction ft.
- Pour rendre stationnaire un tel processus, on doit estimer
d'abord a et b par la méthode des moindres carrés
ordinaires (MCO), puis retrancher de Xt la valeur
estiméea$+ b $ t .
b- Processus DS
(Differency
Stationnary)
C'est un processus non stationnaire de type aléatoire,
dont un choc à un instant donné se répercute à
l'infini sur les valeurs de la série, l'effet choc est donc permanent et
va en décroissance. La stationnarisation de ce type de processus est
réalisée par l'utilisation d'un
filtre au différence d'ordre d : ( )d
1 -- L X t = fi + ? t
avec /3: constante réelle.
et : Processus stationnaire
d'espérance nulle.
- En pratique on utilise souvent la différence d'ordre 1 :
VX t =/3+e t ? X t =X t
? 1+/3+e t
On obtient, par substitution successive :
t
X X /3t e
t = + +?
0 i
i ? 1
Le processus n'est pas stationnaire car on a :
2
Var X t
( ) .
ae
=
t
cov( , ) min( , ) , .
X X s t s t
= ?
2 t s t
a
En fait, on distingue deux types de processus
(a) Si /3 = 0 alors le processus est dit sans
dérive, il s'écrit sous la forme suivante :
X t = X t ? 1 + e t
Comme et est un bruit blanc, le modèle
porte le non de marche aléatoire (random walk Model), il est
fréquemment utilisé en analyse de l'efficience des marchés
financiers. Test de racine unitaire (test de Dickey-Fuller
1979)
Le choix d'un processus DS ou TS comme structure de la chronique
n'est pas neutre; pour cela les tests de Dickey et Fuller permettent non
seulement de détecter l'existence d'une tendance (racine unitaire,
unit root test) mais aussi de déterminer son type et par
conséquent la bonne manière de stationnariser la chronique.
Les modèles servant de base à la construction de
ces tests qu'on estime par la méthode des moindres carrés
ordinaires sont les suivants :
Modèle [1] : X t = pX t _1 +
et. modèle autorégressif d'ordre 1.
Modèle [2] : X t = pX t ? 1 + c
+ et. modèle autorégressif d'ordre 1
avec constante.
Modèle [3] : X t = pX t ? 1
+c+bt+e t .modèle
autorégressif d'ordre 1 avec tendance et constante.
Avec 2
e t -* iid(0, a
e ) (bruit blanc).
- Les hypothèses de test sont :
p ? 1
H : p = 1 contre H 1 :
0
- Si dans l'un des trois modèles cités ci dessus
l'hypothèse nulle est vérifiée, le processus est
alors non stationnaire (le processus suit une marche
aléatoire). Les observations présentes et passées ont la
même importance, on détermine dans ce cas l'ordre
d'intégration d.
- Sinon, la série est stationnaire (le processus est
asymptotiquement stationnaire), i.e., l'observation présente est plus
importante que les observations passées.
|
- Si p
|
>1 alors la série n'est pas stationnaire la variance
augmente de façon exponentielle
|
avec le temps, les observations passées ont un effet
persistant sur les observations présentes et futures, dans ce cas le
processus est dit explosif.
Donc Dickey et Fuller ont tabulé, à l'aide de
simulation de Monte Carlo, les valeurs critiques pour des échantillons
de différentes tailles7.
Ce qui ne pose aucun problème puisqu'il est
équivalent de tester comme hypothèse nulle:
H0 : p = 1 ou u
u H 0 : p - 1 = 0.
Le déroulement de test
On estimation par la méthode des moindres carrés
ordinaires le paramètre pu et l'écart type
p u 1
?
pour chaque modèle, ce qui fournit t p u avec u
t =
p ? à ?
- Si t u t tabulée
p > alors H0 est acceptée,
c'est à dire, il existe une racine unitaire et le
processus n'est pas stationnaire.
Test de Dickey-Fuller Augmenté (1981)
(ADF)
Dans les tests de Dickey-Fuller simples les résidus
sont supposés être des bruits blancs et donc non
corrélés, ce qui n'est pas forcément le cas. Pour cela
Dickey-Fuller (1981) ont proposé une généralisation de
cette approche en considérant une représentation AR (p) de
Xt .
7 Les valeurs théoriques sont données
par les plupart des logiciels économétriques en particulier par
(E VIE WS).
Après transformation des modèles de base, les tests
ADF sont fondés, sous l'hypothèse
|
alternative p suivants :
|
<1, sur l'estimation par la méthode des moindres
carrés ordinaires des modèles
|
|
p
Modèle [4] : $ $
? ? -- ?
X ? X ? ? X _ +
t t j t j
1 1
|
+ modèle autorégressif d'ordre p.
e t
|
|
j ?
|
1
|
|
p
Modèle [5] : $ $
? ? -- ?
X ? X ? ? X ? ?
t t j t j
1 1
|
+ + modèle autorégressif d'ordre p avec
c e t
|
|
j ?
|
1
|
|
constante
p
Modèle [6] : $ $
? ? -- ?
X ? X ? ? X ? ?
t t j t j
1 1
|
+ + + modèle autorégressif d'ordre p avec
bt c e t
|
|
j ?
|
1
|
tendance et constante.
Où 2
e t ? iid (0, ? e ) (bruit
blanc).
Le déroulement des tests est identique au cas
Dickey-Fuller sur les modèles [4], [5] et [6], seules les tables
statistiques de Dickey-Fuller diffèrent8.
Remarque :
Les retards X t ? j (j = 1,...,
p) participent dans l'explication du dynamisme du processus ce qui
implique la baisse, en valeur absolue, des
autocorrélations résiduelles, donc le nombre de retard p est
choisi suffisamment grand pour éliminer les autocorrélations des
résidus, pour se faire, on commence par estimer les modèles pour
les premiers ordres de j et on l'augmente au fur et à mesure
jusqu'à l'obtention des résidus qui forment un bruit
blanc9.
On note que le test ADF ne permet pas de tester directement si
les résidus forment un bruit blanc, donc il convient de faire une
estimation des modèles pour pouvoir observer les résidus et
éventuellement les tester.
V. Analyse de la saisonnalité
Analyse de la variance et test de Fisher (test
d'ANOVA)
Il s'agit de s'assurer que l'effet régulier que manifeste
la série n'est pas une coïncidence due au seul fait du hasard, et
qu'il ne s'agit pas aussi, d'oscillations plus au moins
régulières d'un effet parasite dû à l'existence de
corrélation non nulle entre les valeurs successives du processus (effet
de Yule (1921), Slutsky (1937)).
Afin de ne pas se tromper dans l'interprétation de cette
régularité un test dit d'ANOVA, basé (comme son nom
l'indique) sur l'analyse de la variance des résidus a été
mis au point.
8 On utilise le test « Portemanteau »
habituel pour tester si les résidus sont blanchis.
9 Voir GOURIEROUX : « séries temporelles
et modèles dynamiques »
- Soit une série chronologique mensuelle, trimestrielle,
journalière, ... , brute telle que :T = N×P : la taille de la
série
Où
N : le nombre d'années.
P : le nombre d'observations dans l'année appelées
période.
xij : l'observation de la série pour la
ième année et la jème
période, avec : i = 1...N et j = 1...P. On suppose que la chronique est
sans tendance ou la tendance a été retirée.
Le modèle s'écrit xij = ai + bj + eij où
: ai : l'effet de la ième année ; bj : l'effet de la jème
période ;
eij : résidus indépendants avec eij?
N(0,ó2).
Principe du test
On test deux effets absents (par exemple : mois, année)
contre deux effets significativement présents.
Si l'effet périodique (mois par exemple) est significatif
alors la série est saisonnière, par
contre si l'effet année est significatif, alors soit que
la chronique n'a pas été transformée et de ce fait, elle
possède des paliers horizontaux, ou bien la chronique a
été transformée ce qui implique la présence de
changements de tendance.
Déroulement du test
- Le calcul de la somme totale des carrés ajustées
ST :
|
N P _ _ N P
1
S x x x x
2
T ij
= - = ?
?? ??
( ) avec ij
i j
= = N P
1 1 i j
= =
1 1
|
(La moyenne totale)
|
- Le calcul de la somme des carrés annuelle SA :
N
p
( ?2 1
S p x x x x
A i
= - = ?
avec i ij
i = p
1 j = 1
(La moyenne de de la i ème année)
- Le calcul de la somme des carrés périodique SP
:
(La moyenne de la j ème période)
N _ N
1
S N x x x x
2
P j i ij
= ? -- = ?
( ) avec
= N
. .
j 1 j = 1
Le calcul de la somme des carrés résiduels SR :
NP
_
2
S x x x x
R ij j i
= ?? - - -
( )
. .
i j
=
SA
1
VarA
N
= =
1 1
Le calcul de la variance année :
S
- Le calcul de la variance périodique : P
Var =
P P - 1
|
- Le calcul de la variance résidu :
|
VarR
|
SR
|
|
( 1)( 1)
P N
- -
|
Le test de saisonnalité
Ce test est basé sur l'influence du facteur période
et est construit à partir des hypothèses
suivantes: 0
?
?
H : Pas de saisonnalité.

?
|
H : Il ex iste u n e s aiso n n a lité.
1
|
On calcule la valeur de Fisher empirique p
F Var
? = que l'on compare à la valeur de
Var
R
Fisher tabulée F? 1 2
y y avec y1 =P- 1, y 2 =(N- 1 )(P- 1)
degré de liberté.
|
SiSi* á
F>Fv1,v2 * á
F <F v1,v2
|
on rejette l'hypothèse H0, la
série est saisonnière.
on rejette l'hypothèse H1, la
série n'est pas saisonnière.
|
Méthode de désaisonnalisation
Pour stationnariser une série affectée d'une
saisonnalité, on procède à la désaisonnalisation de
la série par une différentiation.
Application de la différence
saisonnière
Cette méthode consiste à considérer la
série différenciée d'ordre S (S : période de la
saisonnalité).
? s X t = X t- X t -
s III. Extension des modèles ARMA
L'objectif de cette extension est de tenir compte des effets
(tendance, saisonnalité) dans la modélisation de la chronique,
sans avoir recours aux méthodes exposées ci-dessus (pour rendre
la série stationnaire).
III.1 Processus autorégressif moyenne mobile
intégré d'ordre (p,d,q)
Ce sont des modèles ARMA intégrés
notés ARIMA. Ils sont issus des séries stationnaires par
l'application du filtre aux différences et ceci, bien entendu dans le
cas des processus DS détectés par le test de Dicky-Fuller.
Le processus Xt suit un ARIMA (p,d,q),
c'est-à-dire qu'il est solution d'une équation aux
différences stochastique du type :
0(B)(1 -- B)d =
-=ye:`(B)e t.
III.2 Processus autorégressif moyenne mobile
intégré saisonnier
Il est possible de trouver que certaines séries
chronologiques peuvent être caractérisées par une allure
graphique périodique, pour cela il est important de les analyser en
tenant compte de l'effet saisonnier. Box et Jenkins (1970) ont proposé
une classe particulière de modèles appelée : classe de
modèles ARIMA saisonniers.
III.3 Modèles saisonniers mixtes
SARIMA
Ce sont des extensions des modèles ARMA et ARIMA. Ils
représentent généralement des séries
marquées par une saisonnalité comme c'est le plus souvent le cas
pour des séries économiques voire financières. Ces
séries peuvent mieux s'ajuster par des modèles saisonniers. Ce
sont les SARIMA (p, d, q)(P,D,Q) qui répondent à la formulation
:
tP(B) tPs (if
)(1--B)d
(1--Bs)D Xt =
0 (B)0s (Blet où
: tP (B) = 1-- t'AB --
tP2B2 --
·
·
·
-- tPpBp : Polynôme autorégressif
non saisonnier d'ordre p. tP (B) = 1 --
eAsB --
tP2sB2s
--
·
·
· -- tPpsBps :
Polynôme autorégressif saisonnier d'ordre P.
0(B) =1+01B +
02B2 +
·
·
·
+ 0qBq : Polynôme moyenne mobile non
saisonnier d'ordre q.
0(B)=1+01sB+02sB2s
+
·
·
·+0Qs--Qs
is : Polynôme moyenne mobile saisonnier d'ordre Q.
(1-- B)d : Opérateur de différence
d'ordre d.
(1-- Bs )D :
Opérateur de différence saisonnière d'ordre D. s :
correspond à la saisonnalité.et --> BB(0,
6E) .
Modèles saisonniers purs (SARMA)
Un processus stochastique { Xt , t E
T} est dit processus autorégressif moyenne mobile
intégré saisonnier pur d'ordre (P, D, Q)(p, 0, q), si son
évolution satisfait la forme suivante :
çb B çb B _ B X t = O B O
s B e t
( ) ( )( 1 ) D ( ) ( )
s s s
s
I. Introduction
L'analyse des séries temporelle est un champ
d'étude en perpétuelle évolution ces dernières
années. D'énormes progrès ont été
réalisés dans diverses disciplines, notamment en économie,
finance,....En effet Wold (1938) est à la base du développement
qu'a connu la classe des modèles autorégressifs moyennes mobiles
(ARMA) univariés.
Cependant, les statisticiens George Box et Gwilym Jenkins ont
contribué dans les années 70, à populariser la
théorie des séries temporelles univariées par leur
célèbre ouvrage. La modélisation univariée de Box
& Jenkins concerne les processus ARMA (p, q), ARIMA(p, d,
q) ou SARIMA(p, d, q)(P, D ,Q). Ces auteurs rassemblent tous les
travaux dans une méthodologie itérative. Cette dernière
englobe trois étapes essentielles à savoir : l'identification du
modèle, l'estimation du paramètre et la validation à
travers des tests. Une fois le modèle déterminé, nous
pouvons faire des prévisions.
La première étape consiste à identifier le
modèle qui pourrait engendrer la série. Elle consiste, d'abord
à transformer la série afin de la rendre stationnaire. Le nombre
de différentiations détermine l'ordre d'intégration d.
Ensuite il s'agit d'identifier le modèle ARMA (p, q) de la
série transformée avec l'aide du corrélogramme simple et
du corrélogramme partiel. Le graphique des coefficients
d'autocorrélation simple (corrélogramme simple) et
d'autocorrélation partielle (corrélogramme partiel) donnent une
information sur l'ordre du modèle ARMA. Après avoir
choisi un ou plusieurs modèles ARMA théoriques, il faut
estimer leurs paramètres en utilisant une méthode non
linéaire (moindres carrés non linéaires ou maximum de
vraisemblance). Ces méthodes sont appliquées en utilisant les
degrés (p, d, q) et (P, D, Q) trouvés dans
l'étape d'identification. Une fois les coefficients estimés, il
s'agit de vérifier l'adéquation du modèle aux
observations. Il existe plusieurs tests : tests graphiques de
l'autocorrélation des résidus, test de Box-Ljung, et d'autres
tests qui confirment la blancheur des résidus. Enfin,
l'intérêt de l'approche de Box-Jenkins est qu'une
modélisation ARMA conduit à des prévisions
optimales si la variance de l'erreur de prévision est minimale. Cette
approche se schématise comme suit :
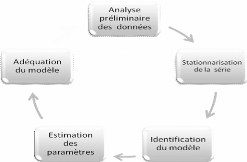
Organigramme de la méthode de Box et
Jenkins
31
II. Démarche de la méthode de Box et
Jenkins
II.1. Analyse préliminaire
L'analyse préliminaire est une phase non
coûteuse, elle permet avant tout test ou traitement
statistique
approprié, d'observer la représentation graphique de la
série (les observations du
processus {Xt , tE cents } en fonction du
temps).
En effet, parfois une simple visualisation du graphe permet de
détecter ou soupçonner l'existence de plusieurs composantes
(tendance, saisonnalité,...) donc il faut, bien évidemment,
confirmer ou infirmer l'existence par des tests appropriés.
Cette étape, permet aussi de prendre des options sur les
variables, tels que : corriger les données aberrantes, suppléer
celles manquantes ou effectuer des transformations...etc.
II.2. Stationnariser la série
Les résultats de l'analyse des séries
chronologiques reposent sur l'hypothèse de stationnarité du
second ordre, mais souvent les caractéristiques stochastiques d'une
série (moyenne, variance) se trouvent modifiées dans le temps,
c'est le cas par exemple lorsque :
- On constate que la série est saisonnière par
l'apparition des pics marquants de périodicité S dans la fonction
d'autocorrélation simple ou dans la représentation graphique de
la série.
- La chronique est affectée d'une tendance, dont il
convient de déterminer la nature par les tests cités de
Dickey-Fuller (voir chapitre 1).
II.3. L'identification du modèle
adéquat
Cette étape consiste à identifier le modèle
ARMA susceptible de représenter la série, c'est pour
cela qu'il est important de se familiariser avec les données en
examinant le graphe de la série chronologique (présence de
saisonnalité, stationnarité,...) qui permet de faire une analyse
préliminaire qui consiste par exemple à corriger les
données aberrantes, transformer les données (transformation
logarithmique, inverse, racine carrée,...) puisqu'il faut se ramener
à un modèle ARMA stationnaire, le recours aux
différences premières ordinaires, différences
premières saisonnières, différences ordinaires et
saisonnières. Le choix est dicté par l'allure graphique de la
série. D'ailleurs le choix de la transformation des données est
plus facile après avoir appliqué les opérateurs de
différence adéquats. Il est conseillé de comparer les
variances des différentes séries. La série avec la plus
petite variance conduit souvent à la modélisation la plus simple.
Ainsi un examen du corrélogramme s'impose. Cette phase est la plus
importante et la plus difficile, elle consiste à déterminer,
parmi l'ensemble des modèles ARMA(p,q), le modèle le plus
représentatif du phénomène
étudié, elle est fondée sur l'étude des
corrélogrammes: simple et partiel; l'idée de base est que chaque
modèle ARMA possède des fonctions d'autocorrélation
(simple et partielle) théoriques spécifiques, le statisticien
essaie donc, à l'aide de son expertise, de reconnaître et
d'identifier, en comparant l'éventuelle similitude de ces fonctions
théoriques et estimées. Il peut alors choisir un ou plusieurs
modèles théoriques (en général, le choix porte sur
trois modèles au plus) en se basant sur les propriétés
suivantes :
? Si le corrélogramme simple n'a que ses q premiers
termes différents de zéro et que les termes du
corrélogramme partiel diminuent exponentiellement vers zéro ou
d'une manière sinusoïdale amortie, nous pouvons pronostiquer un
moyenne mobile d'ordre q : MA (q).
? Si le corrélogramme partiel n'a que ses p premiers
termes différents de zéro et que les termes du
corrélogramme simple diminuent exponentiellement vers zéro ou
d'une manière sinusoïdale amortie, nous identifions un
autorégressif d'ordre p : AR (p).
? Si les fonctions d'autocorrélation simple et partiel
n'apparaissent pas tronquées, il s'agit d'un processus ARMA ; en fait
dans ce cas il est très difficile d'identifier directement les vrais
paramètres du modèle, il convient donc d'en proposer plusieurs
pour éliminer, après des tests appropriés, ceux qui ne
reflètent pas les variations du processus.
II.3 Estimation des paramètres du
modèle
Une fois l'étape de l'identification terminée, il
faut estimer les paramètres qui sont les coefficients des
polynômes AR et MA ainsi que les polynômes
saisonniers SAR et SMA, et la variance des résidus
2
cr .
La méthode d'estimation la plus couramment utilisée
est celle du maximum de vraisemblance ou bien la méthode des moindres
carrés. Plus spécifiquement la technique consiste à
construire une fonction appelée fonction de vraisemblance et à
maximiser son logarithme par rapport aux paramètres I
i et Oj (avec i := 1,.., p et j :=
1,..., q) permettant de trouver la valeur numérique la
plus vraisemblable pour ces paramètres. L'étape
d'estimation achevée, l'étape suivante va nous permettre de
valider le(s) modèle(s) estimé(s).
II.4 Validation
A l'étape de l'identification, les incertitudes
liées aux méthodes employées font que plusieurs
modèles en général sont estimés et c'est l'ensemble
de ces modèles qui subit alors l'épreuve des tests, il en existe
de très nombreux critères permettant de comparer les performances
entre
modèles; nous pouvons citer les tests sur les
paramètres et les tests sur les résidus. II.4.1 Tests
concernant les paramètres
Tous les coefficients du modèle retenu doivent être
significativement différents de zéro, il convient donc d'utiliser
le test de Student classique.
· Test de Student sur les
paramètres
Il s'agit dans cette étape de tester la
significativité des paramètres m i et
Oj (i=1 ... ,p et j =
1... ,q) dans la formulation obtenue. Nous rejetterons avec un
risque 5% l'hypothèse que le paramètre est nul si :
à
> =
t a t a
( 1,9 6)
(Même procédure pour les Oj).
m
i
( )
m i
à
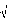
Var
II.4.2 Tests sur les résidus
Le processus estimé est évidemment de bonne
qualité si la chronique calculée suit les évolutions de la
chronique empirique. Les résidus entre les valeurs observées et
les valeurs calculées par le
modèle, doivent se comporter comme un bruit blanc. Pour
montrer que les { Et , t E cents } forment
un bruit blanc, nous devons vérifier si :
-La moyenne des résidus est nulle, sinon il convient
d'ajouter une constante au modèle.
-Le graphe des résidus en fonction du temps semble
approximativement compatible avec une suite de variables aléatoires non
corrélées. C'est ainsi que nous proposerons une multitude de
tests concernant les caractéristiques du résidu
souhaité.
è Test de Box-Ljung
Lorsque le processus est bien estimé, les résidus
entre les valeurs observées et les valeurs estimées par le
modèle doivent se comporter comme un bruit blanc. Nous noterons par la
suite Eàt le résidu d'estimation du
modèle.
o Principe du test
Ce test permet de savoir si les résidus forment un bruit
blanc ou non, pour le réaliser : nous observons le corrélogramme
des erreurs du modèle optimal, si tous les pics sont dans la bande de
confiance de plus la probabilité de significativité est
supérieure à 0.05 alors les résidus forment un bruit
blanc.
Pour confirmer ce résultat nous testons
H0 : « Les autocorrélations au
pas K, (k=N/5) sont non corrélés » C'est-à-dire
H0 : « p1 =p2
=...=pK = 0 » Contre H1 : «
3p j : j=1,k tel que pj ~0
».
= +
( )?= -
2 p 6 Statistique de BOX-LJUNG au pas K avec
:
K 2 ( )
Q n n i
n i
i 1
K : nombre de retard choisi. N : Taille de
la série brute. n : nombre de résidus.
o Règle de décision Si
Q <2 ? K - p - q - P
- Q)
? , degrés de liberté nous acceptons
l'hypothèse H0 que les résidus
sont non corrélés, Sinon les résidus ne
forment pas un bruit blanc et le modèle est inadéquat.
è Test des Points de
Retournements
Nous dirons que la suite des données 6
1 , 6 2 , ,6n
présente un point de retournement à la date
? i i i
1 2
i, si ? 6 6 6 i = 1,2,...n-2
+ +
< >
> <
? 6 6 6
i i i
+ +
1 2
[1 ' int
si c est un pode retournement
Soit la variable aléatoire Xi = ?
t_0 sinon
La variable Xi suit la loi de Bernoulli de
paramètre p = 2/3
n-2
?x i
i=1
Le nombre total des points de retournement est p =
n 2
Nous avons : E (p) =
- ?= = 3 2 (n-2) ;
E(x )
i
i 1
? ( \ 1
2
n-2 40 n 2 - 144 n + 131
Donc Var (p) = 90
16 n - 29
E (p 2 ) = ? ? 1 I
E x
= 90
i
? ? ? ) I ?
i=1
Sous l'hypothèse que les ( 6 i )
forment une suite de variables aléatoires, indépendantes et
identiquement distribuées.
La statistique U =
suit la loi normale d'espérance nulle et de variance
égale à 1
p E(p)
-
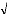
Var(p)
(U--* N (0,1) ; (n (nombre d'observations) > 30).
Le principe de ce test est d'accepter l'hypothèse que les
(6 i ) i (les résidus du
modèle) forment un bruit blanc si U < 1.96, au seuil a =
0.05.
è Test de la nullité de la moyenne des
résidus
Soit T le nombre de données disponibles
(après avoir enlevé les retards correspondant aux termes
AR et MA). Si le processus { e t , tE Z}
est i.i.d. (0, 2
oe ), nous devons avoir :
T
1
e t T e
= ? = 1 à
t
t ? 0
T ??
Par application du Théorème central limite, nous
montrons que :
TN?> L
T --*co
( , )
0 1
e t
à
o e t
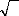
Dés lors, nous pouvons tester la nullité de la
moyenne des résidus en construisant l'intervalle de confiance sur e
t au seuil standard de 95%.
? ? _ . .
1,9 6 o à e o e
1,9 6 à
Pt
?? e E ? ,
t ?? ?
?T T
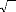
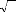
1 ? ? ?
= 0,95.
? ???j
Le test basé sur la statistique de Student pour tester
l'hypothèse
H0: « m=0 » contre
H1 : « m ~ 0 ».
e
t
La statistique utilisée est : t =
oe/ n-1
H0 Est acceptée si
t <t n ? 1 à 5% (=1,96) pour n
>30, dans le cas contraire, il convient d'ajouter

une constante au modèle. è Tests de
normalité
Le test de Jarque & Bera (1984) peut s'appliquer
pour tester la normalité des résidus.
Ce dernier est fondé sur la notion de Skewness
(l'asymétrie de la distribution, moment d'ordre 3) et de Kurtosis
(l'aplatissement qui se traduit en particulier par une épaisseur des
queues de distribution, moment d'ordre 4). Soit jUk le
moment empirique d'ordre k du
|
processus ? ?
p e e
= ? ?
1 à
T k
k t
T t = 1
|
.
|
o Test de Skewness
La Skewness est une mesure de l'asymétrie de la
distribution de la série autour de sa moyenne. Le coefficient de
Skewness (Sk ou encore J31 ) est
défini par :
L
( )1 2 1 2 3
S P ? 6 ?
? ? --* N J
( ) ?
k E P --*o 0,
1 3 2 T T
2 ? ?
La Skewness d'une distribution symétrique, telle que la
distribution normale est nulle. Une Skewness positive signifie que la
distribution a une queue allongée vers la droite et la Skewness
négative signifie que la distribution a une queue allongée vers
la gauche.
o Test de Kurtosis
La Kurtosis mesure le caractère pointu ou plat de la
distribution de la série. Le coefficient de Kurtosis (k u
ou encore J2) est défini par :
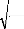
?
J .
?
P L ? 24
k N T
? - --*
4
J3 P --* o 3,
u 2 2 ?
T
2 ?
La Kurtosis de la distribution normale est 3. Si la Kurtosis est
supérieure à 3, la distribution est plutôt pointue
relativement à la normale ; si la Kurtosis est inférieure
à 3, la distribution est plutôt plate relativement à la
normale.

Nous construisons alors les statistiques centrées
réduites correspondantes à (Sk )
12 et ku que
l'on compare aux seuils d'une loi normale centrée
réduite
1 2
7 = 1
L k _ 3 L
( )
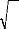
--* = --*
N et N
( ) ( )
u
0,1 7 0,1
2
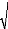
S k
6 T 24 T
--*o --*o
T T
Si la statistique centrée réduite de
(Sk ) 12 ( 71 ) est
inférieure au seuil 1,96 à 5%, nous acceptons
l'hypothèse de symétrie. Si la statistique
centrée réduite de ku
(72) est inférieure au seuil 1,96 à
5%, nous acceptons l'hypothèse de queue de distributions
non chargées (not weighted queues). La conjonction des deux conclusions
nous fait accepter l'hypothèse de normalité.
o Test de Jarque-Bera
La statistique de Jarque-Bera est une statistique de test pour
examiner si la série est normalement distribuée. La statistique
mesure la différence de la Skewness et de la Kurto sis de la
série avec ceux de la distribution normale. La statistique est
calculée comme suit :
|
JB S
=
|
T T
S +
6 24
k
|
?
( 3 ) ( 2)
- --*
2 z 2
k u
T--*o
|
Où Sk est la Skewness, k
u est la Kurtosis. Sous l'hypothèse nulle d'une
distribution normale, la statistique de Jarque-Bera suit asymptotiquement une
loi de 2
z à deux degrés de liberté ;
aussi,
si JB ( 2)
? ? 1 -- a nous rejetons l'hypothèse
H0 de normalité des résidus au seuil.
2
è Test d'indépendance de
Von-Neumann
Ce test peut être effectué lorsque les
résidus sont gaussiens.
Nous testons l'hypothèse nulle :
H0 : « Les résidus sont
indépendants et identiquement distribués » contre
l'hypothèse H1 : « Au moins deux observations
successives tendent à être corrélées ».
Les tests sont basés sur les deux estimateurs suivants de
la variance 2
?g des résidus :
2
n
D2= ? )
n g g
t t
? --
1 ?? 1
-- 1 t 1
n
2
; ( )
S g g
? ?
2 --
1 ?? t
n -- 1 t 1
?2
.
2 2
? (
Sous H0 : E ?
D = 1
--
D = 1 et Var ? 2
n
?
? 2S '2
J ? 2S 2 --
? n
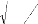
La statistique U = ( )
D S
2 2
2 ?
n
n 2 -- 1
-- 1
--
2
sous l'hypothèse nulle, suit une loi Normale N (0, 1).

La région critique est donnée par : { U
> U a }, U a est tel
que P{ U > Ua J = a.
è Test de Durbin-Watson
Si les résidus { g t , t Z}
obéissent à un bruit blanc, il ne doit pas exister
d'autocorrélation dans la série. Nous pouvons pour cela appliquer
le test suivant :
Test de Durbin - Watson : repose sur l'hypothèse de
normalité des résidus; test de l'autocorrélation d'ordre
1.
o Principe du test de Durbin -
Watson
Ce test permet de tester l'autocorrélation d'ordre 1 sous
l'hypothèse que les résidus sont Gaussiens. Donc il teste
l'hypothèse nulle
H0 : « p = 0 » contre
l'hypothèse alternative H1 : « p ~ 0
».Durbin et Watson ont proposé la
statistique suivante :
( )
g g
t t
-- -- 1
n
?
2
|
DW =
|
t
|
?
|
2
|
|
|
|
|
n
?
|
g
|
2 t
|
|
t
|
?
|
1
|
Le test de Durbin-Watson fait intervenir deux seuils critiques d
l,a et du ,a ( dl
,a < du ,a) fonctions
de n et du nombre de variables explicatives.
Ce test est utilisé pour tester trois hypothèses
:
1- H0 : « les
résidus sont non corrélés » contre H1:
« les résidus sont positivement corrélés »
Dans ce cas la règle de décision est : i)- Si DW
< dl ,a : nous rejetons H0.
ii)-Si DW > du ,a :nous acceptons
H0 .
iii)- Si dl ,a ~ DW ~ d u ,a
: nous ne pouvons rien dire.
2- H0 : « les
résidus sont non corrélés » contre H1:
« les résidus sont négativement
corrélés » la règle de décision
est :
i)- Si (4-DW) < dl ,a : nous rejetons
H0.
ii)- Si (4-DW) > d u ,a : nous acceptons
H0 .
iii)-Si dl ,a ~ (4-DW) ~ d u ,a
: nous ne pouvons rien dire.
3- H0 : « les
résidus sont non corrélés » contre H1:
« les résidus sont positivement ou négativement
corrélés »
Dans ce cas :
i) - Si DW < dl ,a2 ou (4-DW)
< dl ,a 2 : nous rejetons
H0.
ii) - Si DW > du ,a 2 ou (4-DW) > du
,a 2 : nous acceptons H0 .
iii)




- Si dl ,a 2 ? DW ~ du ,a 2
ou dl ,a 2 ? (4-DW)~ du ,a 2 : nous ne
pouvons rien dire.
è Test
d'homoscédasticité
L'hétéroscédasticité signifie que la
dispersion des résidus a tendance à augmenter ou à
diminuer en fonction des valeurs ajustées, plus
généralement, elle se manifeste quand la dispersion des
résidus varie en fonction des variables explicatives.
Non seulement L'hétéroscédasticité
influence les tests de significativité mais surtout, elle fausse les
intervalles de prévision.
Nous allons présenter, un test permettant de
détecter une hétéroscédasticité
éventuelle. Le test ARCH ou test du multiplicateur de Lagrange
a été introduit par Engle (1982). Supposons que les
résidus prévisionnels sont non corrélés et qu'ils
obéissent à un modèle ARCH (dans la plupart des
cas un modèle ARCH simple d'ordre p).
Nous construisons alors une régression entre les
résidus au carré et les résidus au carré
décalés jusqu'à l'ordre p.
L'hypothèse nulle testée est celle
d'homoscédasticité H0:"a1
= a2 =K K = a p = 0" contre L'hypothèse
alternative d'hétéroscédasticité conditionnelle
H ? i i = p tel que i
1 : " , 1 0"
K a.Si l'hypothèse H0 est
acceptée, la variance conditionnelle
de l'erreur est constante 0
a? 2 = a . En revanche, si l'hypothèse
nulle est rejetée, les résidus suivent un processus ARCH
(p) dont l'ordre p est à déterminer.
Le test est fondé soit sur un test de Fisher classique,
soit sur le test du Multiplicateur de Lagrange (LM). La mise en oeuvre
du test est simple et peut s'effectuer en trois étapes :
· Etape1 : nous estimons
l'équation de la moyenne. Nous récupérons les
résidus estimés ?àt et nous
calculons la série des 2
?àt .
· Etape 2 : Nous
régressons 2
?àt sur une constante et sur
ses p valeurs passées.
· Etape 3 : Nous calculons la
statistique du Multiplicateur de Lagrange LM = n*R2 où
n est le nombre d'observations servant au calcul de la
régression de l'étape 2 et R2 est le coefficient de
détermination de l'étape 2.
Sous l'hypothèse nulle d'homoscédasticité,
la statistique 2
TR suit une loi de khi - deux à
p
degré de liberté. La règle de
décision est :
- Si LM < ( )
z 2 p , l'hypothèse nulle est
acceptée : il n'existe pas d'effet ARCH.
- Si LM ~ ( )
z 2 p , nous rejetons
l'hypothèse nulle en faveur de l'hypothèse alternative
d'hétéroscédasticité conditionnelle.
Une autre approche consiste à calculer le
corrélogramme des résidus au carré du modèle
initial. Si les premiers termes de ce corrélogramme sont
significativement différents de zéro (0), alors nous pouvons
conclure à un modèle de type ARCH. Sinon si tous les
pics sont dans la bande de confiance, alors nous pouvons donc conclure que les
résidus sont homoscédastiques.
II.4.3 Choix du Meilleur Modèle
Après les étapes précédentes,
plusieurs formulations dans la vaste classe des modèles ARMA
pourraient être retenus ; il faut donc choisir le meilleur
modèle parmi ceux sélectionnés. Pour cela nous utilisons
:
s Les critères standards
Ils sont fondés sur le calcul de l'erreur de
prévision que l'on cherche à minimiser. Nous rappelons ici
l'expression des trois critères les plus fréquemment
utilisés.
-Erreur absolue moyenne (Mean Absolute Error)
-Racine de l'erreur quadratique moyenne (Root Mean Squared
Error)
1
eà 2
t

N
?t
RMSE =
-Ecart absolu moyen en pourcentage (Mean Absolute Percent
Error)
|
1
MAPE = ?
100
N t
|
à
et
Xt
|
|
|
Où N est le nombre d'observation de la série X
t étudiée et
eàt désigne les résidus
estimés. Plus
la valeur de ces critères est faible, plus le
modèle estimé est proche des observations.
· Les Critères d'information
L'idée sous - jacente consiste à choisir un
modèle sur la base d'une mesure de l'écart entre la vraie loi
inconnue et le modèle estimé. Cette mesure peut être
fournie par la quantité d'information de Kullback. Les différents
critères ont alors pour objet d'estimer cette quantité
d'information. Il en existe plusieurs, Nous présentons ici les trois
critères les plus fréquemment employés.
a) Critère d'information d'Akaike (AIC)
(1969)
Le meilleur des modèles ARMA (p, q) est le
modèle qui minimise la statistique : AIC (p, q) = n Log
2
?àe + 2 (p+ q)
b) Critère d'information Bayésien
(BIC)
Ce critère présente l'avantage de pénaliser
les modèles où les paramètres sont en surnombre
comparativement à l'AIC. Il est donné par :
? ? ? ? ? 1
? 2
p q ? 1
BIC (p, q) = n Log 2
?àe - (n-p-q) Log
?J
?? 1 + (p+q) Log 2
? n ? ? ? ? ?
( ) à 1
?
p q e
? ? - J J
a e
c) Critère de Schwartz 1978
SC (p, q) = n Log 2
?àe + (p+ q) Log
n
d) Critère de Hannan-Quin
1979
[
HQ 69, q) = Log 6-:+ (p+ q) c Log Log
ni
Où c (c >2) est une constante.
n
Remarque : Le critère le plus
utilisé est le critère AIC. Cependant Hannan
(1980) a montré que seuls les estimations des ordres p et
q déduits des critères BIC et HQ sont
convergentes et conduisent à une sélection asymptotiquement
correcte du modèle.
Nous cherchons à minimiser ces différents
critères. Leurs applications nous permettent de retenir un modèle
parmi les divers processus ARMA validés. Ainsi s'achève
l'étape de validation. La dernière étape de la
méthodologie de Box & Jenkins est celle de la prévision.
· Principe de parcimonie
Lorsqu'on veut modéliser une série chronologique,
par un processus Stochastique et dans le cas où les critères
d'information AIC et BIC de deux ou plusieurs modèles
retenus seraient très proches ou contradictoires, nous faisons
intervenir ce principe qui cherche à minimiser le nombre de
paramètre requis; il est préférable de conserver un
modèle qui est ½moins bon½, mais qui contient moins de
paramètres.
II.5 Prévision
L'objectif de la modélisation de Box et Jenkins est la
prévision de futures valeurs de la série chronologique. A
l'horizon h la valeur de la prévision
Xà(t + h )notée
It (h ) est l'espérance conditionnelle de
X(t+ h) telle que :
Xàt (h )
= E(Xt+h / Xt ,
Xt--1 )
|
It (h )
|
est la prévision (la valeur estimée de X
t+h)
|
t :l'origine de la prévision.
h : l'horizon de la prévision
L'espérance conditionnelle de la prévision est
définie par : 1 -- X(t -- j)
X(t), X(t --1), ....,
X(1)}=X(t -- j), j>_0
2 Ef X(t+ j)
X(t),X(t--1),....,X(1)}=Yi(
j), j > 0
3 Ef e(t -- j)
X(t),X(t--1),....,X(1)}=e(t--
j), j 0 4 -- Ef e(t + j)
X(t), X(t --1), ...., X(1)}=0, j >
0
Nous considérons un processus ARIMA (p, d, q)
défini par :
?(L
)vdXt = (L
)et, t > 0
où 0(L) =E(AÉ,
0(L)= E0 avec 00 00 1, et
Vd (1-- L) i
p q
d
Nous pouvons écrire :
|
? ? ? ? ? ?
q q d d
d
? _ ? _ = ? _ ? ? ? _
1 1 1
? ? ?
O O
i ( ) ( )
i
i L L L L
i
? ? ? ? ?
j
i = 0 i j
= =
0 0
|
d j
_**
|
X t = 49 1 Xt _ 1 +
492X t _2 +
·
·
· + ÇO
p Xt _ p _ d
Où les çoi sont obtenus
à partir du développement de * * Pour un horizon h,
l'équation s'écrit:
p q q
+
X h E X t j X t X t ? X h ? e h i
u( ) ( ) u( ) $( )
t = + _ = ? _ ? _
( ) ( ), ( 1),... i t i t
i i
= =
1 1
0 pour i < h
où ( )
? _
å h-i
( )
t
pour i h
?
$ h i =
t r??
? L'erreur de prévision
Soit et+h l'erreur de la prévision à
l'instant t+h : ut+h
e t+h = X t+h - X
Nous notons que : E (e t+h) = 0, Var (e t+h) =
( )
1 + r 1 + r 2 +... +
r h _ 1 a e
2 2 2 2
Donc Xt + h ~ ( ( 2 ) 2
)
N Xt + h + 'T' + 'I' + + P h _
a
à , 1 1 ...
2 2
2 1
D'où les intervalles de confiance de la prévision
à (1-a )% donnée par :
à
X t h X t h Z a a
= #177;
+ + 1
( 1 ... );
+ q1 + q1 + + p
2 2 2
1 2 h _ 1
_
2
où ? _ 2 ?
Z est le quantile d'ordre ??
[\ 1 a de la loi normale centrée
réduite. Pour a = 5% Nous
1 a
_
2
avons :
X t h X t h 0
= #177;
à 1 . 9 6
+ +
( 2 )
1 1 ...
+ ? + ? + + ?
2 2
2 h _ 1

Les critères suivants sont utilisés pour juger la
validité de la méthode de prévision :
1
e e
= ? i
n i
1- L'erreur moyenne (Mean Error) ME
(e) =
n
= 1
|
n
2- La variance Var
(e) = ( )
n e e _
1 ?= i
i 1
|
2
|
|
n
1
3-
e 2
i
Le carré moyen des erreurs (Mean Square
Error) MSE (e ) = ?=
n 1
i
Très utilisé, car il pénalise un biais
éventuel dans la prévision.
n
4- Root mean square error RMSE (e
) = MSE( ? ) = 2
1 ??
i
n i = 1
Conclusion
Ainsi s'achève la partie méthodologie de Box &
Jenkins; au chapitre suivant on passe à l'application
de cette méthode sur les séries étudiées.
Modélisation de la série SPY
Notation
La série SPY est l'actif qui correspond à la valeur
des actions de 500 compagnies les plus représentatives de
l'économie américaine. Il couvre la plupart des secteurs de
l'industrie et est échangé sur les marchés NASDAQ et NYSE
(New York Stock Exchange).
La valeur de l'actif SPY tient compte de la capitalisation
boursière des compagnies qu'il contient.
Identification
Les données de la série SPY s'étalent sur
une période de trois ans, les observations sont journalières ; du
03 janvier 2005 au 30 novembre 2007 soit 760 observations. L'unité de
mesure est le dollar américain.
I- Analyse graphique
Graphe de la moyenne et de la variance de la série
brute SPY
D'après les deux graphes ci-dessous, on remarque que la
moyenne et la variance varient au cours du temps, donc on peut
appréhender la non stationnarité de cette série.
Pour vérifier ceci, on va appliquer des tests statistiques
juste après la présentation des corrélogrammes simple et
partiel de la série brute.
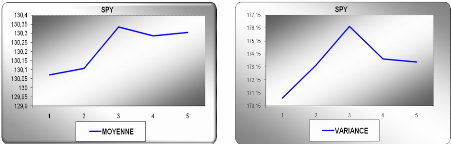
Diagramme séquentiel de la série brute
SPY
On voit clairement sur le graphe de la série brute que ce
processus est non stationnaire et cela provient tout naturellement de la
présence d'une tendance haussière.
165
160
155
150
145
140
135
130
125
120
115
110
105
56 111 166 221 276 331 386 441 496 551 606 661
716
TEMPS(JOURS)
GRAPHE DE LA SERIE SPY
SPY
Examen du corrélogramme de la série
SPY
On constate que la fonction d'autocorrélation simple
(colonne AC) décroit très lentement, cela est typique d'une
série non stationnaire. En revanche, la fonction
d'autocorrélation partielle (colonne PAC) a seulement son premier terme
significativement différent de 0 (l'intervalle de confiance est
stylisé par les pointillés).
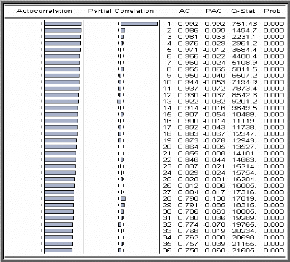
-Corrélogramme de la série SPY-
II -Analyse analytique
Application du test de Dickey- Fuller Augmenté
(DFA)
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [1], [2] et [3] de
Dickey-Fuller sur la série SPY.
Remarque
On choisit le retard (d=1) qui minimise les critères
d'informations d'Akaike et Schwarz.
s Modèle [3]
|
d
A = + + â + A +
SPY q$ SPY ? c t q$ SPY e
t t 1 j t j t
?
j ? 1
Avec et est un processus stationnaire
|
.
|
On commence par tester la significativité de la tendance
en se référant aux tables de DickeyFuller. Le résultat du
test sur la série SPY est donné dans la table
suivante:
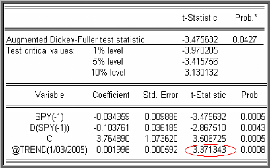
On compare la t-statistique du coefficient de la tendance
(@trend) avec la valeur donnée par la table de Dickey-Fuller. La
tendance est significativement différente de zéro puisque sa
statistique (3,37) est supérieure à la valeur critique (2,78) au
seuil 5%.
De plus la statistique de Student t?à = -3,4756
est inférieure à la valeur critique -3,4157
(donnée par la table de Dickey- Fuller)
pour le seuil 5%. D'où la série ne possède pas
une racine unitaire (on rejette l'hypothèse nulle «q$ =
0«).
Donc la série SPY est non stationnaire
de type TS, pour la stationnariser on a eu recours à un
ajustement linéaire, car le R2 associé est égal
à 0,918 (d'après les résultats obtenus par le logiciel
SPSS 10.0).
|
Dépendent
|
MTH
|
RSQ
|
D.F
|
F
|
SIGF
|
b0
|
b1
|
b2
|
b3
|
|
SPY
|
LIN
|
0,918
|
758
|
8458,49
|
0
|
108,406
|
0,0573
|
|
|
|
SPY
|
LOG
|
0,615
|
758
|
1208,9
|
0
|
71,087
|
10,4867
|
|
|
|
SPY
|
INV
|
0,041
|
758
|
32,26
|
0
|
130,773
|
-58,267
|
|
|
|
SPY
|
QUA
|
0,93
|
757
|
5017,82
|
0
|
111,648
|
0,0318
|
3,40E-05
|
|
|
SPY
|
CUB
|
0,938
|
756
|
3808,11
|
0
|
114,794
|
-0,0176
|
0,0002
|
-1,00E-07
|
|
SPY
|
COM
|
0,927
|
758
|
9584
|
0
|
109,689
|
1,0004
|
|
|
|
SPY
|
POW
|
0,638
|
758
|
1334,03
|
0
|
81,9846
|
0,0812
|
|
|
Remarque
On note la série ajustée par AJSPY,
elle est donnée par la formule suivante : AJSPY = SPY -
y(t).
Où y(t) est l'équation de la
tendance.
Estimation de la tendance:
L'estimation de l'équation de la tendance
y(t) est donnée par :
y(t)=b0 + bt 1
Les coefficients b0, b1
sont données par le tableau ci-dessus :
D`ou l`équation de la tendance est la suivante :
y(t)= 108, 406+ 0,0573t
Graphe de l'ajustement linéaire de la série
SPY
On remarque d'après ce graphe que la droite suit le
mouvement ascendant du graphe. Diagramme séquentiel de la
série ajustée AJSPY
-12
12
-4
-8
4
8
0
1 51 101 151 201 251 301 351 401 451 501 551 601 651 701 751
AJSPY
D'après le graphe on constate que la série
AJSPY semble stationnaire. Pour confirmer cette supposition,
on va appliquer les tests statistiques appropriés.
Test de Dickey- Fuller Augmenté sur la
série AJSPY
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [1], [2] et [3] de
Dickey-Fuller sur la série AJSPY.
Corrélogramme de la série AJSPY
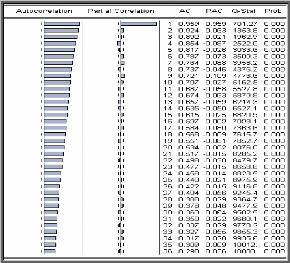
On voit que la fonction d'autocorrélation de la
série AJSPY décroit vers zéro et la première
autocorrélation partielle est clairement significative. Cette structure
est peut être celle d`une série stationnaire.
Pour confirmer cela, on fait appel aux tests de Dickey-Fuller
augmenté et de Fisher.
Test de Dickey- Fuller augmenté sur la
série AJSPY
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [4], [5] et [6] de
Dickey-Fuller sur la série AJSPY.
Modèle [6]
|
d
A = + + â + ? A +
AJSPY AJSPY ? c t AJSP Y e
t t 1 j t j t
j ? 1
Avec et est un processus stationnaire.
|
.
|
On vérifie alors l'absence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat du test pour la
série AJSPY est donné par la table
suivante :
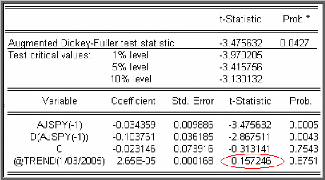
On remarque que la t- statistique de la tendance (= 0,157) est
inférieure aux valeurs critiques 3,48 ; 2,78 et 2,38 (données par
la table de Dickey- Fuller) pour les seuils 1%, 5% et 10%, on
le confirme par la probabilité 0,875 1 supérieure à
0,05.
Donc l'hypothèse nulle est bien entendu accepté, la
série AJSPY n'est pas affectée d'une tendance.
Modèle [5]
d
.
A = + C + A +
A JS P Y A JSP Y Çb A JS P Y ?
t t -1 j t j t
-
j ? 1
Après rejet du modèle [6], on procède au
test d'absence de la constante, dont le résultat est donné par la
table suivante :
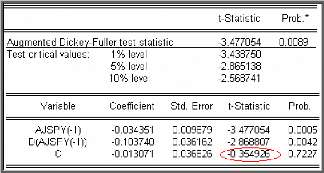
On remarque que la t-statistique de la constante (= -0,3549) est
inférieure aux valeurs critiques 3,72 ; 3,08 et 2,72 (données par
la table de Dickey- Fuller) pour les seuils 1%, 5% et 10%, on
le confirme par la probabilité 0,7227 supérieure à
0,05.
Donc, on rejette l'hypothèse de présence d'une
constante.
Modèle [4]
d
.
A = + A +
A JSP Y q$ A JSP Y ? q$ A JSP Y ?
t t j t j t
1 ?
j
?
1
On teste alors la présence d'une racine unitaire dans le
processus en vérifiant la nullité du paramètre q$
à l'aide d'une statistique de Student, où
q$à désigne l'estimateur des moindres
carrés ordinaires (MCO).
Le résultat du test pour la série AJSPY est
donné dans le tableau suivant :
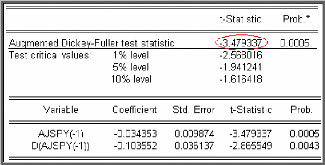
La statistique de Student (t?à = -3,4793 ) est
inférieure aux valeurs critiques -2,5680 ; -1,9412
et -1,6164 pour les seuils 1%, 5% et 10%, d'où la
série ne possède pas de racine unitaire (on rejette
l'hypothèse nulle «q$ = 0«).
Test de FISHER pour la série AJSPY
Pour détecter la saisonnalité de la série,
on a fait appel à l'analyse de la variance à deux facteurs sans
répétition.
TABLE DE l'ANOVA
|
SDV
|
SDC
|
DDL
|
Moyenne des carrés
|
Fc
|
Probabilité
|
Valeur critique pour F
|
|
Lignes
|
10130,7981
|
151
|
67,0913779
|
63,136
|
1,412E-292
|
1,22674639
|
|
Colonnes
|
2,81115108
|
4
|
0,70278777
|
0,661
|
0,61904387
|
2,38668545
|
|
Erreur
|
641,834829
|
604
|
1,06264045
|
|
|
|
|
Total
|
10775,444
|
759
|
|
|
|
|
Test d'influence du facteur colonne, la période
(jours : H0 = pas d'influence)
V
Calcul de la statistique de Fisher p
Fc ? que l'on compare
à la valeur théorique lue dans la
V R
table.
F v ;v à v 1 =p-1 et v 2 =(N-1)(p-1)
degrés de liberté.
á
1 2
F c = 0,66 1 ~ F v ;v =2,386 , donc on accepte
l'hypothèse nulle, la série n'est pas saisonnière.
á
1 2
Test d'influence du facteur ligne, la tendance
(H0 =pas d'influence du facteur
semaine)
' V S que l'on compare à la valeur
théorique 3 2
F v ;v à v 3 =N-1 et v 2
=(N-1)(p-1) degrés de
á
F =
c V R
liberté.
F c = 63,136 > F v ;v =1,226 ; donc on rejette
l'hypothèse nulle la série est peut être affectée
á
3 2
d'une tendance. Mais d'après le test de Dickey-Fuller la
tendance n'est pas significativement différent de zéro, car il
est plus précis que le test de Fisher pour la tendance.
Désignation
Vp : La variance de la période, VR:
la variance résiduelle, VS : la variance de la semaine, N:
nombre de semaines, p : le nombre d'observations
(périodicité) dans la semaine (jours p=5). En conclusion La
série AJSPY est donc stationnaire; c'est à dire
intégrée d'ordre 0. Estimation des paramètres du
modèle
Il convient à présent d'estimer le modèle
susceptible de représenter la série. En observant les
corrélogrammes simple et partiel de la série stationnaire AJSPY,
On remarque que la fonction d'autocorrélation simple (AC) possède
des valeurs importantes aux retards q= 1, 2, 3, 4, 5...; et la
fonction d'autocorrélation partielle (PAC) possède des valeurs
importantes aux retards p=1, 2,4.
Par conséquent on a plusieurs modèles candidats
parmi lesquels nous avons sélectionné deux modèles :
|
Modèles
|
AIC
|
BIC
|
|
ARMA (3, 3)
|
2,86
|
2,89
|
|
ARMA (4, 2)
|
2,86
|
2,89
|
On a choisi le modèle ARMA (3, 3) d'après le
critère de parcimonie, car les deux modèles ont les mêmes
valeurs de AIC et BIC.
Estimation du processus ARMA (3,3)
L'estimation des processus ARMA repose sur la méthode du
maximum de vraisemblance. On
suppose que les résidus suivent une loi normale de moyenne
nulle et de variance 2
o? .
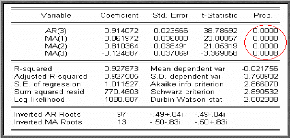
L'étape d'estimation achevée, l'étape
suivante permet de valider ou non le modèle estimé.
Validation du processus ARMA (3,3)
Test sur les paramètres
On remarque que tous les paramètres du modèle sont
significativement différents de zéro. En effet les statistiques
de Student associées sont en valeur absolue supérieurs à
1,96, ce qui est confirmé par les probabilités de
nullité des coefficients qui sont toutes inférieures à
0, 05(voir tableau estimation du processus
précédent).
Graphique des inverses des racines
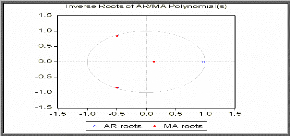
D'après la représentation graphique des inverses
des racines des polynômes de retards moyenne mobile et
autorégressif on s'aperçoit qu'ils sont tous supérieurs
à 1 en module (leurs inverses sont en module, inférieurs à
1).
Graphique des séries résiduelles
réelles et estimées

A partir de la représentation graphique des séries
résiduelles réelles et estimées nous constatons que le
modèle estimé ajuste parfaitement la série AJSPY.
Il convient maintenant d'analyser les résidus à
partir de leur fonction d'autocorrélation et d'appliquer une
série de tests.
Tests sur les résidus
$ $ ( )
Ces tests ont pour objet de vérifier la blancheur des
résidus estimés ( u L X
ê t =
t ) en
? $ ( )
L
appliquant des tests d'absence d'autocorrélation et des
tests d'homoscédasticité. Tests d'absence
d'autocorrélation
Il existe un grand nombre de tests d'absence
d'autocorrélation, les plus connus étant ceux de Box et Pierce
(1970) et Ljung et Box (1978), test des points de retournements dont on
rappelle brièvement le principe ci-dessous.
s Test de Box - Ljung
On a à tester l'hypothèse nulle
:
H0 : « Les autocorrélations
jusqu'au pas K, (K=N/5) ne sont pas significatives » C'est-à-dire
H0 : « p1 = p2
=... ? pK = 0 » Contre H1 : «
?p j : j = 1,K ,99 tel que pj ~ 0
».
2
.
K
Ce test est basé sur la statistique de Box-Ljung au pas k
: E ? ?
Q n n
= +
( 1) Y k
n k
k 1
Si 2
Q ? ? 0,95 ( K - p - q
- P - Q ) , nous acceptons l'hypothèse H
0 .
Les valeurs de la statistique de Box-Ljung ont de fortes
probabilités. Ce qui entraîne à dire que les résidus
forment un bruit blanc.
Corrélogramme simple et partiel des
résidus
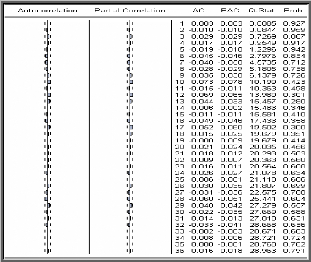
La probabilité de la statistique de Box-Ljung est
supérieure à 0,05 pour tous les retards et la valeur de la
statistique de Box-Ljung quand k = 99, p = 3, q = 3, P = 0 et Q = 0
égale à 62,153 est inférieure à 2
?0., 95 (93) = 116,51 ; On conclue alors que les
erreurs ne sont pas corrélées.
Conclusion
Les résultats du test de Box - Ljung sont identiques
à ce qu'on a remarqué de visu sur les corrélogrammes
simple et partiel.
s Test des points de retournements
Il s'agit de tester l'hypothèse nulle :
H0 : « Les ei sont
aléatoires » contre
H1 : « Il existe une corrélation
entre les ei i = 1,..., n ».
Après les calculs à l'aide du Visual Basic on a
obtenu les résultats suivants :
n - 2
|
Le nombre des points de retournements égal à P =
?
|
Xi = 490
|
i = 1
On a : n = 754 donc 2
E P n et Var P -
16 29 n
( ) ( 2) 504,66 ( ) 134.61
= - = = =
3 90
VAR ( P ) = 11,602 , ( ) 1,26
P E P
-
S = 1.26< S (tabulée) = 1,96
S = = - . Donc :
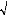
Var P
( )
Alors, on accepte l'hypothèse H0 :
« les résidus sont aléatoires ».
s Test de nullité de la moyenne des
résidus
Pour tester l'hypothèse H0: « m=0
» contre H1 : « m ~ 0 » on utilise le test
de Student
? t
.
o?/ n-1
basé sur la statistique : t =
Si t < tn-1 à
5% (=1,96) on accepte l'hypothèse de nullité de la moyenne des
résidus
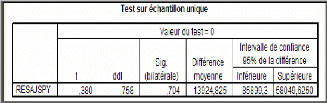
|
D'après le Tableau ci-dessus on a :
|
t = 0,3 80 qui est inférieure à 1,96; Donc on
accepte
|
l'hypothèse H0: « la moyenne des
résidus est nulle ».
s Tests de normalité sur les résidus du
modèle optimal
Les tests sont effectués à partir des valeurs
empiriques des coefficients de Skewness, Kurtosis et la statistique de
Jarque-Bera données par le logiciel EVIEWS 5.0. En utilisant le logiciel
on a l'histogramme suivant :
s Test de Skewness (asymétrie) et de Kurtosis
(aplatissement)
7 7
1 2
~ ?
0 0
ou
:
H0
:
2 -
0
71
6
= fi1 1
Coefficient de Skewness :
3
fi2
=
7
2
24
N
?
??
On teste les hypothèses suivantes :
?1
77 1 2
= =
0 0
et
H1
Coefficient de Kurtosis :
N
P
Où : 3 2
fi =
1 2 3 : est le coefficient de Skewness (l'indicateur
d'asymétrie des résidus).
1 P2
P
fi = : est le coefficient de Kurtosis (le degré
d'aplatissement de la loi des résidus).
4
P 2
2 2
Sous l'hypothèse H0 et si le nombre
d'observations est assez grand (N >30), on a :
P ?
????
N N
L 0,
--oo ?
?
6 ? ???????? ( )
1 .
N ? ?
fi
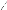
1 23
1 3 2
=
P 2


12 -
fi1
P 4
|
fi =
2 2
P 2
|
?
????
N N
L
?? ?
?
|
24 ?
0, N ? ?
|
|
( )
2
|
|
Après calculs on a obtenu :

6
N
71
-
24
Test de Skewness:
Test de Kurtosis:
0 = 6,93 > 1, 96.
3 = 19,03 > 1,96.
N
Alors, les résidus ne sont pas gaussiens. Ce qui est
confirmé par le test de Jarque et Bera s Test de Jarque et
Bera
On définit la statistique S par : S = ( )2
N N
fi ?
1 2 3
fi -
6 24
Sous (1) et (2) : S( 2)
3 Z 1 - a
2
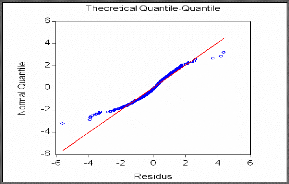
On teste H0 : « accepter la
normalité des résidus au seuil a =0,05 » contre
H1 : « Il n'y a pas de normalité des
résidus ».
Si S ( 2)
> Z 1 _ a on rejette l'hypothèse
H0 sinon on l'accepte.
2
D'après le tableau la statistique de Jarque et Bera
notée (S) est égale à 409,9777 ; elle est
supérieure à (2)
Z = 5,99.
2
s Test QQ-Plot (méthode graphique)
Le nuage de point (en bleu) est formé par (quantiles de
N(0,1), quantiles empiriques réduits des résidus), sous H0 le
nuage est rectiligne sur la droite rouge y=x )
On remarque que le nuage de point n'est pas rectiligne sur la
droite, donc l'hypothèse nulle est rejetée c'est-à-dire
les résidus ne suivent pas une loi normale.
On affirme donc que les résidus forment un bruit blanc non
gaussien.
Remarque
On ne peut pas appliquer le test de Durbin-Watson et le test
d'indépendance de Von Neumann puisque les résidus ne sont pas
gaussiens.
Test d'homoscédasticité
s Test d'effet ARCH
Une première observation du graphe des résidus
ci-dessous montre que la moyenne de cette série est constante alors que
sa variance change au cours du temps. De plus le processus étant non
gaussien, on suspecte la présence d'un effet ARCH.
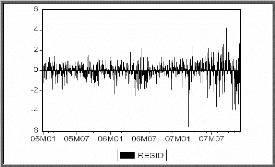
Corrélogrammes simple et partiel des
résidus au carré
A partir du Corrélogramme on remarque plusieurs termes
significativement différents de zéro cela veut dire qu'il y a
certainement un effet ARCH. Pour cela on est passé au test
d'homoscédasticité dont le résultat est sur le tableau
ci-dessous :
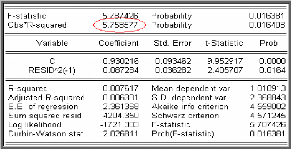
On a la statistique du multiplicateur de Lagrange
(n*R2) = 5,7585 qui est supérieure à z2 (1) =
3,84, on rejette l'hypothèse nulle d'homoscédasticité en
faveur de l'hypothèse alternative
d'hétéroscedasticité conditionnelle.
Identification du modèle de type ARCH
On a eu plusieurs modèles ARCH avec des ordres p assez
grands. Par conséquent on est passé au modèle GARCH
(1,1).
Les résultats obtenus dans la table ci-dessous montrent
que les paramètres de l'équation de la variance conditionnelle
sont significativement différents de zéro.
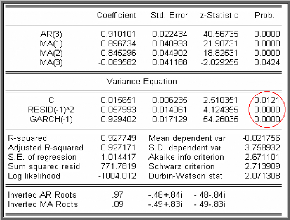
Le modèle retenu avec erreur GARCH (1, 1) s'écrit
sous la forme suivante :
(1 0,91 ) (1 0,89 0,85 0,08 )
- = + + -
B AJSPY B B B
3 2 3 & t
?
? ? =
& 17h 17 :
IID ( )
0, 1
t t t t
? ?L = + +
h h
0,0156 0,057 0.929
& - -
2
t t t
1 1
Prévision
Pour faire des prévisions, on remplace t par t+h dans
l'expression ci-dessus du modèle générateur de la
série.
On a par la suite
|
Observation
|
Prévision
|
Valeur réelle
|
Borne Inf
|
Borne Sup
|
|
761
|
148,71
|
147
|
144,84
|
152,70
|
|
762
|
148,96
|
145,59
|
143,54
|
154,56
|
|
763
|
148,99
|
148,02
|
142,55
|
155,41
|
|
764
|
149,18
|
150,14
|
142,09
|
156,40
|
|
765
|
149,41
|
150,11
|
141,54
|
157,47
|
Graphe de la série réelle et la
série prévue
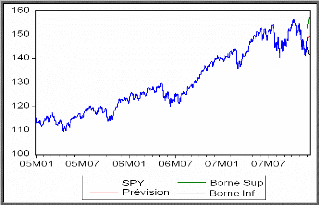
Modélisation de la série IEV
Notation
La série IEV est l'actif qui correspond à la valeur
des actions de 350 sociétés économiques qui sont
représentatives de l'économie européenne. Cet actif mesure
la performance des actions de compagnies en Autriche, Belgique, Danemark,
Finlande, France, Allemagne, Grèce, Italie, Pays Bas, Norvège,
Portugal, Espagne, Suède, Suisse et Grande-Bretagne.
Identification Les données de la
série IEV s'étalent sur une période de trois ans, les
observations sont journalières ; du 03 janvier 2005 au 30 novembre 2007
soit 760 observations. L'unité de mesure est le dollar
américain.
I- Analyse graphique
Graphe de la moyenne et la variance de la série
brute IEV
D'après les deux graphes ci-dessous, on remarque que la
moyenne et la variance varient au cours du temps, donc on peut
appréhender la non stationnarité de cette série.
Pour vérifier ceci, on va appliquer des tests statistiques
juste après la présentation des corrélogrammes simple et
partiel de la série brute.
93,74
93,62
93,38
93,26
93,14
93,02
93,5
92,9
1 2 3 4 5
IEV
MOYENNE
271
270
269
268
267
266
265
264
263
262
261
260
1 2 3 4 5
IEV
VARIANCE
Diagramme séquentiel de la série brute
IEV
On voit clairement sur le graphique de la série brute que
ce processus est non stationnaire et cela provient tout naturellement la
présence d'une tendance haussière.
130
120
110
100
90
80
70
60
50
1 71 141 211 281 351 421 491 561 631 701
TEMPS (JOURS)
IEV
GRAPHE DE LA SERIE BRUTE IEV
Examen du corrélogramme de la série
IEV
On constate que la fonction d'autocorrélation simple
(colonne AC) décroît très lentement, cela est typique d'une
série non stationnaire. En revanche, la fonction
d'autocorrélation partielle (colonne PAC) a seulement son premier terme
significativement différent de 0 (l'intervalle de confiance est
stylisé par les pointillés).
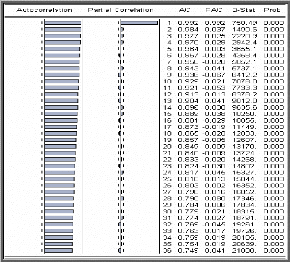
-Corrélogramme de la série IEV-
II- Analyse analytique
Application du test de Dickey- Fuller Augmenté
(DFA)
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [1], [2] et [3] de
Dickey-Fuller sur la série IEV.
Remarque
On choisit le retard (d=1) qui minimise les critères
d'informations d'Akaike et Schwarz.
s Modèle [3]
d
A = + + + A + .
IEV IEV ? c fi t Çb IE V e
t 1 j t j t
?
j
?
1
Avec et est un processus stationnaire.
On commence par tester la significativité de la tendance
en se référant aux tables de DickeyFuller. Le résultat du
test de la série IEV est donné dans la table
suivante:
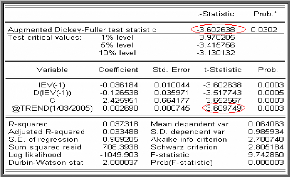
On compare la t-statistique du coefficient de la tendance
(@trend) avec la valeur donnée par la table de Dickey-Fuller. La
tendance est significativement différente de zéro puisque sa t -
statistique (3,609) est supérieure à la valeur critique (2,78),
au seuil statistique 5%. De plus la statistique de Student t?à
= -3,6026 est inférieure a la valeur critique -3,415 (donnée par
la
table de Dickey- Fuller) pour le seuil 5%.
D'où la série ne possède pas une racine unitaire (on
rejette l'hypothèse nulle «q$ = 0«).
Donc la série IEV est non stationnaire de
type TS, pour la stationnariser on a eu recours à un
ajustement linéaire, car le R2 associé est égal
à 0.953.
|
Dépendent
|
MTH
|
RSQ
|
D.F
|
F
|
SIGF
|
b0
|
b1
|
b2
|
b3
|
|
IEV
|
LIN
|
0,953
|
758
|
15247,1
|
0
|
65,81
|
0,0724
|
|
|
|
IEV
|
LOG
|
0,639
|
758
|
1341,57
|
0
|
13,2503
|
|
|
|
|
IEV
|
INV
|
0,143
|
758
|
34,16
|
0
|
-74,217
|
|
|
|
|
IEV
|
QUA
|
0,962
|
757
|
9513,65
|
0
|
0,045
|
3,60E-05
|
|
|
|
IEV
|
CUB
|
0,972
|
756
|
8801,92
|
0
|
73,7256
|
-0,0247
|
0,0003
|
-2, E-07
|
|
IEV
|
COM
|
0,961
|
758
|
18657,8
|
0
|
1,0008
|
|
|
|
|
IEV
|
POW
|
0,674
|
758
|
1569,13
|
0
|
0,1454
|
|
|
|
Remarque
On note la série ajustée par AJIEV
elle est donnée par la formule suivante :
AJIEV = IEV - y(t)
Où y(t) est l'équation de la
tendance.
Estimation de la tendance
L`estimation de l'équation d'ajustement
y(t) qui est donnée par l`équation suivante
:
y(t)=b0+b1
t
Les coefficients bo, b1
sont données par le tableau ci-dessus : D'où l`équation de
la
tendance est la suivante :
y(t)=65,81+0,0724 t
Graphe de l'ajustement linéaire de la série
IEV
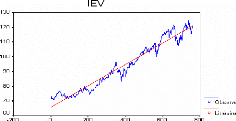
Diagramme séquentiel de la série
ajustée AJIEV
-12
12
-4
-8
4
8
0
1 76 151 226 301 376 451 526 601 676 751
AJ IEV
D'après le graphe on constate que la série
AJIEV semble stationnaire. Pour confirmer cette affirmation on
va appliquer les tests statistiques appropriés.
Test de Dickey- Fuller Augmenté sur la
série AJIEV
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [1], [2] et [3] de
Dickey-Fuller sur la série AJIEV.
Corrélogramme de la série AJIEV
On remarque que la fonction d`autocorrélation de la
série AJIEV décroît rapidement vers
zéro et la première autocorrélation partielle est
hautement significative. Cette structure est peut être celle d`une
série stationnaire.
On va confirmer cette affirmation a l`aide du test de
Dickey-Fuller et du test de Fisher.
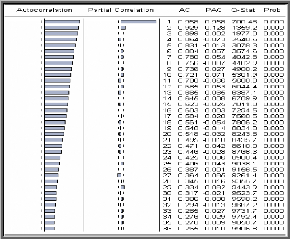
Test de Dickey- Fuller Augmenté sur la
série AJIEV
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [4], [5] et [6] de
Dickey-Fuller sur la série AJIEV.
Modèle [6]
d
.
? = + + â + A +
AJIEV çb AJIE V ? c t çb AJIEV
e
t t 1 j t j t
?
j
?
1
Avec et est un processus stationnaire.
On vérifie alors l'absence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat du test pour la
série AJIEV est donnée par la table suivante
:
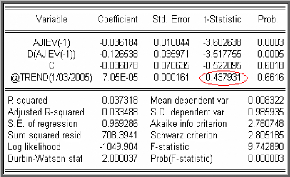
On remarque que la t- statistique de la tendance (= 0,43 79) est
inférieure aux valeurs critiques 3,48; 2,78 et 2,38 (données par
la table de Dickey- Fuller) pour les seuils 1%, 5% et10%, on
le confirme par la probabilité = 0,6616 supérieure à
0,05.
Donc la tendance n'est pas significativement différente de
zéro.
Modèle [5]
d
A = + + ? A +
AJIEV A JIE V ? AJIE V E
C .
t t j t j t
1 ?
?
1
j
Après rejet du modèle [6], on procède au
test d'absence de la constante, dont le résultat est donné par la
table suivante :
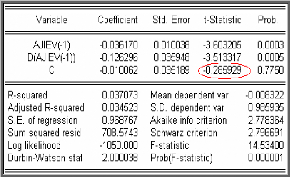
On remarque que la t-statistique de la constante (= -0.2859) est
inférieure aux valeurs critiques 3,72; 3,08 et 2,72 (données par
la table de Dickey- Fuller) pour les seuils 1%, 5% et 10%, on
le confirme par la probabilité 0,775 supérieure à 0,05.
Donc la constante n'est pas significativement différente
de zéro.
Modèle [4]
d
A = ? ? A ?
A J IE V q$ A J IE V q$ A J IE V ?
t t j t j t .
-1 -
j=1
On teste la présence d'une racine unitaire dans le
processus en testant la nullité du paramètre q$ à
l'aide d'une statistique de Student, où q$à
désigne l'estimateur des moindres carrés
ordinaires (MCO).
Le résultat du test pour la série
AJIEV est donné dans le tableau suivant :
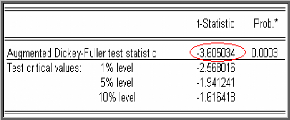
La statistique de Student (t?à = -3,650) est
inférieure aux valeurs critiques -2,5680; -1,9412
et -1,6164 pour les seuils 1%, 5% et 10% , d'où la
série ne possède pas de racine unitaire (on rejette
l'hypothèse nulle «q$ = 0«).
Test de FISHER pour la série AJIEV
Table de l'ANOVA
|
SDV
|
SDC
|
DDL
|
Moyenne des carrés
|
F
|
Probabilité
|
Valeur critique pour F
|
|
Lignes
|
8945,18746
|
151
|
59,2396521
|
61,524
|
1,942E-289
|
1,226
|
|
Colonnes
|
2,05511717
|
4
|
0,51377929
|
0,534
|
0,71110566
|
2,386
|
|
Erreur
|
58 1,573868
|
604
|
0,96287064
|
|
|
|
|
Total
|
9528,81645
|
759
|
|
|
|
|
Test d'influence de facteur colonne, la période
(jours : H0 = pas d'influence)
Fs tat = 0,534
<Ftheo = 2,386 donc on accepte
l'hypothèse nulle ; la série n'est pas saisonnière.
Test de l'influence du facteur ligne, la tendance
(H0 =pas d'influence du
facteur
semaine)
F?c
= 61,524 > tabF? = 1,226 donc (on rejette
l'hypothèse nulle) la série est peut être affectée
d'une tendance.
En conclusion la série AJIEV est donc stationnaire, c'est
à dire intégrée d'ordre 0. Estimation des
paramètres de modèle
Il convient à présent d'estimer le modèle
susceptible de représenter la série. En observant les
corrélogrammes simple et partiel de la série stationnaire AJIEV,
nous remarquons que la fonction d'auto corrélation simple (AC)
possède des valeurs importantes aux retards q=1, 2, 3, 4, 5...
; et la fonction d'auto corrélation partielle (PAC)
possède des valeurs importantes aux retards p=1,2 et 4 .
Par conséquent nous avons plusieurs
modèles candidats parmi lesquels nous avons sélectionné
deux modèles :
|
Modèles
|
AIC
|
BIC
|
|
ARMA (1, 1)
|
2,77
|
2,78
|
|
ARMA (4, 2)
|
2,77
|
2,79
|
On a choisi le modèle parcimonieux qui minimise les deux
critères AIC et BIC qui est le modèle ARMA (1,
1).
Estimation du processus ARMA (1,1)
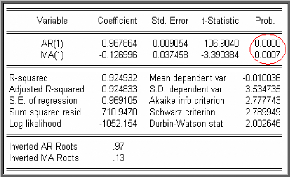
Test de validation des paramètres
On remarque que tous les paramètres du modèle sont
significativement différents de zéro. En effet les statistiques
de Student associées sont en valeur absolue supérieurs à
1,96, ce qui est confirmé par les probabilités de
nullité des coefficients qui sont toutes inférieures à
0,05.
Graphique des inverses des racines
D'après la représentation graphique des inverses
des racines des polynômes de retards moyenne mobile et
autorégressif nous constatons qu'ils sont tous les deux
supérieurs à 1 en module (leurs inverses sont en module,
inférieures à 1).
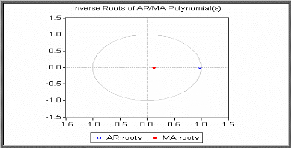
Graphique des séries résiduelles
réelles et estimées
La représentation graphique des séries
résiduelles réelles et estimées fait ressortir que le
modèle estimé ajuste convenablement la série AJIEV.
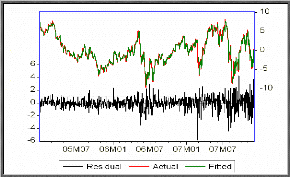
Il convient maintenant d'analyser les résidus à
partir de leur fonction d'autocorrélation et d'appliquer une
série de tests.
Tests sur les résidus du modèle
optimal
s Test de Box - Ljung
Les valeurs de la statistique de Box-Ljung ont de fortes
probabilités. Ce qui nous entraîne à dire que les
résidus forment un bruit blanc.
Corrélogramme simple et partiel des
résidus
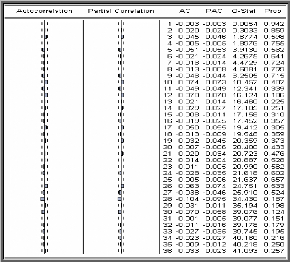
La probabilité de la statistique de Box-Ljung est
supérieure à 0,05 pour tous les retards et la valeur de la
statistique de Box-Ljung quand k = 99, p = 1, q = 1, P = 0 et Q = 0
égale à 83,488 est inférieure à 2
?0., 95 (97) = 120,99 ; on conclut alors que les
erreurs ne sont pas corrélées.
Conclusion
Les résultats du test de Box - Ljung sont identiques
à ce que nous avons remarqué de visu sur les
corrélogrammes simple et partiel.
s Test des points de retournements
n -- 2
|
Le nombre des points de retournements égal à P =
?
|
Xi = 520
|
i ? 1
On a : n = 759 donc 2
E P n et VAR P --
16 29 n
( ) ( 2) 504,66 ( ) 134, 61
? -- = = =
3 90
VAR ( P ) = 11,56 , ( ) 2,01.
P E P
--
S ? = Donc :
Var P
( )
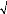
S = 1,32< S (tabulée) = 1,96
Alors, on accepte l'hypothèse H0 :
« les résidus sont aléatoires ».

12 ?
fi1
s Test de nullité de la moyenne des
résidus

|
D'après le Tableau ci-dessus on a :
|
t = 0,156 qui est inférieure à 1,96 ;
Donc on accepte
|
l'hypothèse H0 : « la moyenne des
résidus est nulle ».
s Tests de normalité sur les résidus du
modèle optimal
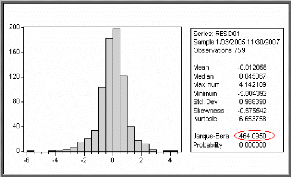
s Test de Skewness (asymétrie) et de Kurtosis
(aplatissement) Après calculs nous avons obtenu :

6
N
71
?
24
Test de Skewness:
Test de Kurtosis :
0= 7,87 > 1, 96.
3 = 19,56 > 1,96.
N
Alors : les résidus ne sont pas gaussiens. Ce qui est
confirmé par le test de Jarque et Bera.
· Test de Jarque et Bera
D'après le tableau la statistique de Jarque et Bera
(notée S) est égale à 464,095; elle est
supérieure à (2)
? = 5,99. On conclue que les résidus forment un
bruit blanc non gaussien.
2
· Test QQ-Plot (méthode
graphique)
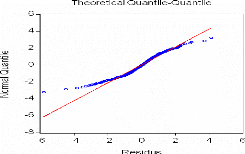
On remarque que le nuage de point n'est pas rectiligne sur la
droite, donc l'hypothèse nulle est rejetée c'est-à-dire
les résidus ne suivent pas une loi normale.
Test d'homoscédasticité
· Test d'effet ARCH
Une première observation du graphe des résidus
ci-dessous montre que la moyenne de cette série est constante alors que
sa variance change au cours du temps. De plus le processus étant non
gaussien, on suspecte la présence d'un effet ARCH.
Corrélogrammes simple et partiel des
résidus carré
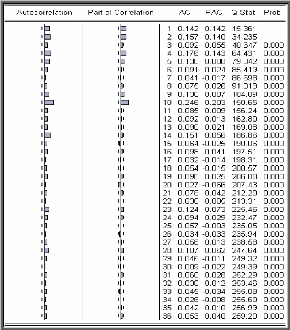
A partir du corrélogramme on remarque plusieurs termes
significativement différents de zéro cela veut dire qu'il ya
certainement un effet ARCH. Pour cela on est passé au test d'effet ARCH
dont les résultats sont sur le tableau ci-dessous :
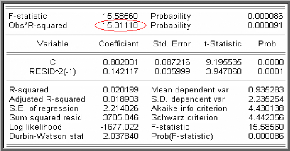
On a la statistique du multiplicateur de Lagrange
n*R2 (= 15,31) qui est supérieure à z2 (1) =
3,84, on rejette l'hypothèse nulle d'homoscédasticité en
faveur de l'hypothèse alternative
d'hétéroscedasticité conditionnelle.
Identification du modèle de type ARCH
On a eu plusieurs modèles avec des ordres p assez grands.
Par conséquent on opte pour le modèle GARCH (1,1).
Les résultats obtenus dans la table ci-dessus montrent
que les paramètres de l'équation de la variance conditionnelle
sont significativement différents de zéro.
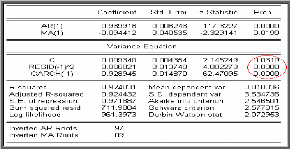
Le modèle retenu avec erreur GARCH (1, 1) s'écrit
sous la forme suivante :
(1 0, 97 ) (1 0, 09 )
+ = --
B Ajiev B
t
g
= h :
IID
t t t ? 1 t
= + +
0, 009 0, 066 0, 928
g 2
h h
t t t
? ?
1 1
?
? ?
? ?

( )
0, 1
Prévision :
Pour faire des prévisions, on remplace t par t+h dans
l'expression ci-dessous du modèle générateur de la
série.
On obtient par la suite
Observation
|
Prévision
|
Valeur réelle
|
Borne Inf
|
Borne Sup
|
761
|
120,51
|
116,80
|
116,88
|
124,16
|
762
|
120,60
|
116,10
|
115,77
|
125,44
|
763
|
120,68
|
117,05
|
114,95
|
126,42
|
764
|
120,77
|
118,29
|
114,30
|
127,23
|
765
|
120,85
|
117,99
|
113,77
|
127,93
|
|
Graphe de la série réelle et la
série prévue
Modélisation de la série
QQQQ
Notation
La série QQQQ est l'actif qui correspond à la
valeur des actions des cents plus grandes compagnies innovantes, autres que
financières, américaines et internationales cotées au
NASDAQ. Les cents plus grandes compagnies sont déterminées par
leur capitalisation sur le marché américain NASDAQ.
Identification
Les données de la série QQQQ s'étalent sur
une période de trois ans, les observations sont journalières ; du
03 janvier 2005 au 30 novembre 2007 soit 760 observations. L'unité de
mesure est le dollar américain.
I- Analyse graphique
Graphe de la moyenne et la variance de la série
brute QQQQ
D'après les deux graphes ci-dessous on peut remarquer que
la moyenne et la variance varient au cours du temps, on peut donc
appréhender la non stationnarité de cette série.
Pour vérifier ceci, on va appliquer des tests
statistiques juste après la présentation des
corrélogrammes simple et partiel de la série brute.
21,75
21,25
20,75
20,25
21,5
20,5
22
21
20
1 2 3 4 5
QQQQ
VARIANCE
QQQQ
42
41,95
41,9
41,85
41,8
41,75
41,7
1 2 3 4 5
MOYENNE
Diagramme séquentiel de la série brute
QQQQ
On voit clairement sur le graphe de la série brute que ce
processus est non stationnaire et cela provient tout naturellement de la
présence d'une tendance haussière.
60
55
50
45
40
35
30
1 71 141 211 281 351 421 491 561 631 701
GRAPHE DE LA SERIE BRUTE QQQQ
TEMPS (JOURS)
QQQQ
Examen du corrélogramme de la série
QQQQ
On constate que la fonction d'autocorrélation simple
(colonne AC) décroît très lentement, cela est typique d'une
série non stationnaire. En revanche, la fonction
d'autocorrélation partielle (colonne PAC) a seulement son premier terme
significativement différent de 0 (l'intervalle de confiance est
stylisé par les pointillés)
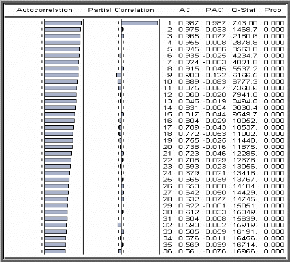
II -Analyse analytique
Application du test de Dickey- Fuller Augmenté
à la série QQQQ
On procède à l'estimation par la méthode
des moindres carrés des trois modèles (1), (2) et (3) de
Dickey-Fuller sur la série QQQQ.
Remarque
On choisit le retard (d=1) qui minimise les critères
d'informations d'Akaike et Schwarz.
s Modèle [3]
d
.
A = + + â + >JJ A +
Q Q Q Q q$ Q Q Q Q c t Q Q Q Q
q$ e
t -1 j t j t
-
j
?
1
Avec et est un processus stationnaire.
On vérifie la présence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat pour la série
QQQQ est donné dans la table suivante :
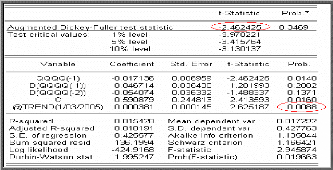
On voit que la probabilité 0.0088 < 0.05,
l`hypothèse nulle est rejetée : la tendance est significativement
différente de zéro, de plus la statistique de Student
t?à = -2.46
est supérieure a la valeur critique -3.4157
(donnée par la table de Dickey- Fuller) pour le seuil
5%. D'où la série possède une racine unitaire (on accepte
l'hypothèse nulle «q$ = 0«).
Donc la série QQQQ est non stationnaire
de type TS et DS en même temps, pour la
stationnariser on a eu recours à une différentiation d'ordre
1.
Notation : On note la série
différenciée par DQQQQ, elle est donnée par la formule
suivante :
DQQQQ t = QQQQ t -QQQQ t-1 .
Diagramme séquentiel de la série
différenciée DQQQQ
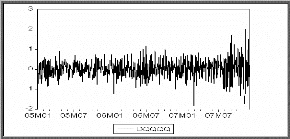
D'après le graphe on constate que la série
DQQQQ semble stationnaire. Pour confirmer cette affirmation on
va appliquer les tests statistiques appropriés.
Corrélogramme de la série
DQQQQ
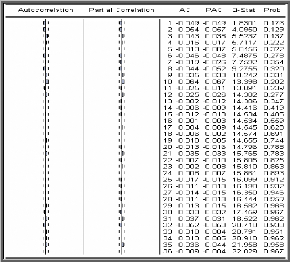
On voit que toutes les autocorrélations sont non
significativement différentes de 0 ( toutes les p-values sont
supérieures à 0,05), ce qui mène à dire que le
processus DQQQQ forme un bruit blanc.
On va confirmer cette affirmation a l`aide du test de
Dickey-Fuller et du test de Fisher.
Test de Dickey- Fuller Augmenté sur la
série DQQQQ
On procède à l'estimation par la méthode
des moindres carrés des trois modèles [4] [5] et [6] de
Dickey-Fuller sur la série DQQQQ.
Modèle [6]
d
t .
A ? ? ? â ? ? ? .
DQQQQ ? DQQQQ c t DQQQQ
t t ? ? e
1 j t j
-
Avec et est un processus stationnaire.
On vérifie l'absence de la tendance dans le processus en
testant la nullité du coefficient de la tendance
â. Le résultat du test pour la
série DQQQQ est donné par la table suivante :
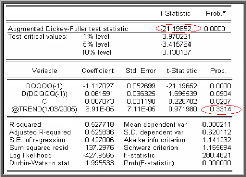
A = + ? A +
DQQQQ I DQQQQ ? I DQQQQ E
t t j t j
1 ?
j
.
t
? 1
On remarque que la probabilité de la tendance (= 0,3314)
est supérieure à 0,05 ; donc la tendance n'est pas
significativement différente de zéro.
Modèle [5]
d
A = + + A +
.
DQQQQ I DQQQQ c I DQQQQ E
t t j t j t
-1 -
j
?
1
Après rejet du modèle [6], on procède au
test d'absence de la constante, dont le résultat est donné par la
table suivante :
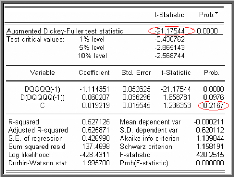
On remarque que la probabilité de la constante (= 0,2
167) est supérieure à 0,05 ; Donc la constante n'est pas
significativement différente de zéro.
Modèle [4]
d
On teste alors la présence d'une racine unitaire dans le
processus en vérifiant la nullité du paramètre q$
à l'aide d'une statistique de Student, où
q$à désigne l'estimateur des moindres
carrés ordinaires (MCO).
Le résultat du test pour la série DQQQQ est
donné dans le tableau suivant :
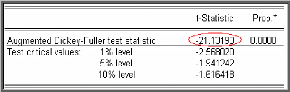
La statistique de Student (t?à = -21,13193) est
inférieure aux valeurs critiques -2,5680; -
1,9412 et -1,6164 pour les seuils 1%, 5% et 10%, d'où la
série ne possède pas de racine unitaire (on rejette
l'hypothèse nulle «q$ = 0«).
Test de FISHER pour la série DQQQQ
TABLE de l'ANOVA
SDV
|
SDC
|
DDL
|
Moyenne des carrés
|
Fc
|
Probabilité
|
Valeur critique pour F
|
Lignes
|
26,1151955
|
150
|
0,174101303
|
0,942
|
0,66708202
|
1,226
|
Colonnes
|
1,27794251
|
4
|
0,3194855629
|
1,729
|
0,14191837
|
2,386
|
Erreur
|
110,864057
|
600
|
0,184773429
|
|
|
|
Total
|
138,257195
|
754
|
|
|
|
|
|
Test d'influence de facteur colonne, la période
(jours : H0 = pas d'influence)
Fc = 1,729 <Ftheo = 2,386 donc
on accepte l'hypothèse nulle ; la série n'est pas
saisonnière.
Test de l'influence du facteur ligne, la tendance
(H0 =pas d'influence du
facteur
semaine)
statF? = 0,942 < theoF? = 1,226 donc (on
rejette l'hypothèse nulle) la série n'est pas affectée
d'une tendance.
Conclusion
La série DQQQQ est donc stationnaire et se comporte comme
un bruit blanc, passons aux tests pour le confirmer.
s Test de Box - Ljung
Les valeurs de la statistique de Box-Ljung ont de fortes
probabilités. Ce qui nous entraîne à dire que les
résidus forment un bruit blanc.
Corrélogramme simple et partiel des
résidus
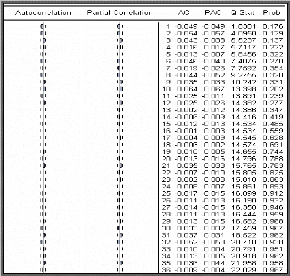
La probabilité de la statistique de Box-Ljung est
supérieure à 0,05 pour tous les retards et la valeur de la
statistique de Box-Ljung quand k = 99, p = 0, q = 0, P = 0 et Q =0 égale
à 62,97 est inférieure à 2
?0., 95 (99) = 123,23; On conclue alors que les
erreurs ne sont pas corrélées.
Conclusion
Les résultats du test de Box - Ljung sont identiques
à ce que nous avons remarqué de visu sur les
corrélogrammes simple et partiel.
s Test de la nullité de la moyenne des
résidus
Si t < tn_1 à
5% (=1,96), on accepte l'hypothèse de nullité de la moyenne des
résidus.
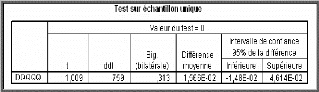
D'après le Tableau ci-dessus on a :
t = 1,009 qui est inférieure à 1,96 ; Donc on accepte

12 ?
fi1
l'hypothèse H0 : « la moyenne des
résidus est nulle ».
s Tests de normalité sur les résidus du
modèle optimal
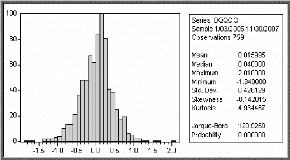
s Test de Skewness (asymétrie) et de Kurtosis
(aplatissement)

71
6
N
?
24
Test de Skewness:
Test de Kurtosis :
0= 1,6 < 1, 96.
3 = 10,85> 1,96.
N
Alors, les résidus ne sont pas gaussiens. Ce qui est
confirmé par le test de Jarque et Bera
· Test de Jarque et Bera :
D'après le tableau la statistique de Jarque et Bera
notée (S) est égale à 121,2207 ; elle est
supérieure à (2)
? = 5,99. On conclue que les résidus forment un
bruit blanc non gaussien.
2
· Test QQ-Plot (méthode graphique)
:
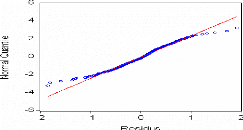
Donc l'hypothèse nulle est rejetée, les
résidus ne sont pas gaussiens.
Test d'effet ARCH
Une première observation du graphe des résidus
ci-dessous montre que la moyenne de cette série est constante alors que
sa variance change au cours du temps. De plus le processus étant non
gaussien, on suspecte un effet ARCH.
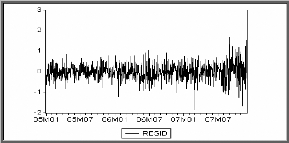
Corrélogrammes simple et partiel des
résidus au carré
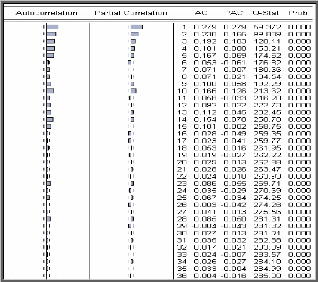
A partir du corrélogramme on remarque plusieurs termes
significativement différents de zéro cela veut dire qu'il y a
certainement un effet ARCH. Pour cela on est passé au dont les
résultats sont sur le tableau suivant :
|
H
|
Pvalue
|
T-Stat
|
Critical value
|
|
1
|
0
|
59,1448
|
3,8415
|
|
1
|
0
|
77,9396
|
5,9915
|
|
1
|
0
|
84,8244
|
7,8147
|
D'après le test H=1, les P-value sont nulles et les T-Stat
sont supérieures aux valeurs critiques, donc on rejette
l'hypothèse nulle, c'est-à-dire qu'il existe un effet ARCH.
Identification du modèle de type ARCH
Les résultats obtenus dans la table ci-dessus montrent que
les paramètres de l'équation de la variance conditionnelle sont
significatifs de zéro.
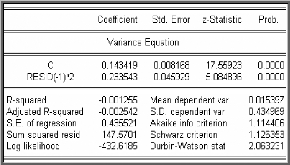
Le modèle retenu est ARIMA(0, 1, 0) avec erreur ARCH (1)
s'écrit sous la forme suivante :

E 17 17
t t t
? h IID
t :
( )
0, 1
L
?
? ?
? ?
( )
1 -- B
2
= +
0,14340,2335 E ?
t t
1
h
GLD
t t
? E
Prévision
Pour faire la prévision, on remplace t par t+h dans
l'expression ci-dessous du modèle générateur de la
série.
On a par la suite
|
Observation
|
Prévision
|
Valeur réelle
|
Borne Inf
|
Borne Sup
|
|
761
|
51,04
|
50,79
|
50,506
|
52,082
|
|
762
|
51,7
|
50,58
|
50,489
|
52,155
|
|
763
|
52,43
|
51,49
|
50,479
|
52,168
|
|
764
|
52,44
|
52,22
|
50,474
|
52,168
|
|
765
|
52,65
|
52,23
|
50,474
|
52,169
|
Graphe de la série réelle et la
série prévue
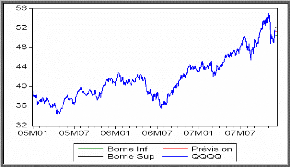
85,00
80,00
75,00
70,00
65,00
60,00
55,00
50,00
45,00
40,00
35,00
1 56 111 166 221 276 331 386 441 496 551 606 661 716
GRAPHE DE LA SERIE BRUTE GLD
TEMPS (JOURS)
Modélisation de la série GLD
Notation
La série GLD est l'actif qui correspond à la valeur
de l'OR sur les marchés internationaux.
Identification
Les données de la série GLD s'étalent sur
une période de trois ans, les observations sont journalières ; du
03 janvier 2005 au 30 novembre 2007 soit 760 observations. L'unité de
mesure est le dollar américain.
I- Etude de la stationnarité
Graphe de la moyenne et de la variance de la série
brute GLD
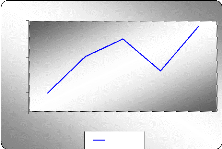
114
113
112
111
110
109
1 2 3 4 5
GLD
VARIANCE
GLD
57,66
57,55
57,44
57,33
57,22
57,11
57
1 2 3 4 5
MOYENNE
D'après les deux graphes, on remarque que la moyenne et la
variance varient au cours du temps. On peut donc dire que cette série
semble non stationnaire.
Pour vérifier ceci, on va appliquer des tests statistiques
justes après la présentation des corrélogrammes simple et
partiel de la série brute.
Diagramme séquentiel de la série brute
GLD
D`après le graphe la série a une tendance
haussière, elle n`est donc pas stationnaire. Elle a aussi un
corrélogramme qui a une structure particulière.
La représentation graphique fait ressortir une tendance
qu'il faut confirmer ou infirmer à l'aide du test de l'analyse de
variance et de Dickey-Fuller respectivement.
Examen du corrélogramme de la série
GLD
Nous constatons que la fonction d'autocorrélation simple
(colonne AC) décroît très lentement, cela est typique d'une
série non stationnaire. En revanche, la fonction
d'autocorrélation partielle (colonne PAC) a seul son premier terme
significativement différent de 0 (l'intervalle de confiance est
stylisé par les pointillés).
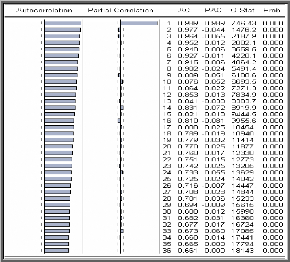
-Corrélogramme de la série GLD-
II- Application du test de Dickey- Fuller Augmenté
a la série GLD
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [1], [2] et [3] de
Dickey-Fuller sur la série GLD.
Remarque :
On choisit le retard (d=1) qui minimise les critères
d'informations d'Akaike et Schwarz. Modèle [3]
.
d
A = 1 + + + ? A +
GLD GLD c â t GLD
çb ? çb ?
t j t j t
?
j ? 1
Avec e t est un processus stationnaire.
On teste alors la présence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat de l'affichage pour la
série GLD est donné dans la table
suivante :
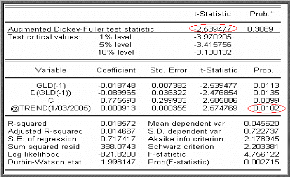
On compare la t-statistique du coefficient de la tendance
(@trend) avec la valeur donnée par la table de Dickey-Fuller. On voit
que la probabilité 0.0 10 < 0.05, l`hypothèse nulle est
rejetée : la tendance est significativement différente de
zéro, de plus la statistique de Student t?à = -2.539 est
supérieure a la valeur critique -3.4157 (donnée par la table
de Dickey-
Fuller) pour le seuil 5%. D'où la
série possède une racine unitaire (on accepte l'hypothèse
nulle «q$ = 0«).
Donc la série GLD est non stationnaire de
type TS et DS en même temps, pour la
stationnariser on a eu recours à une différentiation d'ordre
1.
Notation : On note la série
différenciée par DGLD, elle est donnée par la formule
suivante :
DGLD t = GLD t -GLD t-1.
Diagramme séquentiel de la série
ajustée DGLD
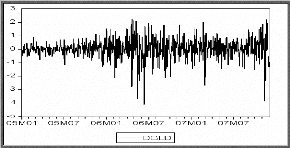
D'après le graphe on constate que la série
DGLD semble stationnaire. Pour confirmer cette affirmation on
va appliquer les tests statistiques appropriés.
Corrélogramme de la série DGLD
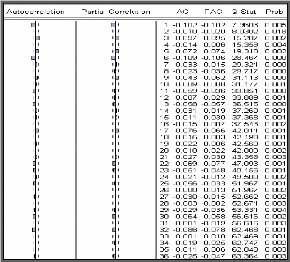
On remarque que la première autocorrélation simple
et partielle de la série DGLD est significativement différente de
0, pour cela on applique le test de Dickey-Fuller sur cette série
différenciée.
Test de Dickey- Fuller Augmenté sur la
série DGLD
On procède à l'estimation par la méthode des
moindres carrés des trois modèles [4], [5] et [6] de
Dickey-Fuller sur la série DGLD.
Modèle [6]
.
d
A = + + â + J A +
DGLD Çb DGLD ? c t Çb DGLD e
t t 1 j t j t
j=1
?
Avec et est un processus stationnaire.
Nous testons alors la présence d'une tendance dans le
processus en testant la nullité du coefficient de la tendance
â. Le résultat de l'affichage pour la
série DGLD est donné par la
table suivante :
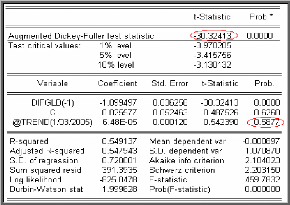
On remarque que la probabilité de la tendance (= 0,587)
est supérieure à 0,05 ; donc la tendance n'est pas
significativement différente de zéro.
Modèle [5]
d
.
A = + + A +
D G L D D G L D C D G L D
? Çb ?
t t 1 j t j t
?
j ? 1
On teste alors la présence d'une constante dans le
processus en testant la nullité du coefficient de la constante
C. Le résultat de l'affichage pour la série DGLD
est donné par la table suivante :
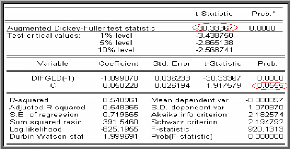
On remarque que la probabilité de la constante (= 0,055)
est supérieure à 0,05 ; Donc la constante n'est pas
significativement différente de zéro.
Modèle [4]
d
? ? ? ? ? ?
D G L D q$ D G L D ? q$ D G L D ?
t j t j t .
t 1 ?
j ? 1
On teste alors la présence d'une racine unitaire dans le
processus en testant la nullité du paramètre q$ à
l'aide d'une statistique de Student, où q$à
désigne l'estimateur des moindres
carrés ordinaires (MCO).
Le résultat de l'affichage pour la série
DGLD est donné dans le tableau suivant :
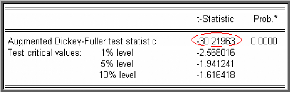
La statistique de Student t?à = -30,2196 est
inférieure aux valeurs critiques,-2,5680; -1,9412
et -1,6164 pour les seuils, 1%, 5% et 10%, d'où la
série ne possède pas de racine unitaire (on rejette
l'hypothèse nulle «q$ = 0«).
Test de FISHER pour la série DGLD
Table de l'ANOVA
|
SDV
|
SDC
|
DDL
|
Moyenne des carrés
|
F
|
Probabilité
|
Valeur critique pour F
|
|
Lignes
|
77,223075
|
150
|
0,5148205
|
0,98
|
0,53130603
|
1,227
|
|
Colonnes
|
4,6413637
|
4
|
1,16034093
|
2,22
|
0,06512035
|
2,386
|
|
Erreur
|
313,09244
|
600
|
0,52182073
|
|
|
|
|
Total
|
394,95687
|
754
|
|
|
|
|
Test d'influence de facteur colonne (jours)
Fs tat = 2,22 <Ftheo = 2,386 donc on accepte
l'hypothèse nulle ; la série n'est pas saisonnière.
Test d'influence de facteur ligne (semaines)
statF? = 0,98 < theoF? =1,227 donc (on
rejette l'hypothèse nulle) la série n'est pas affectée
d'une
tendance.
En conclusion La série DGLD est donc stationnaire.
Il convient à présent d'estimer le modèle
susceptible de la représenter. En observant les corrélogrammes
simple et partiel de la série stationnaire DGLD, on remarque que la
fonction
d'auto corrélation simple (AC) possède des
valeurs importantes aux retards q= 1, 3, 5, 6; et la fonction d'auto
corrélation partielle (PAC) possède des valeurs importantes aux
retards p= 1, 3, 5, 6.
Par conséquent on a eu plusieurs modèles candidats
parmi lesquels on a sélectionné les deux modèles :
|
Modèles
|
AIC
|
BIC
|
|
ARIMA (4, 1, 4)
|
2,16
|
2,19
|
|
ARIMA (7, 1, 7)
|
2.16
|
2.22
|
On a choisi le modèle qui minimise les deux
critères AIC et BIC on retient le modèle ARIMA (4, 1,
4).
Estimation des paramètres de
modèle
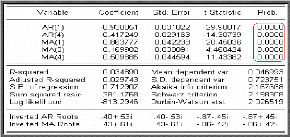
Test de validation des paramètres
Nous remarquons que tous les paramètres du modèle
sont significativement différents de zéro. En effet les rapports
des coefficients du modèle sont en valeur absolue supérieurs
à 1.96, ce qui est confirmé par la probabilité de
la nullité des coefficients qui sont toutes inférieures
à 0.05.
Représentation graphique des inverses des
racines
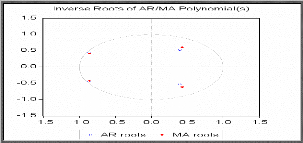
De la représentation graphique des inverses des racines
des polynômes de retards moyenne
mobile et autorégressif nous déduisons que les
racines sont toutes supérieurs à 1 en module
(leurs inverses sont en module, inférieures à
1). Représentation graphique des séries
résiduelles réelles et estimées
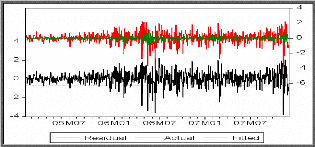
A partir de la représentation graphique des séries
résiduelles réelles et estimées on constate que le
modèle estimé ajuste bien la série DJGLD.
Il convient maintenant d'analyser les résidus à
partir de leur fonction d'autocorrélation et d'appliquer une
série de tests.
Tests sur les résidus du modèle
optimal
s Test de Box - Ljung
Les valeurs de la statistique de Box-Ljung ont de fortes
probabilités. Ce qui nous entraîne à dire que les
résidus forment un bruit blanc.
Corrélogramme simple et partiel des
résidus
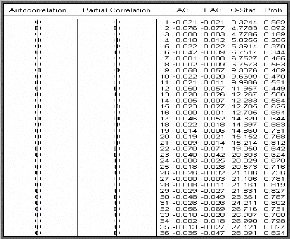
La probabilité de la statistique de Box-Ljung est
supérieure à 0,05 pour tous les retards et la valeur de la
statistique de Box-Ljung quand k = 99, p = 1, q = 0, P = 0 et Q =0 égale
à 84,9 est inférieure à 2
?0., 95 (98) = 122,11 ; on conclut alors que les erreurs
ne sont pas corrélées.
Conclusion
Les résultats du test de Box - Ljung sont identiques
à ce que nous avons remarqué de visu sur les
corrélogrammes simple et partiel.
s Test des points de retournements
n - 2
|
Le nombre des points de retournements égal à P =
?
|
Xi = 503
|
i = 1
Nous avons : n = 759 donc 2
E P n et VAR P -
16 29 n
( ) ( 2) 504,66 ( ) 134,61
= - = = =
3 90
VAR ( P ) = 11,602 , ( ) 0,14
P E P
-
S = 0,14 < S (tabulée) = 1,96
S = = - . Donc :
Var P
( )
Alors, nous acceptons l'hypothèse H0 :
« les résidus sont aléatoires » s
Test de la nullité de la moyenne des résidus
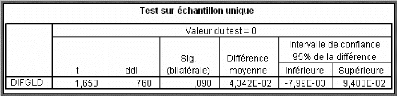
D'après le Tableau ci-dessus on a : t
= 1,658 qui est inférieure à 1,96 ; Donc on accepte
l'hypothèse H0 : « la moyenne des
résidus est nulle ».
s Tests de normalité sur les résidus du
modèle optimal
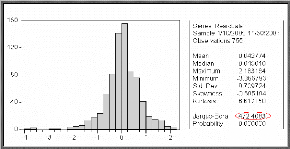
s Test de Skewness (asymétrie) et de Kurtosis
(aplatissement) :


12 ?
fi1
Après calculs on a obtenu :
71
Test de Skewness:
0 = 7,81>1,96.
6
N

24
Test de Kurtosis :
3 = 20,34 > 1,96.
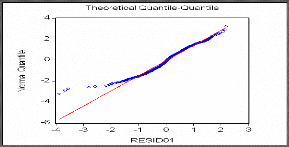
N
Test QQ-Plot (méthode graphique) :
Ainsi on rejette l'hypothèse de normalité, Ce qui
est confirmé par la statistique de Jarque et Bera notée (S) est
égale à 472,4083 qui est supérieure à (2)
? = 5,99. On conclut que les
2
résidus forment un bruit blanc non gaussien.
Test d'effet ARCH
Une première observation du graphe des résidus
ci-dessous montre que la moyenne de cette série est constante (nulle)
alors que sa variance change au cours du temps. De plus le processus
étant non gaussien, on suspecte un effet ARCH
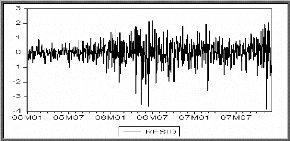
Corrélogramme simple et partiel des résidus
au carré
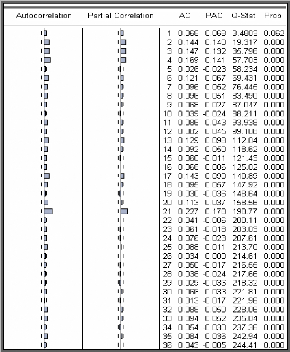
A partir du corrélogramme on remarque plusieurs termes
significativement différents de zéro cela veut dire qu'il y a
certainement un effet ARCH. Pour cela on est passé au test dont les
résultats sont dans le tableau ci-dessous :
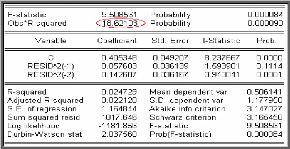
On a la statistique du multiplicateur de Lagrange n*R2
= 18,62 qui est supérieure à
z2 (2) = 5,99 alors on rejette l'hypothèse nulle
d'homoscédasticité en faveur de l'hypothèse
alternative d'hétéroscédasticité
conditionnelle.
Identification du modèle de type ARCH
On a eu plusieurs modèles candidats dont celui qui
minimise les critères AIC et BIC est le modèle ARCH (2).
Les résultats obtenus dans la table ci-dessus montrent que
les paramètres de l'équation de la variance conditionnelle sont
significativement différents de zéro.
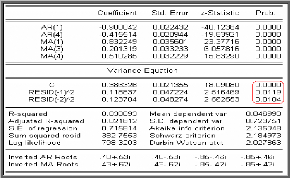
Le modèle retenu avec erreur ARCH (2) s'écrit sous
la forme suivante :

h t
0,386 0,118 0,123
+ +
& ? & ?
2 2
t t
1 1
& t
h 1l :
IID
t t t
? (
=
t
? ?
??
? & ll
1 0,9 0,41 1 (1 0,83 0,2 0 ,51 )
+ + -- = + + +
B B B GLD B B B
4 3 4
)( ) t
( )
0, 1
Prévision
Pour faire la prévision, on remplace t par t+h dans
l'expression ci-dessous du modèle générateur de la
série.
|
Observation
|
Prévision
|
Valeur réelle
|
Born Inf
|
Borne Sup
|
|
761
|
76,95
|
78,28
|
75,29
|
78,63
|
|
762
|
76,98
|
79,4
|
75,49
|
78,48
|
|
763
|
76,63
|
78,63
|
75,13
|
78,13
|
|
764
|
76,89
|
79,37
|
75,42
|
78,37
|
|
765
|
76,8
|
78,6
|
75,34
|
78,27
|
Graphe de la série réelle et la
série prévue
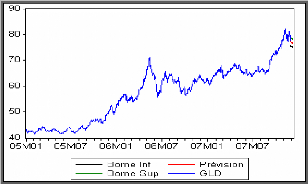
Chapitre 3 Lissage Exponentiel
I Introduction
La prévision à court terme a connu des
développements importants durant les dernières années;
elle constitue la base de l'action. La prise de décision repose en effet
toujours sur des prévisions. C'est ainsi qu'une entreprise commerciale
s'intéresse aux prévisions des ventes futures pour faire face
à la demande, gérer sa production ainsi que ses stocks, mais
aussi orienter sa politique commerciale (prix, produits et marketing). De
même, on essaie de prévoir les rendements d'un investissement, la
pénétration d'un marché ou l'effet de la modération
salariale sur l'emploi.
Les développements de la pratique statistique ont permis
de disposer d'un certain nombre d'outils de calcul, les méthodes de
lissage exponentiel font l'objet de ce chapitre, ces méthodes datent du
début des années soixante (HOLT en 1957 et BROWN en 1962). Ils
justifient amplement leurs utilisations.
Après avoir fait un lissage exponentiel simple qui ne peut
être utilisé en présence d'une tendance ou d'une
saisonnalité, nous passons au lissage double et à la
méthode de HOLT, ces derniers peuvent convenir pour des séries
présentant une tendance. Le lissage de WINTERS intervient dans les cas
ou la tendance et la composante saisonnière sont juxtaposées soit
de manière additive soit de manière multiplicative.
II Principe de base
La méthode de lissage exponentiel repose sur l'idée
suivante : les informations contenues dans une série chronologique ont
d'autant plus d'importance qu'elles sont plus récentes. Pour effectuer
une prévision, il faut affecter aux informations un poids d'autant plus
faible qu'elles proviennent d'époques plus éloignées.
III Description de la méthode
Si x1, x2 ,...; x
n sont les termes d'une chronique, la méthode du lissage
exponentiel consiste à prendre comme prévision :
x = -- a x n + a x n --
h telle que 0 ? á ?1, h est l'horizon.
$ $
n h (1 ) 1,
,
Où á, appelée constante de lissage est
généralement comprise entre 0 et 1.
Pour débuter le processus de lissage, il convient de
choisir une valeur pour la constante. Ce choix est très important car il
conditionne la prévision future à travers le degré de
pondération que l'on affecte au passé récent
et au passé lointain et ceci pour assurer une bonne qualité de
prévision.
IV Lissage exponentiel simple
Cette méthode ne doit être employée que sur
une série qui ne présente ni tendance ni De composante
saisonnière.
En prenant en compte toute l'histoire de la chronique de sorte
que plus nous nous éloignons de la prévision moins l'influence
des observations correspondantes est importante.
Cette décroissance de l'influence est de type exponentiel
ce qui justifie l'appellation.
Nous disposons d'une série chronologique x
=(x1,x2,...,x n ) de longueur enregistrée aux
dates 1, . . ., n. Nous nous situons à la date n et nous souhaitons
prévoir la valeur x n+h non encore observée
à l'horizon h. Nous notons cette prévision : x $,n h
. L'entier n est parfois appelé base
de la prévision
Les formules de lissage sont :
x = -- a x n + a x -- telle
que 0 ? á ?1 (*). Avec $
$ $
n h (1 ) 1,
, n h x 1, h = x1, h
(initialisation).
Il existe d'autres initialisations x1 comme
la moyenne de la série.
Dans le choix de á, nous distinguons les deux cas
particuliers suivants :
? Si á =0, alors toutes les prévisions sont
identiques, les prévisions restent inchangées, on dit dans ce cas
que le lissage est inerte.
? Si á =1, la prévision est égale à
la dernière valeur observée, la nouvelle valeur lissée est
toujours égale à la dernière réalisation, dans ce
cas on dit que le lissage est hyper réactif.
La relation (*) peut être développée en
remontant dans le temps (n-1, n-2, n-3,..., 1 ,0) et laisse apparaître
que la nouvelle valeur lissée est une combinaison linéaire de
toutes les observations du passé affectée d'un poids
décroissant avec l'âge, les poids sont de plus en plus faibles au
fur et à mesure que l'on s'éloigne de l'observation actuelle.
On retrouve : x $ a
(1 )
, = -- ? n h
a x
j
n j
--
n -- 1
j 0
Remarque
La formule, $ $
x = -- a x n + a x n --
h permet :
n h (1 ) 1,
,
? D'interpréter, x $,n h comme le
barycentre de xn et de x $ n -- 1 , h
affecté respectivement des
masses (1-á) et á.
? D'interpréter le lissage comme une moyenne
pondérée de la dernière réalisation et de la
dernière valeur lissée.
? De réécrire cette formule sous la forme suivante
: x x _ a x n x n h
$ , $ 1, ( $ )
n h n h (1 ) 1,
= + _ _ _
Le lissage apparaît comme le résultat de la
dernière valeur lissée corrigée par une pondération
de l'écart entre la réalisation et la prévision.
? Lorsque á est proche de 0 (a
0), la pondération s'étale sur un grand nombre
de termes dépendant du passé, la mémoire du
phénomène étudié est forte et la prévision
est peut réactive aux dernières observations.
? Lorsque á est proche de 1 (a
1), les observations les plus récentes ont un poids
prépondérant sur les anciens termes, la mémoire du
phénomène étudié est faible et la prévision
est très réactive aux dernières observations.
On peut retrouver l'équation du lissage exponentiel en
employant une approche très simple basée sur le concept de la
fonction de prévision, telle que:
x $ n , h ? a n
... ( *** )
Où an est une constante qui
dépend de l'origine de prévision.
On choisit an en utilisant un critère
de moindres carrés pondérés, avec des coefficients de
pondération décroissant exponentiellement quand on recule dans le
passé, de la forme de j
J3 ,
on l'appelle facteur d'escompte.
En appliquant la prévision au passé de la
série, l'erreur de prévision est la différencex n
_ j _ a n .
La somme des carrés des erreurs à minimiser est
alors de la forme :
|
Q a J3 x _ a
( ) ( )
? ? _
j
n n j n
|
2
|
j~0
Egalons à zéro la dérivée par rapport
à n a de cette expression:
Q a J3 x _
a
( ) ( )
= _ ? _
2 j
n n j n
j~0
Ce qui entraîne l'équation :
? = ?
J3 x _ a J3
j j
n j n
j j
~ ~
0 0 Or ( ) 1
? ? _
J3 J3 _
j 1
j~0
D'où
a J3 J3 x
$ ( ) ( )
? _ ?
1 **
j
n n
j~ 0
L'expression (**) est exactement ce que nous avons trouvé
pour la prévision x $,n h, (relation
(*)) du lissage exponentiel simple tel que le facteur d'escompte
â est remplacé par la constante de lissage á
c'est-à-dire â =á
Démonstration :
x x x
$ ( ) $
n h
, = _ +
1 a a
n n h
_ 1,
a x a
n n n
= _ +
( ) ( )
1 d'après la relation * **
a a _ 1
x x e x e x
_ = = = +
$ $
n n n n n
n
_ 1
a e a a
n n n n
= 1
( )( )
_ + +
a a
_ 1
= _ + _ +
e e a a a
n n n n n
a a a
a a a a
a e a
n n n
= _ + ?
( )
1 si 0 alors :
_ 1
( )
1 _ a
a a e a
n n n n
? + = +
1 1
y
_ _
0 1
< <
y
a
a e a avec
n n n
= +
y _ 1
En conséquence, nous pouvons dire que le lissage
exponentiel simple est justifié dans le cas d'une fonction de
prévision constante, dans le contexte de moindres carrés
pondérés, et elle ne sera vraiment constante que si l'on choisit
un facteur d'escompte â égale à 1, ce qui correspond
à á =1.
V Choix du coefficient de lissage
Pour débuter le processus de lissage, il convient de
choisir une valeur pour la constante á, ce choix est très
important car il conditionne la prévision future à travers le
degré de pondération que l'on affecte au passé
récent et au passé lointain.
Diverses procédures d'estimation ont été
établies, on s'intéresse à la méthode la plus
classique qui consiste à retenir une valeur de á qui minimise
l'écart entre la prévision et la réalisation sur la partie
connue de la chronique. Pour optimiser le choix de la constante á, il
suffit de :
? Choisir un des critères d'optimisation : le
critère MSE (Mean square error ou moyenne des carrées des
résidus) satisfait ce besoin.
? Choisir un ensemble de valeurs de á pour effectuer un
balayage, par exemple les valeurs de 0 à 1 par pas de 0,1.
? Choisir la prévision initiale.
? Pour chaque valeur de á choisie, on effectue l'ensemble
du lissage exponentiel par application des formules suivantes:
Pour n=1 à N....faire
xn .'i- --> en
x $ n
; - a en -->
fin.
? Choisir la valeur de á qui améliore aux mieux le
critère MSE (celle qui fournit la plus petite moyenne des carrées
des résidus).
VI Lissage exponentiel double
Les formules précédentes permettent de calculer
une prévision pour des séries chronologiques stationnaires sans
tendance, nous pouvons définir un lissage exponentiel double qui est
utilisé en cas de série présentant une tendance.
On part d'une fonction de prévision linéaire de la
forme:
->i,h = >n + nh
Notons que :
i>n Et t>n sont des
coefficients dépendant de n
On cherche à déterminer les valeurs des deux
paramètres par le critère des moindres carrées escomptes
â, tel que le facteur d'escompte est remplacer par á
c'est-à-dire â =á.
VII Méthode de Holt-Winters
Cette approche a pour but d'améliorer et de
généraliser le Lissage Exponentiel Simple. Nous étudions
plusieurs cas particuliers de cette méthode :
- ajustement d'une droite affine (sans saisonnalité)
- ajustement d'une droite affine plus une composante
saisonnière
- ajustement d'une constante plus une composante
saisonnière
Cette méthode est plus souple que le lissage exponentiel
amélioré, dans la mesure où elle fait intervenir deux
constantes â et y au lieu d'une á.
Telle que 0 <â < 1 et 0 < y < 1 deux
constantes fixées et les formules de mise à jour :
=flxn+(1-fl)[>(n-1)+§(n-1)1
§ = y[t(n)-
t>(n -1)1+ (1- y)§(n - 1)
La prévision prend la forme :
x $ n , h= a$1+
ha2$(n)
|
a n a n a n x x a n a n
$( ) $( ) $( ) ( ) $ $( ) $( )
2 2
1 1 2
= _ + _ + _ _ + _ + _
a ? ? ? _
1 1 1 a 1,1 1 2
1 1
n n
? ? ?
|
?
?
|
Si 2 1
? a y
= _ =
1 et
_ a
alors :
1 +a
xn
= ? _ + _ ? + _
2 $( ) $( ) ( )
2
a n a n
a 1 2
1 1 1
? ? a
2
? ?
? ?
$( ) $( ) ( )
1
= _ + _ ? _ + _
_ ?
a
a n a n a n a n a n
$( ) $( ) $( )
a 2
1 1 1
2 2 1 1 2
( )
1 _ a ? ?
_ _ ? _ + _ ?
( ) $( ) $( )
1 1 1
a 2 a n a n
? ?
1 2
2
$( ) ( )
1
= _ + _ _ _ _ ?
a n a n a n a n
_ ?
a
1 $( ) $( ) $( )
2 1 1 2
1 1
( )
1 _ ?
a ?
Remarque
Si â et y sont petits, le lissage est
fort puisque á est grand et que nous tenons compte du passé
lointain.
Application : Lissage exponentiel
Etude de la série QQQQ
La série QQQQ est tendancielle et ne
présente pas de composante saisonnière, donc dans ce cas on a
appliqué la technique de lissage double.
XLSTAT 2007
Séries temporelles
Lissage : Holt-Winters
Méthode : Linéaire (Holt)
Alpha : Optimisé / Bêta: Optimisé
Optimiser (Convergence = 0,0000 1 / Itérations = 500)
Prédiction : 5
Intervalles de confiance (%) : 95
Statistiques simples
|
Var
|
Obs
|
Obs. avec
données
manquantes
|
Obs. sans
données
manquantes
|
Min
|
Max
|
Moyenne
|
Ecart-type
|
|
QQQQ
|
760
|
0
|
760
|
34,41
|
55,03
|
41,855
|
4,589
|
Coefficients d'ajustement (QQQQ)
|
Statistique
|
Valeur
|
|
DDL
|
756,000
|
|
SCE
|
147,206
|
|
MSE
|
0,195
|
|
RMSE
|
0,44 1
|
|
MAPE
|
0,000
|
|
MPE
|
0,045
|
|
MAE
|
0,328
|
|
R2
|
0,991
|
Paramètres du modèle (QQQQ)
Coefficient de lissage de la moyenne noté :
á= 0,952
Coefficient de lissage de la tendance noté :
/3 =0,05 8
La racine des carrés résiduels moyens :
RMSE = 0,441
45
40
60
55
50
35
30
0 200 400 600 800
temps
Holt-Winters(QQQQ) QQQQ
Prédiction Borne inférieure
(95%)
Borne supérieure (95%)
Holt-Winters / (QQQQ)
Prévisions de la série QQQQ
|
Dates
|
Prévisions
|
Valeurs
réelles
|
Borne
inférieure
(95%)
|
Borne
supérieure
(95%)
|
|
03-décembre-
2007
|
51,337
|
50,79
|
50,472
|
52,202
|
|
04-decembre-
2007
|
51,345
|
50,58
|
50,118
|
52,573
|
|
05-decembre-
2007
|
51,353
|
51,49
|
49,820
|
52,887
|
|
06-decembre-
2007
|
51,361
|
52,22
|
49,548
|
53,174
|
|
07-decembre-
2007
|
51,369
|
52,23
|
49,292
|
53,446
|
Graphe de la prévision
Etude de la série IEV
La série IEV est tendancielle et ne
présente pas de composante saisonnière, donc dans ce cas on a
appliqué la technique de lissage double.
XLSTAT 2007
Séries temporelles
Lissage : Holt-Winters
Méthode : Linéaire (Holt)
Alpha : Optimisé / Bêta: Optimisé
Optimiser (Convergence = 0,0000 1 / Itérations = 500)
Prédiction : 5
Intervalles de confiance (%) : 95
Statistiques simples
|
Var
|
Obs
|
Obs. avec
données
manquantes
|
Obs. sans
données
manquantes
|
Min
|
Max
|
Moy
|
Ecart-type
|
|
IEV
|
760
|
0
|
760
|
70,80
|
124,60
|
93,35
|
16,28
|
Coefficients d'ajustement (IEV)
|
Statistique
|
Valeur
|
|
DDL
|
756,000
|
|
SCE
|
779,719
|
|
MSE
|
1,031
|
|
RMSE
|
1,016
|
|
MAPE
|
0,000
|
|
MPE
|
0,050
|
|
MAE
|
0,725
|
|
R2
|
0,996
|
Paramètres du modèle (IEV)
Coefficient de lissage de la moyenne noté : á=0,
876 Coefficient de lissage de la tendance noté : /3
=0,067
La racine des carrés résiduels moyens :
RMSE = 1,016
130
120
100
110
90
80
70
60
0 100 200 300 400 500 600 700 800
Holt-Winters(IEV) IEV
Prédiction Borne inférieure (95%)
Borne supérieure (95%)
Holt-Winters / (IEV)
temps
Les prévisions de la série IEV
|
Dates
|
Prévisions
|
Valeurs réelles
|
Borne
inférieure
(95%)
|
Borne
supérieure
(95%)
|
|
03-décembre-
2007
|
120,512
|
116,8
|
118,522
|
122,502
|
|
04-decembre-
2007
|
120,609
|
116,1
|
117,885
|
123,333
|
|
05-decembre-
2007
|
120,706
|
117,05
|
117,340
|
124,072
|
|
06-decembre-
2007
|
120,803
|
118,29
|
116,839
|
124,767
|
|
07-decembre-
2007
|
120,900
|
117,99
|
116,361
|
125,439
|
Graphe des prévisions
Etude de la série GLD
La série GLD est tendancielle et ne
présente pas de composante saisonnière, donc dans ce cas on a
appliqué la technique de lissage double.
XLSTAT 2007
Séries temporelles
Lissage : Holt-Winters
Méthode : Linéaire (Holt)
Alpha : Optimisé / Bêta: Optimisé
Optimiser (Convergence = 0,0000 1 / Itérations = 500)
Prédiction : 5
Intervalles de confiance (%) : 95
Statistiques simples
|
Var
|
Obs
|
Obs. avec
données
manquantes
|
Obs. sans
données
manquantes
|
Min
|
Max
|
Moy
|
Ecart-type
|
|
GLD
|
760
|
0
|
760
|
41,26
|
82,24
|
57,25
|
10,55
|
Coefficients d'ajustement (GLD)
|
Statistique
|
Valeur
|
|
DDL
|
756,000
|
|
SCE
|
398,807
|
|
MSE
|
0,528
|
|
RMSE
|
0,726
|
|
MAPE
|
0,000
|
|
MPE
|
0,068
|
|
MAE
|
0,512
|
|
R2
|
0,995
|
Paramètres du modèle (GLD)
Coefficient de lissage de la moyenne noté : á=0,905
Coefficient de lissage de la tendance noté : /3 =0,016
La racine des carrés résiduels moyens :
RMSE = 0,726
Les prévisions de la série GLD
|
Dates
|
Prévisions
|
Valeurs
réelles
|
Borne
inférieure
(95%)
|
Borne
supérieure
(95%)
|
|
03-décembre-
|
77,514
|
78,28
|
76,091
|
78,938
|
|
2007
|
|
|
|
|
|
04-decembre-
|
77,595
|
79,4
|
75,661
|
79,529
|
|
2007
|
|
|
|
|
|
05-decembre-
|
77,676
|
78,63
|
75,328
|
80,024
|
|
2007
|
|
|
|
|
|
06-decembre-
|
77,757
|
79,37
|
75,047
|
80,466
|
|
2007
|
|
|
|
|
|
07-decembre-
|
77,837
|
78,6
|
74,800
|
80,874
|
|
2007
|
|
|
|
|
Graphe des prévisions
45
40
85
80
75
70
65
60
55
50
0 100 200 300 400 500 600 700 800
temps
GLD Holt-Winters(GLD)
Prédiction Borne inférieure
(95%)
Borne supérieure (95%)
Holt-Winters / (GLD)
Etude de la série SPY
La série SPY est tendancielle et ne
présente pas de composante saisonnière, donc dans ce cas on a
appliqué la technique de lissage double.
XLSTAT 2007
Séries temporelles
Lissage : Holt-Winters
Méthode : Linéaire (Holt)
Alpha : Optimisé / Bêta: Optimisé
Optimiser (Convergence = 0,0000 1 / Itérations = 500)
Prédiction : 5
Intervalles de confiance (%) : 95
Statistiques simples
|
Var
|
Obs
|
Obs. avec
données
manquantes
|
Obs. sans
données
manquantes
|
Min
|
Max
|
Moy
|
Ecart-type
|
|
SPY
|
760
|
0
|
760
|
109,41
|
156,48
|
130,221
|
13,138
|
Coefficients d'ajustement (SPY)
|
Statistique
|
Valeur
|
|
DDL
|
756,000
|
|
SCE
|
840,065
|
|
MSE
|
1,111
|
|
RMSE
|
1,054
|
|
MAPE
|
0,000
|
|
MPE
|
0,034
|
|
MAE
|
0,755
|
|
R2
|
0,994
|
Paramètres du modèle (SPY)
Coefficient de lissage de la moyenne noté :
á=0,886
Coefficient de lissage de la tendance noté :
â=0,053
La racine des carrés résiduels moyens :
RMSE = 1,054
160
150
140
130
120
110
100
Holt-Winters(SPY) SPY
Prédiction Borne inférieure (95%)
Borne supérieure (95%)
100 200 300 400 500 600 700 800
Holt-Winters / (SPY)
temps
Les prévisions de la série SPY
|
Dates
|
Prévisions
|
Valeurs réelles
|
Borne
inférieure
(95%)
|
Borne
supérieure
(95%)
|
|
03-décembre-
2007
|
148,519
|
146,18
|
146,453
|
150,585
|
|
04-decembre-
2007
|
148,560
|
144,87
|
145,735
|
151,385
|
|
05-decembre-
2007
|
148,601
|
147,3
|
145,126
|
152,076
|
|
06-decembre-
2007
|
148,642
|
149,4
|
144,571
|
152,713
|
|
07-decembre-
2007
|
148,683
|
149,37
|
144,047
|
153,318
|
Graphe des prévisions
Comparaison des méthodes
Lorsqu'on adopte plusieurs méthodes de prévision
sur une ou plusieurs chroniques, on est amené au bout du compte à
les comparer afin de les départager en terme de qualité
prévisionnelle, en se basant sur un certain nombre d'outils
appelés « indicateurs de mesure de qualité
prévisionnelle ». Ils en existent plusieurs, chacun sa
procédure et ses propriétés, on
à
|
X X
t t
-
peut citer à titre d'exemple : erreur relative en
pourcentage noté : 100
ER t x
=
Xt
|
,
|
MSE...etc.
Dans notre cas, on utilise le RMSE = MSE avec :
n n
1 1 2
MSE = ? =
i (X Xà )
e 2 ? -
i i
n n
i 1
= i 1
=
: La distance au carré entre la valeur réelle et la
valeur
prédite ou bien l'erreur quadratique moyenne.
La méthode jugée meilleure parmi d'autres est celle
qui minimise le RMSE, qui signifie que la chronique est bien ajustée et
que par conséquent les prévisions seront proches des
réalisations.
Comparaison du pouvoir prédictif de la
méthode de Box-Jenkins et celui de Holt & Winters :
|
Méthode Série
|
Box & Jenkins
|
Holt & Winter
|
|
SPY
|
1.8246
|
2.0893
|
|
IEV
|
3.5077
|
3.5287
|
|
QQQQ
|
0.6964
|
0.6902
|
|
GLD
|
2.0501
|
1.2601
|
Table -1-
Une méthode directe pour comparer l'efficacité des
deux approches, consiste à comparer leur pouvoir prédictif, pour
cela nous avons calculé les prévisions hors
échantillon.
Il en résulte que les modèles ARMA(1, 1, 1)
et ARMA(3, 3) sont plus performant que celui
des modèle Holt & Winter pour les séries
IEV et SPY respectivement, par contre , les
modèle Holt & Winter semble meilleur que
les modèle ARIMA(0 ,1 ,0) et ARIMA(4, 1,
4) des séries QQQQ et GLD
respectivement. Ce jugement a eu lieu grâce aux critères
RMSE (voir Table -1-).
Voici la Table-2- qui nous permet de visualiser les
prévisions des quatre séries et leurs valeurs réelles avec
les deux méthodes Box & Jenkins et Holt &
Winters pour la période allant de 03 décembre 2007 au 07
Décembre 2007.
|
Méthode Série
|
Box & Jenkins
|
Holt & Winter
|
|
|
Prévisions
|
Prévisions
|
Valeurs réelles
|
|
SPY
|
148,70
|
148,51
|
146,18
|
|
148,96
|
148,56
|
144,87
|
|
148,98
|
148,60
|
147,3
|
|
149,17
|
148,64
|
149,4
|
|
149,41
|
148,68
|
149,37
|
|
IEV
|
120,51
|
120,52
|
116,8
|
|
120,60
|
120,61
|
116,1
|
|
120,68
|
120,70
|
117,05
|
|
120,77
|
120,80
|
118,29
|
|
120,85
|
120,90
|
117,99
|
|
QQQQ
|
51,31
|
51,33
|
50,79
|
|
51,29
|
51,34
|
50,58
|
|
51,32
|
51,35
|
51,49
|
|
51,32
|
51,36
|
52,22
|
|
51,32
|
51,36
|
52,23
|
|
GLD
|
76,95
|
77,514
|
78,28
|
|
76,98
|
77,595
|
79,4
|
|
76,63
|
77,676
|
78,63
|
|
76,89
|
77,757
|
79,37
|
|
76,8
|
77,837
|
78,6
|
Table -2-
Introduction
L'approche ARCH/GARCH a été proposée pour
prendre en compte des variances conditionnelles dépendant du temps. Le
principe général consiste donc à remettre en cause la
propriété d'homoscédasticité que l'on retient
généralement dans le cadre du modèle linéaire. La
spécification hétéroscédastique conditionnelle ou
ARCH a été initiée par Engle (1982) Pour
caractériser la dynamique des seconds moments conditionnels que l'on
retrouve dans la Plupart des séries financières. Elle a
été par la suite généralisée par Bollerslev
(1986) avec ce qu'on a appelé l'hétéroscédastique
conditionnelle autorégressive généralisée ou GARCH
c'est le modèle le plus populaire lorsqu'il s'agit d'estimer les
variances conditionnelles.
Les modèles GARCH ne se contentent pas seulement d'estimer
des variances qui évoluent dans le temps, mais incorporent
également les caractéristiques observés sur les
séries financières (leptokurtisme, clusters de
volatilité,...).
D'autres généralisations ont été
proposées par plusieurs chercheurs, on peut citer les modèles
AGARCH, EGARCH, FIGARCH, GJR-GARCH, TARCH,...
I. Diverses Modélisations
I.1 Modèle ARCH (q)
Les économistes utilisent fréquemment des
modèles estimés à l'aide des séries temporelles
où la variabilité des résidus est relativement faible
pendant un certain nombre des périodes successives, puis beaucoup plus
grande pour un certain nombre d'autres périodes et ainsi de suite, et ce
généralement sans aucune raison apparente, ce
phénomène est particulièrement fréquent et visible
avec les séries boursières, des taux des changes
étrangers, ou d'autre prix déterminés, sur les
marchés financiers, ou la volatilité semble
généralement varier dans le temps.
Récemment, d'importants approfondissements ont vu le jour
dans la littérature pour modéliser ce phénomène.
L'article novateur d'Engle (1992), expose pour la première fois le
concept d'hétéroscédasticité conditionnelle
autorégressive, ou ARCH. L'idée fondamentale est que la variance
de l'aléa au temps t dépend de l'importance des aléas au
carré des périodes passés, cependant il existe plusieurs
façons de modéliser cette idée de base, la
littérature correspondante est foisonnante.
Définition :
Un processus { E t , t Ecents }
satisfait une représentation ARCH (q) si :

E
t t t
= 11 h
q
E E a
2 ?
E h
( / )
t t t
= = +
? 1 0
i ? 1
0, 0 1 , . . . ,
a ~ V =
i
i
? ?
?
? ?L >
a 0
q
a E a
2 , 0 , O ù
~
i t i q
?
et (?t ) t désigne un bruit
blanc faible tel que E(ii t ) = 0 et ( 2 ) 2
E 1 t = cr .
Pour ce type de processus on retrouve les deux
propriétés essentielles vues précédemment à
savoir la propriété de différence de martingale
E(E t /' t ? 1 ) = 0 et la propriété
de variance conditionnelle variable dans le temps puisque :
q
i
/ I = = +?
Var ( ) 2
E . h a a E
t t t i t
1 0 ?
i ? 1
Où It ? 1 est la tribu engendrée par le
passé du processus jusqu'au temps t-1.
I.2 Modèle GARCH (p, q) (Bollerslev [1986])
Introduction
Plusieurs variantes du modèle ARCH ont
été proposées. Une variante particulièrement utile
est le modèle ARCH généralisé ou GARCH
suggéré par Bollerslev (1986). Contrairement au modèle
ARCH, la variance conditionnelle ht dépend aussi
bien de ses propres valeurs passées que des valeurs retardées de
2
Et .
Dans la pratique un modèle GARCH avec très peu
de paramètres ajuste souvent aussi bien qu'un modèle ARCH ayant
de nombreux paramètres, en particulier, un modèle simple qui
fonctionne souvent très bien est le modèle GARCH (1, 1).
On considère un modèle linéaire
autorégressif exprimé sous la forme suivante :
Xt =E(X t /X
t ? 1)+E t
Où { E t , t E cents } est un
bruit blanc faible tel que E (Et) = 0 et E
( E t E s ) = 0 sit ~ s,
satisfaisant la condition de différence de martingale.
E(EtIt?1 ) = 0 On suppose toujours que le processus peut
s'écrire sous la forme :
E t =? tht Où
i't est un bruit blanc
On cherche à modéliser la volatilité
conditionnelle du processus de bruit { E t , t E
cents }
pour tenir compte de la dynamique observée, on peut
être amené à imposer une valeur élevée du
paramètre q dans la modélisation ARCH (q) ce qui peut poser des
problèmes d'estimation.
II s'agit d'une difficulté semblable à celle que
l'on rencontre dans les modélisations de l'espérance
conditionnelle: si le théorème de Wold assure
que toute série stationnaire possède une représentation de
type MA, il est possible que pour une série donné, l'ordre de cet
MA soit particulièrement élevé, voir
infini. Dans ce cas Box et Jenkins proposent de regagner en
parcimonie en utilisant une représentation de type AR (p) ou ARMA (p,
q). Pour la variance conditionnelle, Bollerslev (1986) définit ainsi le
processus GARCH (p, q).
Définition :
Un processus { e t , t E cents }
satisfait une représentation GARCH (p q) si :
??
e ii
t t t
= h
= + ? + ?
q p t t
2 ( )
où est un bruit blanc
ij
h h
t i t i j
a a e - /3 -
0 t j
i j
= =
1 1
avec les conditions a0 > 0,
ai ~ 0 /3j ~ 0 Vi = 1,...,
q, Vj = 1,..., p suffisante pour garantir la
positivité deht . Ainsi l'erreur du processus{ X
t , t E cents } définie par le processus
GARCH(p, q) admet pour moments conditionnels : E( e t / e
t - 1) = 0
q p
Var e - h a a e /3 e
( ) 2
t t t i t i j t j
/ ' = = + ? + ?
1 0 - -
i j
= =
1 1
Tout comme le modèle ARCH, on peut exprimer le processus
2
et sous la forme d'un
processus ARMA défini dans une innovation.
u t = e t - h t
2
En introduisant cette notation dans l'équation d'un GARCH
(p, q), il dévient :
max( , )
p qp
e a a /3 e /3 e u
2 ( ) ( )
2 2
t t
- = + + + ? -
u 0 i i j t j t j
t i
- - -
i = 1 j = 1
D'où l'on tire que:
p
max( , )
p q
e a a /3 e u /3 u
2 = + ? + + - ?
2
( )
t 0 i i t j t j
t i
- -
i=1 j=1
Avec la convention ai = 0 si i>
q et /3j = 0 sij > p.
Remarque :
Le degré de p apparaît comme un degré de
moyenne mobile de la représentation ARMA
dans 2
et . A partir de cette représentation,
on peut calculer de façon aussi simple les moments
et les moments conditionnels du processus d'erreur { e
t , t E cents } mais aussi du
processus{X t ,tE cents }.
Exemple :
Considérons le cas d'un processus GARCH (1, 1) : ? ? =
e i
t t t
h
= + + > ~
?
a a
0 1
0 0
et
2
? ? h h
t t t
a a e ? /3 ?
0 1 1 1 1
Qui peut être représenté par le modèle
suivant : e a a /3 e u t /3 u t
2 = + + ? + -- ?
( ) 1
2
t 0 1 1 t 1 1
Où ( )
u t = e t ? Var e t / ? t ? 1
= e t ? h t
2 2
est un processus d'innovation pour 2
et . Sous la condition de
stationnarité du second
ordre a1 + /3 1< 1, la
variance non conditionnelle du processus { X t , t
E cents } est définie et constante dans le temps.
Sachant que ( ) ( 2 )
Var e t = E e t il suffit, à
partir de la forme ARMA (1, 1) sur 2
et de définir
l'espérance du processus :
Var
< 1
( ) ( 2 ) 0
a
e e
t E t avec
= = +
a /3
1-- - a /3
1 1
1 1
En fin, on peut montrer que, pour un processus GARCH, rappelons
la Kurtosis est directement liée à
l'hétèroscedasticité conditionnelle. Le cas de la Kurtosis
associée à la loi non conditionnelle dans un processus GARCH
conditionnellement gaussien :
e t = i t h t Où i t
??? N
iid
(0, 1)
Dans ce cas, les moments conditionnels d'ordres 2 et 4 du
processus { e t , t cents } sont liés :
E e t I t _ 3 E e t I t 1
( ) ( ) 2
4 = ? ? ? ?
2
1 _
En effet on rappelle que si une variable X suit une loi
gaussienne centrée: E X = 3 Var X = 3 ? ? E X
? ?
( ) ( ) ( ) 2
4 2 2
Si l'on considère l'espérance des membres de cette
équation, il vient :
I t ? 1 E e t
) ( )
?
4
? =
E E e t 4
? (
?
2 2
E E e I ? E E e t I t E e t
? ? ~ ? ? = ? ?
? ? ? ? ? ?
( ) ( ) ( )
2 2 2
t t 3 1 3
1 ?
Ainsi on déduit que la loi marginale a des queues plus
épaisses qu'une loi normale puisque : E e t ~ 3 ? ? E e t
? ?
( ) ( ) 2
4 2
De plus, on peut calculer la Kurtosis comme suit :
E ( )
e 4
Kurtosis=
t
2
E ( )
e 2
t
2
3
E E I
? ?
( )
2
? ?
e /
t t _ 1
2
E ( )
e 2
t
2
E ( )
e 2
( ) ( ) { ( ) ( ) }
t 3 2 2
2 2
3 + ? ?
/ _
2 2
2 2 ? ?
e e e
E E
t t t
E E
e e
t t
= + ? ? r ?
( ) { ( ) ( ) ?
3 2
3 / / 2
2 2
E E E
2 1
? ? ? ? ? ?
e e e e
t t t t
_
( )
e e
2 / ?
t t _ 1 ?
e 2
E t
Var E
? ?
= +
3 3
E
La Kurtosis est donc liée à une mesure de
l'hétèroscedasticité conditionnelle.
Proposition
Si le processus{ e t , t E cents }
satisfait une représentation GARCH (p, q) conditionnellement gaussienne,
telle que :
où ii
Var ( ) 2 ( )t
t
/ = = + ? + -
e _ ? ?e ? _
I h h
t t t i t i j
1 0 _ t j
i j
= =
1 1
??
q p
est un bruit blanc
eii
t t t
= h
La loi marginale de{ e t , t E cents
} a des queues plus épaisses qu'une loi normale (distribution
leptokurtique).
E e t ~ 3 ? ? E e t ? ?
( ) ( ) 2
4 2
Son coefficient d'excès de Kurtosis peut s'exprimer sous
la forme suivante :
E
Kurtosis= 3
_
2
E ( )
e 2
t
( )
e 4
t
Var E
? ?
( )
2
? ?
e e
/
= 3
t t _ 1
2
E ( )
e 2
II. Estimation, Prévision [Christian
GOURIEROUX]
Les paramètres du modèle GARCH peuvent être
estimés selon différentes méthodes : Maximum de
vraisemblance, pseudo maximum de vraisemblance, méthode des moments,...
(Pour plus de détail voir Gourieroux 1997). Les méthodes
généralement utilisées sont celles du maximum de
vraisemblance (MV) ou pseudo maximum de vraisemblance (PMV). L'avantage de PMV
réside dans le fait que l'estimateur obtenu converge malgré une
mauvaise spécification (supposé normale) de la distribution
conditionnelle des résidus à condition que sa loi
spécifiée appartienne à la famille des lois exponentielles
(Gourieroux et
Mont fort 1 989).Ainsi l'estimateur de MV obtenu sous
l'hypothèse de normalité des résidus et l'estimateur du
PMV sont identiques. Seules leurs lois asymptotiques respectives
différent. Toutefois dans le deux cas (MV ou PMV) sous
l'hypothèse standard, l'estimateur est asymptotiquement convergent et
asymptotiquement normal.
II.1 Estimation
II.1.1 Estimation par le pseudo maximum de vraisemblance
(PMV)
Soit {& t ,tE cents } un processus
généré par un modèle GARCH (p, q)
c'est-à-dire qu'il est solution des équations stochastiques
suivantes :
? ? ?
& ij
t t t
= h
2 t ( )
? ???
iid
p q N 0, 1
(* *)
?? = ? ? ? ?
j i
= =
1 1
h h
t j t j i t i
a a ? ? ? ?
0
Où a0>0, ai~0
J3 j ~0 Vi=1,...,p,
Vj=1,...,q
Comme le montre l'équation (**), le processus { g
t , t E cents } que nous avons défini a
toutes
ses observations conditionnellement au passé, et nous
avons les densités conditionnelles alors nous exprimons la fonction de
ses densités conditionnelles.
Soit L(O / ? t ) la fonction du pseudo
maximum de vraisemblance et
O = a 0 , a 1 ,
. . . , a p , ? 1 , . .., o q le vecteur
des paramètres inconnus. Nous notons f la fonction
( )'
densité et ( )'
? t = ? 1,..., ? T
où T est un entier positif.
T
|
L f
( / )
O ? =
t
|
( ) ( )
e C O e 6 O
=
1 ,..., / / ,
T t t
fJ f 1
?
|
t = 1
T 2
? ( ?
1
L ( / ) 2 exp
O ? ?
= l _ ?
2 t
? ( )
t 2 h
t 1 ? ?
= t
Nous obtenons la fonction log de vraisemblance suivante :
? T 2
- 1? ? ?
?
log ( / ) log 2 exp
2 t
( ) ( )
L h
0 c ?
= -
t f f ?
? t
? ? ?
2 h ?
t = 1 t ?
T ? 2
- ? ? ?
1?
f ?
log 2 h log exp
2 t
= f + -
( )
7r
? t 2 h ?
t 1 ? ? ?
= t ?
T ? ?
t 1 ? ?
= t
( )
h
= f - ?
log 2 r 2 t
? t 2 h
2
- ?
1

T ? ?
2
= - f + ?
t
1 log 2 C
? ( )
? h t
2 h
t 1 ? ?
= t
2 T
Posons ( )
1
l = - f
t t
2
l o g 2
? ? 1
r h e t
+ =
t ?
? h T
? ?
l t
1
l
t t =
C'est-à-dire ( )
1
l h
= f
- log 2
?T ? ir t
? 2 ?
+ ?
ht t ?
2 T t = 1 ?
La dérivée première et seconde de la
fonction de vraisemblance :
5
l
1 1 1
T T ? 2
5 h h
5
= -
5
? ?
t t t
+
0 0 0
2
2 2
T h T h
t t t t
= =
1 1
5 5
T 5 f ? - ? ?
2
1 1 h t t
&
? 1
2 T h h
t t t
0
= 1 5 ? ?
Prenons par exemple le cas d'un GARCH (1, 1) c'est-à-dire
( )'
0 = a 0 , a 1 ,
/3 1
Donc la variance inconditionnelle est de la forme 2
h t = a 0 + a 1 ? t
- 1 + /3 1 h t - 1
Qu'on peut écrire de la manière h h
= + +
a a ? /3
2
t t t
0 1 1 1 1
- -
=
2 ( )
2 h
a ? /3 a a ? /3
a ++ + +
0 1 1 1 0 1 2 1 2
t - t t
- -
( ) ( ) ( )
2 2 2 2
= a
/3 a e /3 e /3 a a g /3 h
1
+ + + + + +
0 1 1 1 1 2 1 0 1 3 1 3
t t
- - t t
- -
.
.
.
j j t
2 1
-
a /3 a /3 E /3
= 0 1 1 1 1 1 1
+ + h
t j
- -
j j
= =
0 0
Alors:
5 5
h h
t - 2
t j t - 1 1
_. +
? /3 /3
1 1
5 5
a a
0 0
j = 1
t - 2
5 h 2 1 1
5 h
t j t -
= +

? /3 e /3
1 1 1
t -
5 a a
5
1 0
j = 1
5 h t
5 /3 1
t - 2 t - 2
1 j 1 2 t
= + + -
j 2
a /3 a /3 e /3
- - -
0 1 1 1 1 1 1
j j t h
( )
1
t -
j = 0 j = 0
Donc:
5 - - 5
1 1 1
T h
l
T 2
e t t
5 h
? L_i
5
t +
a a a
2
0 1
2 2
T h T h
t 1 t t
5 5
? 0 ? t 0
=
T 5 ? ( - ' ?
2
1 1 h t t
e
? 1
2 T h h
t t t
1 0
5 ? ?
a
?
' ? ?
T t 2 2
1 1 ( - e
1 1
5 ' (
h
? ? + -
-
j t t
? ? /3 /3 1
1 1 ? ? 2
2 T h
t t j
1 0
? 5 ?
a h
? ? 1 ? t
l
h h
2
1 1 1
T
5 T
5 e 5
t
T 5 ? ( - ' ?

2
1 1 h t t
e
? 1
2 T h h
t t t
1 1
5 ? ?
a
?
T t 2 2
1 1 ( - 2 1 1
5 ' ( '
h e
j t
? + -
-
= ? ? t
/3 e /3
1 1 1 ? ? ?
1
t -
2 T h
t t j
1 0
? 5 ? ?
a h
? ? 1 ? t
T 2
5 5 5
l T h h
1 1 1 e
? - +
? ?
t t t
2
5 5 5
/3 /3 /3
2 2
T h T h
t ? 1 t ? 1
1 t 1 t 1
2
1 1
T
5 h ( '
e

t t
? ? ?
2 T h
?
- 1
t t t
1 1
5 /3 h
? ?
2
' ( '
et
II ?
-1
) ?
h t
- -
2 2
1 1
T t t
( j j t h
j j
1 1 2 2
t -
= ? ? ?
- -
? a /3 a /3 e /3
+ + -
? ?
1
0 1 1 1 1 1 1
t -
2Th
t j j
? ? =
1 0 0
t ?
La dérivée seconde est de la forme
5 5 5 5 ( 5 ' 5 ( 5 ' 5
5 ?
2 2 2
T ? 1 ?
h h h h h h
T
l 1 1 1 e e
- 2h
t
' ' '
= ? + ? + ?
? ?
t t t t t t t t
? ? ? ? ?
5 5 ? 5 5 5 ? 5 ) ] ? 5 ? 5 ) 5 5
6 6 ? 6 6 6 6 6 6 6 6
' 2 4 '
2 T h h h
2
t 1 t t ? 1 t t ]
II.2 Prévision
II.2.1 Forme des intervalles de
prévision
Considérons un modèle ARMA avec erreurs GARCH
conditionnellement gaussiennes :
? ?
? ?
?
?
?IL
q O e
( ) ( )
B X B
t t
=
? ?
=h où .
? ?
? est un bruit blanc
t t t t t
q p
t j
-
h h
= ? ?
2
t 0 i t i j
? ?
a a ? ? ?
i 1 j 1
= =
avec a0 > 0,a i ~ 0,/i j
~ 0 Vi=1p, j=1,q
Un tel modèle peut être analysé de deux
façons différentes :
1. On peut dans un premier temps appliquer les procédures
classiques d'estimation et d'analyse des processus ARMA, c'est à dire
faire comme si les donnés étaient conditionnellement
homoscédastiques. Les prévisions à horizon 1 des
Xt ,
$
r 1
? ( ) 1 ,
L
X X
= ? ? ?
t u t
? ? ? ?
O ( )
L
C'est-à-dire, les variables sont asymptotiquement sans
biais. Dans cette démarche, la variabilité est estimée par
:
2
T T
u u
2 1 1 2
c = ? = ?
( - ) ,
X X
t t t
4
TT
t = 1 t = 1
et des intervalles de prévisions sont :
[ X t #177; 2 c ]
u u
(En négligeant l'effet d'estimation deq$ et
O).
u2
c n'est autre qu'une estimation convergente de :
[ ( / )] [[ -E(X / X )] / X ]
2 2
E X E X X EE X
t t t t
-- =
? 1 t t-1 t-1]
EV ( / )
X X
t t ? 1
C'est-à-dire de la valeur moyenne de la
volatilité. Elle est en particulier indépendante de la date t de
prévision, de sorte que tous les intervalles de prévision ont la
même largeur.
2. Dans un deuxième temps, on peut tenir compte du
modèle d'évolution de la volatilité et appliquer les
procédures d'estimation spécifiques aux modèles
ARCH. si u$
?, O désignent les
estimateurs des polynômes autorégressifs et moyenne
mobile, les prévisions à horizon l des Xt ,
données par :
$
? ? ?
X X
= ? -
( ) 1
L , sont asymptotiquement sans biais. Les intervalles de
prévision sont
t
? ? ? ?
? ( )
u t
L
maintenant calculés par :
[ X t #177; 2 h t ]
u $
Ou ht u est l'estimation de la volatilité de la
date t. la largeur de ces intervalles dépend maintenant de la date t
considérée.
III. Extensions des modèles ARCH / GARCH
linéaires et non linéaires
La méthodologie ARCH contribue à relâcher
l'hypothèse forte de la constance de la volatilité dans le temps.
Suite à l'article pionnier d'Engle, plusieurs variantes du modèle
ARCH (p) ont été proposées afin de donner une meilleure
description et prévision de la volatilité. Les chercheurs
exploitent principalement deux dimensions pour améliorer les
modèles GARCH. D'abord, ils s'intéressent aux autres
distributions que la loi Normale pour les innovations. Aussi, ils recherchent
des modèles plus flexibles expliquant mieux l'évolution de la
volatilité. En règle générale, la classe des
modèles ARCH peut être divisée en deux sous ensembles : les
modèles ARCH linéaires et les modèles ARCH non
linéaires. Les premiers regroupent les processus ARCH (p) et GARCH (p,
q) décrits précédemment. D'autres variantes comme le
modèle GARCH intégré (IGARCH) de Engle et Bollerslev
(1986) et le modèle GARCH in Mean (GARCH-M) de Engle, Lilien et Robins
(1987) s'ajoutent à la liste des modèles linéaires.
Ensuite, la réaction de la volatilité à un
choc sur le rendement peut être différente selon le signe du choc.
Une mauvaise nouvelle a généralement un impact plus grand sur la
volatilité qu'une bonne nouvelle dans le marché boursier. Ce
mécanisme d'asymétrie sur la variance conditionnelle est
modélisable par des processus ARCH non linéaires. L'omission de
ce fait stylisée du marché, s'il est présent de
manière significative, affectera potentiellement la spécification
de la variance conditionnelle.
L'estimation des extensions du modèles ARCH/GARCH est
faite par la méthode de maximum de vraisemblance décrite
précédemment et ce en supposant une distribution des
rendements.
III.1 Modèle IGARCH
En bref, le processus IGARCH permet une persistance infinie de la
volatilité.
L'effet d'un choc se répercute sur les prévisions
de toutes les valeurs futures. Sa spécification est identique à
un modèle GARCH (p, q) à la différence qu'une contrainte
sur la somme des coefficients est imposée, elle doit être
égale à 1. Ceci implique que la variance non conditionnelle
n'existe pas dans ce processus. Le modèle RiskMetrics ou moyenne mobile
à pondération exponentielle (EWMA), développé par
la banque d'investissement JP Morgan pour le calcul de la valeur à
risque, est à la base un processus IGARCH (1,1) sans constante dans
lequel pour les données quotidiennes, le coefficient
suggéré pour le terme d'erreur au carré de la
période précédente est 0.06 et celui de la variance
conditionnelle retardée est 0.94.
Considéronsc t = ij t
ht , le processus IGARCH s'écrit :
p q
h a a c ? J3 h ?
= + ? +
2
t i t i j t j
0
i j
= =
1 1
p q
|
avec les conditions 0
a
|
> ~ ? ? ? = . Le modèle RiskMetrics est une
0, , 0 et 1
a J3 a J3
i j i j
i j
= =
1 1
|
variante du modèle IGARCH (1,1) :
h t = 0.6c t ? 1 + 0.94 h t ? 1
2
Une extension plus fonctionnelle, le modèle GARCH
fractionnellement intégré (FIGARCH), est proposée par
Baillie, Bollerlsev et Mikkelsen (1996). Ce processus est un cas
intermédiaire entre les modèles GARCH et IGARCH. La
mémoire longue de la volatilité est prise en compte mais l'effet
d'un choc n'est pas infini comme dans le modèle IGARCH, il
décroît à un rythme hyperbolique.
III.2 Modèle GARCH-M
Quant au modèle GARCH-M, il introduit la volatilité
comme un déterminant de la rentabilité. La variance
conditionnelle est alors une variable explicative dans l'équation du
rendement, elle intervient dans la fonction de régression pour
conditionner le rendement espéré. L'équation de la
variance conditionnelle du modèle GARCH-M est identique à la
formulation standard du processus GARCH, elle peut être substituée
par un autre processus de volatilité. Par exemple, un modèle
asymétrique GARCH exponentiel (Nelson, 1991). La représentation
GARCH-M est souvent utilisée pour étudier l'influence de la
volatilité sur le rendement conditionnel des titres dans les travaux
empiriques.
La formulation GARCH-M s'écrit :
Xt = HJ3 + 8ht +
c t avec c t / I t ? 1 : N(0,
ht)
Considérons e t = i t ht
p q
ha a e ? f3 h ?
= ? ? + ?
2
t i t i j t j
0
i j
= =
1 1
Dans l'ensemble, les modèles linéaires reposent sur
une spécification quadratique des perturbations sur la variance
conditionnelle. Ils supposent que c'est l'ampleur et non pas le signe des chocs
qui détermine la volatilité. Par conséquent, les chocs
positifs et négatifs de même taille ont un impact identique sur la
variance conditionnelle.
En d'autres termes, ce sont des processus symétriques.
Pourtant, l'hypothèse d'effet asymétrique des chocs sur la
volatilité, à savoir la variance conditionnelle réagit
différemment aux chocs de même amplitude selon le signe de ces
derniers, est très réaliste pour des séries
financières et monétaires. Les modèles ARCH
symétriques ont le désavantage de ne pas tenir compte de ce fait
stylisé possible dans les séries étudiées.
III.3 Modèle EGARCH
Suite à la formulation GARCH de Bollerlev (1986), une
seconde mise au point importante de la famille ARCH est sur la
spécification de l'asymétrie de la volatilité introduite
par Nelson (1991) lors d'une étude sur les rentabilités des
titres boursiers américains. À première vue, le
modèle EGARCH est caractérisé par une spécification
asymétrique des perturbations.
Il permet à de bonnes nouvelles et de mauvaises nouvelles
d'avoir un impact différent sur la volatilité.
L'évolution de la variance conditionnelle est
expliquée par l'importance des termes d'erreur passés, le signe
de ces erreurs et les variances conditionnelles retardées.
Puis, Nelson considère que les conditions sur les
paramètres du modèle GARCH sont contraignantes. Elles
restreignent la dynamique réelle de la volatilité et la
non-négativité des coefficients est souvent violée en
pratique quand l'ordre d'un processus GARCH de paramètres p et q est
grand. C'est pourquoi dans le modèle EGARCH, la variance conditionnelle
est mise sous forme logarithmique donc elle demeure toujours positive.
Dès lors, il n'est plus nécessaire d'imposer des
restrictions de positivité sur des paramètres.
Considérons :
.
et= it ht
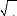
L'équation de la variance conditionnelle d'un processus
EGARCH (1,1) s'écrit :
ln(h t )
a0 +a1 ? j
?
) ? + J 1 ln( a t - 1 ) + yj t
- 1
?
2
=

t - 1 - E( j t - 1
Où jt - 1 représente les résidus
standardisés à la date t - 1. Le coefficient
a1 mesure l'effet
d'amplitude du terme d'erreur passé. Ensuite, le
coefficient y capte l'effet du signe de l'erreur. La relation de
récurrence entre la variance conditionnelle à celle de la
période précédente est mesurée par le coefficient
J1 .
La valeur E(j t - 1 ) dépend de la loi
supposée des innovations standardisées : Pour la distribution
Normale :
E ( j t )
- 1
2
=
?
Pour la loi de Student-t :
2
( ?
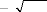
v
Fi i -
v
? )
? ? v
E (j t -
) 2
1 =
2
? ( 1)
v - F? ?
Pour la loi Generalized Error Distribution (GED) :
E
( j t - 1
) 2
=
? ? ? ?
1 3
F ? ? F ? ?
? ? ? ?
v v
Où F(.) désigne la fonction Gamma
? ? v
F? ?
? ?
2
Engle et Ng (1993) notent que la variabilité de la
variance conditionnelle du modèle EGARCH est élevée,
autrement dit la variance conditionnelle augmente très vite lorsque
l'ampleur des perturbations est grande. Ceci peut conduire à des
réactions exagérées de la variance conditionnelle dans la
prévision.
III.4 Modèle GJR-GARCH
Une autre approche permettant de capter l'effet
d'asymétrie des perturbations sur la variance conditionnelle est
introduite par Glosten, Jagannathan et Runkle (1993).
La formulation GJR-GARCH est en fait un modèle GARCH avec
l'ajout d'une variable muette qui est multipliée par le carré du
terme d'erreur de la période passée dans l'équation de la
variance conditionnelle. C'est un modèle à seuil où la
fonction indicatrice, c'est-à-dire la variable muette, est égale
à 1 si le résidu de la période précédente
est négatif et elle est nulle
autrement. De cette façon, la variance conditionnelle suit
deux processus différents selon le signe des termes d'erreur.
Considérons c t = i t ht.
L'équation de la variance conditionnelle d'un processus
GJR-GARCH s'écrit :
p q
h a a c ? J3 h ? yc ? L ?
= + + +
2 2
t i t i j t j t t
0 1 1
i j
= =
1 1
Où L t ? 1 =1 si c t ? 1 <0, 0
sinon
p q
|
Avec les conditions 0
a
|
> ~ + + <
0, , 0 0.5 1.
a J3 et a J3 y
i j i j
i j
= =
1 1
|
L'étude de Glosten, Jagannathan et Runkle (1993) porte
également sur le lien entre la prime de risque et la variance
conditionnelle des rendements boursiers aux États-Unis.
Différentes spécifications du modèle GARCH-M sont
utilisées pour fins d'analyse, notamment le modèle GJR-GARCH (p,
q) qui capte l'effet d'asymétrie des perturbations sur la variance
conditionnelle. Les auteurs se servent des données mensuelles
plutôt que journalière de l'indice de la valeur
pondéré par la capitalisation boursière de CRSP (Center
Research Security Prises) pour réaliser l'étude.
La période concernée allant d'avril 1951 à
décembre 1989. À la lumière des résultats, les
chocs négatifs provoquent une augmentation de la variance conditionnelle
plus forte que des chocs positifs. De plus, au sujet de l'impact de la variance
conditionnelle sur l'espérance conditionnelle du taux de rendement
excédentaire, le coefficient estimé est négatif comme dans
l'article de Nelson (1991) et en plus il est statistiquement différent
de zéro. Une hausse de la variance conditionnelle est donc
associée à un décroissement du rendement conditionnel.
Pourtant, ce résultat est en contradiction avec la plupart des
modèles d'évaluation d'actifs qui postulent qu'un actif
risqué devrait offrir un rendement supérieur à un actif
moins risqué.
Dans la littérature financière, cette relation
négative entre les rendements conditionnels et la variance
conditionnelle est appuyée par plusieurs travaux, notamment ceux de
Black (1976), Bekaert et Wu (2000), de Whitelaw (2000) et de Li et al. (2005).
Ce phénomène peut être expliqué par l'effet de
levier financier initialement discuté dans l'article de Black (1976),
à savoir une baisse du prix d'un titre (rendement négatif)
augmente le ratio emprunts/capitaux propres de l'entreprise en question.
Sachant qu'une entreprise plus endettée est plus
risquée, donc la volatilité du titre augmente. Une autre
explication possible du phénomène est le concept de volatility
feedback (Pindyck, 1984 ; French et al. 1987) qui suggère qu'une hausse
anticipée de la volatilité accroisse le rendement exigé
par les investisseurs puisque le titre deviendra plus risqué, ceci
implique que la valeur du titre diminue immédiatement toutes choses
étant égales par ailleurs.
III.5 Modèle TGARCH
Considérons c t =?
tht l'équation de la variance conditionnelle
d'un processus TGARCH s'écrit :
p q
h t i t i j t j t t
= + ? + +
a a c ? J3 h ? yc ? L ?
0 1 1
1 1
j =
i=
Où L t ? 1 =1 si c t ? 1 <0, 0
sinon
Le modèle TGARCH (Threshold GARCH) de Zakoian (1994) est
similaire au processus GJRGARCH à la différence qu'il
spécifie l'asymétrie sur l'écart-type conditionnel et non
sur la variance conditionnelle. Il s'agit d'un modèle à seuil
où la dynamique de l'écart-type conditionnel des rendements
diffère selon le signe des termes d'erreur.
L'équation de l'écart-type conditionnel de TGARCH
(1,1) est une fonction linéaire par morceau selon le signe du choc et
l'écart-type conditionnel de la période précédente.
Par ailleurs, dans le modèle TGARCH, il est possible d'observer une
discontinuité de la dérivée de la variance conditionnelle
par rapport aux perturbations au voisinage de zéro de telle sorte que
les problèmes d'estimation sont plus complexes que le modèle
GJR-GARCH. Une extension du modèle est suggérée dans
l'article de Rabemananjara et Zakoian (1993), les auteurs exposent qu'il est
possible de relâcher les conditions de positivité sur des
paramètres, autorisant ainsi un comportement oscillatoire de
l'écart-type conditionnel (en valeur absolue) par rapport à la
valeur du choc de la période passée.
Nous avons présenté les 3 modèles
asymétriques classiques dans la littérature financière.
D'autres travaux sur les modèles non linéaires existent, comme
ceux concernant les modèles NARCH (Nonlinear ARCH) de Higgins and Bera
(1992), NAGARCH (Nonlinear Asymmetric GARCH) de Engel et Ng (1993) et APARCH
(Asymmetric Power ARCH) de Ding, Engle et Granger (1993). Pour une description
détaillée de la littérature référant aux
autres modèles non linéaires, nous renvoyons aux travaux de
Hentschel (1995). L'auteur regroupe les modèles asymétriques dans
une forme générale. Il compare notamment les modèles par
les courbes de réponse à des perturbations (news impact
curves).
Il s'agit d'une méthode de comparaison proposée par
Engel et Ng (1993), représentant des effets des perturbations sur la
variance conditionnelle.
Par exemple, la courbe de l'impact des chocs associés au
processus GARCH standard est symétrique et elle est centrée
à l'origine. Ceci justifie que le modèle accorde une même
importance aux innovations négatives que positives de force égale
sur la volatilité.
Pour les modèles EGARCH, GJR-GARCH et TGARCH, leur courbe
de réponse à des nouvelles est centrée à l'origine
mais asymétrique, ce qui signifie que la variance conditionnelle
répond de manière différente au choc de même
amplitude selon le signe de ce dernier. Quant au modèle NAGARCH, il se
distingue par le fait que sa courbe de l'impact des perturbations est
asymétrique et de plus elle n'est pas nécessairement
centrée à l'origine.
IV Séries de rendements
En général il très intéressant de
voir juste le prix d'un investissement à savoir un titre financier dans
notre cas. Du point de vue d'un investisseur le rendement de l'investissement
est beaucoup plus intéressant. Principalement du fait qu'un investisseur
insiste plus sur le gain relatif réalisable, plutôt que sur le
prix nominal de l'investissement, mais aussi parce que le rendement comme
indice de changement du prix relatif permet de capitaliser entre compagnies,
titres bousiers et monnaies. En plus du fait que les rendements sont
généralement stationnaires, une propriété que ne
possède pas le prix actuel des titres. Dans le monde de la finance le
concept de rendement n'est pas défini de manière claire. Soit
Xt le prix d'un titre
au temps t le rendement à l'instant t peut être
défini par : Définition 1 : (le taux de
rendement arithmétique) :
r1, t
? 1
= t t
X X
-
Xt ? 1
Définition 2 : (le taux de rendement
géométrique)
r2, t
( ?
X
= I ?
X
t
log
L ?
t _ 1
Les deux rendements sont reliés par la formule suivante du
moins pour les rendements quotidiens :
r e r
r t
1, 2, t = 2, -- 1 ; t
Le taux de rendement géométrique est aussi dit
rendement composé. Tout au long de cette partie on utilise le taux de
rendement géométrique car il est le plus utilisé dans
diverses recherches ce qui permet de comparer les résultats obtenus.
IV.1 Propriétés statistiques des
séries de rendement
Les séries des prix d'actifs et de rendements
présentent généralement un certain nombre de
propriétés similaires suivant leurs
périodicités.
Soit Xt , le prix d'un actif à la date
t et rt le logarithme du rendement correspondant :
r t = X t - X t ?
log log 1
|
=log 1+D
( )
t
Où t t 1
X X
? ?
D?
t X
t
|
désigne la variation de prix.
|
Charpentier (2002) distingue six principales
propriétés qu'on va aborder successivement.
Propriété 1
(stationnarité)
Les processus stochastiques ( t )
t
X associés aux prix d'actifs sont
généralement non
stationnaire au sens de la stationnarité du second ordre,
tandis que les processus associés aux rendements sont compatibles avec
la propriété de stationnarité au second ordre.
Propriété 2
Les autocorrélations des variations de prix.
La série 2
rt associées au carrées de
rendement présente généralement des fortes
autocorrélations, tandis que les autocorrélations de la
série rt sont souvent très faibles
(hypothèse du bruit blanc).
Propriété 3 (queues de
distribution épaisse)
L'hypothèse de normalité de rendements est
généralement rejetée. Les queues des distributions
empiriques des rendements sont généralement plus épaisses
que celle d'une loi gaussienne. On parle alors de distribution
leptokurtique.
Propriété 4 (clusters de
volatilité)
On observe empiriquement que de fortes variations des
rendements sont généralement suivies de fortes variations. On
assiste ainsi à un regroupement des extrêmes des clusters ou
paquets de volatilités.
Propriété 5 (queues
épaisses conditionnelles)
Même une fois corrigée, la volatilité de
clustering (comme pour le modèle ARCH) la distribution des
résidus demeure leptokurtique même si la kurtosis est plus faible
que dans le cas non conditionnel.
Propriété 6 (effet de levier)
Il existe une asymétrie entre l'effet des valeurs
passées négatives et l'effet des valeurs passées positives
sur la volatilité des cours ou des rendements.
Les baisses de cours tendent à engendrer une augmentation
de la volatilité supérieure à celle induite par une hausse
des cours de même ampleur.
IV.2 Modèle des séries des
rendements
? = +
r C
t t
?
?
? ?
&ij
t tt
h
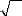
Les séries des rendements sont souvent
modélisées par des modèles GARCH. Prenons pour exemple un
modèle GARCH (1, 1), il s'écrit sous la forme suivante :
? ?L = + +
h h
a a ? ? fl ?
2
t 0 1 1 1 1
t t
Avec a0 > 0, a1 ~ 0,
/3 1 ~ 0 et C représente la moyenne de la série
rt .
Analyse et estimation des séries de
rendements
Dans cette partie on utilise le modèle par défaut
GARCH toolbox (boite à outils), pour estimer les paramètres
nécessaires à la modélisation des séries de
rendements.
? = +
r C
t t
?
?

? =
? 17 h
t t t
? ?L = + +
a a ? fi ?
2
h h
t 0 1 1 1 1
t t
Avec a0 > 0, a 1 ~ 0, /3
1 ~ 0 et C représente la moyenne de la série
rt .
Les étapes à suivre sont les suivantes :
1- Effectuer une analyse de pre-estimation pour vérifier
si les séries de rendements sont
hétéroscédastiques, et peuvent être
modélisées en utilisant la formulation GARCH.
2- Estimer les paramètres du modèle par
défaut.
3- Effectuer une analyse de post-estimation pour confirmer
l'adéquation du modèle par défaut choisi.
Série de rendement RNDQQQQ
1- Pre-estimation
? Graphe de la série brute QQQQ et la série
de rendements RNDQQQQ
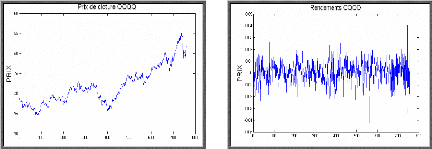
On voit clairement sur le graphe de la série brute QQQQ
que ce processus est non stationnaire, et cela provient de l'inclusion de la
tendance (caractéristique des séries de prix), par contre la
série de rendements logarithmiques RNDQQQQ à droite semble
stationnaire autour de sa moyenne, ce qui est une propriété
principales des séries de rendements.
Pour confirmer ou infirmer cette stationnarité on
procède dans un premier temps à l'analyse des
corrélogrammes simple et partiel.
? Corrélogramme simple et partielle de la
série RNDQQQQ
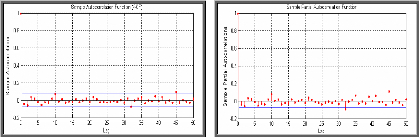
D'après les corrélogrammes simple et partiel, on
remarque que presque tous les pics sont non significatifs, ce qui confirme la
propriété de non corrélation des rendements.
s Corrélogramme des rendements au carré
RNDQQQQ
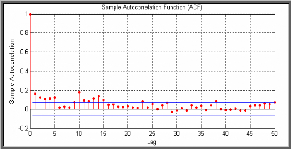
On remarque d'après le corrélogramme des
rendements au carré que les autocorrélations sont nettement
significatives, cela peut être expliqué par une forte
corrélation et une persistance du moment de second ordre.
Mesure de la corrélation
On peut quantifier les autocorrélations
précédentes en utilisant les tests d'hypothèses formelles,
comme le test de Ljung Box-Pierce et le test ARCH d'Engel.
Sous MATLAB la fonction lbqtest implémente le test de
Ljung Box-Pierce Q-test qui suppose sous l'hypothèse nulle que les
rendements sont aléatoires.
· Ljung Box-Pierce Q-Test
En utilisant le test de Box Ljung, on peut vérifier qu'il
n'y a pas de corrélation significative entre les rendements.
Remarque
Dans les tableaux qui suivent, la sortie H est une
décision booléenne, H=0 veut dire qu'il n'y a pas de
corrélation significative, H=1 implique l'existence d'une
corrélation significative.
|
H
|
Pvalue
|
T-Stat
|
Critical value
|
|
0.000
|
0.2257
|
12.9630
|
18.3070
|
|
0.000
|
0.5151
|
14.1379
|
24.9958
|
|
0.000
|
0.7751
|
15.0221
|
31.4104
|
D'après le test on remarque que H=0, les
probabilités sont toutes supérieures à 5% et les T-Stat
sont inférieures aux valeurs critiques, donc on accepte
l'hypothèse de non corrélation des rendements.
s Engel's ARCH Test
Pour appliquer le test de Engel, on implémente la fonction
ARCH test qui vérifie la présence d'un effet ARCH, sous
l'hypothèse nulle la série de rendements est une séquence
aléatoire gaussienne (c'est-à-dire pas d'effet ARCH)
|
H
|
Pvalue
|
T-Stat
|
Critical value
|
|
1.000
|
0.000
|
67.0647
|
18.3070
|
|
1.000
|
0.000
|
75.1928
|
24.9958
|
|
1.000
|
0.000
|
76.8591
|
31.4104
|
D'après le test H=1, les P-value sont nulles et les T-Stat
sont supérieures aux valeurs critiques, donc on rejette
l'hypothèse nulle, c'est-à-dire qu'il existe un effet ARCH.
2- Estimation des paramètres
La présence
d'hétéroscédasticité vue dans l'analyse
précédente, indique que la modélisation GARCH est
appropriée pour mettre en oeuvre ce phénomène.
|
Parameter
|
Value
|
Standard Error
|
T Statistic
|
|
C
|
0.00046524
|
0.00033463
|
1.3903
|
|
a0
|
2.3721 10-6
|
1.6617 10-6
|
1.4275
|
|
GARCH(1)
|
0.92729
|
0.028437
|
32.6086
|
|
ARCH(1)
|
0.04946
|
0.015371
|
3.2178
|
On remarque que tous les paramètres du modèle sont
significativement différents de zéro. La condition de
positivité des paramètres et aussi vérifiée.
Donc le modèle GARCH(1, 1) peut s'écrire sous la
forme suivante :
? = +
-8
RNDQQQQ t 4.6524 e ?
t
?
h
( )
0, 1
? ???
Où N
iid
? 7 ri
t t t
= t
? ?L = + +
2.3721 10 0.04946 0.92729
-6 2
h g
t t t
-1 -1
h
3- Post-estimation
On utilise le graphique ci-dessous pour inspecter le rapport
entre les innovations (résidus) dérivées du modèle
estimé, les écarts types conditionnels et les rendements
observés.
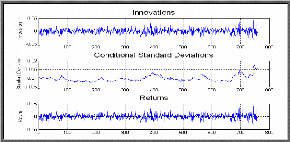
- Comparaison des innovations, écarts types
conditionnels et rendements-
On remarque dans la figure précédente que les
innovations et les rendements montrent des faibles clusters de
volatilité, on note aussi que la somme a1 + ?
1 = 0.04946+0.92729 est égale
à 0,97675 (strictement inférieurs à 1) ;
donc la condition de stationnarité du processus GARCH est
vérifiée.
? Graphe des innovations standardisées
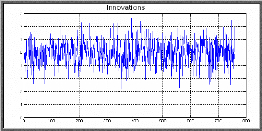
D'après le graphe des résidus standardisés,
on voit clairement qu'ils montrent une stabilité au cours du temps, avec
peu de clusters.
s Corrélogramme des résidus
standardisés au carré
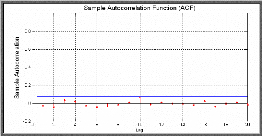
D'après le corrélogramme, on voit clairement
l'absence de corrélations des résidus standardisés
élevés au carré, car aucun pic n'est significatif.
Pour confirmer cela, on effectue le test de Box Ljung-Pierce
Q-Test et le test d'Engle.
? Ljung Box-Pierce Q-Test
|
H
|
Pvalue
|
Stat
|
Critical value
|
|
0.000
|
0.4121
|
10.3293
|
18.3070
|
|
0.000
|
0.7557
|
10.9558
|
24.9958
|
|
0.000
|
0.8865
|
12.7834
|
31.4104
|
D'après le test on remarque que H=0, les
probabilités sont toutes supérieures à 5% et les TStat
sont inférieures aux valeurs critiques, donc on accepte
l'hypothèse de non corrélation des résidus
standardisés.
s Engel's ARCH Test
|
H
|
P-value
|
T-Stat
|
Critical value
|
|
0.000
|
0.0604
|
19.0395
|
19.6751
|
|
0.000
|
0.1646
|
20.1946
|
24.9958
|
|
0.000
|
0.2670
|
23.4546
|
3 1.4104
|
D'après le test H=0, les P-value sont
supérieures à 5% et les T-Stat sont inférieures aux
valeurs critiques, donc on accepte l'hypothèse nulle,
c'est-à-dire qu'il n'existe pas d'effet ARCH sur les résidus
standardisés.
Conclusion
L'étape de post-estimation sur les résidus
standardisés montre la puissance explicative et confirme
l'adéquation du modèle par défaut.
Pour les autres séries RNDGLD, RNDSPY et RNDIEV, on a
appliqué la même procédure, on a obtenu les modèles
suivants :
Série de rendement RNDGLD
|
Parameter
|
Value
|
Standard Error
|
|
C
|
0.00053526
|
0.00036727
|
|
a0
|
9.4616 10-6
|
5.2273 10-6
|
|
GARCH(1)
|
0.94348
|
0.012373
|
|
ARCH(1)
|
0.052564
|
0.011958
|
Donc le modèle GARCH (1, 1) peut s'écrire sous la
forme suivante :
|
RNDGLDt
|
= +
0.00053526
|
Et
|
iid
t t t
= ? h i
Où N
???
t
-6 2
h = + +
9.46 16 10 0.052564 0.94348
E
t t t
-1 -1
h
? ? ?
? ?
( )
0, 1
E
Série de rendement RNDSPY
|
Parameter
|
Value
|
Standard Error
|
|
C
|
0.00046062
|
0.00026418
|
|
a0
|
5.9113 10-6
|
6.3759 10-6
|
|
GARCH(1)
|
0.90204
|
0.024266
|
|
ARCH(1)
|
0.065529
|
0.016189
|
Donc le modèle GARCH (1, 1) peut s'écrire sous la
forme suivante :
h = 5.911310
t
-6 2
+ +
0.065529 0.90204
E t t
-1 -1
h
?
?
RNDSPY 0.00046062 E
t = + t
iid
E ii
t t t
= h ?
Où N
t ???
( )
0, 1
? ???
iid
E ?
t t t
= h Où N
t
?
?
|
RNDIEV t
|
= +
0.00086285
|
E t
|
|
h = 1.9287 10
t
|
-6 2
+ +
0.089584 0.85068
E t t
-1 -1
h
|
( )
0, 1
Série de rendement RNDIEV
|
Parameter
|
Value
|
Standard Error
|
|
C
|
0.00086285
|
0.00032006
|
|
a0
|
1.9287 10-6
|
2.0614 10-6
|
|
GARCH(1)
|
0.85068
|
0.041057
|
|
ARCH(1)
|
0.089584
|
0.023105
|
Donc le modèle GARCH (1, 1) peut s'écrire sous la
forme suivante :
? i ??)
iid
?
t t t
= h OùN
t
h = 6.2741 10
t
? ? ?
? ?
-6 2
+ +
0.031218 0.95158
c t t
-1 -1
h
( )
0, 1
RND OIH
t t
0.0013296
? &
+
Série de rendement RNDOIH
|
Parameter
|
Value
|
Standard Error
|
|
C
|
0.0013296
|
0.00067436
|
|
a0
|
6.2741 10-6
|
6.173 1 10-6
|
|
GARCH(1)
|
0.95158
|
0.026164
|
|
ARCH(1)
|
0.031218
|
0.013188
|
Donc le modèle GARCH (1, 1) peut s'écrire sous la
forme suivante :
I. Introduction
Les modèles ARCH que nous avons abordés
jusqu'à présent sont des modèles ARCH univariés.
Ils permettent de décrire et de prévoir le comportement de la
volatilité d'une série monétaire et plus encore les
données financières avec une grande taille. La dynamique d'une
série comprend la non constance de la volatilité en fonction du
temps et le mécanisme asymétrique potentiel des chocs sur la
variance conditionnelle.
Toutefois, l'analyse des risques liés à un
portefeuille composé de plusieurs actifs doit se faire dans une optique
de risques multiples, à savoir les interactions entre les
différents éléments du portefeuille doivent être
prises en considération. Or, les modèles univariés ne
tiennent pas compte de la corrélation entre les actifs. Il faudrait
alors passer aux modèles multivariés afin de capter les liens
dynamiques entre les actifs.
II. Modèle VEC
Une première approche est l'extension directe du
modèle ARCH au cas multivarié. Elle a été
introduite en premier par Engle, Granger et Kraft (1984). Il s'agit d'un
modèle ARCH dans lequel chaque variance conditionnelle dépend non
seulement de ses propres erreurs au carré des périodes
précédentes, mais aussi de celles de l'autre variable du
système ainsi que du produit croisé des erreurs passées
des deux variables. En appliquant une même extension sur le processus
GARCH (1,1), nous obtenons la forme générale du modèle VEC
(1,1) proposée par Bollerslev, Engle et Wooldridge (1988). Cette
méthodologie permet une dépendance dynamique entre les
séries étudiées.
Le modèle VEC (1, 1) est défini par :
1
h = C + Ai7 + Gh t ?
t t
Où C est un vecteur et A, G sont des matrices h t = Vech(H
t )
i7 t = Vech(s t s
t )
'
Le terme Vech est un opérateur matriciel qui stocke les
éléments de la partie triangulaire
inférieure de la
matrice Ht de dimension (N x N) dans un vecteur colonne de
dimension
(N (N+1)/2 x 1). Prenons un portefeuille à 3 actifs. ?
h h h
11 12 13
t t t
H h h h
?
t t t t
= ? 21 22 23
? ? h h h
(h 11 t , h21 t ,
h31 t , h22 t , h32 t ,
h33 t ) '
31 32 33
t t t
Alors Vech(H t ) =
L'opérateur Vec sert à empiler tous les
éléments de la matrice Ht dans un vecteur colonne de dimension
((N x N) X 1).
Par exemple pour N=3
On a Vec(H t) -- (h,
. ,.1t , h21t
, h31t , h12t ,
h22t, h32t , h13t
, h23t , h33t )
Propriété de l'opérateur
Vech
Vec(ABC)-- (C' 0
A)VecB (II.1)
Où ® est le produit de Kronecker
? ? ?
IL
[
1[
h1 h h
(II.2)
(II.3)
2
1 1 t = C 1 1 + a 11'
1t-1 + g 11h11t -1
(II.4)
2 2 t = 2
C 2 2 #177; a 3 3£ 2 t
-1 + g 3 3 h 2 2 t -1
Prenons par exemple un modèle Vech (1, 1) :
h22tC22
hÿÿ11t [C11
h21t = C12 + a21 a22
a23 '1t-1'2t-1 + g21
g22 g23 k
a11 a12 a13 1
'12t-1 1 g11 g12 g13 1
k1t-1 1

'2a31a32a33j2t
-
1jg31g32g33j
h
22t
-
1j
02 _, ,
'2 _,
1t
-
1
L'écriture équivalente donne :
1t = C11 #177;
a11-1t-1 '
-12'1t-1-2t-1 #177;
a132t-1 ' g11h21t-1 +
g12h22t-1 + g13h22t-1
2
21t = C12 + a21' 1t
+ ,
-i . `^
·22'1t-1'
2t-1 + a23' 22 + t-1 '
g21h21t-1 + g22h22t-1 +
g23h22t-1
2 2t
22t = C22
+a31'11-12_,,
ir-i ' '^'32'1t-1'
2t4 #177; a33'2,t-1 ' _,
g31h21t-1 #177; g32
h22t_1 #177; g33 h22t_1
[
Donc pour deux titres financiers le nombre des paramètres
à estimer est de 21 dans un modèle VEC (1, 1). Cet exemple met en
évidence l'inconvénient majeur du modèle VEC qui est le
nombre de paramètres à estimer, il devient de plus en plus grand
au fur et à mesure que le nombre des variables augmente. Ainsi, pour un
modèle VEC(1, 1) avec 4 titres (actifs) à modéliser
conjointement, le nombre de paramètres est égal à 210 et
avec 8 titres il atteint 2628.
Afm de réduire le nombre de paramètres à
estimer, les auteurs suggèrent la formulation Diagonal VEC (DVEC). En
supposant que les matrices A et G sont diagonales, le nombre des
paramètres est égal à 9 pour un VEC (1, 1). Dans ce cas
les équations deviennent :
h
h 21 t = C + a
t-l'2t-1 + g
1 2 g 2 2h 2 1 t -1
h
En supposant que certaines matrices sont diagonales,
modéliser conjointement 8 actifs dans la formulation DVEC (1, 1) demande
maintenant l'estimation de 52 paramètres.
Les éléments du modèle DVEC (1, 1) suivent
en fait un GARCH (1, 1), a savoir que chaque variance conditionnelle est
déterminée par le carré de leurs propres erreurs
précédentes et son propre retard tandis que la covariance de deux
éléments dépend du produit croisé des erreurs
passées des deux éléments impliqués et de son
propre retard. Cependant, le grand désavantage de ce modèle est
l'absence de l'interdépendance entre les composantes du système
donc la transmission de chocs entre les variables n'est pas possible. Les
variations de la volatilité d'une variable n'influencent pas le
comportement des autres variables dans le système. D'autre part, la
positivité de la matrice des variances-covariances conditionnelles n'est
pas garantie par le modèle. Il faudrait imposer des restrictions sur
chaque élément de la matrice des variances-covariances
conditionnelles.
Etant donné, la condition de positivité de la
matrice Ht , nous pouvons réécrire le
système sous forme matricielle de la façon suivante :
f ?
a12
? ?f ?
a 11 2 e 1 1
-
11 11 1 1 2 1
= + ? ?? ?
t
h C
t t t
( )
e e
- -
? ?\ )
a e
12 2 1
t -
? ?
a 22
\ ?
2
a 22
f ?
? ?f ?
a 21 2 e
? ?? ?
? ?\ ?
a e
22 2 1
t -
? ?
a 23
\ ?
2
1 1
h C
21 12 1 1 2 1
t t t
= + ( )
e e
- -
(II.5)
t -
f ?
a32
? ?f ?
a312 e
? ?[ ?
1 1
t -
? ?
a 22
\ ?
? I\ ?
a e
h C
22 22 1 1 2 1
t t t
= + ( )
e e
- -
32 2 1
t -
2
Si nous écrivons les trois dernières
équations sous formes matricielles, nous obtenons
H t
f a a a a e
/ 2 / 2 0
11 12 21 22 1 1
?f ?
t -
0 0 /2 /2 0
?? ?
C C
= ? ? ?? ? ? ?? ?
11 12 1 1 2 1 12 13 22 23 2 1
e e a a a a e
?
f ? f ? ?
t t
- - t - (II.6)
0 0 / 2 /2 0
?? ?
\ ) \ j
C C
12 22 1 1 2 1 21 22 31 32 1 1
e e a a a a e
t t
- - t -
? /2 / 2 / 2 0
?? ?
\ a a a a e
22 23 32 33 2 1
?\ ?
t -
Si nous notons A° la matrice de
dimension 4 X4, alors la forme matricielle du modèle Vech (1, 1) peut
être écrite comme :
H t = C + I N ® e t - 1
A I N ® e t - 1
( )°? )
'
Et la condition de positivité implique C ~ 0 et
A ° ~ 0 avec au moins une inégalité stricte.
III. Modèle BEKK
Une approche qui garantit la positivité de la matrice des
variances-covariances conditionnelles est suggérée initialement
par Baba, Engle, Kraft et
Kroner (1990). Puis, elle a été
synthétisée dans l'article d'Engle et Kroner (1995). Le
modèle BEKK (p, q, k) prend en compte des interactions
entre les variables étudiées.
L'équation suivante spécifie un modèle BEKK
(1, 1, K) :
|
K K
HC C A 8 8 A G H G
* * * * * *
' ' '
= + ? +
t k t t k t k
_ _
1 1 _ 1
k=1 k=1
|
(III.1)
|
Où C , A k et G k
* * * sont des matrices de dimension (Nx N) et
C* est une matrice
triangulaire supérieure et '
CC
* * = . On observe que le 1er et le
2e terme de l'équation sont
positifs et donc pour que Ht soit positive, il faut que
Ht_1 soit positive. Voici un modèle BEKK
(1, 1, 1).
' 2
h h C C C
1 = [ 1
[ 1 [ 1 [ 1 [ 1
[
?
?
* * * * * * *
a a
11 21 11 11 21 11 12 1 1 1 1 2 1
0 a a 8 8 8
t t 11 12
? ? ? ? + ? ? ? ?
t t t
_ _ _
? ? ?
2
h h C C C
* * * * *
21 22 21 22 22 21 22 1 1 2 1 2 1
0 a a 8 8 8
t t ? J [ ]
a a
* *
J ? j ? j ? ] t t t
_ _ _ 21 22
|
[ ? ?
?
|
g g h h g
* * * *
11 12 11 1 21 1
1 [ 1 g
[ 1
t t
_ _ 1 1 12
? ?
g g h h
? ? ?
* *
21 22 21 1 22 1
? J
t t
_ _ ? J
g g
* *
21 22
|
Nous observons que le nombre de paramètres à
estimer est réduit à 11 avec un modèle BEKK (1, 1, 1) (21
pour le modèle Vech (1, 1). Si on utilise (II.1), nous pouvons
écrire le modèle (6) comme un modèle VEC :
Vec H A A Vec 8 8 G G Vec H t
( t ) ( ) ( ) ( ) ( 1 )
= ? + ® + 0 _
* * ' ' * * '
t t
_ _
1 1
D'ailleurs, le modèle BEKK est faiblement stationnaire si
les racines caractéristiques De ( A A ) ( G G )
* * * *
® + ® sont plus petites que 1 en valeur absolue et
donc nous avons :
_ 1
Vec E VecH A A G G Vec
( ) ( ) ( 2 ( ) ( ) ) ( )
>. = = I _ ® _ ® Q
t N ' '
* * * *
Néanmoins, bien que le nombre des paramètres
à estimer soit inférieur à celui du modèle Vech, il
demeure encore très élevé. Par exemple, pour un
modèle BEKK (1, 1, 8) ayant 8 actifs dans le système, il faut
estimer jusqu'à 164 paramètres. Les recherches utilisant ce
modèle limitent le nombre d'actifs étudiés et/ou imposent
des restrictions comme de supposer que les corrélations sont constantes
(Bollerslev 1990). Cependant, cette hypothèse est très forte
puisque plusieurs travaux empiriques montrent que les corrélations
varient au cours du temps. Le processus FARCH (Factor ARCH) proposé par
Engle, Ng et Rothschild (1990) est un cas particulier du modèle BEKK
avec des facteurs communs dans la volatilité des séries.
En imposant une structure commune aux éléments de
la matrice des variances-covariances, le nombre de paramètres à
estimer dans un modèle FGARCH (1, 1, 8) est réduit à
54.
IV. Modèle CCC
Comparée aux modèles multivariés
précédents, la formulation CCC (Constant Conditional Correlation)
de Bollerslev (1990) diminue grandement le nombre de paramètres à
estimer. Par exemple, modéliser conjointement 8 actifs exige
l'estimation de 52 paramètres. D'ailleurs, le modèle permet aux
covariances conditionnelles de varier dans le temps, mais en supposant que les
corrélations entre les variables restent constantes. La
méthodologie CCC consiste à estimer en premier la variance
conditionnelle de chaque variable du système avec un modèle de
type ARCH quelconque. Une matrice diagonale contenant ces variances
conditionnelles est ensuite construite et la racine carrée de cette
matrice donne une matrice diagonale des écart- types conditionnels
Dt des variables étudiées. Le calcul de la
matrice des variances
covariances conditionnelles est obtenue par le produit de trois
matrices : la matrice diagonale des écart-types
conditionnels(Dt), la matrice de la structure des
corrélations entre les variables (R) et la matrice diagonale
des écart-types conditionnels(Dt).
L
HD RD
t t t
=

Ddiag h h h
t t t NNt
= ( 11 , 22 ,..., )
R p avec ? i n
= ? ?
ij ii
, 1 1,...,
Où R est un une matrice (N x N) contenant les
corrélations constantes. Les variances conditionnelles
hiit pour i= 1, ..., N, sont estimés à partir
d'un modèle GARCH univarié. Nous
pouvons écrire la covariance entre deux actifs
hijt comme :
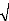
h ijt = p ij h iit h
jjt , Vi ~ j
La matrice des variances-covariances conditionnelles est presque
toujours définie positive en pratique en raison de la
méthodologie d'estimation. L'hypothèse fondamentale du
modèle CCC est le fait que les corrélations conditionnelles sont
constantes dans le temps. L'avantage de cette hypothèse est la
facilité de l'estimation des paramètres et le nombre moins grand
de paramètres à estimer. Mais, comme le modèle BEKK,
l'hypothèse de constance des corrélations ne résiste pas
à la réalité des faits.
La condition de positivité de Ht exige
la positivité de R et de hiit pour i=1,...,
N. Dans le
modèle CCC, les éléments de la matrice des
corrélations R sont constants. La dynamique de la covariance
est déterminée seulement par deux variances conditionnelles, ce
qui implique un
paramètres en R (matrice des corrélations).
nombre de ( 1)
N N -
2
Pour une description détaillée des modèles
GARCH multivariés présentés précédemment, le
nombre de paramètres à estimer représente un
problème majeur dans l'application des modèles
multivariés. Dans ces conditions, il faut faire des compromis notamment
limiter le nombre d'actifs à modéliser dans le système et
imposer des restrictions comme la constance des corrélations dans le
temps. En effet, les modèles présentés
précédemment permettent aux covariances conditionnelles entre les
variables étudiées de changer dans le temps mais ces variations
sont entièrement attribuées aux fluctuations des variances
conditionnelles. Ainsi, Tse (2000), en utilisant le test du multiplicateur de
Lagrange, rejettent l'hypothèse nulle de constance des
corrélations entre les marchés boursiers de Hong Kong, Japon et
Singapore estimées à partir d'un modèle GARCH
multivarié BEKK de Engle et Kroner (1995). Par ailleurs, les
mécanismes d'asymétrie des chocs sur les variances et les
corrélations conditionnelles ne sont pas pris en considération
par ces modèles (à l'exception du modèle CCC où il
est possible de modéliser la variance conditionnelle des séries
avec des modèles ARCH non linéaires). Cependant, il est
établi que la volatilité peut réagir différemment
selon le signe des chocs et la corrélation entres les marchés
boursiers a tendance à augmenter en période de baisse. La
négligence de ces phénomènes constitue une source d'erreur
possible dans l'estimation de la matrice des variances-covariances
conditionnelle, particulièrement dans les situations extrêmes
comme une crise financière.
Estimation de la matrice de
corrélation
Soit rt le vecteur de rendements et
&t le vecteur de résidus standardisés
1
& t D t ? r t
?
L'estimation de la matrice de corrélation constante est
donnée par :
R
'
& &
tt
1 T
? ?T
IV.1 Test de constance de corrélation
Une motivation première de cette approche est que les
corrélations entre les actifs ne soient pas constantes au cours du
temps. Il faudra donc effectuer un test de constance de corrélation. Il
s'agit d'un problème difficile. Engle et Sheppard (2001) ont
proposé le test suivant :
p
H0 : Rt R,V
te T Contre H1 :
Vechu(Rt)
VechuR)+EfiiVechu(Rt_i)
i
Où Vechu est un Vech modifié
qui choisit seulement les éléments au dessus de la diagonale.
Rt c'est la matrice de corrélation dynamique.
Après avoir estimé les modèles GARCH
univarié on standardise les résidus pour chaque série,
soit Di1rt
On estime ensuite la corrélation entre les résidus
standardisés et on standardise conjointement
1
|
le vecteur des résidus univariés
standardisés. C'est-à-dire que l'on utilise
|
~~R 2D--t1r
t
|
.
|
Où R2 est la racine carrée de
la matrice symétrique R .
Sous l'hypothèse nulle de corrélation constante,
ces résidus sont indépendants identiquement distribués
(iid) de matrice de variance covariance 1k .
Var R 21 etj R 2
Var(et)R2 R2RR2
1k
H0 H0
Si l'on considère Vechu R 2 e e
1
1
tt
2 on remarque que
- -
EH0 [VechuR 2etetR
2 VechuEH0 2etetR
2 Vechu (1k) (c)~ ~ ~ (c)~ ~
Soit le processus centré{ Yt,
te `~ . En supposant une dynamique linéaire de la forme du
processus suivant :
Yt a1k +
fi1Yt~~1+ ...+ fi
sYt~~s + ri t,t
s +1,..., T
Où (rit )test
processus centré i.i.d du second ordre de variance
a2 . Engle et Sheppard proposent pour le test de :
H0: "a 0, et fii
0; V i 1,p" Contre H1 :a # 0
3ie 1,s tq fii #0
Yt est de dimension k(k -1)
2 .
Y1 a + fi1Ys+ ...+ fi sY1+ri1
Ys+2 a + fi1Ys+1+ ...+ fi)72 +ri s+2
.
YT a + fiYT-1
·
·
·vT--s+ + fi + riT
L'écriture matricielle est de la forme suivante :
1Ys . . . Y1
1 . . .
Y Y
s + 1 2
. . .
. . .
. . .
1 . . .
Y Y
T - 1 T s
-
?
?
?
?
Y = ?
?
?
?
?
?
?
?
?
? ? ?
+ = X
?
?
?
?


8 ij
+
? = X X X Y Avec ( $ ) 1
$ ( )
' ' EH 0 ? = 0 s + et $ ( )
Var ? = X X a
' 2
Ceci est justifié asymptotiquement (Hamilton (1994) P.2
15)
On estime 2
cr par :
1 T
= ?T S
t s
= +
s
Y Y
t k j t j
- I - ?
a J3 -
j = 1
? u 2
1
2
-
La statistique de test est la suivante. Il s'agit du tester de
Wald adapté à ce problème (Hamilton 1990)
|
$ $
' '
? XX ?
? u 2
|
Où ( )'
? = a , J3 1 , J3
2 , ..., J3 s Elle suit asymptotiquement
une loi du Khi Deux à (s+1)
|
degré de liberté.
La règle de décision est la suivante :
|
' '
? ? ?
$ $
XX ? s
Si 2 1
> +
2 ( )
? u
|
on rejette l'hypothèse nulle (H0).
|
Sinon H0 est acceptée.
V. Modèle DCC (Dynamic Conditional
Correlation)
Une approche récente pour modéliser à la
fois les variances et les corrélations conditionnelles de plusieurs
séries est la méthode DCC (Dynamic Conditional Correlation)
proposée par Engle (2002) et Tse et Tsui (2002). S'inspirant du
modèle CCC, la démarche de l'estimation comporte 2 étapes.
En premier, la variance conditionnelle de chaque variable du système est
estimée à partir d'un processus de type ARCH ou GARCH
univarié quelconque. A ce point, il est possible de choisir un
modèle non linéaire pour prendre en compte le mécanisme
asymétrique des chocs sur la volatilité si le
phénomène est significativement présent dans la
série. Par la suite, les résidus standardisés des
régressions effectuées à la première étape
sont utilisés pour modéliser les corrélations de
façon autorégressive, obtenant ainsi la matrice des
corrélations conditionnelles qui varie dans le temps. La matrice des
variances-covariances
conditionnelles est le produit de la matrice diagonale des
écart-types conditionnels par la matrice des corrélations
conditionnelles et par la matrice diagonale des écart-types
conditionnels.
Le modèle DCC proposé par Engle (2002)
s'écrit de la manière suivante :
~°~®~ °~~
Ht DtRtDt
D diag
t
( h1 1t ,
h22,...,hNNt )

Où R t est la matrice de
corrélation conditionnelle qui peut être obtenue par
l'équation :
Et-(CtC;) Di
1HtDt-1 Rt Car
Ct Di 1r
On modélise Rt de la manière
suivante :
Qt (1- a - /3 )Q
+ a (CtC;)#177; /3 Qt-1
-Rt (diagQt) 1/ 2
Qt (diag Qt )-1/2
Qt c'est la matrice de variances-covariances
conditionnelles des résidus standardisées. Où Q
est la matrice de variances-covariances inconditionnelle de
dimension(Nx N),
\'
symétrique et définie positive alors que
Et=(å1t,å2t ,...,åNt est un vecteur colonne des

résidus standardisés des N actifs du portefeuille
à la date t, ri i t C t
Où rit hitCit V i 1,2
avec{ Cit , te cents`~ iid, de (V. 1) on obtient
:
pour i=1,...,N
h iit
P12Et-1( kt
h2t CuCu)Et-1
(C1tC2t
h1th2
les coefficients a et /3 sont des
paramètres à estimer. La somme de ces coefficients doit
être inférieure à 1 pour respecter la positivité de
la matrice Qt.
Corrélation conditionnelle.
Soient deux variables aléatoires
r1t et r2t
centrées
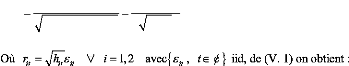
(rtr2t)E (r r
)
2t
(V. 1) Car Et-1(rit) hit
P
Et-1
12,t 2 2
E1 fritgt-1(r2t)
t-
t
h1th2
Alors on a :
Ainsi on peut dire que la corrélation conditionnelle entre
les variables est aussi la covariance entre les résidus
standardisés.
Rt( Q t ) Q
t ( Q t ) où Q t * diag
Q t
* 1/ 2 * 1/ 2
- -
= { } { }
=
V.1 Estimation des paramètres
Pour estimer les paramètres ( )'
? = a 0 ,a1 ,
...,a p ,ii 1 ,..., ii
q nous devons passer par une estimation du maximum de
vraisemblance logarithmique. En supposant que les résidus sont gaussiens
centrés, la fonction de vraisemblance s'écrit :
l
T
( ) ( ) / 2 1/ 2 ' 1
? n ? ? ?
1
? ? r g
, / 2 exp
= ?
-
? ? - ?
- H - r H r
t t t t t ?
2
t = 1 ? ? ? ?
Où rt désigne l'actif
Car ? r t / t - 1 ? N n ? 0
n , H t ?
? ? ? ?
? ?
Ainsi on aura la fonction de vraisemblance logarithmique :
( T ? ?
n / 2 1/ 2 ' 1
? ? ?
1
- -
log , / log 2 exp
l ( ) ( )
0 ? & g
= i -
t ? ? ? ?
H r H r

-
fl t t t t ?
? ?
2
t = 1 ? ? ? ?
= -
T
1 ?
2
1
t =
( )
n H r H r
' 1
-
log 2 log
g + +
t t t t
On sait que H t = D t R t D
t et 1
s t D t - r t
= , en remplaçant Ht par l'expression
D t R t D t on aura :
T

( ) ( )
1 ' 1 1 1
- - -
log , / log 2 log
l n D R D r D R D r
0 çb e g
= - + +
?
t = 1
t t t t t t t t t
2
= -
T
1 ?
2
1
=
t
( )
n D R R
g e e
' 1
-
log 2 2log log
+ + +
t t t t t
T
Avec cette fonction log-vraisemblance il est très
difficile d'estimer les paramètres pour des matrices de grandes tailles.
Alors Engle (2002) propose une estimation en deux étapes permettant une
estimation consistante des paramètres.
Soit ( ) (
1
L l O çb c n g D r D r c c R ? R ?
= = - ? + + - + +
' 2 ' ' 1
-
log , / log 2 2log log
- )
t t t t t t t t t t t
t=1
2
Donc Engle propose de diviser l'estimation en deux étapes
: une partie dépend des paramètres
de la volatilité et la seconde partie dépend
à la fois des paramètres des corrélations conditionnelles
et des paramètres de la volatilité.
Ainsi la fonction log-vraisemblance s'écrit :
L ? ? ? = l ? ? ? t = L v ? ? t +
L c ? ? ? t
( , / t ) log ( , / ) ( / ) ( , / )
T
comprend les paramètres de la
Avec ( ) ( )
L O e n ,r D r D - r
1 ' 2
/ log 2 2log
= - ? + +
v t t t t t
t = 1
2
volatilité( Dt ) .
T
Et ( ) ( )
1
L O çb e R e e e R e
' ' 1
comprend les paramètres de la corrélation
-
, / log
= - - +
c t t t t t t t
2 t = 1
conditionnelle( Rt ) .
Pour déterminer O $ et ? $ on cherche
à maximiser la fonction log-vraisemblance ce qui revient
à max { L v ( / t ) }
O O e et max { L c ( u , /
t ) }
? O 7 e
Etape 1 :
Dans cette première étape d'estimation, un
modèle GARCH (p, q) univarié est appliqué aux
variances conditionnelles de chaque actif. A l'issue de celle-ci,
les coefficients qui expliquent la volatilité de chaque actif pris
individuellement sont obtenus en résolvant le
problème max{L v ( / t ) }
O O e . Pour la résolution
voir chapitre 4.
Etape 2 :
Dans cette seconde phase d'estimation, les coefficients des
volatilités obtenus lors de la
première étape, O $ sont maintenant
supposés connus et servent à conditionner la fonction de
vraisemblance utilisée pour estimer les paramètres q$ de
la dynamique de corrélation.
Cette procédure réduit grandement le temps de
calcul mais au prix d'une perte d'efficacité dans la mesure où ce
n'est qu'une partie de la vraisemblance, celle des corrélations qui est
maximisée lors de la seconde étape.
max { L c ( u , / t ) }
? O e
IV.2 Estimation de la corrélation
conditionnelle
Dans la deuxième étape d'estimation, les
paramètres de la corrélation dynamique sont obtenus par diverses
méthodes.
Méthode 1 (le lissage exponentiel)
T
t s
-
. e e
s
1, 2,
t s -
?
? u
1,2
s = 1
t T T
? ?? ?
s s
2 2
? ?? ?
? ?
? e ? e
1,
2,
t s t s
- -
? ?? ?
s s
= =
1 1
C'est-à-dire
.
u ( )( ) ( )
= = - ? ? - ? - + ? -
q où q
1,2,
? t , 1
1,2 , , , 1 , 1 , , 1
q
t i j t i t j t i j t
q q
1,1, 2,2,
t t
L'estimateur obtenu est appelé DCC LL INT a +
fi =1. Méthode 2 (le Mean Reverting)
.
u ( ) ( ) ( )
q où q
1,2,
? = = ? - a - fi + a ?
- ? - + fi -
t , 1
1,2 , , , , 1 , 1 , , 1
q
t i j t i j i t j t i j t
q q
1,1, 2,2,
t t
Où ? i , j est la corrélation
inconditionnelle
Dans cette partie on estime les paramètres des
corrélations, L'estimateur obtenu est appelé DCC LL MR si et
seulementa +fi <1.
On retrouve l'estimateur DCC LL INT lorsque a + fi
=1.
Modèle de corrélation simple
Les modèles de corrélation simple d'Engle
s'écrit sous la forme :
Q t t t
t = ( 1 - )( ? - 1 ? ' - 1 )+
 - 1
Q pour DCC LL INT
Q R t t t
t = ( 1 - a - fi ) + a (
? - 1 ? ' - 1 ) + fi - 1
Q pour DCC LL MR
R est la matrice de corrélation inconditionnelle
Donc la matrice est obtenue par
- 1 / 2
R t =
( ) ( )
d i a g Q t Q t d i a g Q t
1 / 2 -
V.2 Propriétés asymptotiques de la
méthode du PMV
Sous des conditions de régularité
supplémentaires portant notamment sur les variances conditionnelles du
score et sur la stationnarité du processus observé, on peut alors
établir que l'estimateur du pseudo-maximum de vraisemblance est
asymptotiquement convergent et asymptotiquement normal :
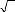
T ? t ? N I - JI -
( u ) ( 1 1 )
- ??>
d 0,
( ? ?
2 lo g ( l t ( )
9 0
Où I E O
= ? ?
0 ? ? ? ?
'
? ?
? ? a ?
log( l t ( ) log( l
t ( )
O O
= ? ?
0 0
J EO
0 ? ? ?
O O '
V. Approche théorique de la gestion de
portefeuille : Introduction
Au cours des dix dernières années, on a
assisté à un renversement des perspectives au niveau de la
gestion de portefeuille. Au lieu de considérer le portefeuille comme
étant une somme d'éléments, c'est le portefeuille
lui-même qui est devenu l'élément de base, les inter
relations entre ces composantes prenant autant d'importance que la
qualité intrinsèque de chacune d'entre elles.
La théorie moderne de portefeuille a été la
base de ce renversement.
Forgée au début des années cinquante par
Harry Markowitz, elle sera reprise, développée et surtout
conduite jusqu'à son application pratique par W. Sharpe et par d'autres
dans la fin des années soixante. C'est pour la première fois que
Markowitz et ses successeurs s'attaquaient à une rationalisation
complète de tous les problèmes de gestion de portefeuille et
construisaient une théorie globale où rien apparemment
n'était laissé dans l'ombre.
Dans cette partie, on va introduire la théorie de gestion
quantitative de portefeuille, en commençant par la théorie de
Markowitz qui est la théorie fondatrice de ce domaine, en suite on
introduit le concept de corrélation qui est sûrement l'un des
outils les plus importants dans la gestion de portefeuille, d'où
l'intérêt majeur d'estimation des matrices variance-covariance
à partir des modèles GARCH-DCC au lieu des matrices de variance
covariance empiriques.
V.1 Théorie de Markovwitz
La gestion de portefeuille est née en 1952 à la
suite d'un article de H.Markowitz. Il s'agit d'une discipline appartenant
à la finance quantitative.
La théorie de Markowitz propose de maximiser la
performance du rendement global d'un portefeuille en minimisant son risque.
Comme mesure de performance et de risque cette théorie
utilise l'espérance et la variance du portefeuille calculées
à partir des espérances et variances des actifs composants
celui-ci, supposées connues.
Pour chaque actif i=1 ,. . . ,n, ì désigne
l'espérance de gain, ó la variance. Pour deux actifs ñ
est
2
i i ij
le coefficient de corrélation.
Si nous représentons par Xi la
proportion du capital investi sur l'actif i, l'espérance et la
variance du portefeuille X= (X1, ,Xn
) sont données par :
( )
X
= ?
n x x
t
=
i i
i_L i_L
E
i ? 1
|
Var ( )
X
|
n
?=
|
t
? ? ? =
i j i j i j
x x x Q x
|
|
i
|
?
|
1
|
? = Q = p a a pour i ~ j et Q ii
= ? i
2
Où ii 1, ij ij i j
Pour l'investisseur désirant prendre le moins de risque
possible, l'objectif est donc de minimiser la variance du portefeuille.
D'autre part, de manière à garantir un rendement
minimum b (choisi par l'investisseur), la contrainte suivante doit être
tenue en compte : ~
ì Xb.De plus, étant donné que
Xi
t
représente un pourcentage du capital on a : t
e X=1 (où e est le vecteur unité).
Le problème d'optimisation auquel est confronté
l'investisseur est donc :
|
( )
M A R K O W IT Z
|
Min X Q X
t
|
1
? =
e t X
?
?
? ~
X 0
?
u X b
t>
V.2 Définition d'un portefeuille
C'est la combinaison d'un ensemble de titres possédant des
caractéristiques différentes en matière de valeur et de
perception de dividendes. Cette combinaison se fait en des proportions
différentes afin d'avoir un portefeuille bien diversifié
permettant de réaliser un rendement espéré bien
déterminé tout en minimisant le risque que peut courir
l'investisseur.
Mathématiquement un portefeuille P est un vecteur de
proportions Xi relatives chacune à la proportion du capital investi dans
chaque titre.
? ?
X1
? ?
? ?
.
? ?
.
P = X
? ?
? ?
i
? ?
.
? ?
? ?
? ?
Xn
Avec i part du capital investi dans l'actif i X
=
capital total
Rendements d'un titre :
Le taux de rendement d'une action est la mesure de la
rentabilité qu'elle a procurée au cours d'une période
donnée. Formellement le rendement d'une action se calcule comme suit
:
Soit Pt , le prix d'un actif à la date
t et Rt le logarithme du rendement correspondant : RP
P
t t t
= log - log -1
log ( )
Où Dt
p p
t - t
-1
1 + D t
p t
= désigne la variation de prix.
-1
Rendements d'un portefeuille : n
R = X R
p t t
?
t=1
C'est la moyenne des rendements des titres constituant le
portefeuille pondérés par leurs proportions dans le
portefeuille.
On peut également calculer le rendement d'un portefeuille
en se basant sur sa valeur. Le calcul se fait de la manière suivante
:
V - V
t t-1
R =
p V
t-1
Avec Vt : valeur du portefeuille à la date t
Vt-1 : valeur du portefeuille à la date t-1
Risque d'un portefeuille et attitude de l'investisseur
:
1. Mesure de risque :
Les taux de rendements successifs d'une action ou d'un
portefeuille peuvent avoir d'importantes fluctuations autour de leur valeur
moyenne.
Pour mesurer ce risque, dont l'origine revient à ces
fluctuations, on a recours à l'écart type ou la variance des
rendements par période.
La variance de l'action sur T périodes est :
1
ó = T
i
T
? ? )
R - R
i,t i
t=1
2
Avec Ri,t : le taux rendement de l'action i au cours de la
période t. Ri :la moyenne arithmétique des taux de rendement.
Si, par ailleurs, on veut connaître le lien qui existe
entre les fluctuations des taux de rendement de deux actions i et j il faut
recourir à la covariance.
n n
?? ( ) ( )
i=1 j=1
R - R R - R
i,t i j,t j
L'interprétation de la covariance est liée à
son signe. En effet si la covariance est positive alors on peut dire que les
taux de rendement des actions i et j évoluent dans le même sens et
si la covariance est négative alors les deux taux évoluent dans
deux sens contraires. Enfin si la covariance est nulle alors on conclura qu'il
n'y a aucune relation entre les évolutions des rendements deux titres.
On pourrait aussi définir un troisième concept qui est le
coefficient de corrélation qui s'obtient en rapportant la covariance au
produit des écarts type des taux de rendement des titres i et j.
= ó , C e coefficien t est com pris entre -1 et 1 .
ij
ñ ij i j
óó
Si le coefficient de corrélation est positif alors les
taux de rendements des actifs i et j ont
tendance à évoluer
dans le même sens et plus ñij se rapproche de
1 plus les variations de
deux variables deviennent proportionnelles. Et si
ñij est négatif alors les deux variables
ont
tendance à varier dans un sens opposé. Plus ce
coefficient se rapproche de -1 plus leurs variations en valeur absolue
deviennent proportionnelles. En fin, une corrélation nulle indique qu'il
n'y a pas de relation entre les taux de rendements des titres
considérés.
2. Risque d'un portefeuille :
Nous avons présenté la technique utilisée
pour la mesure du risque d'un titre. Dans cette partie on va
s'intéresser au risque total du portefeuille. Pour un portefeuille qui
se compose
de N titres, son taux de rendement dépendra à la
fois des taux rendements des différents titres et aussi de leurs
différentes proportions.
N
i= 1
N
Donc : ?
E(Rp) = X E(R )
i i
i=1
Et :
ó 2 2 2 2 2
p 1 1 1 2 1,2 1 N 1,N 2 2 2 1 2,1
= X ó +X X ó +....+X X ó +X ó +X
X ó +.... ...+X ó +X X ó +X X ó +....
2 2
N N N 2 N,2 N 1 N,1
NN
On peut aussi obtenir :
ó = X X ñ ó ó
2
p i j
?? i j i j
i=1 j=1
Cette dernière expression de la variance renseigne sur le
lien étroit entre le risque du portefeuille et la corrélation
existant entre les rendements des titres le constituant. Par ailleurs on peut
définir un autre concept qui est la contribution d'un titre au risque du
portefeuille. En effet la variance peut s'écrire :
? ? ? ?
2 2 2 2
2 2 2
ó =X X ó ... X ó ... X ó ... X X
ó ... X ó ... X ó ..
? ? ? ? ? ? ? ? ? ? ?
p i N i i i
1 1 1 1,i 1,N 1 i,1 N i,N
( )
X ó ... X ó ... X ó
2 2 2
1 N,1 N,i N N
+ + + +
i
.. . X + N
La contribution du titre i dans le risque est alors :
X i X 1 ó i,1 ... X
i ó i ... X N ó
i,N C'est la contribution absolue, elle dépend de
trois
( + + + + )
2 2 2
facteurs :
V' La variance de son rendement
V' La covariance du titre avec les autres titres
V' La proportion du titre dans le portefeuille
3. Corrélation et diversification :
La corrélation est sûrement l'un des outils les plus
importants utilisé dans la gestion de portefeuille, car elle sert
à déterminer si les rendements de différents placements
dans un portefeuille réagissent de façon identique ou
opposée en fonction des conditions économiques.
En statistiques, le degré de corrélation est le
degré d'association entre 2 variables aléatoires.
Mathématiquement et aussi en finances, la corrélation est
exprimée par un coefficient de corrélation qui varie entre -1
(pas de corrélation) en passant par 0 (tout à fait
indépendant) et +1(corrélation maximale). Cependant, il est
important de ne pas confondre corrélation avec causalité.
Depuis l'avènement de la théorie de la gestion
moderne du portefeuille, il y a 50 ans, la règle d'or dans la
constitution d'un portefeuille consiste à combiner diverses
catégories d'actif qui affichent la plus faible corrélation
possible entre elles. Bien que cette règle soit valide a priori, on a eu
tendance à oublier qu'une forte corrélation des rendements entre
les divers actifs n'équivaut pas nécessairement à des
rendements similaires.
Un peu de technique
L'analyse de corrélation consiste à mesurer
l'interrelation entre deux variables; le résultat de cette mesure
s'appelle «le coefficient de corrélation». La mesure d'un
coefficient de corrélation peut varier entre +1 et -1. Un coefficient de
+1 représente une corrélation positive parfaite, alors qu'un
coefficient de -1 représente une corrélation négative
parfaite, ce qui signifie de façon générale que les deux
variables (ex : rendement de deux placements) réagiront de façon
opposée face à un même événement.
Il existe une règle générale pour
évaluer le coefficient de corrélation de différents actifs
ou placements :
Corrélation élevée
Plus de 0.75; cette mesure implique que les deux actifs
réagissent de façon très similaire aux conditions du
marché et que leurs rendements iront généralement dans la
même direction. Corrélation
modérée
Entre 0.25 et 0.75; implique que les deux actifs répondent
de façon assez similaire aux conditions du marché, mais que leurs
rendements pourront évoluer plus ou moins dans la même
direction.
Corrélation basse
Entre 0.00 et 0.25; les deux actifs réagissent
différemment aux conditions du marché et leurs rendements ont
tendance à demeurer indépendants l'un de l'autre.
Corrélation négative
Moins de 0.00; les actifs réagissent différemment
aux conditions du marché et leurs rendements évoluent en
direction opposée.
Diversification du risque
Afin de réduire le risque total d'un portefeuille, il
est préférable de combiner des actifs présentant une
corrélation négative ou légèrement positive. Une
combinaison d'actifs entretenant une corrélation négative
parfaite permet en effet d'éliminer la variabilité du rendement
du portefeuille, c'est-à-dire son risque.

Corrélation entre les séries M, N et P. Les
séries présentant une corrélation positive parfaite, M et
P, sur le graphique de gauche varient dans le même sens. En revanche, les
séries présentant une corrélation négative
parfaite, M et N sur le graphique de droite, varient en sens
diamétralement opposé.
Combiner des actifs corrélés négativement
afin de diversifier les risques. Le risque lié à la
variabilité des rendements résultant de la combinaison d'actifs
corrélés négativement, F et G, dotés du même
rendement espéré, r, donnent un portefeuille (graphique de
droite) et ayant le même rendement espéré mais avec un
facteur de risque moindre.
Certains actifs ne sont pas corrélés : ils ne
présentent aucune liaison et leurs rendements respectifs sont totalement
indépendants. La combinaison d'actifs non corrélait permet
également de réduire le risque (certes, cette méthode
n'est pas aussi efficace que la combinaison d'actifs corrélés
négativement, mais elle est toujours plus que la combinaison d'actifs
corrélés positivement dans la parenthèse. Les actifs non
corrélés présentent un coefficient de corrélation
égale à 0, point médian entre une corrélation
positive parfaite et une corrélation négative parfaite.
Conclusion :
Donc, lors du choix du portefeuille, l'investisseur doit prendre
en compte ces trois facteurs pour bien gérer son risque. Dans notre
mémoire les deux premiers facteurs ont été pris en compte
dans un contexte des modèles GARCH multivariés, plus
précisément le modèle GARCH-DCC qui prend en
considération l'interdépendance entre les actifs, cela en
permettant à la matrice de corrélation d'être dynamique
dans le temps. Donc à chaque fois on peut refaire l'optimisation pour
obtenir une meilleure diversification.
Application de la méthode
multivariée
Le but de cette application est d'estimer deux types de
modèles GARCH multivariés: CCC (Constant Conditional
Correlation) et DCC (Dynamic Conditional
Correlation). Les données journalières utilisées
sont les indices de prix : QQQQ, SPY, GLD, IEV et l'indice ajouté dans
cette partie OIH.
L'analyse des données journalières couvre la
période de 03 janvier 2005 au 30 novembre 2007, ce qui nous donne 780
observations par marché. Ces indices sont pris en dollar
américain. Ils ont été extraits de la base de
données Yahoo finance.
L'échantillon est constitué de 5 marchés
dont 2 américains (QQQQ et SPY), 2 internationaux (GLD et OIH) et le
dernier IEV qui représente le marché européen.
Statistique descriptive
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
|
Moyenne
|
0.000773
|
0.00117
|
0.000335
|
0.00065
|
0.000357
|
|
Minimum
|
0.06100
|
0.054100
|
0.031500
|
0.041200
|
0.040400
|
|
Maximum
|
-0.070900
|
-0.063800
|
-0.039900
|
-0.055500
|
-0.041800
|
|
Ecart-type
|
0.011791
|
0.018721
|
0.007623
|
0.009881
|
0.009908
|
|
Skewness
|
-0.661455
|
-0.263921
|
-0.418388
|
-0.290512
|
-0.109315
|
|
Kurtosis
|
6.2451
|
3.075056
|
5.537491
|
5.687913
|
4.004332
|
Le tableau ci-dessus affiche un ensemble de statistiques
descriptives des variables de nos séries. Les distributions des cinq
actifs sont significativement différentes de la distribution normale au
seuil de 5%. Ces séries sont caractérisées par des
coefficients d'aplatissement suffisamment supérieurs à celui de
la loi normale. Elles présentent également des coefficients
d'asymétrie différents de celui d'une distribution normale.
La négativité des coefficients d'asymétrie
pour les séries indique que ces branches d'activités ont subi
plus de chocs négatifs que de chocs positifs durant la période
analysée. Les spécifications GARCH adoptées sont
susceptibles d'expliquer une part significative de la non-normalité de
ces séries. En effet, l'application du test Jarque-Bera aux
séries de rendements révèle la non-normalité des
séries qui s'explique par la présence des effets GARCH.
Analyse graphique
Le graphe précèdent représente
l'évolution des prix des actifs, sur le marché boursier. Un
examen minutieux des changements à court terme (une semaine) fait
apparaître de nombreux pics compensés souvent par des creux, plus
précisément des variations traduisant la forte volatilité
des prix boursiers.
Traitement logarithmique
Quand il s'agit des prix, la transformation des données
par l'introduction des rendements logarithmiques est très
fréquente ; en particulier, elle est utilisée lorsqu'on constate
que la série chronologique a une forte variabilité
instantanée ou si elle est affectée d'une tendance. En plus du
fait que les rendements sont généralement stationnaires, une
propriété que ne possède pas les séries prix.
Estimation du modèle CCC
La méthodologie du modèle CCC de Bollerslev (1990)
qui est le précurseur du DCC de Engel (2002) consiste à estimer
en premier :
- la variance conditionnelle de chaque actif avec un
modèle de type GARCH. Une matrice diagonale contenant ces variances
conditionnelles est construite, la racine carrée de cette matrice donne
une matrice diagonale des écart-types conditionnels
Dt des actifs étudiés.
Le calcul de la matrice de variances covariances conditionnelles
Ht est obtenue par le produit de trois matrices : la
matrice diagonale des écart-types conditionnels Dt ,
la matrice R de corrélation entre les variables et la matrice diagonale
des écart-types conditionnels Dt .
Le modèle s'écrit de la manière suivante
:
IL
HD RD
t t t
=
Ddiag= t
R p
= ij
, 1
avec ? ?
ii
( 11 , 22 ,..., )
h h h
t t NNt
Estimation
Pour des raisons de parcimonie et de simplicité, le
modèle GARCH (1,1) de Bollerslev est une réponse sur-mesure,
puisqu'il est équivalent à un modèle ARCH d'ordre infini.
En effet ce dernier intègre toute l'information avec moins de
paramètres à estimer.
La première étape de la procédure
utilisée dans Engle (2002) renvoie à l'estimation d'un GARCH pour
chacune des séries.
Afin d'obtenir les paramètres p et q des GARCH
univariés, on a utilisé l'approche Box-Jenkings (1976) qu'on a
appliqué à chacune des 5 séries:
· Auto corrélation des rendements
· Test de Engle pour la présence des ARCH
· Estimation du GARCH (p, q) et le test de Ljung-Box
Le choix des paramètres p et q d'une série
donnée est obtenu en prenant le modèle qui a le critère
d'information bayésien (BIC) le plus petit.
En utilisant la procédure Ccc-Mvgarch10, on
estime des GARCH univariés pour chacune des séries de rendements.
Les résultats obtenus sont les suivants :
10Programme MATLAB disponible sur le site de
http://www.kevinsheppard.com/research/MatlabAtlas/MatlabAtlas.htm
Estimation des paramètres des modèles
GARCH (1,1)
Le tableau ci-dessous résume les paramètres du
modèle GARCH de chaque série.
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
Alpha 0
|
1,92E-06
|
2,53E-05
|
3,42E-06
|
1,25E-05
|
1,10E-05
|
Alpha 1
|
0,060912
|
0,04371
|
0,092956
|
0,16105
|
0,094017
|
Béta 1
|
0,92886
|
0,8858 1
|
0,85236
|
0,72462
|
0,79884
|
|
Matrice de corrélation R
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
GLD
|
1
|
0,3558
|
0,1903
|
0,4017
|
0,1261
|
OIH
|
|
1
|
0,5 135
|
0,485 1
|
0,3849
|
SPY
|
|
|
1
|
0,8117
|
0,8489
|
IEV
|
|
|
|
1
|
0,6725
|
QQQQ
|
|
|
|
|
1
|
|
Le tableau 2 ci-dessus présente les coefficients de
corrélation entre les rendements des indices boursiers des
sociétés américaines (SPY), les sociétés
technologiques américaines (QQQQ), les sociétés
européennes (IEV), l'indice de l'or (GLD) et celui du pétrole
(OIH). Ce tableau, montre que:
· Les sociétés américaines et les
sociétés technologiques américaines (SPY, QQQQ) sont
fortement corrélées. La corrélation est de 84,89% ce qui
implique que les deux actifs réagissent de façon très
similaires aux conditions des marchés et que leurs rendements iront dans
la même direction. Cette corrélation s'explique par le fait que
des perspectives économiques favorables (respectivement
défavorables) pour les grandes sociétés américaines
sont également favorables (respectivement défavorables) pour les
sociétés américaines de technologie (QQQQ). Les plus gros
clients des sociétés américaines de technologie sont les
sociétés américaines traditionnelles (SPY), viennent
ensuite les sociétés européennes qui sont elles aussi
dépendante de la technologie américaine mais dans une moindre
mesure (67,25 %). Les sociétés américaines traditionnelles
(SPY) sont très fortement corrélées (81,17 %) aux
sociétés européennes (IEV). Ce traduit une forte
intégration de ces deux grandes économies qui sont les plus
puissantes à l'heure actuelle.
· Les coefficients de corrélation entre les
rendements de l'indice du pétrole (OIH) avec les valeurs des
sociétés américaines (QQQQ et SPY) et européennes
(IEV) sont moyens, autour de 50%. La corrélation avec les
sociétés américaines (SPY) et européennes (IEV) est
de 51,53 % et 48,51 % respectivement. Cela montre une dépendance de ces
sociétés au pétrole dans la mesure où une
augmentation de leur valeur (perspective d'augmentation de l'activité)
fait
monter le prix du pétrole. Les sociétés
technologiques (QQQQ) dépendent moins du pétrole puisqu'elles
sont fondées sur l'innovation et moins sur les grandes infrastructures
de fabrication consommatrice d'énergie comme les usines ce qui explique
une corrélation plus faible de 38,49 %.
s Les coefficients de corrélation entre l'indice de l'or
(GLD) et les sociétés américaines (SPY, QQQQ) sont faibles
et parfois moyen avec IEV et OIH. Cela s'explique par le fait qu'en
période de crise boursière l'or, qui est considéré
comme une valeur sûre (refuge), monte de manière importante. Dans
une période de crise persistante, les valeurs qui montent ensuite sont
les matières premières, comme le pétrole, suivi des
valeurs des sociétés européennes. Cela explique une
corrélation de 3 5,58% entre GLD et OIH et de 40,17% entre GLD et IEV.
Ces dernières sont recherchées comme alternatives aux
sociétés américaines. Cependant, le coefficient de
corrélation le plus faible est de 12,6 1% entre GLD et QQQQ et 19,03 %
entre GLD et SPY. Cela traduit la politique de la réserve
fédérale américaine qui a décidé de
dépareiller sa monnaie de la valeur de l'or dans les années 80
pour démontrer la force de son économie. Cette faible
corrélation démontre que l'économie américaine est
suffisamment forte pour ne pas dépendre de la valeur de l'or.
Matrice de variance covariance à l'instant t =1
:
GLD
GLD 0,1043
?
OIH
?
?
SPY
?
IEV
QQQQ ?
OIH
0,0733
0,4067
|
SPY 0,0184 0,0983 0,0901
|
IEV 0,0696 0,0166 0,1308 0,288
|
QQQQ 0,0184 0,1108 0,115 0,1629 0,2037
|
?
?
?
? ?
?
?
?
?
|
? 4
10
|
Matrice de variance covariance à l'instant t = 780
:
GLD OIH SPY IEV QQQQ
GLD 0,1826 0,0883 0,0238 0,05 0,0177
?
OIH 0,337 0,0871 0,082 0,0735
?
?
SPY0,0853 0,069 0,08 16
?
IEV0,0848 0,0644 QQQQ ? 0,1083
On remarque de ces deux tableaux précédents que la
matrice de variance covariance varie au cours du temps, cela est dû
certainement aux fortes fluctuations de la volatilité de chaque indice,
car la matrice de corrélation est supposée constante dans le
modèle CCC.
Prévision de la matrice variance covariance
à l'instant t = 781 :


On sait que H t = D t RD
t , alors u u u
H t + 1 = D t + 1 R D t + 1 ,
où u $ $ $
D t + 1 = diag ( h 11t+1,
h 22t+1 ,..., h 55t+1),
donc pour faire la prévision de la matrice variance
covariance, il suffit seulement de prévoir la matrice de variances
conditionnelles, d'où :
0 ?
?
0
?
?
0
?
0
?
?
0.0105 ?
D u781
|
? 0.0132
?
0
?
= 0
?
? 0
?
? 0
|
0
0.0182
0
0
0
|
0
0
0.0090
0
0
|
0
0
0
0.0099
0
|
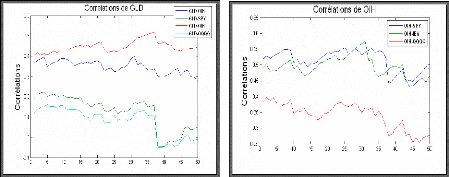
Donc on obtient la matrice variance covariance suivante
:
GLD OIH SPY IEV QQQQ
GLD 0,1741 0,0856 0,0226 0,0526 0,0175
?
OIH 0,3326 0,0844 0,0878 0,0737
?
?
SPY0,0812 0,0726 0,0803
?
IEV0,0985 0,0701 QQQQ ? 0,1103
Test de constance de corrélation
Analyse graphique :
Les graphes ci-dessous affichent les niveaux des
corrélations conditionnelles dynamiques estimés selon l'approche
de Engle (2002). A l'observation de l'évolution de ces
corrélations, il semble que ces dernières affichent des tendances
variées qui laissent présager que les interprétations
basées sur l'hypothèse de constance des corrélations
seraient erronées.
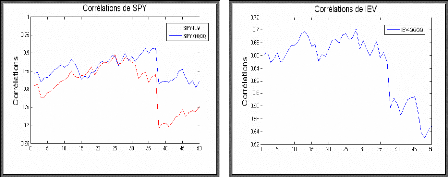
Mise en oeuvre du test :
Divers tests statistiques furent développés pour
tester l'hypothèse de constance des corrélations entre une
structure dynamique de celles-ci. Le test proposé par Engle et Sheppard
(2001) est implémenté dans cette analyse. Sous l'hypothèse
nulle, ce test suit asymptotiquement une distribution Khi deux à (p+1)
degrés de liberté.
Les hypothèses du test sont les suivantes :
p
H0 :R t
=R,VtE T Contre 1 ( ) ( ) ( )
H Vech R Vech R Vech R
u u
: J3 ?
u
= +?
t i t i
i= 1
On effectue le test de Engle et Sheppard (2001) sur les 5
séries, en gardant la même hypothèse de départ
concernant la structure de la variance, c'est-à-dire qu'elle suit un
processus GARCH (1,1).
Aussi on teste la présence d'autocorrélation dans
la matrice de corrélation avec un retard. Le tableau suivant
présente les résultats du test.
Test de Engle et Sheppard
(2001)
|
Echantillon
|
P Value
|
|
T statistic
|
|
0.055
|
|
13.76
|
Les conclusions du tableau ci-dessus sont claires, on rejette
l'hypothèse que la corrélation est constante dans
l'échantillon. La modélisation DCC semblerait plus
appropriée afin de capturer l'évolution dynamique de la matrice
de corrélation.
Estimation du modèle DCC
Comme on l'a signalé dans le chapitre 5, l'estimation des
paramètres se fait en deux étapes, la première concerne la
partie de volatilité O, la seconde étape pour la partie
corrélation dynamique.
Dans la première étape d'estimation, un
modèle GARCH (1,1) est appliqué aux variances conditionnelles de
chaque actif. A l'issu de celle-ci les coefficients qui expliquent la
volatilité pour les 5 séries prisent individuellement sont
affichés sur le tableau suivant :
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
|
Alpha 0
|
1,92E-06
|
2,53E-05
|
3,42E-06
|
1,25E-05
|
1,10E-05
|
|
Alpha 1
|
0,060912
|
0,04371
|
0,092956
|
0,16105
|
0,094017
|
|
Bêta 1
|
0,92886
|
0,88581
|
0,85236
|
0,72462
|
0,79884
|
Ces paramètres sont estimés à l'aide de la
fonction Dcc-Mvgarch11.
Interprétation
Sur les marchés boursiers, il existe, en
général, une persistance (á + â) proche de
l'unité, malgré la contrainte (á + â) < 1
imposée. Ceci étant, la série qui a une volatilité
plus sensible aux innovations que les autres (á élevé) est
IEV avec une valeur égale à 0,16. Inversement, OIH a une
volatilité qui semble moins affectée par les chocs. Les autres
séries (GLD, SPY et QQQQ) ont une sensibilité aux chocs oscillant
entre [0,06 0,095].
En ce qui concerne les effets autorégressifs de ces
volatilités, on remarque qu'il est dans l'ensemble supérieur
à 0,80, sauf pour IEV où il n'est que de 0,72; et
inférieur à 0,96. La série GLD a le coefficient
autorégressif le plus élevé (0,9288) ce qui explique la
forte variation des rendements.
Remarque
Les paramètres obtenus par la fonction Dcc-MVGARCH sont
identiques à ceux obtenus par la modélisation des séries
de rendements.
Pour estimer la matrice de corrélation temporelle DCC, on
commence par calculer la matrice de variance covariance conditionnelle
Qt des résidus standardisés qui
s'écrit de la forme
suivante :
Q = -- a - /3 Q + a e t
e t + /3 Q t ?
t 1 1
( ) ( )
'
11 Programme MATLAB disponible sur le site de
http://www.kevinsheppard.com/research/MatlabAtlas/MatlabAtlas.htm
Application :
|
La matrice Qt à l'instant t = 1
GLD
GLD0,9578 OIH
SPY IEV QQQQ
|
OIH
0,3549
0,9806
|
SPY 0,1847 0,5038 0,9751
|
IEV 0,3872 0,4775 0,7917 0,9805
|
QQQQ
0,1162 ?
0,3803 ?
?
0,8277 ?
?
0,6544 ?
0,9796 ?
?
|
La matrice Qt à l'instant t = 780
|
GLD
GLD0,9581 OIH
SPY IEV QQQQ
La matrice Qt à l'instant t = 781
GLD
|
OIH
0,4249
1,00
OIH
|
SPY 0,2102 0,6150 1,0731
SPY
|
IEV 0,4278 0,5682 0,8743 1,0456
IEV
|
QQQQ
0,1707 ?
0,5451 ?
?
0,9420 ?
?
0,7591 ?
1,1125 ?
?
QQQQ
|
|
GLD OIH SPY IEV QQQQ
|
0,9729
|
0,4244
0,9837
|
0,1991
0,5981
1,0513
|
0,4408 0,5613 0,8510 1, 0394
|
0,1636 ?
?
0,5290
?
0,9212 ?
?
0,7401 ?
1, 0877 ?
?
|
Après calcul de la matrice Qt , on
modélise la matrice Rt de la manière suivante
:
? 1 / 2 ? 1 / 2
R t =
( ) ( )
diagQ t Q t diagQ t
|
Application :
Matrice de corrélation à l'instant t =
1
GLD OIH GLD1 0,3662
OIH 1
SPY
IEV
QQQQ
|
SPY
0,1912
0,5152
1
|
IEV
0,3996
0,4869
0,8097
1
|
QQQQ
0,1200
0,3880
0.8469
0.6678
1
|
|
Matrice de corrélation à l'instant t =
780
GLD OIH GLD1 0,4341
OIH 1
SPY
IEV
QQQQ
|
SPY 0,2073 0,5936
1
|
IEV
0,4274
0,5556
0,8254
1
|
QQQQ
0,1654
0,5168
0,862 1
0,7038
1
|
Prévision de la matrice de corrélation
à l'instant t = 781
|
GLD OIH SPY IEV QQQQ
|
GLD OIH
1 0,4338
1
|
SPY 0,1969 0,5881
1
|
IEV 0,4384 0,5551 0,8142
1
|
QQQQ 0,1591 0,5114 0,8615 0,6961
1
|
Paramètres de la partie
corrélation
|
Paramètres
|
Valeurs
|
|
áDCC
|
0 ,01853
|
|
âDCC
|
0,94881
|
On constate qu'à l'image de la majeure partie des
séries d'actifs à l'étude, les corrélations
conditionnelles dynamiques ont un effet autorégressif inférieur
à 0,94. Pour ce qui est de la
sensibilité aux chocs de nos corrélations, elle est
moins importante que celle que l'on trouve pour les 5 séries ci-dessus
(0.01853).
On a, par conséquent, une volatilité avec une
sensibilité aux chocs beaucoup plus forte pour les corrélations
comparativement à celle des rendements d'actifs.
Simulation par backtesting de stratégies
d'investissements
Introduction :
Dans ce chapitre, nous allons présenter la partie pratique
de notre mémoire. Cette partie consiste à présenter un
programme, que nous avons réalisé en Matlab, qui permet
d'effectuer une opération appelée dans le monde de la finance, le
Backtesting. Cette opération, consiste à simuler dans le
passé une stratégie d'allocation de portefeuille,
c'est-à-dire une manière d'attribuer des poids à chacun
des actifs du portefeuille au cours du temps. Elle permet en particulier, de
vérifier de manière empirique, comment une stratégie
donnée se serait comportée dans des conditions réelles en
se plaçant dans le passé sur une période donnée.
Description du Backtesting effectué
L'opération de backtesting consiste à simuler dans
des conditions réelles une stratégie d'allocation de
portefeuille. Elle consiste à choisir une date particulière dans
le passé, à allouer un capital donné (une somme d'argent)
dans un portefeuille à cette date en utilisant la formule d'optimisation
introduite dans le chapitre précédant. Elle consiste ensuite
à réallouer le capital du portefeuille chaque semaine ou chaque
mois, c'est à dire avec une fréquence donnée. On imite
ainsi un gestionnaire de fond qui, en fonction de l'évolution du
marché va attribuer son capital en prenant en compte les variations de
prix constatées sur les marchés le dernier mois ou les
dernières semaines. Dans notre cas, ces variations sont traduites par le
calcul de nouveaux rendements espères pour chacun des actifs et d'une
nouvelle matrice de corrélation estimée selon la méthode
GARCH DCC. Celle-ci prends en compte les données des prix des actifs
depuis la date initiale jusqu'à la date de réallocation. Les
valeurs se trouvant après la date de réallocation ne peuvent
effectivement pas être prises en compte puisqu'elles se trouvent dans le
futur à ce moment-là.
Dans notre cas pratique, nous avons choisi de tester notre
approche sur le portefeuille composé de GLD, OIH, SPY, IEV et QQQQ
introduits précédemment.
Nous avons effectué le Backtesting sur une période
allant de janvier 2005 à décembre 2007, avec une
réallocation des poids tous les mois (22 jours ouvrables).
La réallocation, c'est-à-dire le nouveau calcul des
poids est effectué en fonction des mesures de performances (rendements
espérés) et du risque estimé sous forme de la matrice de
corrélation calculée au moyen de la méthode GARCH DCC.
A la première date du backtesting, on suppose que le
capital initial du portefeuille est de 100 unités. On réalise une
opération d'optimisation qui donnera pour chaque actif un poids
donné. Le capital investit sur chaque actif correspondra au capital
initial multiplié par le poids correspondant. Ensuite, les jours
suivants la valeur de ce portefeuille va évoluer.
En effet, chaque jour séparant deux allocations, les poids
vont rester constants mais les prix des différents actifs vont
évoluer sur les marchés. Ces variations de prix vont donner,
chaque jour, une nouvelle valeur au capital investit dans chaque actif et donc
au portefeuille. La nouvelle valeur du portefeuille correspond à la
somme des nouvelles valeurs des capitaux investis dans chaque actif. Les jours
prochains, la valeur du portefeuille va changer conformément au
changement des prix des actifs détenus dans le portefeuille.
Lors d'une nouvelle période de réallocation, nous
calculons la valeur du portefeuille le jour précédant de la
réallocation. Nous calculons de nouveaux poids au moyen d'une nouvelle
opération d'optimisation et le nouveau capital du portefeuille est
réparti sur les différents actifs et ainsi de suite
jusqu'à la fin de la période de backtesting.
Afin de comparer l'efficacité de l'optimisation en
utilisant la méthode GARCH DCC, nous allons calculer la valeur du
portefeuille en utilisant en parallèle une méthode d'optimisation
qui utilise une matrice de corrélation empirique. Pour les deux
méthodes, tous les paramètres d'optimisation seront les
mêmes mis a part la matrice de corrélation. Nous allons
également supposer que le capital initial est de 100 unités pour
les deux portefeuilles ce qui permettra de les comparer par la suite sur une
base commune. Un portefeuille qui vaudra 120 unités à la fin du
backtesting correspondra à un portefeuille dont la valeur aura
augmenté de 20% sur cette période.
La fonction de backtesting que nous avons
réalisé est la suivante :
[PortA_NAV, PortB_NAV, PortWtsA, PortWtsB] = backtesting (NAV,
Window, StartDate, EndDate, Frequency).
Le programme matlab
function [TickSeries, PortA_NAV, PortB_NAV, PortWtsA ,PortWtsB] =
backtesting(NAV, Window, StartDate, EndDate, Frequency)
%
% Backtesting simulation (Mean-Variance optimization)
%
% Inputs
% NAV : market data (price or Net Asset value)
% Window : estimation window
% StartDate : backtesting begin
% EndDate : backtesting end
% Frequency : rebalancing frequency
%
% Outputs
% TickSeries : NAV (base 100) of assets
% PortA_NAV : NAV of optimal portfolio with empirical cov.
matrix
% PortB_NAV : NAV of optimal portfolio with GARCH cov. matrix
% PortWtsA : optimal weights of portfolio with empirical
cov.
ma t r ix
% PortWtsB : optimal weights of portfolio with GARCH cov.
matrix
%
% Example
% backtesting(NAV, 250, 250, 779, 22)
%
% author: Khaled Layaida, M.Allamine Alhabo, (2008)
%
% get/load data ETFs
%disp('Load Market Data ...'); %addpath . /market_data
%load serie
% log-returns
serie = price2ret(NAV);
% number of dates and number of assets [NumDates, NumAssets] =
size(serie);
% tests
if (Window < 12)
disp('Input error - the input parameter window is too small !
Window >= 12 pts');
return;
end;
if (StartDate < Window)
disp('Input error - the start date of the backtesting is smaller
than window estimation !');
return;
end;
if (StartDate > (EndDate-2))
disp('Input error - the end date of the backtesting must be
bigger than start date + 1 !');
return;
end;
% backtesting parameters
NumOpt = floor((NumDates-StartDate)/Frequency + 1); % number of
rebalancing (optimization)
% Quadratic programming options
options = optimset('quadprog');
options = optimset(options, 'LargeScale','off'); f =
zeros(NumAssets,1); % linear part
Aeq = ones(1,NumAssets); % matrix of equalities constraints
beq = ones(1,1); % vector of equalities constraints
lb = zeros(NumAssets,1); % lower bounds
ub = 0.5*ones(NumAssets,1); % upper bounds
% initialisation
PortWtsA = [] ; % weights of portfolio A
PortRiskA = [];
PortReturnA = [];
PortWtsB = [] ; % weights of portfolio B
PortRiskB = [];
PortReturnB = [];
normFro = [];
% backtest loop: Start date -> End date
ii = 0;
%sprintf('Backtest ... with %i', NumOpt, ' rebalancing ...'); for
k = 1:NumOpt
% use subdata for rebalancing ii
index = ii*Frequency + StartDate + 1 - Window : ii*Frequency +
StartDate;
RetSeries = serie(index,:);
% cumulative estimation window (for GARCH) index_cum = 1 :
ii*Frequency + StartDate; RetSeriesGARCH = serie (index_cum,:);
ii = ii + 1;
% expected returns and empirical cov. matrix [ExpReturn,
ExpCovariance] = ewstats(RetSeries);
% GARCH cov. matrix
[ExpCovarianceGARCH] = covGARCH (RetSeriesGARCH);
% Frobenius-norm of matrix
covDif f = ExpCovariance-ExpCovarianceGARCH; normFro = [normFro,
norm(covDiff,'fro')];
% target return
TargetReturn = -10000; %TargetReturn = mean(ExpReturn);
%TargetReturn = 20000;
% Mean-Variance optimal portfolio
% portfolio A (empirical cov. matrix)
[WtsA, fval,exitflag, output, lambda] = quadprog(ExpCovariance,
f, - ExpReturn,-TargetReturn,Aeq,beq,lb,ub,[] ,options);
PortWtsA = [ PortWtsA, WtsA];
PortRiskA = [ PortRiskA, sqrt(WtsA'*ExpCovariance*WtsA)];
PortReturnA = [ PortReturnA, ExpReturn*WtsA];
% portfolio B (GARCH cov. matrix)
[WtsB, fval,exitflag, output, lambda] =
quadprog(ExpCovarianceGARCH, f, - ExpReturn,-TargetReturn,Aeq,beq,lb,ub,[]
,options);
PortWtsB = [ PortWtsB, WtsB];
PortRiskB = [ PortRiskB, sqrt(WtsB'*ExpCovarianceGARCH*WtsB)];
PortReturnB = [ PortReturnB, ExpReturn*WtsB];
end
% returns -> prices
[TickSeries] = ret2price(serie(StartDate+1:EndDate,:));
% construct portfolio NAV
|
PortA_NAV
|
=
|
[];
|
|
PortB_NAV
|
=
|
[];
|
|
coefA
|
=
|
1;
|
|
coefB
|
=
|
1;
|
for k = 1:NumOpt-1
index = 1 + (k-1)*Frequency: k*Frequency; WtsA = [];
WtsB = [];
for i = 1:Frequency
WtsA = [WtsA; PortWtsA(:,k)']; WtsB = [WtsB; PortWtsB (: , k)
'];
end;
PortA_NAV = [ PortA_NAV; coefA*sum(WtsA.*TickSeries(index,
:),2)];
PortB_NAV = [ PortB_NAV; coefB* sum(WtsB.*TickSeries (index, :) ,
2)];
if (k < (NumOpt -1))
coefA =
PortA _NAV(k* Frequency) /sum(PortWtsA(: , k+1)'.*TickSeries
(k*Frequency+1, :) , 2) ;
coefB =
PortB_NAV(k*Frequency) /sum(PortWtsB(: , k+1)'.*TickSeries
(k*Frequency+1, :) , 2) ;
end;
end
% portfolio log-returns
PortA_ret = price2ret(PortA_NAV); PortB_ret =
price2ret(PortB_NAV); [n, p] = size(PortA_NAV);
% plot NAV
hold on;
title('Portfolios and Assets NAV');
xlabel ('Time');
ylabel('NAV (base 100)'); plot(100*PortA_NAV, 'b');
plot(100*PortB_NAV, 'r'); for k = 1:NumAssets
plot(100*TickSeries(1:n,k), 'g');
end;
hold off
%
% ex-post Perf. and Risk Analysis % % Total return %
perfA = 100* (PortA_NAV(n)-PortA_NAV(1))/PortA_NAV(1);
perfB = 100* (PortB_NAV(n)-PortB_NAV(1))/PortB_NAV(1);
% Mean return %
meanA = 100*mean(PortA_ret);
meanB = 100*mean(PortB_ret);
% volatility %
volatilityA = 100*STD(PortA_ret);
volatilityB =
100*STD(PortB_ret);
% Value-at-Risk %
%ValueAtRiskA = portvrisk(PortReturn, PortRisk, RiskThreshold,
PortValue);
%ValueAtRiskB = portvrisk(PortReturn, PortRisk, RiskThreshold,
PortValue);
% display results
disp('Total perf.% Mean% Vol%');
disp([perfA, meanA, volatilityA; perfB, meanB, volatilityB] );
End.
Cette fonction permet de réaliser l'opération de
backtesting et d'afficher le graphe des valeurs des portefeuilles
calculés avec la méthode GARCH DCC et avec la méthode
empirique.
Les paramètres d'entrée de la fonction sont :
NAV : la matrice qui contient les séries
des prix des actifs.
Window : la fréquence pour estimer la
matrice empirique, cela veut dire que l'on prend 50 valeurs
précédant la date d'allocation pour calculer la matrice
empirique.
StartDate : début du backtesting.
EndDate : fin du backtesting.
Frequency : fréquence de ré
optimisation (ici on optimise chaque 22 jours).
Les paramètres de sortie sont :
TickSeries : valeurs de chaque actif à
base 100.
PortA_NAV : valeurs de chaque actif à
base 100, avec la matrice empirique.
PortB_NAV : valeurs de chaque actif à
base, avec la matrice du GARCH DCC. PortWtsA : les proportions
optimales du portefeuille avec la matrice empirique. PortWtsB
: les proportions optimales du portefeuille avec la matrice GARCH DCC.
L'opération de backtesting est effectuée dans
Matlab au moyen de deux commandes :
1) La commande : [NAV]=xlsread ('données'); permet de
charger les pris des actifs depuis un fichier Excel et les stocker dans un
tableau NAV dans le MATLAB.
2) la commande : [TickSeries, PortA_NAV, PortB_NAV, PortWtsA,
PortWtsB]=backtesting (NAV, 250, 250, 779, 22); cette commande permet de lancer
le programme qui calcule en même temps la matrice de corrélation
empirique et la matrice de corrélation avec le modèle GARCH DCC,
en suite lancer le programme d'optimisation avec chaque matrice. Cela va nous
permettre de voir l'efficacité des modèles GARCH DCC au sens de
la minimisation de la variance (risque).
En fin d'optimisation, on obtient les pourcentages d'allocation,
ainsi que la valeur de chaque portefeuille à base 100.
Application :
Dans cette partie on va appliquer le backtesting en posant les
contraintes suivantes :
1. l'optimisation ne peut pas allouer 50% du capital sur un seul
actif.
2. l'optimisation ne peut pas allouer 35% du capital sur un seul
actif.
3. l'optimisation est effectuée sans contraintes, il est
possible que chaque actif puisse représenter 100 % du capital du
portefeuille à l'issu de l'optimisation.
Dans la suite de ce chapitre, nous allons donc appliquer ces
trois opérations de backtesting et comparer les résultats avec la
méthode empirique. Pour chaque test, nous allons afficher : le graphique
des rendements des deux portefeuilles, la composition initiale et finale des
portefeuilles ainsi que l'évolution de la composition du portefeuille au
cours de la période du backtesting.
Contrainte 1 : Maximum 50 % sur chaque actif
Dans cette partie, on suppose que l'investisseur ne peut pas
mettre plus de 50 % de son capital sur un seul actif, cela en posant cette
contrainte dans le problème d'optimisation
précèdent. Diagrammes en camembert :
La méthode empirique :
Ces diagrammes montrent la stratégie d'allocation
initiale et finale de l'investisseur, et cela on se basant sur le programme
d'optimisation quadratique, la matrice de corrélation utilisée
dans cette partie est calculée empiriquement.
|
|
|
Proportions initiales (Décembre
2005)
Méthode empirique
|
|
Proportions finales (Décembre
2007)
Méthode empirique
|
|
50%
|
0% 8%
|
|
|
|
42%
|
GLD OIH SPY IEV QQQQ
|
|
50%
|
0%
|
5%
|
|
|
|
45%
|
GLD OIH SPY IEV QQQQ
|
|
|
0%
|
|
0%
|
|
|
La méthode GARCH DCC :
En prenant en compte la matrice GARCH DCC dans l'optimisation, on
voit que les proportions d'investissement sont différentes à ceux
de la méthode empirique, par exemple dans la partie empirique on a
initialement 8% QQQQ et 42% GLD, mais dans cette partie on remarque une
diminution de l'actif QQQQ (4%) aussi l'actif GLD avec 36%, aussi on voit que
la proportion de l'actif SPY a diminué de 4% c'est-à-dire avec
une proportion de 45%. Dans la période décembre 2007, on remarque
que les proportions sont 45% GLD, 5% QQQQ et 50% SPY, alors qu'on ne
possède pas de OIH et IEV dans le portefeuille.
|
|
|
Proportions initiales (Décembre 2005)
GARCH
DCC
|
Proportions finales (Décembre 2007)
GARCH
DCC
|
|
45%
|
0% 4%
|
|
|
36%
|
GLD OIH
SPY IEV
QQQQ
|
|
50%
|
|
0%
|
|
0%
|
50%
|
GLD OIH SPY IEV QQQQ
|
|
|
15%
|
0%
|
|
|
Composition historique des portefeuilles
Méthode empirique:
Ce diagramme nous donne la composition historique du
portefeuille après chaque allocation optimale (22 jours ouvrables),
cette allocation est effectivement basée sur la minimisation de la
volatilité, et cela en se basant sur la matrice de corrélation
calculée empiriquement.
|
|
Composition du portefeuille (Méthode
empirique)
1
|
|
0,9
|
|
|
|
0,8
|
|
QQQQ IEV SPY OIH GLD
|
|
|
0,7 0,6 0,5 0,4 0,3 0,2
|
|
|
0,1
0
|
|
|
|
Dates
|
|
Tableau historique des allocations :
Le tableau ci dessous affiche les différentes proportions
de chaque actif durant toute la période du backtesting, il nous permet
de voir les valeurs exactes des allocations après chaque optimisation
mensuelle, avec la matrice calculée empiriquement.
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
|
déc-05
|
0,42389
|
0
|
0,5
|
0
|
0,07611
|
|
janv-06
|
0,37319
|
0
|
0,5
|
0
|
0,12681
|
|
févr-06
|
0,31551
|
0
|
0,5
|
0,039197
|
0,14529
|
|
mars-06
|
0,2943
|
0
|
0,5
|
0,06502
|
0,14068
|
|
avr-06
|
0,21528
|
0
|
0,5
|
0,11997
|
0,16475
|
|
mai-06
|
0,19627
|
0
|
0,5
|
0,079208
|
0,22452
|
|
juin-06
|
0,18516
|
0
|
0,5
|
0,037334
|
0,27751
|
|
juil-06
|
0,17966
|
0
|
0,5
|
0,024975
|
0,29537
|
|
aoùt-06
|
0,18313
|
0
|
0,5
|
0,070324
|
0,24654
|
|
sept-06
|
0,16463
|
0
|
0,5
|
0,098395
|
0,23698
|
|
oct-06
|
0,14205
|
0
|
0,5
|
0,14098
|
0,21698
|
|
nov-06
|
0,15193
|
0
|
0,5
|
0,13404
|
0,21403
|
|
déc-06
|
0,16469
|
0
|
0,5
|
0,12482
|
0,21049
|
|
janv-07
|
0,17223
|
0
|
0,5
|
0,088494
|
0,23927
|
|
févr-07
|
0,18806
|
0
|
0,5
|
0,057388
|
0,25456
|
|
mars-07
|
0,20609
|
0
|
0,5
|
0
|
0,29391
|
|
avr-07
|
0,23204
|
0
|
0,5
|
0
|
0,26796
|
|
mai-07
|
0,22355
|
0
|
0,5
|
0
|
0,27645
|
|
juin-07
|
0,26982
|
0
|
0,5
|
0
|
0,23018
|
|
juil-07
|
0,26605
|
0
|
0,5
|
0
|
0,23395
|
|
aoùt-07
|
0,33515
|
0
|
0,5
|
0
|
0,16485
|
|
sept-07
|
0,39176
|
0
|
0,5
|
0
|
0,10824
|
|
oct-07
|
0,41407
|
0
|
0,5
|
0
|
0,08593 1
|
|
nov-07
|
0,41818
|
0
|
0,5
|
0
|
0,081825
|
|
déc-07
|
0,45213
|
0
|
0,5
|
0
|
0,047867
|
Méthode GARCH DCC :
On voit d'après cette composition historique, que la
stratégie d'investissement est basée principalement sur l'action
refuge GLD avec 50% du capital, et cela tout le long du backtesting, on
remarque aussi que la proportion de SPY est aussi remarquable, par contre les
autres actifs ne figurent pas avec des pourcentages considérables.
Par exemple, on voit l'actif OIH figure dans le graphique en
début de période, après il disparaît pour
réapparaître entre avril et août 2007, dans cette
période on voit aussi l'apparition de l'actif IEV avec les même
proportions a peut prêt.
|
|
Composition du portefeuille (GARCH DCC)
1
|
|
0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2 0,1
0
|
|
|
|
QQQQ IEV SPY OIH GLD
|
|
|
|
|
Dates
|
|
Proportions avec la matrice GARCH DCC :
Le tableau ci-dessous affiche les valeurs du graphique
précédent. On voit l'inclusion brusque des actifs OIH et IEV
entre Avril et Juin 2007, cela a causé la diminution des parts de
l'actif SPY dans le portefeuille. La proportion du GLD est de 50% pendant toute
la période, elle désigne une valeur maximale que peut prendre cet
actif.
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
|
déc-05
|
0,36407
|
0,14979
|
0,4443
|
0
|
0,041835
|
|
janv-06
|
0,5
|
0,017636
|
0,48236
|
0
|
0
|
|
févr-06
|
0,5
|
0,16536
|
0,33464
|
0
|
0
|
|
mars-06
|
0,5
|
0,16441
|
0,33559
|
0
|
0
|
|
avr-06
|
0,5
|
0,15325
|
0,34675
|
0
|
0
|
|
mai-06
|
0,5
|
0,14609
|
0,35391
|
0
|
0
|
|
juin-06
|
0,5
|
0,0069236
|
0,49308
|
0
|
0
|
|
juil-06
|
0,5
|
0
|
0,5
|
0
|
0
|
|
aoùt-06
|
0,5
|
0
|
0,5
|
0
|
0
|
|
sept-06
|
0,5
|
0
|
0,5
|
0
|
0
|
|
oct-06
|
0,5
|
0
|
0,5
|
0
|
0
|
|
nov-06
|
0,5
|
0
|
0,5
|
0
|
0
|
|
déc-06
|
0,5
|
0
|
0,5
|
0
|
0
|
|
janv-07
|
0,5
|
0
|
0,5
|
0
|
0
|
|
févr-07
|
0,5
|
0
|
0,5
|
0
|
0
|
|
mars-07
|
0,5
|
0
|
0,5
|
0
|
0
|
|
avr-07
|
0,5
|
0,15173
|
0,12109
|
0,22719
|
0
|
|
mai-07
|
0,5
|
0,16387
|
0,11988
|
0,21625
|
0
|
|
juin-07
|
0,5
|
0,18366
|
0,11412
|
0,20222
|
0
|
|
juil-07
|
0,5
|
0
|
0,5
|
0
|
0
|
|
aoùt-07
|
0,5
|
0
|
0,5
|
0
|
0
|
|
sept-07
|
0,5
|
0
|
0,5
|
0
|
0
|
|
oct-07
|
0,5
|
0
|
0,5
|
0
|
0
|
|
nov-07
|
0,5
|
0
|
0,5
|
0
|
0
|
|
déc-07
|
0,5
|
0
|
0,5
|
0
|
0
|
Comparaison des valeurs historiques de chaque
portefeuille :
|
Portfolio and asset NAV
|
|
|
1,8
|
|
|
1,6
1,4
|
|
|
|
|
|
|
|
1,2
1
|
|
|
|
|
|
Empirique GARCH DCC
|
|
|
0,8
|
|
|
|
|
0,6
|
|
|
0,4
|
|
|
0,2
0
|
|
|
|
|
|
|
|
Dates
|
On remarque d'après le graphique ci-dessus que le
rendement du portefeuille avec la méthode GARCH DCC est nettement
supérieur à celui de la méthode empirique, surtout dans
les période de forte volatilité (entre le mois de février
et septembre 2006), on remarque que dans cette partie le rendement est
nettement meilleur, on peut donc affirmer que les modèles GARCH DCC sont
puissant au sens de l'anticipation rapide de la corrélation, cette
anticipation cause évidemment un changement rapide des allocations lors
de l'optimisation.
Contrainte 2 : Maximum 35 % sur chaque actif
Dans cette partie, on suppose que l'investisseur ne peut pas
mettre plus de 35 % de son capital sur un seul actif, cela en posant cette
contrainte dans le problème d'optimisation précédent. On a
posé cette nouvelle contrainte pour voire est ce que cette
dernière peut changer les résultats de l'optimisation, c'est la
méthode utilisée souvent par les gestionnaires de portefeuilles,
cela pour forcer la diversification et diminuer ainsi le risque.
Diagrammes en camembert :
La méthode empirique :
Ces diagrammes montrent la stratégie d'allocation
initiale et finale de l'investisseur, et cela on se basant sur le programme
d'optimisation quadratique, la matrice utilisée dans cette partie est
calculée empiriquement.
|
|
|
Proportions initiales (Décembre
2005)
Méthode empirique
22%
|
|
Proportions finales (Décembre
2007)
Méthode empirique
|
|
30%
0%
|
|
|
|
|
35%
0%
|
GLD OIH SPY IEV QQQQ
|
|
35%
|
GLD OIH SPY IEV QQQQ
|
|
8%
0%
|
|
35%
|
|
35%
|
|
|
On remarque que les proportions initiales et finales n'ont pas
changé pratiquement, sauf pour le de IEV qui a diminué
jusqu'à atteindre la valeur 0%, ce qui veut dire l'absence totale de cet
actif, aussi l'augmentation de la proportion de l'actif QQQQ. Alors que l'actif
OIH est depuis le début en 0%.
La méthode GARCH DCC :
Ici, les proportions de départ sont de 11% QQQQ, on
remarque aussi qu'on a la même valeur de GLD 35%, mais dans cette partie
l'actif OIH est inclus dans le portefeuille avec 19%, cela est peut être
dû au pouvoir prédictif de la volatilité de la
méthode GARCH DCC, c'est-à-dire que dans cette période on
a eu sûrement une baisse remarquable de volatilité, ce qui
implique a causé l'inclusion de cet actif dans cette méthode.
|
|
|
Proportions initiales (Décembre 2005)
GARCH
DCC
11%
|
Proportions finales (Décembre 2007)
GARCH
DCC
|
|
35%
|
0%
|
|
|
|
|
35%
|
GLD OIH SPY IEV QQQQ
|
|
27%
|
|
35%
3%
|
GLD OIH SPY IEV QQQQ
|
|
0%
|
|
|
|
|
35%
|
|
19%
|
|
|
Composition historique des portefeuilles
Méthode empirique :
Ce diagramme nous donne la composition historique du portefeuille
après chaque allocation optimale (chaque 22 jours ouvrables), cette
allocation est effectivement basée sur la minimisation de la
volatilité, on remarque que ce portefeuille se compose de 4 actifs, il
est diversifié en plus grande partie entre QQQQ, SPY, GLD et une petite
proportion de l'actif IEV. Tout le long de l'historique on remarque l'absence
de l'actif OIH, et cela contrairement à la méthode GARCH DCC,
c'est à cause des différences entre les matrices de
corrélation.
|
|
Composition du portefeuille (Méthode
empirique)
1
|
|
0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2 0,1
0
|
|
|
|
QQQQ IEV
SPY OIH GLD
|
|
|
|
|
|
|
|
Dates
|
|
Proportions avec la matrice empirique :
Le tableau dans la page suivante affiche les différentes
proportions de chaque actif durant toute la période du backtesting, il
nous permet de voire les valeurs exactes des allocations après chaque
optimisation mensuelle (22 jours ouvrables), avec la matrice calculée
empiriquement.
On voit que les proportions de la série OIH sont nulles
tout le long du backtesting, celles de SPY sont constantes et maximales,
puisque elles sont égales à la contrainte supposée (35%).
Les autres actifs ont par contre des proportions variables dans le temps, et
cela est dù aux changements de la volatilité du portefeuille.
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
|
déc-05
|
0,35
|
0
|
0,35
|
0,08194
|
0,21806
|
|
janv-06
|
0,35
|
0
|
0,35
|
0,067631
|
0,23237
|
|
févr-06
|
0,32003
|
0
|
0,35
|
0,098958
|
0,23101
|
|
mars-06
|
0,29927
|
0
|
0,35
|
0,12564
|
0,22509
|
|
avr-06
|
0,217
|
0
|
0,35
|
0,18111
|
0,25189
|
|
mai-06
|
0,19964
|
0
|
0,35
|
0,136
|
0,31435
|
|
juin-06
|
0,18791
|
0
|
0,35
|
0,11209
|
0,35
|
|
juil-06
|
0,18186
|
0
|
0,35
|
0,11814
|
0,35
|
|
aoùt-06
|
0,18669
|
0
|
0,35
|
0,13878
|
0,32453
|
|
sept-06
|
0,16884
|
0
|
0,35
|
0,1668
|
0,31437
|
|
oct-06
|
0,14647
|
0
|
0,35
|
0,20999
|
0,29355
|
|
nov-06
|
0,15652
|
0
|
0,35
|
0,20432
|
0,28917
|
|
déc-06
|
0,17006
|
0
|
0,35
|
0,19507
|
0,28487
|
|
janv-07
|
0,17936
|
0
|
0,35
|
0,15852
|
0,31212
|
|
févr-07
|
0,19607
|
0
|
0,35
|
0,12789
|
0,32604
|
|
mars-07
|
0,22493
|
0
|
0,35
|
0,075066
|
0,35
|
|
avr-07
|
0,26159
|
0
|
0,35
|
0,038414
|
0,35
|
|
mai-07
|
0,23734
|
0
|
0,35
|
0,068735
|
0,34392
|
|
juin-07
|
0,30162
|
0
|
0,35
|
0
|
0,34829
|
|
juil-07
|
0,3
|
0
|
0,35
|
0
|
0,35
|
|
aoùt-07
|
0,35
|
0
|
0,35
|
0
|
0,3
|
|
sept-07
|
0,35
|
0
|
0,35
|
0
|
0,3
|
|
oct-07
|
0,35
|
0
|
0,35
|
0
|
0,3
|
|
nov-07
|
0,35
|
0
|
0,35
|
0
|
0,3
|
|
déc-07
|
0,35
|
0
|
0,35
|
0
|
0,3
|
Méthode GARCH DCC:
Après diminution de la contrainte jusqu'à la valeur
35%, on remarque des changements significatifs dans les proportions,
contrairement à la méthode empirique.
Le changement principal est l'inclusion de l'actif OIH avec des
proportions importantes, et cela tout le long de la période du
backtesting, on voit aussi que les proportions de l'actif QQQQ ne sont pas les
mêmes (dès fois nulles), par contre le premier portefeuille
contenait de fortes proportions de QQQQ.
|
|
Composition du portefeuille (GARCH DCC)
1
|
|
0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2
0,1
0
|
|
|
|
QQQQ IEV SPY OIH GLD
|
|
|
|
|
|
Dates
|
|
Proportions avec la méthode GARCH DCC
:
Le tableau suivant montre la différence significative
entre les deux portefeuilles, au sens de diversification, cela est
naturellement à cause des différences entre les matrice de
corrélation, cette différence cause des changements dans
l'optimisation, car elle est basée sur la minimisation de la
volatilité qui s'écrit en fonction de la corrélation entre
les rendements des différents actifs.
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
|
déc-05
|
0,35
|
0,18935
|
0,35
|
0
|
0,11065
|
|
janv-06
|
0,35
|
0,17061
|
0,35
|
0,03721
|
0,092176
|
|
févr-06
|
0,35
|
0,25907
|
0,35
|
0,011695
|
0,029231
|
|
mars-06
|
0,35
|
0,26393
|
0,35
|
0,0036128
|
0,032454
|
|
avr-06
|
0,35
|
0,26284
|
0,35
|
0
|
0,037155
|
|
mai-06
|
0,35
|
0,25449
|
0,35
|
0
|
0,045505
|
|
juin-06
|
0,35
|
0,17813
|
0,35
|
0,11767
|
0,0041986
|
|
juil-06
|
0,35
|
0,17164
|
0,35
|
0,12836
|
0
|
|
aoùt-06
|
0,35
|
0,15025
|
0,35
|
0,14975
|
0
|
|
sept-06
|
0,35
|
0,13663
|
0,35
|
0,16337
|
0
|
|
oct-06
|
0,35
|
0,12713
|
0,35
|
0,17287
|
0
|
|
nov-06
|
0,35
|
0,11995
|
0,35
|
0,18005
|
0
|
|
déc-06
|
0,35
|
0,12057
|
0,35
|
0,17943
|
0
|
|
janv-07
|
0,35
|
0,13242
|
0,35
|
0,16758
|
0
|
|
févr-07
|
0,35
|
0,13014
|
0,35
|
0,16986
|
0
|
|
mars-07
|
0,35
|
0,13492
|
0,35
|
0,16508
|
0
|
|
avr-07
|
0,35
|
0,21158
|
0,088423
|
0,35
|
0
|
|
mai-07
|
0,35
|
0,22504
|
0,085912
|
0,33905
|
0
|
|
juin-07
|
0,35
|
0,2487
|
0,081176
|
0,32013
|
0
|
|
juil-07
|
0,35
|
0,17807
|
0,35
|
0,12193
|
0
|
|
aoùt-07
|
0,35
|
0,14458
|
0,35
|
0,15542
|
0
|
|
sept-07
|
0,35
|
0,14236
|
0,35
|
0,15764
|
0
|
|
oct-07
|
0,35
|
0,13674
|
0,35
|
0,16326
|
0
|
|
nov-07
|
0,35
|
0,056212
|
0,35
|
0
|
0,24379
|
|
déc-07
|
0,35
|
0,02917
|
0,35
|
0
|
0,27083
|
Comparaison des rendements historiques des deux
portefeuilles :
En posant la contrainte pas plus de 35%, le rendement des deux
portefeuilles se rapprochent, mais celui de la méthode GARCH DCC reste
toujours supérieur à celui de la méthode empirique.
Le graphique suivant affiche les résultats :
|
|
Portfolio and asset NAV
|
|
1,6
|
|
|
1,4
|
|
|
1,2
|
|
|
1
|
|
|
0,4
0,2
0
|
|
Empirique GARCH DCC
|
|
|
0,8
|
|
0,6
|
|
|
|
Dates
|
|
Contrainte 3 : dans cette partie l'investisseur
peut placer tout son capital sur un seul actif. Donc l'investisseur est
exposé au risque de perdre toute fortune.
Diagrammes en camembert :
La méthode empirique :
Ces diagrammes montrent la stratégie d'allocation initiale
et finale de l'investisseur, et cela on se basant sur le programme
d'optimisation quadratique, la matrice utilisée dans cette partie est
calculée empiriquement, le programme d'optimisation n'est soumis
à aucune contrainte, au sens que les proportions de chaque actif peuvent
varier entre 0% et 100%.
|
Proportions initiales (Décembre
2005)
Méthode empirique
0% 0%
|
|
|
Proportions finales (Décembre
2007)
Méthode empirique
0%
|
|
|
|
|
|
|
40%
|
GLD OIH SPY IEV QQQQ
|
|
57%
|
|
|
|
|
43%
|
GLD OIH SPY IEV QQQQ
|
|
60%
|
|
0%
|
|
|
|
|
|
|
0%
|
|
|
On voit que cette fois le portefeuille est réparti
initialement seulement sur les deux actifs SPY et GLD, avec les proportions
respectivement 60% et 40%, ces deux actifs sont maintenus tout le long du
backtesting, on peut voir cela avec les proportions finales sur le diagramme en
camembert et le tableau historique des allocations ci-dessous.
La méthode GARCH DCC :
On voit que les proportions initiales de ce portefeuille sont de
15% OIH et 4% QQQQ, le reste du capital est réparti presque
semblablement entre GLD et SPY. Juste après cette période on
remarque la disparition de l'actif OIH du portefeuille.
|
|
|
Proportions initiales (Décembre 2005)
GARCH
DCC
0% 4%
|
Proportions finales (Décembre 2007)
GARCH
DCC
0% 0%
|
|
45%
|
|
|
|
|
36%
|
GLD OIH SPY IEV QQQQ
|
|
55%
|
|
|
|
|
45%
|
GLD OIH SPY IEV QQQQ
|
|
15%
|
|
0%
|
|
|
Composition historique des portefeuilles :
Méthode empirique :
Dans cette partie, on voit que le portefeuille est panaché
seulement entre l'actif SPY et GLD, la proportion de SPY est nettement plus
grande que celle de GLD.
On voit aussi une très faible proportion de QQQQ entre
août et décembre 2007.
|
|
Composition du portefeuille (Méthode
empirique)
1
|
|
0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2 0,1
0
|
|
|
|
QQQQ IEV SPY OIH GLD
|
|
|
|
Dates
|
|
Allocations avec la méthode empirique
:
Le tableau ci-dessous montre bien que le portefeuille comporte
seulement deux actifs, car les proportions des autres actifs sont toutes
nulles.
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
|
déc-05
|
0,40238
|
0
|
0,59762
|
0
|
0
|
|
janv-06
|
0,33761
|
0
|
0,66239
|
0
|
0
|
|
févr-06
|
0,28326
|
0
|
0,71674
|
0
|
0
|
|
mars-06
|
0,26366
|
0
|
0,73634
|
0
|
0
|
|
avr-06
|
0,19407
|
0
|
0,80593
|
0
|
0
|
|
mai-06
|
0,16256
|
0
|
0,83744
|
0
|
0
|
|
juin-06
|
0,13331
|
0
|
0,86669
|
0
|
0
|
|
juil-06
|
0,12084
|
0
|
0,87916
|
0
|
0
|
|
aoùt-06
|
0,12733
|
0
|
0,87267
|
0
|
0
|
|
sept-06
|
0,10793
|
0
|
0,89207
|
0
|
0
|
|
oct-06
|
0,086667
|
0
|
0,91333
|
0
|
0
|
|
nov-06
|
0,095493
|
0
|
0,90451
|
0
|
0
|
|
déc-06
|
0,10489
|
0
|
0,89511
|
0
|
0
|
|
janv-07
|
0,097432
|
0
|
0,90257
|
0
|
0
|
|
févr-07
|
0,10374
|
0
|
0,89626
|
0
|
0
|
|
mars-07
|
0,10456
|
0
|
0,89544
|
0
|
0
|
|
avr-07
|
0,1241
|
0
|
0,8759
|
0
|
0
|
|
mai-07
|
0,089102
|
0
|
0,9109
|
0
|
0
|
|
juin-07
|
0,16178
|
0
|
0,83822
|
0
|
0
|
|
juil-07
|
0,17809
|
0
|
0,82191
|
0
|
0
|
|
aoùt-07
|
0,29933
|
0
|
0,68424
|
0
|
0,016429
|
|
sept-07
|
0,36392
|
0
|
0,63608
|
0
|
0
|
|
oct-07
|
0,39237
|
0
|
0,6007
|
0
|
0,0069254
|
|
nov-07
|
0,39355
|
0
|
0,60645
|
0
|
0
|
|
déc-07
|
0,43296
|
0
|
0,56704
|
0
|
0
|
La méthode GARCH DCC :
Le diagramme suivant montre la composition historique du
portefeuille en optimisant avec la matrice GARCH DCC, ce portefeuille est
panaché seulement avec les actif SPY et GLD. L'actif OIH est inclus au
début avec de petites proportions, mais après juin 2006 il ne
fait plus partie de ce portefeuille. On voit aussi de très faibles
proportions de QQQQ juste au début du backtesting.
|
|
Composition du portefeuille (GARCH DCC)
1
|
|
0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2 0,1
0
|
|
|
|
QQQQ IEV SPY OIH GLD
|
|
|
|
|
Dates
|
|
Proportions avec la méthode GARCH DCC
:
|
GLD
|
OIH
|
SPY
|
IEV
|
QQQQ
|
|
déc-05
|
0,36407
|
0,14979
|
0,4443
|
0
|
0,041835
|
|
janv-06
|
0,70364
|
0
|
0,29636
|
0
|
0
|
|
févr-06
|
0,81414
|
0,025608
|
0,15137
|
0
|
0,0088825
|
|
mars-06
|
0,79983
|
0,025452
|
0,17253
|
0
|
0,0021918
|
|
avr-06
|
0,78757
|
0,019813
|
0,19262
|
0
|
0
|
|
mai-06
|
0,78528
|
0,011579
|
0,20314
|
0
|
0
|
|
juin-06
|
0,65375
|
0
|
0,34625
|
0
|
0
|
|
juil-06
|
0,67228
|
0
|
0,32772
|
0
|
0
|
|
aoùt-06
|
0,63736
|
0
|
0,36264
|
0
|
0
|
|
sept-06
|
0,61046
|
0
|
0,38954
|
0
|
0
|
|
oct-06
|
0,5927
|
0
|
0,4073
|
0
|
0
|
|
nov-06
|
0,56008
|
0
|
0,43992
|
0
|
0
|
|
déc-06
|
0,5783
|
0
|
0,4217
|
0
|
0
|
|
janv-07
|
0,5705
|
0
|
0,4295
|
0
|
0
|
|
févr-07
|
0,5832
|
0
|
0,4168
|
0
|
0
|
|
mars-07
|
0,56575
|
0
|
0,43425
|
0
|
0
|
|
avr-07
|
0,84662
|
0,0013472
|
0,15204
|
0
|
0
|
|
mai-07
|
0,85078
|
0,005443
|
0,14378
|
0
|
0
|
|
juin-07
|
0,8617
|
0,0090138
|
0,12929
|
0
|
0
|
|
juil-07
|
0,5624
|
0
|
0,4376
|
0
|
0
|
|
aoùt-07
|
0,5277
|
0
|
0,4723
|
0
|
0
|
|
sept-07
|
0,48123
|
0
|
0,51877
|
0
|
0
|
|
oct-07
|
0,47608
|
0
|
0,52392
|
0
|
0
|
|
nov-07
|
0,451 77
|
0
|
0,54823
|
0
|
0
|
|
déc-07
|
0,45346
|
0
|
0,54654
|
0
|
0
|
Comparaison des rendements historiques des deux
portefeuilles :
Comme dans les parties précédentes, on voit dans ce
graphique le décalage nette entre les deux portefeuilles, la
méthode GARCH DCC se comporte mieux que la méthode empirique
même si on n'impose aucune contrainte.
Donc on peut dire que la méthode GARCH DCC est meilleure
que la méthode empirique utilisée souvent par la plupart des
gestionnaires de portefeuilles financiers, et cela surtout dans les
période de forte volatilité, par exemple dans la période
entre mars et juin 2006 on voit que la courbe GARCH DCC en rouge est nettement
supérieure à la courbe empirique (voire graphe ci-dessous).
|
|
Portfolio and asset NAV
|
|
1,8
1,6
1,4
|
|
|
|
|
|
1,2
|
|
1 0,8 0,6 0,4 0,2
0
|
|
Empirique GARCH DCC
|
|
|
|
|
|
|
|
Dates
|
|
|
Interprétation des résultats :
Ces résultats montrent que les techniques qui tiennent
compte des corrélations dynamiques performent mieux que les
méthodes traditionnelles basées sur les corrélations
empiriques. L'écart entre les niveaux de rendement produit par les
opérations d'optimisation basées sur des matrices empiriques et
DCC GARCH fait bien ressortir les différences très nettes. En
particulier, en période de forte volatilité, le modèle DCC
GARCH semble mieux anticiper le changement des corrélations. En effet,
on remarque que lorsque la volatilité des marchés augmente dans
les périodes suivantes :
1. Février 2006 à Juin 2006.
2. Avril 2007 à Août 2007.
3. Novembre 2007 à Décembre 2007.
Le graphique suivant affiche les rendements historiques des
actifs tout le long du backtesting, il montre aussi les trois périodes
volatiles que l'on a précisé précédemment.
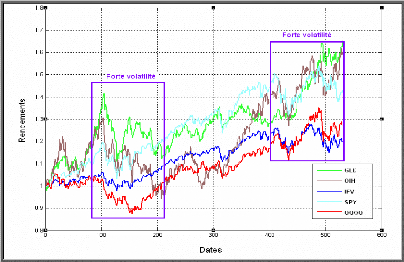
Plutôt que de tenter d'interpréter la composition
des portefeuilles lors du backtesting, opération difficile, nous allons
tenter d'identifier la variation de la composition du portefeuille à des
périodes clés. En effet, la composition du portefeuille
évolue de manière plus importante dans ces périodes pour
le portefeuille DCC GARCH que dans le cas empirique.
La différence des rendements tout au long du backtesting
permet de montrer que les rendements des portefeuilles GARCH sont
quasi-systématiquement supérieurs à ceux de la
méthode empirique. Cette supériorité demeure vraie
lorsqu'on applique des contraintes sur les poids. Ces contraintes sont souvent
utilisées par les gestionnaires de portefeuille pour forcer la
diversification et diminuer ainsi le risque.
Les techniques DCC GARCH sont plus efficaces dans la mesure
où elles se soucient des changements dans les corrélations et
qu'elles tiennent compte de leurs dynamiques dans le calcul des poids optimaux
des portefeuilles. Les poids calculés lors de l'optimisation incorporent
une plus grande quantité d'informations sur l'évolution des
marchés.
D'après nos résultats, le DCC GARCH apparaît
comme la meilleure option que puisse avoir un gestionnaire qui veut
améliorer ses rendements ou encore couvrir ses actifs contre les risques
de marchés.
Conclusion générale
Au cours de la préparation de notre mémoire de fin
d'études, nous avons été amenés à faire des
prévisions à l'aide de diverses méthodes sur des
séries financières. Et essayer d'attendre l'objectif principal de
notre étude qui est de tester une nouvelle modélisation de la
matrice de variance covariance pour l'optimisation de portefeuilles
financiers.
Pour cela nous avons proposé dans un premier temps
d'étudier individuellement les séries en utilisant l'approche
univariée, cette approche nous a permis de représenter nos
séries avec des modèles ARMA et ARIMA avec des résidus
ARCH ou GARCH.
En suite on est passé à la méthode Holt
& Winters, pour faire une prévision à court terme et comparer
les résultats avec ceux de la méthodologie de Box et Jenkins.
En effet, l'application de ces deux méthodes sur des
séries financières nous a permis de conclure que :
Les modèles ajustés ARMA (1,1) et ARMA (3,3) sont
plus performant que celui de la méthode Holt & Winters pour les
séries IEV et SPY qui représentent respectivement la valeur des
actions de 350 sociétés les plus représentatives de
l'économie européenne et la valeur des actions de 500 compagnies
les plus représentatives de l'économie américaine.
Par contre, la méthode Holt & Winters semble meilleure
que les modèles intégrés ARIMA (2, 1,0) et ARIMA (4, 1,4)
des séries QQQQ et GLD qui représentent respectivement la valeur
des actions des 100 plus grandes compagnies innovantes autre que
financières et la valeur de l'OR sur les marchés
internationaux.
Cependant la méthodologie de Box et Jenkins ne prend pas
en compte l'interdépendance des séries, pour cette raison nous
avons proposé par la suite une approche
hétéroscédastique multivariée pour parer aux
insuffisances de l'approche univariée.
Dans la partie multivariée, nous avons passé en
revue les différentes méthodes utilisées dans l'estimation
de la volatilité. Nous avons d'abord commencé par les
différentes approches depuis leurs créations, la première
approche est le modèle VEC proposé par Bollerslev, Engle et
Wooldrige (1988), c'est une extension directe du modèle ARCH
univarié, l'inconvénient majeur de ce modèle est le nombre
de paramètres à estimer, il devient de plus en plus grand au fur
et à mesure que le nombre des variables augmente. Pour réduire le
nombre de paramètres à estimer, les auteurs suggèrent la
formulation diagonale VEC (DVEC).
Certes, ce modèle réduit remarquablement le nombre
de paramètres à estimer par rapport au modèle
précédent, mais le grand désavantage de ce modèle
est l'absence de l'interdépendance entre les composants du
système donc la transmission de chocs entre les variables n'est pas
possible. Les variations de la volatilité d'une variable n'influencent
pas le comportement des autres variables dans le système. D'autre part,
la positivité de la matrice des variances covariances conditionnelles
n'est pas garantie par le modèle. Il faudrait imposer des restrictions
sur chaque élément de la matrice des variances covariances
conditionnelles.
Pour pallier aux insuffisances des modèles VEC et DVEC,
une approche qui garantit la positivité de la matrice des variances
covariances conditionnelles est suggérée par Baba, Engle, Kraft
et Kroner (1 990).Puis elle a été synthétisée dans
l'article d'Engle et Kroner (1995). Le modèle BEKK prend en compte des
interactions entre les variables étudiées. Néanmoins, bien
que le nombre des paramètres à estimer soit inférieur
à celui des modèles VEC et DVEC, il demeure encore très
élevé. Les recherches utilisant ce modèle limitent le
nombre d'actifs étudiés et ou imposent des restrictions comme de
supposer que les corrélations sont constantes.
On a commencé par une modélisation de la matrice
variance covariance par la spécification CCC de Bollerslev (1990), en
suite on a effectué un test de constance de corrélation pour
passer au modèle DCC de Engle et Sheppard (2002). Le DCC GARCH de Engle
et Sheppard (2002) a été retenu comme modèle
économétrique de référence car il permet de
réduire de manière significative le nombre de paramètres
à estimer et il fournit une interprétation relativement simple
des corrélations. Ce type de modèle GARCH est donc beaucoup plus
rapide à implémenter et beaucoup plus convivial lorsque vient le
moment d'interpréter les coefficients, c'est cela l'avantage qu'il offre
aux professionnels de la finance.
Les résultats du modèle GARCH DCC ont
été comparés en matière de gestion de portefeuille
à ceux de la méthode de calcul empirique de la matrice de
corrélation utilisée par la plupart des sociétés
financières.
Cette comparaison a eu lieu grâce à une
opération appelée dans le monde de la finance, le Backtesting.
Cette opération, consiste à simuler dans le passé une
stratégie d'allocation de portefeuille, c'est-à-dire une
manière d'attribuer des poids à chacun des actifs du portefeuille
au cours du temps. Elle permet en particulier, de vérifier de
manière empirique, comment une stratégie donnée se serait
comportée dans des conditions réelles en se plaçant dans
le passé sur une période donnée.
Afin de comparer l'efficacité de l'optimisation en
utilisant la méthode GARCH DCC, nous avons calculé la valeur du
portefeuille en utilisant en parallèle une méthode d'optimisation
quadratique (modèle mean-var de Markowitz) qui utilise une matrice de
corrélation
empirique. Pour les deux méthodes, tous les
paramètres d'optimisation étaient les mêmes mis a part la
matrice de corrélation, on note aussi que lors des simulations par
Backtesting on a fait l'hypothèse qu'il n'y a pas de coûts de
transactions (ou qu'ils sont négligeables).
En fin on achève notre étude avec les
résultats du Backtesting qui ont montré l'efficacité du
modèle GARCH DCC par rapport à la méthode empirique, car
ce modèle prend en compte la dynamique des volatilités des
covariances et la fait introduire dans l'optimisation de portefeuille.
Le rendement du portefeuille GARCH DCC superforme nettement le
rendement de la méthode empirique dans les périodes de forte
volatilité, par contre dans les autres périodes il semble que les
deux portefeuilles soient identiques, ce qui explique l'apport majeur de
l'introduction de la dynamique entre les actifs dans l'optimisation de
portefeuille.
Cette nouvelle méthode d'estimation de la matrice variance
covariance est une nouvelle porte pour la gestion de portefeuilles financiers,
car elle donne des résultats remarquables par rapports aux autres
méthodes classiques et empiriques.
On espère avoir répondu aux problèmes
posés et que les résultats trouvés seront d'une
utilité pertinente surtout dans le monde de la gestion de portefeuilles
financiers.
ANNEXE A : Symboles et Tableau
Symboles :
AR (p) Autorégressive
processus of ordre p (processus autorégressive d'ordre p).
MA (q) moyenne mobile d'ordre
q.
ARIMA (p, d, q) processus
autorégressif moyenne mobile intégré d'ordre (p, d, q).
GARCH(p, q) Generalised Autoregressif Conditional
Heteroscedasticity
CCC Constant Conditional
Correlation
DCC Dynamic Conditional
Correlation
? Produit de Kronecker
AIC Akaike information.
SC Schwarz criterion.
E espérance.
e erreur.
Var variance.
MSE mean square error matrix
(matrice de l'erreur quadratique moyenne).
T taille de l'échantillon ou
longueur de la série chronologique.
BEKK Baba Engle Kraft et
Kroner
Tables de Dikey Fuler
Valeurs critiques du test de Dickey Fuller
pour p =1
Modèle [1]
|
100
|
-2,6
|
-1,95
|
-1,61
|
|
250
|
-2,58
|
-1,95
|
-1,62
|
|
500
|
-2,58
|
-1,95
|
-1,62
|
Modèle [2]
|
100
|
-3,51
|
-2,89
|
-2,58
|
|
250
|
-3,46
|
-2,88
|
-2,57
|
|
500
|
-3,44
|
-2,87
|
-2,57
|
Modèle [3]
|
100
|
-4,04
|
-3,45
|
-3,15
|
|
250
|
-3,99
|
-3,43
|
-3,13
|
|
500
|
-3,98
|
-3,42
|
-3,13
|
Valeurs critiques de la constante et de la
tendance :
Modèle [2]
Constante
|
1%
|
5%
|
10%
|
|
100
|
3,22
|
2,54
|
2,17
|
|
250
|
3,19
|
2,53
|
2,16
|
|
500
|
3,18
|
2,52
|
2,16
|
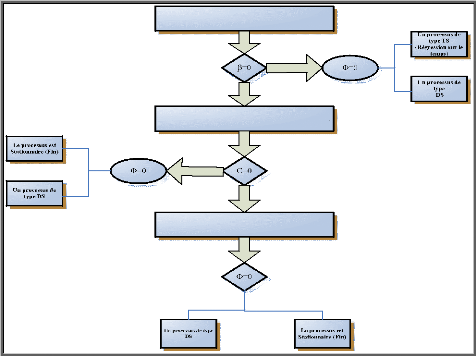
RH 0
AH 0
p
A = #177; ? A #177; #177; #177;
X q X _ çb X ? J3 t C e
t t j t j
1 t
j ? 1
p
A = #177; ? A #177; #177;
X ? X ? ? X C e
t t j t j t
1 ?
j ? 1
A
p
X ? X ? çb X e
t t j t j t
= #177; A #177;
1 ?
j ? 1
AH 0
R H0
AH 0
AH 0
R H0
RH0
.
.
.
R H0
AH 0
Modèle [3
Constante
|
1%
|
5%
|
10%
|
|
100
|
3,78
|
3,11
|
2,73
|
|
250
|
3,74
|
3,09
|
2,73
|
|
500
|
3,72
|
3,08
|
2,72
|
Tendance
|
1%
|
5%
|
10%
|
|
100
|
3,53
|
2,79
|
2,38
|
|
250
|
3,49
|
2,79
|
2,38
|
|
500
|
3,48
|
2,78
|
2,38
|
Algorithme de Dicky-Fuller augmenté
:
Annexe B: Programmes Matlab
GARCH univarié:
function [parameters, likelihood, ht, stderrors, robustSE,
scores, grad] = garchpq(data , p , q , startingvals, options)
% PURPOSE:
% GARCH(P,Q) parameter estimation with normal innovations
using
analytic derivatives
%
% USAGE:
% [parameters, likelihood, ht, stderrors, robustSE, scores, grad]
=
garchpq(data , p , q , startingvals, options)
%
% INPUTS:
% data: A single column of zero mean random data, normal or not
for
quasi likelihood
%
% P: Non-negative, scalar integer representing a model order of
the
ARCH
% process
%
% Q: Positive, scalar integer representing a model order of the
GARCH
% process: Q is the number of lags of the lagged conditional
variances included
% Can be empty([] ) for ARCH process
%
% startingvals: A (1+p+q) vector of starting vals. If you do
not
provide, a naieve guess of 1/(2*max(p,q)+1) is
% used for the arch and garch parameters, and omega is set to
make
the real unconditional variance equal
% to the garch expectation of the expectation.
%
% options: default options are below. You can provide an
options
vector. See HELP OPTIMSET
%
% OUTPUTS:
% parameters : a [ 1+p+q X 1] column of parameters with omega,
alpha1,
alpha2, ..., alpha(p)
% beta1, beta2, ... beta(q)
%
% likelihood = the loglikelihood evaluated at he parameters
%
% ht = the estimated time varying VARIANCES
%
% stderrors = the inverse analytical hessian, not for quasi
maximum
liklihood
%
% robustSE = robust standard errors of form A^-1*B*A^-1*T^-1
% where A is the analytic hessian
% and B is the covariance of the scores
%
% scores = the list of T scores for use in M testing
%
% grad = the average score at the parameters
%
% COMMENTS:
%
% GARCH(P,Q) the following(wrong) constratins are used(they are
right for
the (1,1) case or any Arch case
% (1) Omega > 0
% (2) Alpha(i) >= 0 for i = 1,2,...P
% (3) Beta(i) >= 0 for i = 1,2,...Q
% (4) sum(Alpha(i) + Beta(j)) < 1 for i = 1,2,...P and j =
1,2,...Q
%
% The time-conditional variance, H(t), of a GARCH(P,Q) process is
modeled
% as follows:
%
% H(t) = Omega + Alpha(1)*r_{t-1}^2 + Alpha(2)*r_{t-2}^2 +...+
Alpha (P)*r_{ t-p} ^2+...
% Beta(1)*H(t-1)+ Beta(2)*H(t-2)+...+ Beta(Q)*H(t-q)
%
% Default Options
%
% options = optimset('fmincon');
% options = optimset(options , 'TolFun' , 1e-003);
% options = optimset(options , 'Display' , 'iter');
% options = optimset(options , 'Diagnostics' , 'on');
% options = optimset(options , 'LargeScale' , 'off');
% options = optimset(options , 'MaxFunEvals' ,
'400* numberOfVariables');
% options = optimset(options , 'GradObj' , 'on');
%
%
% uses GARCH_LIKELIHOOD and GARCHCORE. You should MEX, mex
'path\garchcore.c', the MEX source
% The included MEX is for R12, 12.1 and 11 Windows and was
compiled with Intel Compiler 5.01.
% It gives a 10-15 times speed increase
%
% Author: Kevin Sheppard
%
kevin.sheppard@economics.ox.ac.uk
% Revision: 2 Date: 12/31/2001
if size(data,2) > 1
error('Data series must be a column vector.') elseif
isempty(data)
error('Data Series is Empty.')
end
if (length(q) > 1) | any(q < 0)
error('Q must ba a single positive scalar or an empty vector for
ARCH.') end
if (length(p) > 1) | any(p < 0)
error('P must be a single positive number.') elseif isempty(p)
error('P is empty.')
end
if isempty(q)
q=0; m=p; else m = max(p,q);
end
if nargin<=3 | isempty(startingvals)
guess = 1/(2*m+1);
alpha = .15*ones(p,1)/p;
beta = .75*ones(q,1)/q;
omega = (1-(sum(alpha)+sum(beta)))*cov(data); %set the uncond =
to its e xpe c t ion
else
omega=startingvals (1);
alpha=startingvals (2:p+1);
beta=startingvals (p+2:p+q+1);
end
LB = [];
UB = [];
sumA = [-eye(1+p+q); ... 0 ones(1,p) ones(1,q)];
sumB = [zeros(1+p+q,1);... 1];
if (nargin <= 4) | isempty(options) options =
optimset('fmincon');
options = optimset(options , 'TolFun' , 1e-003);
options = optimset(options , 'Display' , 'iter');
options = optimset(options , 'Diagnostics' , 'on'); options =
optimset(options , 'LargeScale' , 'off'); options = optimset(options ,
'MaxFunEvals' , 400* (1+p+q)); options = optimset(options , 'GradObj' ,
'on');
end
sumB = sumB - [ zeros(1+p+q,1); 1]*2*optimget(options, 'TolCon',
1e-6);
stdEstimate = std(data,1);
data = [ stdEstimate(ones(m,1)) ; data];
% Estimate the parameters.
[parameters, LLF, EXITFLAG, OUTPUT, LAMBDA, GRAD] =
fmincon('garchlikelihood', [omega ; alpha ; beta] ,sumA , sumB ,[] , [] , LB ,
UB,[] ,options,data, p , q, m, stdEstimate);
if EXITFLAG<=0
EXITFLAG
fprintf(1,'Not Sucessful! \n') end
parameters(find(parameters < 0)) = 0;
parameters(find(parameters(1) <= 0)) = realmin;
if nargout>1
[likelihood, grad, hessian, ht, scores, robustSE] =
garchlikelihood(parameters , data , p , q, m, stdEstimate); stderrors=hessian^
(-1);
likelihood=-likelihood; end.
%%%%%%%%%%%%%%%%%%%%%% Fin du
programme%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
GARCH multivarié CCC (CCC-MVGARCH)
:
function [parameters, loglikelihood, R ,Ht, likelihoods,
stdresid, unistdresid, hmat, stderrors, A, B,
j ointscores] =cc _mvgarch (data, archP, garchQ)
% PURPOSE:
% Estimates a multivariate GARCH model using Bollerslev's
constant
correlation estimator
%
% USAGE:
% [parameters, loglikelihood, R, Ht, likelihoods, stdresid,
unistdresid, hmat, stderrors, A, B, jointscores] =...
% cc_mvgarch (data, archP, garchQ)
%
% INPUTS:
% data: A zero mean t by k vector of residuals from some
filtration
% archP: One of three things: Empty in which case a 1
innovation
model is estimated for each series
% A scalar, p in which case a p
innovation model is estimated for each series
% A k by 1 vector in which case the
ith series has innovation terms p=archP(i)
% garchQ: One of three things: Empty in which case a 1 GARCH
lag
is used in estimation for each series
% A scalar, q in which case a q
GARCH lags is used in estimation for each series
% A k by 1 vector in which case the
ith series has lagged variance terms q=archQ(i)
%
% OUTPUTS:
% parameters= A vector of parameters estimated form the model of
the
fo rm
% [GarchParams (1) GarchParams (2) ... GarchParams (k)
Correlation(ccvech of the correlation matrix)]
% where the garch parameters from each estimation are of
the form
% [omega(i) alpha(i1) alpha(i2) ... alpha(ip(i)) beta(i1)
beta(i2) ... beta(iq(i))]
% loglikelihood=The log likelihood evaluated at the optimum
% R = k x k matrix of correlations
% Ht= A k by k by t array of conditional variances
% likelihoods = the estimated likelihoods t by 1
% stdresid = The multivariate standardized residuals
% unistdresid = Residuals standardized by their estimated std
devs
% Hmat = The t by k matrix of conditional variances
% stderrors=A length(parameters)^2 matrix of estimated correct
standard errors
% A = The estimated A form the rebust standard errors
% B =the estimated B from the standard errors
% scores = The estimated scores of the likelihood t by
length (parameters)
%
% COMMENTS:
% % % Author: Kevin Sheppard
%
kevin.sheppard@economics.ox.ac.uk
% Revision: 2 Date: 12/31/2001
% Lets do some error checking and clean up [t, k] =size
(data);
if k<2
error('Must have at least 2 data series') end
if ~(isempty(archP) | length(archP)==1 | length(archP)==k)
error('Wrong size for archP')
end
if ~(isempty(garchQ) | length(garchQ)==1 | length(garchQ)==k)
error('Wrong size for garchQ')
if isempty(archP)
archP=ones (1,k);
elseif length(archP)==1 archP=ones (1,k)*archP; end
if isempty(garchQ)
garchQ=ones (1,k);
elseif length (garchQ) ==1 garchQ=ones (1, k)*garchQ; end
% Now lest do the univariate garching using fattailed_garch as
it's faster then garchpq
stdresid=data;
options=optimset ( 'fmincon');
options=optimset (options, 'Display','off',
'Diagnostics','off', 'MaxFunEvals', 1000*max(archP+garchQ+1), 'MaxIter'
,1000*max(archP+garchQ+1), 'LargeScale', 'o ff', 'MaxSQPIter' ,1000);
options = optimset(options , 'MaxSQPIter' , 1000);
hmat=zeros (t, k);
for i=1:k
fprintf(1,'Estimating GARCH model for Series %d\n',i)
[univariate{ i} .parameters, univariate{ i} .likelihood,
univariate{i} .stderrors, univariate{i} .robustSE, univariate{i}
.ht, univariate{ i} .scores] ...
= fattailed_garch(data(:,i) , archP(i) , garchQ(i) , 'NORMAL',[],
options); stdresid(:,i)=data(:,i)./sqrt(univariate{i} .ht);
hmat(:,i)=univariate{ i} .ht;
end
unistdresid=stdresid;
% The estimated parameters are real easy
R=corrcoef (stdresid);
% We now have all of the estimated parameters parameters=[ ];
H=zeros (t, k);
for i=1:k
parameters=[ parameters;univariate{ i} .parameters];
H(:,i)=univariate{ i} .ht;
end
parameters=[ parameters;ccvech(R)];
%We now have Ht and the likelihood
if nargout >=2
[loglikelihood, likelihoods] =cc _mvgarch _full _likelihood
(parameters, data, archP,garchQ);
likelihoods=-likelihoods;
loglikelihood=-loglikelihood;
Ht=zeros (k, k, t); stdresid=zeros (t, k);
Hstd=H.^ (0.5); for i=1:t
Ht(:, :,i)=diag(Hstd(i, :))*R*diag(Hstd(i, :));
stdresid(i,:)=data(i,:)*Ht(:,:,i)^(-0.5);
end
if nargout>=9
%How ar we going to get STD errors? Partitioned invers probably.
Well, we need to get the scores form the dcc model, the joint likelihood.
%We then need to get A12 and A22 so we can have it all. We also
need to get A11 in the correct form.
A=zeros (length(parameters) ,length(parameters));
index=1;
for i=1:k
workingsize=size (univariate{ i} . stderrors);
A (index: index+workingsize-1, index: index+workingsize-
1)=univariate{ i} .stderrors^ (-1);
index=index+workingsize;
end
% Ok so much for a All and A12 and A22, as we have them all
between whats above
fprintf(1,'\n\nCalculating Standard Errors, this can take a
while\n'); otherA=dcc_hessian('cc_mvgarch_full_likelihood' ,parameters, (k*
(k-1) /2), data, archP,garchQ);
A(length(parameters)-(k* (k-1)/2)+1:length(parameters),
:)=otherA;
% tempA=hessian _2sided('dcc _garch _full _likelihood'
,parameters, data,
archP, garchQ, dccP, dccQ);
% A(length(parameters)-1 :length(parameters), :
)=tempA(length(parameters)-
1 : length (parameters),:); %That finishes A
% We now need to get the scores for the DCC estimator so we can
finish B jointscores=zeros (t,length(parameters));
index=1;
for i=1:k
workingsize=size (univariate{ i} . scores, 2);
jointscores (:, index:index+workingsize-1)=univariate{ i} .
scores; index=index+workingsize;
end
%Now all we need to do is calculate the scores form teh dcc
estimator and we have everything
h=max(abs(parameters/2) ,1e-2)*eps^(1/3);
hplus=parameters+h;
hminus=parameters-h;
likelihoodsplus=zeros (t,length(parameters));
likelihoodsminus=zeros (t,length(parameters));
for i=length(parameters)-(k* (k-1)/2)+1:length(parameters)
hparameters=parameters;
hparameters (i) =hplus (i);
[HOLDER, indivlike] = cc_mvgarch_full_likelihood(hparameters,
data, archP,garchQ);
likelihoodsplus (:, i)=indivlike;
end
for i=length(parameters)-(k* (k-1)/2)+1:length(parameters)
hparameters=parameters;
hparameters (i) =hminus (i);
[HOLDER, indivlike] = cc_mvgarch_full_likelihood(hparameters,
data, archP,garchQ);
likelihoodsminus (:, i)=indivlike;
end
CCscores=(likelihoodsplus(:,length(parameters)-(k*
(k1)/2)+1:length(parameters))-likelihoodsminus(: ,length(parameters)-(k* (k-
1) /2) +1: length (parameters)))...
./(2*repmat(h(length(parameters)-(k* (k-1)/2)+1:length(parameters)) ',t,1));
jointscores(: ,length(parameters)-(k* (k-
1) /2) +1: length (parameters) ) =CCscores;
B=cov (jointscores);
stderrors=A^ (-1)*B*A^ (-1)*t;
end %Done!
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Helper Function
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [parameters] =ccvech (CorrMat)
[k, t] =size (CorrMat);
parameters=zeros (k* (k-1) /2,1);
index=1;
for i=1:k
for j=i+1:k
parameters (index) =CorrMat (i, j);
index=index+1;
end end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Helper Function
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [CorrMat] =ccivech(params)
[k, t] =size (params);
for i=2:m
if (k/((i* (i-1))/2))==1
sizes=i;
break
end
end
index=1;
CorrMat=eye (sizes)
for i=1:sizes
for j=i+1:sizes
CorrMat (i, j ) =params (index); CorrMat (j,i) =params
(index); index=index+1;
end
end
%%%%%%%%%%%%%%%%%%%%%% Fin du programme% % % % % % % % % % % % %
% % % % % % % % % % % % % % % % % % % %
Test de Engle et Sheppard:
function [pval, stat] =dcc_mvgarch_test(data,archP,garchQ,nlags);
% PURPOSE:
% Test for presence of dynamic correlation
%
% USAGE:
% [pval, stat] =dcc_mvgarch_test(data,archP,garchQ,nlags);
% INPUTS:
% data - T by k matrix of residuals to be tested or dynamic
corrrelation
% archP - The length of the news terms in each univariate
garch(either
a scalar or a k by 1 vector)
% garchQ - The length of the smoothing terms in each
univariate
garch(either a scalar or a k by 1 vector)
% nlags - THe number of lags to use in the test
%
% OUTPUTS:
% pval - The probability the correlation is constant
% stat - The Chi^2 stat, with nlags+1 D.F>
%
% COMMENTS:
% % % Author: Kevin Sheppard
%
kevin.sheppard@economics.ox.ac.uk
% Revision: 2 Date: 12/31/2001
[t, k] =size (data);
if isempty(archP)
archP=ones (1,k);
elseif length(archP)==1 archP=ones (1,k)*archP; end
if isempty(garchQ)
garchQ=ones (1,k);
elseif length (garchQ) ==1 garchQ=ones (1, k)*garchQ; end
[holder,holder2,holder3,holder4,holder5, stdresid] =cc
_mvgarch(data,archP, gar chQ);
outerprods=[];
for i=1:k
for j=i+1:k;
outerprods=[ outerprods stdresid(:,i) .*stdresid(:,j)];
end
end
j=size (outerprods, 2);
regressors=[];
regressand=[];
for i=1:j
[Y,X] =newlagmatrix(outerprods (:, i) ,nlags, 1);
regressors=[ regressors; X]; regressand=[ regressand; Y];
end
beta=regressors\ regressand; XpX=(regressors'*regressors);
e=regressand-regressors* beta; sig=e'*e/ (length(regressors-nlags-1));
stat=beta'*XpX*beta/sqrt (sig); pval=1-chi2cdf(stat,nlags+1);
end.
%%%%%%%%%%%%%%%%%%%%%% Fin du programme% % % % % % % % % % % % %
% % % % % % % % % % % % % % % % % % % %
GARCH multivarié DCC (DCC-MVGARCH)
:
function [parameters, loglikelihood, Ht, Qt, stdresid,
likelihoods, stderrors, A,B, jointscores]
=dcc_mvgarch(data,dccP,dccQ,archP,garchQ)
% PURPOSE:
% Estimates a multivariate GARCH model using the DCC estimator
of
Engle and Sheppard
%
% USAGE:
% [parameters, loglikelihood, Ht, Qt, likelihoods, stdresid,
stderrors, A,B, jointscores]...
% =dcc_mvgarch (data, dccP, dccQ, archP, garchQ)
%
% INPUTS:
% data = A zero mean t by k vector of residuals from some
filtration
% dccP = The lag length of the innovation term in the DCC
estimator
% dccQ = The lag length of the lagged correlation matrices in
the DCC estimator
% archP = One of three things: Empty in which case a 1
innovation model is estimated for each series
% A scalar, p in which case a p
innovation model is estimated for each series
% A k by 1 vector in which case the
ith series has innovation terms p=archP(i)
% garchQ = One of three things: Empty in which case a 1
GARCH lag is used in estimation for each series
% A scalar, q in which case a q
GARCH lags is used in estimation for each series
% A k by 1 vector in which case the
ith series has lagged variance terms q=archQ(i)
%
% OUTPUTS:
% parameters = A vector of parameters estimated form the model
of
the form
% [GarchParams (1) GarchParams (2) ...
GarchParams (k) DCCParams]
% where the garch parameters from each estimation
are of the form
% [omega(i) alpha(i1) alpha(i2) ... alpha(ip(i))
beta(i1) beta(i2) ... beta(iq(i))]
% loglikelihood = The log likelihood evaluated at the optimum
% Ht = A k by k by t array of conditional variances
% Qt = A k by k by t array of Qt elements
% likelihoods = the estimated likelihoods t by 1
% stderrors = A length(parameters)^2 matrix of estimated
correct
standard errors
% A = The estimated A form the rebust standard errors
% B = The estimated B from the standard errors
% scores = The estimated scores of the likelihood t by
length (parameters)
% % % COMMENTS:
% % % Author: Kevin Sheppard
%
kevin.sheppard@economics.ox.ac.uk
% Revision: 2 Date: 12/31/2001
% Lets do some error checking and clean up [t, k] =size
(data);
if k<2
error('Must have at least 2 data series')
end
if length (dccP) ~=length (dccQ) | length (dccP)~=1 error('dccP
and dccQ must be scalars')
end
if ~(isempty(archP) | length(archP)==1 | length(archP)==k)
error('Wrong size for archP')
end
if ~(isempty(garchQ) | length(garchQ)==1 | length(garchQ)==k)
error('Wrong size for garchQ')
end
if isempty(archP)
archP=ones (1,k);
elseif length(archP)==1 archP=ones (1,k)*archP; end
if isempty(garchQ)
garchQ=ones (1,k);
elseif length (garchQ) ==1 garchQ=ones (1, k)*garchQ; end
% Now lest do the univariate garching using fattailed_garch as
it's faster then garchpq
stdresid=data;
options=optimset ( 'fmincon');
options=optimset (options, 'Display','off',
'Diagnostics','off', 'MaxFunEvals', 1000*max(archP+garchQ+1), 'MaxIter'
,1000*max(archP+garchQ+1), 'LargeScale', 'o ff', 'MaxSQPIter' ,1000);
options = optimset(options , 'MaxSQPIter' , 1000);
for i=1:k
% fprintf(1,'Estimating GARCH model for Series %d\n',i)
[univariate{ i} .parameters, univariate{ i} .likelihood,
univariate{i} .stderrors, univariate{i} .robustSE, univariate{i}
.ht, univariate{ i} .scores] ...
= fattailed_garch(data(:,i) , archP(i) , garchQ(i) , 'NORMAL',[],
options); stdresid(:,i)=data(:,i)./sqrt(univariate{i} .ht);
end
options=optimset ( 'fmincon');
%options = optimset(options , 'Display' , 'iter');
%options = optimset(options , 'Diagnostics' , 'on'); options =
optimset(options , 'LevenbergMarquardt' , 'on'); options = optimset(options ,
'LargeScale' , 'off');
dccstarting=[ ones(1,dccP)* .01/dccP ones(1,dccQ)* .97/dccQ];
%fprintf(1, '\n\nEstimating the DCC model\n')
[dccparameters,dccllf,EXITFLAG,OUTPUT,LAMBDA,GRAD]
=fmincon('dcc_mvgarch_lik elihood' ,dccstarting,ones (size(dccstarting)),[
1-
2*options.TolCon] ,[] ,[]
,zeros(size(dccstarting))+2*options.TolCon,[] ,[] ,opt ions,
stdresid,dccP,dccQ);
% We now have all of the estimated parameters
parameters=[ ];
H=zeros (t, k);
for i=1:k
parameters=[ parameters;univariate{ i} .parameters];
H(:,i)=univariate{ i} .ht;
end
parameters=[ parameters;dccparameters'];
%We now have Ht and the likelihood
[loglikelihood, Rt, likelihoods,
Qt] =dcc_mvgarch_full_likelihood(parameters, data,
archP,garchQ,dccP,dccQ); likelihoods=-likelihoods;
loglikelihood=-loglikelihood;
Ht=zeros (k, k, t);
stdresid=zeros (t, k);
Hstd=H.^ (0.5);
for i=1:t
Ht(:,:,i)=diag(Hstd(i,:))*Rt(:,:,i)*diag(Hstd(i,:));
stdresid(i,:)=data(i,:)*Ht(:,:,i)^(-0.5);
end
save tempHt Ht
clear Ht
if nargout >=7
%How ar we going to get STD errors? Partitioned invers probably.
Well, we need to get the scores form the dcc model, the joint likelihood.
%We then need to get A12 and A22 so we can have it all. We also
need to get A11 in the correct form.
A=zeros (length(parameters) ,length(parameters));
index=1;
for i=1:k
workingsize=size (univariate{ i} . stderrors);
A (index: index+workingsize-1, index: index+workingsize-
1)=univariate{ i} .stderrors^ (-1);
index=index+workingsize;
end
% Ok so much for a All and A12 and A22, as we have them all
between whats above
% fprintf(1,'\n\nCalculating Standard Errors, this can take a
while\n');
otherA=dcc_hessian ( 'dcc _mvgarch _full _likelihood'
,parameters, dccP+dccQ, data, archP,garchQ,dccP,dccQ);
A(length(parameters)-dccP-dccQ+1 :length(parameters), :
)=otherA;
% tempA=hessian('dcc _garch _full _likelihood' ,parameters,
data,
archP, garchQ, dccP, dccQ);
% A(length(parameters)-1 :length(parameters), :
)=tempA(length(parameters)-
1 : length (parameters),:); %That finishes A
% We now need to get the scores for the DCC estimator so we can
finish B jointscores=zeros (t,length(parameters));
index=1;
for i=1:k
workingsize=size (univariate{ i} . scores, 2);
jointscores (:, index:index+workingsize-1)=univariate{ i} .
scores; index=index+workingsize;
end
%Now all we need to do is calculate the scores form teh dcc
estimator and we have everything
h=max(abs(parameters/2) ,1e-2)*eps^(1/3);
hplus=parameters+h;
hminus=parameters-h;
likelihoodsplus=zeros (t,length(parameters));
likelihoodsminus=zeros (t,length(parameters));
for i=length (parameters) -dccP-dccQ+1 : length (parameters)
hparameters=parameters;
hparameters (i) =hplus (i);
[HOLDER, HOLDER1, indivlike] = dcc _mvgarch _full
_likelihood(hparameters, data, archP,garchQ,dccP,dccQ);
likelihoodsplus (:, i)=indivlike; end
for i=length (parameters) -dccP-dccQ+1 : length (parameters)
hparameters=parameters;
hparameters (i) =hminus (i);
[HOLDER, HOLDER1, indivlike] = dcc _mvgarch _full
_likelihood(hparameters, data, archP,garchQ,dccP,dccQ);
likelihoodsminus (:, i)=indivlike; end
DCCscores= (likelihoodsplus (:, length (parameters) -dccP-
dccQ+1 : length (parameters) ) -likelihoodsminus (:, length
(parameters) -dccPdccQ+1:length(parameters)))...
./(2*repmat(h(length(parameters)-dccP-dccQ+1:length(parameters))
',t,1));
j ointscores (:, length (parameters) -dccP-dccQ+1 : length
(parameters) ) =DCCscores; B=cov (jointscores);
A=A/t;
stderrors=A^ (-1)*B*A'^ (-1)*t^ (-1); end
%Done!
load tempHt
end.
%%%%%%%%%%%%%%%%%%%%%% Fin du programme% % % % % % % % % % % % %
% % % % % % % % % % % % % % % % % % % %
Bibliographie
A. Ouvrages
1. BOSQ Denis, Jean- pierre LECOUTURE « Analyse et
Prévision des séries chronologiques Méthodes
paramétriques et non paramétriques »
2. Bourbonnais .régis : « Econométrie
», 4ème édition Dunod, Paris 2002.
3. Bourbonnais régis - Michel Terraza : «
Analyse des séries temporelles », édition Dunod, Paris
2004.
4. Bourbonnais régis - Usunier Jean Claude : «
Prévision des ventes », 3ème édition
Economica, Paris 2001.
5. Bollerslev, T. et E. Ghysels (1996), « Periodic
AutoRegressive Conditional Heteroscedasticity »,Journal of Business and
Economics, 14(2) :139-52.
6. Bollerslev, T., R.Y. Chou et K. F. Kroner (1992), «
ARCH modeling in finance: A review of the theory and empirical evidence »,
Journal of Economics, 52:5-59.
7. Boullerslev, T. (1990), «Generalized AutoRegressive
Conditional Heterosedasticity »
8. Charpentier Arthur: « Cours de séries
temporelles théorie et applications », édition
université Paris DAUPHINE. Larousse illustré, édition
librairie Larousse 1984.
9. Capéraà Philippe - Bernard van Cutsen
« Méthodes et modèles en statistique non paramétrique
», édition Dunod, Paris 1988.
10. Cappiello, Engle and Sheppard, 2002, Asymmetric Dynamics
in the Correlations of International Equity and Bond Returns», UCSD
Discussion Paper, Correlations between 34 International equity and bond
indices.
11. Dominick, (1986), «Econométrie et
statistique appliquée », Serie Schaum.
12. DROSBERKE Jean jacques, BERNARD FICHET, PHILIPPE
TASSI
« M ODEL ISATION ARCH », théorie
statistique et applications dans le domaine de la finance.
13. Engle, 2002 : »Dynamic Conditional Correlation-A
Simple Class of Multivariate GARCH Models», Journal of Business and
Economic Statistics, Bivariate examples and Monte Carlo.
14. Engle and Sheppard, 2002 «Theoretical and
Empirical Properties of Dynamic Conditional Correlation Multivariate
GARCH», NBER Discussion Paper, and UCSD DP, Models of 30 Dow Stocks and
100 S&P Sectors.
15. Engle, R. F. et K. F. Kroner (1995), « Multivariate
simultaneous generalized ARCH », Economet. Theory, 11 :122-50.
16. Engle R obert F. "A Note on Robust Methods for ARIMA
Models, " in Applied Time Series Analysis of Economic Data, ed. A. Zellner
(Washington, D. C.: Bureau of the Census, 1981), pp. 176-1 77.
17. Engle Robert F. "Multiperiod forecast error variances of
inflation estimated from ARCH models, " (with Dennis Kraft), in Applied Time
Series Analysis of Economic Data, ed. A. Zellner (Washington, D.C.: Bureau of
the Census, 1983), 293-302.
18. Engle Robert F. "ARCH Models in Finance," (eds. R. Engle
and M. Rothschild), Journal of Econometrics 52 (1992): 245-266.
19. Engle Robert F. "Editors Introduction" (with M.
Rothschild), ARCH Models in Finance, eds. R. Engle and M. Rothschild, Journal
of Econometrics 52 (1992): 1.
20. Engle Robert F. «Time Varying Volatility and the
Dynamic Behavior of the Term Structure," (with V. Ng), Journal of Money, Credit
and Baning 25 (1993): 336-349.
21. Engle Robert F. "Statistical Models for Financial
Volatility, é» Financial Analysts Journal (Jan/Feb 1993): 72 -
78.
22. Engle Robert F. "ARCH Models, " (with D. Nelson and T.
Bollerslev) in Handbook of Econometrics, Volume IV, ed. R. Engle and D.
McFadden (Amsterdam: North Holland, 1994), 2959-3038. (without Figures 3 and
4).
23. Engle Robert F. «Forecasting Volatility and Option
Prices of the S&P 500 Index," (with Jaesun Noh and Alex Kane), Journal of
Derivatives 2(1994): 17-30.
24. Engle Robert F. «Multivariate Simultaneous GARCH,"
(with K. Kroner), Econometric Theory 11 (1995): 122-150.
25. Engle Robert F. "Estimating Common Sectoral Cycles,"
(with J. Issler), Journal of Monetary Economics 35 (1995): 83-113.
26. Engle Robert F. "GARCH Gammas," (with Joshua Rosenberg),
Journal of Derivatives 2 (1995): 47-59.
27. Engle Robert F. "Correlations and Volatilities of
Asynchronous Data," (with Pat Burns and Joe Mezrich), Journal of Derivatives
(1998) Summer: 1-12.
28. Engle Robert F. "CAViaR: Conditional Value At Risk By
Regression Quantiles, " (with Simone Manganelli).
29. Engle Robert F. "Dynamic Conditional Correlation - A
Simple Class of Multivariate GARCH Models."
30. Engle Robert F. "Financial Econometrics - A New
Discipline With New Methods,"
31. Engle Robert F. "Impacts of Trades in an
Error-Correction Model of Quote Prices, " (with Andrew Patton).
32. Gourieroux Christian- Alain Monfort : «
Séries temporelles et modèles dynamiques »,
2ème édition Economica, Paris 1995.
33. Gourieroux C., Montfort A. (1990), « Séries
temporelles et modèles dynamiques, Economica », Paris.
34. Hamilton James.D :«Time series analysis »,
Princeton University press, New Jersey 1994.
35. Journal of MIT press.
36. Mignon Valérie - Sandrine Lardig : «
Econométrie des séries temporelles macroéconomiques et
financières », édition économica, Paris 2002.
37. Wong, H et W. K. Li (1997), « On multivariate
conditional heteroscedasticity model », Biometrika,
84.
B. Mémoires

Alexis-O. François «Evaluation des performances
de couverture d'un GARCH multivarié à corrélations
conditionnelles dynamiques de type ENGLE(2002)». Université de
Montréal. C.Durville « Implémentation des coûts de
transaction dans les modèles de gestion de portefeuille
».Université de Nice Sphia-Antipolis.
F.Madi - L.Teffah. « Prospection d'une nouvelles classe
de Mélanges de Modèles Autorégressifs à erreur ARCH
». Mémoire de fin d'étude en ingéniorat en Recherche
Opérationnelle. USTHB 2007.

Landry Eric « Modélisation de la matrice de
covariance dans un contexte d'optimisation de portefeuille », science de
la gestion, Mémoire présenté en vue de l'obtention du
grade de maitrise és science (M.Sc.) , HEC Montréal, Septembre
2007.

Menia. A -Yous. A « Prévision des ventes /
Production des carburants par région et par raffinerie ;
Modélisation VARMA», Mémoire d'ingéniorat. U.S.T.H.B
(2004-2005).

Mémoire de fin d'études en vue de l'obtention
du diplôme d'Ingénieur d'Etat en Statistique M.osman
& C.Yakobene Thème : « Modélisation VAR et
ARFIMA en Vu de la Prévision des Quantités de Ventes de
Carburants Aviation et Marine ». U.S.T.H.B (2005/2006). M.Bourai -
S.Belkadi. « Prévision des quantités de Ventes de Bitumes en
Algérie ». Mémoire de fin d'étude en
ingéniorat en Statistique. USTHB 2007.
N.Saimi « Estimation de la volatilité et filtrage
non linéaire ».Université du Québec à
Trois-rivières.
P.Alexandre « Probleme d'optimisation de portefeuille en
temps discret avec une modélisation GARCH».HEC
Montréal.
R.Hamdi « Modèles GARCH multivariés
».Université Charles de Gaulles-Lille 3.
S.Baha - M.H.Benbouteldja. « Etude
prévisionnelle et d'interdépendance pour les quantité de
marchandises importées au port d'Alger ». Mémoire de fin
d'étude en ingéniorat en statistique. USTHB 2007.
S. Ouchem-M. Bouinoez « Gestion de portefeuille
application à la BVMT ». Université 7 novembre Cartage
Tunisie.
Yasmine Abbas & Wissem Bentarzi Thème :
« Etude des Prix Spot du Gaz naturel», Mémoire de fin
d'études en vue de l'obtention du diplôme d'Ingénieur
d'Etat en Recherche opérationnel. U.S.T.H.B (2005).
C. Internet
? Chapitre 3: Econométrie Appliquée
Séries Temporelles. Livre de Christophe HURLIN. (
Www.
dauphine.fr)
? Chapitre 4: Lissage exponentiel. Jean-Marie Dufour.
Université de Montréal. Version Février 2003.
? Michel LUBRANO (Septembre 2004) Cours Séries
Temporelles.
? (
Www.
Vcharite.univ-mrs.fr).
? (
Www.kevinsheppard.com)
.q (
Www.spatial-econometrics.
com)


